 夜雨聆风
夜雨聆风昨天我让AI帮我写了一个PDF水印工作台,效果完全超出了我的预期,感觉还不错。
它只有一个HTML文件,全程在浏览器里处理PDF,文件也不会上传到哪里哪里的服务器。
直接可以操作水印的文字调整、透明度、角度等等,还可以一键下载。
来看看效果图:
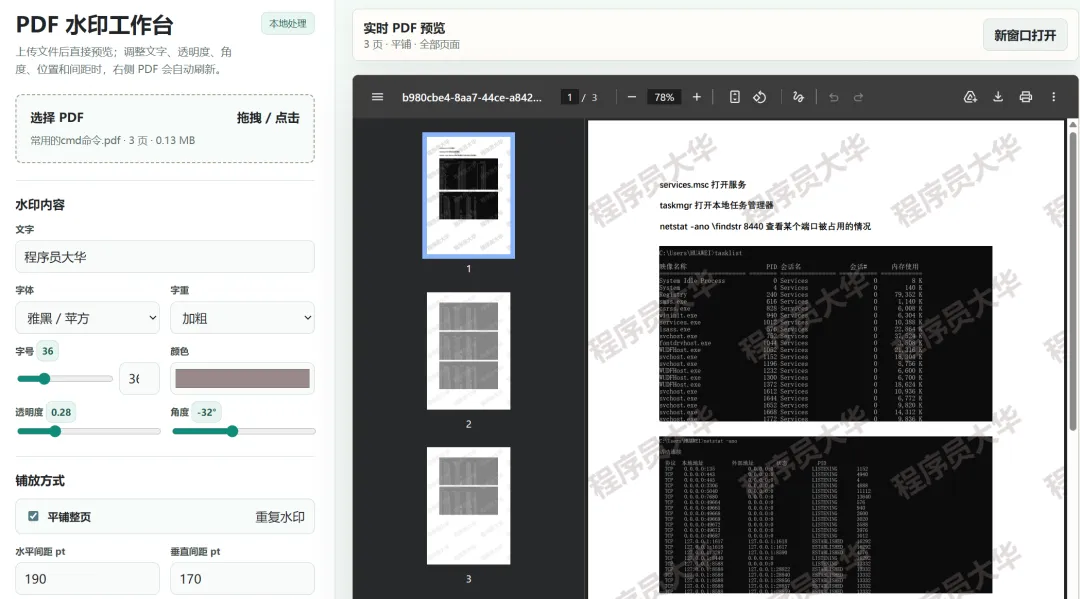
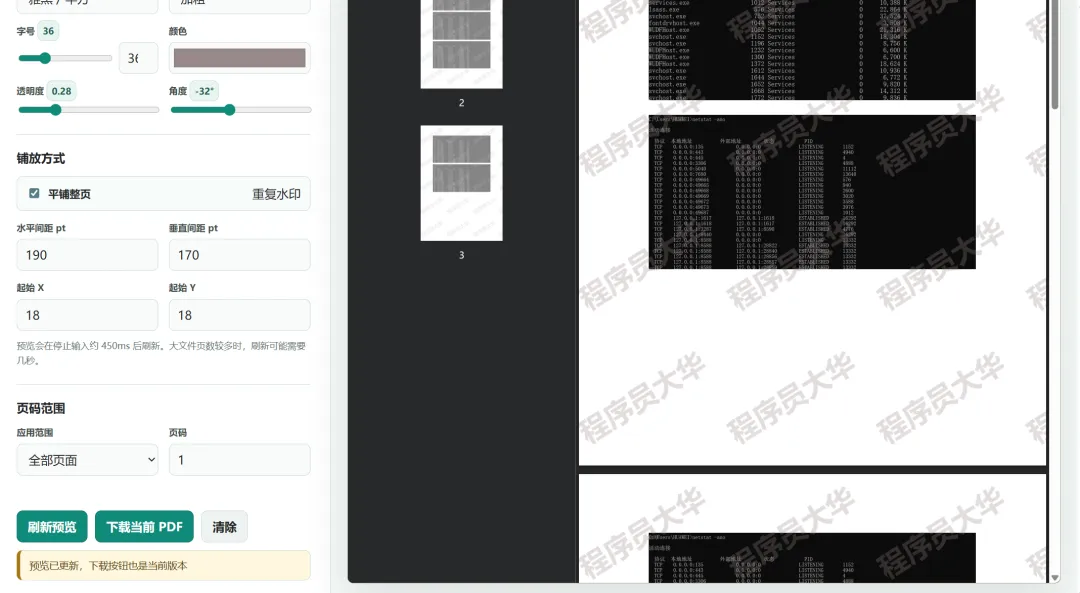
实现的功能:
• 上传PDF(支持拖拽) • 自定义水印文字、字体、颜色、透明度、旋转角度 • 选择平铺(重复水印)或单个水印模式 • 精准控制间距、边距、起始位置 • 指定页码范围(全部、首页、自定义如 1,3,5-8)• 实时预览,一键下载带水印的PDF
接下来看看AI实现的技术思路是怎样的。
一、技术栈
整个工具只依赖一个外部库:pdf-lib.js。它是一个强大的纯JavaScript PDF处理库,可以在浏览器中创建、修改PDF文档。
另一个核心是浏览器自带的 Canvas,它负责把水印文字渲染成带透明度的PNG图片,然后再塞进PDF。
这里我在实现过程中遇到一个问题,pdf-lib对中文字体的内嵌支持比较麻烦,需要加载字体文件,但我怎么反复调整都还是无法添加中文水印。用Canvas直接调用系统字体,画图再嵌入,可以解决这个问题。
整体流程可以概括为:
上传PDF → 读取为二进制数据 → 用pdf-lib解析页数 ↓用户调整参数 → 防抖等待450ms → Canvas绘制水印PNG ↓遍历每一页PDF → 将PNG按坐标铺入 → 生成新PDF二进制 ↓转为Blob URL → 更新iframe预览 → 更新下载链接二、核心实现
1. 文件读取与解析
上传的PDF文件通过File.arrayBuffer()拿到原始字节流,然后交给pdf-lib加载。
const arrayBuffer = await file.arrayBuffer();const pdfDoc = await PDFDocument.load(arrayBuffer);const pages = pdfDoc.getPages().length;originalPdfBytes = arrayBuffer; // 保存起来,后续每次生成水印都要用originalPdfBytes会一直保留,因为每次调整参数都要基于原始PDF重新生成水印(避免叠加)。
2. 水印图片生成
这是整个工具里最巧妙的环节。我们把水印文字画在一个离屏Canvas上,然后导出为PNG格式的Uint8Array,后续pdf-lib可以直接嵌入。
关键代码:
function createWatermarkImage(settings) { // 1. 考虑高分屏,放大绘制保证清晰度 const scale = Math.max(2, Math.ceil(window.devicePixelRatio || 1)); // 2. 创建Canvas,设置尺寸(根据文字旋转后占用的宽高计算) const canvas = document.createElement("canvas"); const ctx = canvas.getContext("2d"); // 3. 设置字体、旋转、颜色、透明度 ctx.font = `${settings.fontWeight} ${settings.fontSize * scale}px ${settings.fontFamily}`; ctx.translate(canvas.width/2, canvas.height/2); ctx.rotate(settings.rotationDeg * Math.PI / 180); ctx.fillStyle = `rgba(${r}, ${g}, ${b}, ${settings.opacity})`; ctx.textAlign = "center"; ctx.textBaseline = "middle"; ctx.fillText(settings.text, 0, 0); // 4. 导出为PNG字节流 return { bytes: dataUrlToUint8Array(canvas.toDataURL("image/png")), width: canvas.width / scale, height: canvas.height / scale };}为什么要把Canvas放大再缩小?为了在高分辨率屏幕(如Retina屏)上水印文字依然清晰,我们用devicePixelRatio的倍数绘制,然后告诉PDF以原始尺寸放置,这样图片精度就足够高。
3. PDF水印嵌入:循环铺放或单点定位
拿到PNG图片后,用pdfDoc.embedPng()将其嵌入PDF文档,然后遍历需要加水印的页面,逐页绘制。
平铺模式(Tile)
从设定的起始偏移(offsetX, offsetY)开始,以水平间距hSpacing和垂直间距vSpacing为步长,在页面范围内循环绘制,直到超出边界。
for (let x = startX; x < width + imageWidth; x += stepX) { for (let y = startY; y < height + imageHeight; y += stepY) { page.drawImage(watermarkImage, { x, y, width: imgWidth, height: imgHeight }); }}单水印模式
根据九宫格位置(如center、top-left、bottom-right)和边距参数,计算出唯一的坐标。
const positions = { "center": [pageWidth/2 - imgWidth/2, pageHeight/2 - imgHeight/2], "top-left": [marginX, pageHeight - imgHeight - marginY], // ...其他位置};const [x, y] = positions[settings.singlePosition];page.drawImage(watermarkImage, { x, y, width: imgWidth, height: imgHeight });4. 页码范围解析:灵活的语法支持
为了让用户可以指定“第1、3、5到8页”,我们实现了一个简单的页码范围解析器。
function parsePageSet(mode, rangeText, totalPages) { if (mode === "all") return new Set([...Array(totalPages).keys()]); if (mode === "first") return new Set([0]); const pageSet = new Set(); const chunks = rangeText.split(",").map(s => s.trim()); for (const chunk of chunks) { const match = chunk.match(/^(\d+)(?:-(\d+))?$/); if (!match) continue; let start = parseInt(match[1], 10); let end = match[2] ? parseInt(match[2], 10) : start; // 修正边界、转为0-based索引 for (let p = Math.min(start, end); p <= Math.max(start, end); p++) { if (p >= 1 && p <= totalPages) pageSet.add(p - 1); } } return pageSet;}5. 实时预览与防抖:体验的关键
用户拖拽滑块时,我们不希望每个微小变化都触发一次昂贵的PDF生成操作。因此引入了**防抖(Debounce)**机制:用户停止操作450毫秒后才开始渲染。
function schedulePreview() { clearTimeout(previewTimer); previewTimer = setTimeout(() => renderPreview(), 450);}同时,为了避免过时的渲染结果覆盖最新的请求,每次渲染前会分配一个递增的renderId,渲染完成后检查ID是否一致。
const renderId = ++latestRenderId;// ... 异步生成PDF后if (renderId !== latestRenderId) return; // 丢弃过时结果生成后的PDF字节被包装成Blob,创建一个blob:协议的URL赋给iframe.src,同时更新下载按钮的链接。
const blob = new Blob([pdfBytes], { type: "application/pdf" });const blobUrl = URL.createObjectURL(blob);pdfPreview.src = blobUrl;downloadLink.href = blobUrl;6. 内存管理:及时清理Blob URL
每次生成新预览前,都要撤销上一次创建的blob:链接,避免浏览器内存泄漏。
if (currentPdfBlobUrl) { URL.revokeObjectURL(currentPdfBlobUrl);}这个PDF水印工作台的完整HTML文件,我已经放在了公众号后台。关注后回复「PDF水印」就可以获取全部完整代码了。
