 夜雨聆风
夜雨聆风AI-agent-drug-design 全模块多维度清单(按原生架构拆分)
【药物研发智能体】AIDD我开源了——大模型驱动的下一代药物发现与设计体系:AI Drug Discovery 2.0
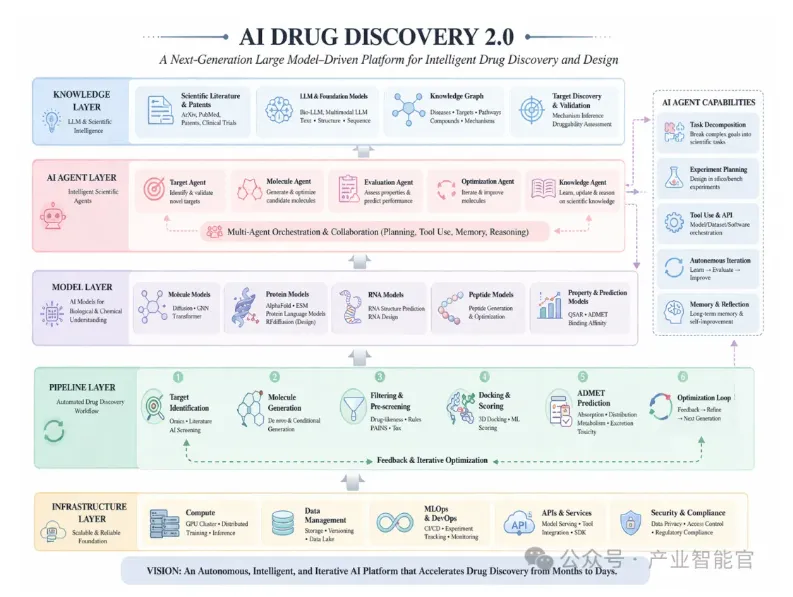
本清单100%严格匹配项目官方README的架构设计、功能定位与技术体系,按照项目原生5层架构+6大核心模块拆分为6张独立表格,新增「成熟度标识、核心输入/输出、技术栈依赖、官方设计目标、适配场景」等丰富维度,完整还原项目从底层工程到顶层智能体的全体系设计。
通用成熟度符号说明
符号 | 官方项目定义 |
✅ | 已落地实现,有可运行代码/Notebook/工程化模块 |
📐 | 架构级明确设计,已规划功能路径与技术方案,待工程化实现 |
🧩 | 模块化预留标准接口,支持第三方工具/模型/算法无缝接入 |
一、基础工程工具集(项目底层架构:计算与工程体系)
模块定位
项目的底层算力与工程底座,解决药物发现系统的规模与效率问题,提供统一的开发语言、算力适配、工程框架与数据管理能力,是上层所有模型、Agent、Pipeline的运行基础。
模块名称 | 核心定位 | 核心输入 | 核心输出 | 核心功能细节 | 核心技术栈/依赖 | 官方设计目标 | 适配场景 | 成熟度 |
Python统一开发框架 | 全系统统一开发语言底座 | 算法代码、模型脚本、Pipeline定义、Agent逻辑代码 | 标准化可执行代码包、容器化部署包 | 1. 基于Python 3.12构建全系统统一开发环境;2. 统一代码规范与类型接口;3. 跨环境兼容适配;4. 模块化代码管理 | Python 3.12、pip、venv/conda | 解决多工具/多模型环境不兼容问题,实现一套代码全场景运行 | 全系统开发、跨环境部署、算法迭代 | ✅ |
高性能计算适配模块 | 算力调度与GPU加速底座 | 算力需求配置、任务队列、模型推理/训练任务 | 任务执行结果、算力资源调度日志、GPU加速优化后的模型输出 | 1. GPU/CUDA环境自动适配与优化;2. 分布式计算任务调度;3. 大规模推理/训练任务的算力资源管理;4. 算力需求与资源自动匹配 | NVIDIA CUDA、cuDNN、PyTorch、JAX | 解决药物发现大模型/生成模型的高算力需求,实现大规模任务高效执行 | 大规模分子生成、虚拟筛选、模型训练、全流程Pipeline量产运行 | 📐 |
深度学习框架适配层 | 模型接入统一接口 | 第三方模型权重、算法实现、自定义算子 | 标准化模型调用接口、推理/训练结果 | 1. PyTorch/JAX双框架原生适配;2. 第三方生物/化学模型的统一封装接口;3. 模型推理加速与内存优化;4. 自定义模型快速接入 | PyTorch、JAX、Hugging Face Transformers | 实现多来源、多框架模型的无缝接入,解决单点模型碎片化问题 | 分子/蛋白/RNA模型接入、自定义模型开发、多模型协同推理 | 📐 |
模块化工程架构 | 全系统代码组织与扩展底座 | 功能模块代码、自定义工具、第三方插件 | 可扩展系统模块、标准化插件、可复用功能组件 | 1. 核心系统、Agent、模型、Pipeline全模块化拆分;2. 标准化模块间通信接口;3. 插件化扩展机制;4. 版本管理与迭代兼容 | Python模块化开发、Git、CI/CD | 实现系统的可扩展、可维护、可定制,支持从原型到生产的全周期迭代 | 系统二次开发、自定义功能扩展、多团队协作开发 | 📐 |
数据管理模块 | 全流程生物/化学数据底座 | 分子/蛋白/核酸原始数据、实验数据、文献数据、模型输出结果 | 标准化数据集、清洗后数据、结构化数据库、数据血缘追踪记录 | 1. 药物发现全流程数据获取、清洗、标准化;2. 分子/蛋白/核酸数据结构化存储;3. 数据血缘全链路追踪;4. 数据集版本管理与复用 | Pandas、NumPy、SQLite/PostgreSQL、RDKit | 解决药物发现数据碎片化、格式不统一、不可追溯的问题,实现数据全生命周期管理 | 模型训练数据准备、虚拟筛选库管理、实验数据管理、文献知识结构化 | 📐 |
交互式实验Notebook模块 | 原型开发与教学演示载体 | 实验代码、流程演示、教学案例、模型测试脚本 | 可运行Notebook、实验结果、可视化报告、教学演示材料 | 1. Jupyter Notebook交互式开发环境;2. 药物发现全流程案例演示;3. 模型/工具功能测试;4. 教学内容与实战案例承载 | Jupyter Notebook、Jupyter Lab、ipywidgets | 实现从教学演示到原型开发的无缝衔接,降低系统使用门槛 | 教学培训、算法原型开发、流程测试、结果可视化 | ✅ |
二、核心模型工具集(AI能力核心:设计与预测层)
模块定位
项目的算法能力核心,覆盖分子、蛋白、RNA/多肽、成药性预测四大维度,为药物发现提供从分子生成、结构设计到性质预测的全环节AI能力,是Agent与Pipeline的核心执行工具。
工具/模型名称 | 所属子类别 | 核心定位 | 核心输入 | 核心输出 | 核心功能细节 | 核心技术栈/依赖 | 官方设计目标 | 适配场景 | 成熟度 |
扩散生成模型 | 分子层 | 小分子从头生成核心工具 | 靶点结构、分子约束条件、母核结构、生成数量 | 全新小分子结构(SMILES/SDF)、分子性质预测结果、生成多样性报告 | 1. 基于扩散模型的小分子从头生成;2. 条件化分子生成(靶点结合、成药性约束);3. 分子骨架跃迁与结构优化;4. 大规模分子库生成 | Diffusion Models、RDKit、PyTorch | 实现靶点匹配的全新小分子快速生成,解决传统分子设计效率低的问题 | 先导化合物生成、分子库构建、结构优化、母核改造 | 🧩 |
图神经网络(GNN) | 分子层 | 分子表示与性质预测核心工具 | 分子SMILES/Graph结构、预测任务定义 | 分子性质预测值、分子表征向量、活性预测结果 | 1. 分子图结构特征提取与表示;2. 分子活性/成药性预测;3. 蛋白-配体相互作用预测;4. 分子相似性与聚类分析 | GNN、PyTorch Geometric、DGL、RDKit | 实现分子性质的精准快速预测,替代部分低通量实验 | 分子虚拟筛选、成药性初筛、活性预测、构效关系分析 | 🧩 |
Transformer分子大模型 | 分子层 | 分子语言理解与生成基础模型 | 分子SMILES序列、自然语言指令、生成/预测任务 | 分子序列、分子性质解释、指令化生成结果、分子文本描述 | 1. 基于Transformer的分子语言建模;2. 自然语言驱动的分子生成与优化;3. 分子结构-性质关系理解;4. 大规模分子预训练知识迁移 | Transformer、LLaMA/Mistral类基座、ChemBERTa、PyTorch | 实现分子设计的自然语言交互,打通生物/化学语言与大模型的壁垒 | 指令化分子设计、分子知识问答、分子生成、构效关系解读 | 🧩 |
AlphaFold系列 | 蛋白层 | 蛋白结构预测金标准工具 | 蛋白氨基酸序列、MSA文件、寡聚体状态 | 蛋白3D结构(PDB/CIF)、结构置信度(pLDDT/PAE)、生物组装体结构 | 1. 蛋白单体/同源寡聚体/复合物高精度结构预测;2. 蛋白-蛋白/蛋白-多肽相互作用结构预测;3. 突变体结构预测;4. 结合口袋识别与分析 | AlphaFold2/3、OpenFold、MMseqs2 | 实现蛋白结构的高精度快速预测,解决靶点结构获取难的问题 | 靶点结构解析、蛋白设计、突变体结构验证、结合口袋分析 | 🧩 |
ESM蛋白语言模型 | 蛋白层 | 蛋白序列理解与设计基础模型 | 蛋白氨基酸序列、预测/设计任务、自然语言指令 | 蛋白序列表征、突变体效应预测、蛋白功能注释、序列设计结果 | 1. 蛋白序列预训练表征提取;2. 蛋白突变体稳定性/活性预测;3. 蛋白功能注释与分类;4. 基于序列的蛋白从头设计 | ESM-2/ESM-Fold、PyTorch、Hugging Face | 实现蛋白序列的深度理解,无需结构即可完成蛋白功能预测与设计 | 蛋白突变体设计、稳定性优化、功能注释、序列从头设计 | 🧩 |
RFdiffusion系列 | 蛋白层 | 蛋白骨架从头生成核心工具 | 蛋白设计约束、contigs规则、结合口袋要求、对称状态 | 全新蛋白骨架3D结构、设计元数据、约束满足度报告 | 1. 蛋白骨架从头扩散生成;2. 功能域/结合口袋定制化设计;3. 固定区域保留的条件化生成;4. 蛋白-配体复合物骨架设计 | RFdiffusion/RFdiffusion3、PyTorch | 实现全新功能蛋白的从头设计,突破天然蛋白序列限制 | 酶设计、结合蛋白设计、蛋白疫苗设计、功能域改造 | 🧩 |
RNA结构预测与设计模型 | RNA/多肽层 | RNA药物设计核心工具 | RNA核苷酸序列、设计约束、二级结构要求 | RNA 2D/3D结构、结构稳定性预测、优化后RNA序列 | 1. RNA二级/三级结构高精度预测;2. siRNA/mRNA/适配体序列设计与优化;3. RNA稳定性与翻译效率优化;4. RNA-蛋白相互作用预测 | RNAfold、AlphaFold-RNA、PyTorch | 实现RNA药物的序列设计与结构优化,覆盖核酸药物全设计环节 | mRNA疫苗设计、siRNA药物开发、核酸适配体设计、RNA结构优化 | 🧩 |
多肽生成与优化模型 | RNA/多肽层 | 多肽药物设计核心工具 | 靶点结构、多肽序列约束、活性要求 | 全新多肽序列、多肽-靶点结合结构、活性预测结果 | 1. 靶向多肽从头生成与优化;2. 多肽-蛋白复合物结构预测;3. 多肽稳定性/透膜性优化;4. 环肽/修饰肽设计 | PeptideBuilder、RDKit、PyTorch、GNN | 实现多肽药物的快速设计与优化,覆盖多肽药物全设计环节 | 靶向肽药物开发、抗菌肽设计、蛋白-蛋白相互作用抑制剂开发 | 🧩 |
QSAR模型 | 性能预测层 | 定量构效关系预测工具 | 分子结构-活性数据集、目标分子、预测终点 | 活性预测值、构效关系模型、关键结构特征 | 1. 基于分子结构的定量活性预测;2. 构效关系建模与解读;3. 多终点活性同步预测;4. 小样本数据集模型优化 | RDKit、scikit-learn、PyTorch、XGBoost | 实现分子活性的快速预测,减少实验筛选的试错成本 | 先导化合物优化、虚拟筛选富集、构效关系分析、活性排序 | 🧩 |
ADMET预测模型 | 性能预测层 | 成药性预测核心工具 | 分子SMILES/结构、预测终点 | ADMET性质预测值、成药性风险评估、优化建议 | 1. 吸收、分布、代谢、排泄、毒性全维度预测;2. 成药性风险分级与预警;3. 类药五规则/先导化合物规则符合性检测;4. 多物种ADMET预测 | ADMETlab、RDKit、GNN、PyTorch | 提前筛除成药性差的分子,降低药物研发后期失败风险 | 先导化合物初筛、分子优化、成药性评估、虚拟筛选 | 🧩 |
结合亲和力预测模型 | 性能预测层 | 靶点-分子结合能力预测工具 | 蛋白靶点结构、小分子配体结构、复合物构象 | 结合亲和力(pKd/pKi)、结合模式分析、关键相互作用位点 | 1. 蛋白-配体结合亲和力高精度预测;2. 结合模式与关键相互作用识别;3. 大规模虚拟筛选快速打分;4. 突变体对亲和力的影响预测 | Gnina、AutoDock Vina、GNN、PyTorch | 实现分子结合能力的精准预测,替代传统分子对接的低精度打分 | 虚拟筛选、先导化合物优化、结合模式分析、突变体设计 | 🧩 |
三、大模型基础能力工具集(2.0版本核心升级层)
模块定位
项目的大脑与交互中枢,是2.0版本的核心升级,大模型不再是辅助工具,而是系统的科学知识理解引擎、文献解析系统、靶点发现系统与分子设计语言接口,实现自然语言驱动的药物发现全流程。
工具/模块名称 | 核心定位 | 核心输入 | 核心输出 | 核心功能细节 | 核心技术栈/依赖 | 官方设计目标 | 适配场景 | 成熟度 |
科学知识理解引擎 | 大模型核心能力底座 | 生物/化学/医学文献、专业数据库内容、科学问题、自然语言指令 | 结构化知识、问题解答、机制解读、科学推理结果 | 1. 生物/化学/医药领域专业知识深度理解;2. 复杂生物机制、疾病通路、药物作用原理的推理与解读;3. 专业领域自然语言交互;4. 跨文献知识整合与关联 | 生物医药领域微调LLM、GPT-4o/Claude Opus类通用大模型、RAG框架 | 让系统具备生物医药领域的专业知识理解与推理能力,替代人工文献调研与知识整合 | 疾病机制研究、靶点生物学解读、药物作用原理分析、专业知识问答 | 📐 |
文献自动解析系统 | 知识获取自动化模块 | 文献PDF/文本、检索关键词、知识抽取规则 | 结构化文献知识库、靶点/分子/实验数据抽取结果、文献综述、知识图谱 | 1. 大规模生物医药文献批量下载与解析;2. 靶点、分子、实验数据、临床结果的自动化抽取;3. 文献知识结构化与知识图谱构建;4. 自动化文献综述与研究进展总结 | RAG框架、PDF解析工具、大模型Function Call、知识图谱数据库 | 解决药物发现中文献调研耗时、知识碎片化的问题,实现文献知识的自动化获取与结构化 | 靶点发现、研究进展调研、专利分析、实验方案参考、知识图谱构建 | 📐 |
靶点发现与验证系统 | 大模型驱动的靶点挖掘模块 | 疾病名称、研究领域、文献知识库、多组学数据 | 潜在靶点列表、靶点成药性评估、靶点验证方案、生物学机制解读 | 1. 基于文献与多组学数据的疾病相关靶点自动化挖掘;2. 靶点成药性、可药性、新颖性综合评估;3. 靶点生物学机制与通路分析;4. 靶点体内外验证方案自动生成 | 大模型、多组学数据分析工具、知识图谱、靶点成药性数据库 | 解决传统靶点发现依赖经验、周期长的问题,实现AI驱动的全新靶点自动化挖掘 | 全新靶点发现、疾病机制研究、靶点成药性评估、靶点验证方案设计 | 📐 |
自然语言驱动分子设计接口 | 人机交互核心模块 | 自然语言设计指令、靶点信息、分子约束条件 | 符合要求的分子结构、设计方案、优化建议、可执行Pipeline | 1. 自然语言到分子设计指令的转换;2. 基于口语化需求的分子生成、优化、筛选;3. 设计需求的自动拆解与Pipeline生成;4. 设计结果的自然语言解读与优化建议 | 指令微调大模型、Function Call、分子设计模型接口 | 降低分子设计的技术门槛,让无计算背景的科研人员通过自然语言完成分子设计 | 先导化合物生成、分子结构优化、虚拟筛选、定制化分子库构建 | 📐 |
多模态推理引擎 | 跨模态数据融合模块 | 蛋白/分子结构、序列数据、文献文本、实验数据、图像数据 | 跨模态关联分析结果、多维度推理结论、结构-功能关系解读 | 1. 序列、结构、文本、实验数据的多模态融合表征;2. 跨模态生物机制推理与结构-功能关系解读;3. 多来源数据的关联分析与因果推断;4. 多模态输入的统一理解与响应 | 多模态大模型、结构表征模型、序列大模型、图文对齐模型 | 打通药物发现中多模态数据的壁垒,实现全维度数据的融合分析与推理 | 靶点-分子相互作用分析、结构-活性关系解读、多组学数据整合分析、疾病机制研究 | 📐 |
四、AI Agent智能体工具集(系统核心突破层)
模块定位
项目的自主科研执行核心,是整个系统的最大突破点,通过多智能体分工协同,让系统具备完整的「科研行为能力」,实现从「人驱动流程」到「AI驱动科学」的范式升级。
Agent名称 | 核心角色 | 核心职责 | 核心输入 | 核心输出 | 核心能力细节 | 协同关联Agent | 官方设计目标 | 适配场景 | 成熟度 |
Target Agent(靶点发现Agent) | 靶点挖掘与验证负责人 | 疾病相关靶点的自动化挖掘、评估、验证方案设计 | 疾病名称、研究领域、文献知识库、多组学数据、用户需求 | 优先级排序的靶点列表、靶点成药性评估报告、靶点验证实验方案、靶点生物学机制图谱 | 1. 自动化文献与多组学数据挖掘,识别疾病相关潜在靶点;2. 靶点成药性、可药性、新颖性、专利风险综合评估;3. 靶点优先级排序与筛选;4. 靶点体内外验证实验方案自动化设计;5. 靶点生物学通路与机制深度解析 | Knowledge Agent、Evaluation Agent | 实现全新靶点的自动化挖掘与评估,解决靶点发现依赖专家经验、周期长的痛点 | 全新靶点发现、疾病机制研究、靶点成药性评估、靶点验证方案设计 | 📐 |
Molecule Agent(分子生成Agent) | 分子设计与库构建负责人 | 针对靶点的先导化合物生成、分子库构建、结构优化 | 靶点结构/序列、设计需求、成药性约束、用户指令 | 全新小分子/多肽/核酸分子结构、定制化分子库、分子优化方案、设计合理性报告 | 1. 基于靶点的小分子/多肽/核酸分子从头生成;2. 定制化分子库的自动化构建;3. 基于成药性/活性约束的分子结构优化;4. 分子设计方案的合理性评估与迭代;5. 自然语言指令到分子设计的转换 | Target Agent、Optimization Agent、Knowledge Agent | 实现靶点匹配的分子自动化设计,解决传统分子设计效率低、依赖专家经验的问题 | 先导化合物生成、分子库构建、结构优化、定制化分子设计 | 📐 |
Evaluation Agent(评估验证Agent) | 设计结果评估与质控负责人 | 分子/靶点设计结果的全维度评估、质控、排序 | 分子结构、靶点信息、模型预测结果、实验数据 | 分子/靶点综合评估报告、优先级排序列表、假阳性结果过滤、实验验证优先级建议 | 1. 分子活性、结合亲和力、ADMET成药性全维度评估;2. 靶点成药性与验证可行性评估;3. 设计结果的质控与假阳性过滤;4. 候选分子/靶点的优先级排序;5. 实验验证方案的优化与建议 | Target Agent、Molecule Agent、Knowledge Agent | 实现设计结果的自动化、标准化评估,筛除低质量候选,降低实验试错成本 | 虚拟筛选结果评估、先导化合物排序、成药性评估、靶点验证优先级排序 | 📐 |
Optimization Agent(优化迭代Agent) | 闭环迭代优化负责人 | 基于评估结果的分子/靶点自动化优化、多轮迭代、策略调整 | 评估报告、设计结果、优化目标、用户约束 | 优化后的分子/靶点序列、迭代优化方案、策略调整报告、多轮迭代结果汇总 | 1. 基于评估结果的分子结构自动化迭代优化;2. 靶点验证策略的调整与优化;3. 多轮设计-评估-优化闭环的自动化执行;4. 优化策略的自主调整与升级;5. 迭代过程全记录与效果分析 | 所有Agent | 实现药物发现全流程的自动化闭环迭代,解决传统线性流程优化效率低的问题 | 先导化合物多轮优化、靶点验证策略迭代、分子库定向优化、结合亲和力提升 | 📐 |
Knowledge Agent(知识更新Agent) | 系统知识底座维护负责人 | 全系统的知识更新、文献追踪、知识库维护、知识供给 | 最新文献、专利数据、专业数据库更新、用户反馈 | 结构化知识库更新、研究进展预警、知识图谱迭代、相关文献推送 | 1. 生物医药领域最新文献、专利、研究进展的自动化追踪;2. 系统结构化知识库与知识图谱的实时更新;3. 其他Agent的知识需求响应与供给;4. 研究领域最新进展的预警与推送;5. 实验数据与文献知识的关联整合 | 所有Agent | 保证系统知识的时效性与全面性,让系统持续跟进领域最新研究进展 | 最新研究进展追踪、知识库维护、专利预警、文献自动化调研 | 📐 |
Agent调度与协同中枢 | 多智能体管理核心 | 任务拆解、Agent调度、流程管控、结果整合 | 用户总任务、科研目标、用户指令 | 任务拆解方案、Agent执行计划、全流程执行结果、汇总报告 | 1. 复杂科研任务的自动化拆解与分步规划;2. 多Agent的任务分配、调度与协同管控;3. 全流程执行状态监控与异常处理;4. 多Agent输出结果的整合、汇总与报告生成;5. 用户指令的解析与任务落地 | 所有Agent | 实现多Agent的高效协同,让复杂科研任务自动化、有序执行 | 端到端药物发现全流程自动化、复杂科研任务拆解、多Agent协同管控 | 📐 |
五、自动化Pipeline流程工具集(全流程执行层)
模块定位
项目的自动化执行载体,将药物发现全流程拆解为标准化、可复用、可自动化执行的Pipeline,实现从靶点识别到候选分子输出的全流程自动化,最终形成可持续运行的药物发现系统。
Pipeline名称 | 核心定位 | 全流程环节 | 核心输入 | 核心输出 | 核心功能细节 | 调用核心工具/Agent | 官方设计目标 | 适配场景 | 成熟度 |
靶点识别与验证Pipeline | 药物发现起始环节自动化流程 | 疾病机制调研→潜在靶点挖掘→靶点成药性评估→靶点优先级排序→验证方案设计 | 疾病名称、研究领域、多组学数据、用户需求 | 靶点候选列表、成药性评估报告、靶点验证方案、机制研究报告 | 1. 疾病相关靶点的自动化挖掘与筛选;2. 靶点多维度成药性综合评估;3. 靶点优先级自动化排序;4. 靶点体内外验证方案自动生成;5. 靶点生物学机制深度解析 | Target Agent、Knowledge Agent、大模型文献解析系统、靶点成药性预测模型 | 实现药物发现起始环节的自动化,解决靶点发现周期长、依赖经验的问题 | 全新靶点发现、疾病机制研究、靶点成药性评估、靶点验证 | 📐 |
分子生成与库构建Pipeline | 先导化合物发现核心流程 | 靶点结构解析→结合口袋分析→分子从头生成→分子库构建→初筛过滤 | 靶点结构/序列、设计需求、成药性约束 | 全新分子库、初筛后候选分子、分子设计报告、结构-性质统计 | 1. 靶点结合口袋自动化识别与分析;2. 靶点匹配的小分子/多肽从头生成;3. 定制化分子库自动化构建;4. 基于类药规则的初筛与过滤;5. 分子多样性与成药性统计分析 | Molecule Agent、Knowledge Agent、扩散生成模型、蛋白结构预测工具、分子性质预测模型 | 实现靶点匹配的分子库自动化构建,快速获得高质量先导化合物候选 | 先导化合物生成、定制化分子库构建、虚拟筛选库准备、全新分子设计 | 📐 |
虚拟筛选与分子过滤Pipeline | 大规模候选分子富集流程 | 分子库预处理→靶点结构准备→分子对接/共折叠→亲和力预测→ADMET评估→多维度过滤排序 | 靶点结构、分子库、筛选阈值、用户约束 | 富集后候选分子列表、虚拟筛选报告、结合模式分析、成药性评估结果 | 1. 大规模分子库的自动化预处理与标准化;2. 高通量分子对接/共折叠与亲和力预测;3. 分子ADMET成药性全维度评估;4. 多维度阈值过滤与优先级排序;5. 结合模式与关键相互作用自动化分析 | Evaluation Agent、Molecule Agent、分子对接工具、结合亲和力预测模型、ADMET预测模型 | 实现大规模分子库的自动化虚拟筛选,快速富集高潜力候选分子,降低实验筛选规模 | 大规模化合物库虚拟筛选、先导化合物富集、结合模式分析、成药性初筛 | 📐 |
对接与评估Pipeline | 候选分子精细化验证流程 | 候选分子预处理→靶点-分子复合物结构预测→结合模式分析→活性/亲和力精准预测→成药性精细化评估 | 候选分子列表、靶点结构、评估维度要求 | 复合物结构、精准亲和力预测结果、结合模式报告、综合评估排名、实验优先级建议 | 1. 靶点-分子复合物高精度结构预测;2. 结合模式与关键相互作用深度分析;3. 结合亲和力精准预测与排序;4. 成药性多维度精细化评估;5. 实验验证优先级排序与方案建议 | Evaluation Agent、Boltz2/AlphaFold3、结合亲和力预测模型、ADMET预测模型 | 实现候选分子的精细化、多维度评估,精准锁定高潜力先导化合物,降低实验失败风险 | 先导化合物精细化评估、结合模式研究、活性排序、实验优先级确定 | 📐 |
ADMET成药性预测Pipeline | 药物开发风险管控流程 | 分子结构输入→吸收/分布/代谢/排泄/毒性全维度预测→成药性风险分级→优化建议生成 | 候选分子结构、预测终点要求、物种信息 | ADMET全维度预测报告、成药性风险评估、风险位点识别、结构优化建议 | 1. 分子ADMET性质全维度自动化预测;2. 成药性风险分级与预警;3. 风险结构位点精准识别;4. 针对性结构优化建议生成;5. 多物种ADMET差异分析 | Evaluation Agent、ADMET预测模型、大模型结构优化建议模块 | 提前识别成药性风险,筛除高风险分子,降低药物研发后期失败率 | 先导化合物成药性评估、风险分子过滤、结构优化指导、临床前候选化合物筛选 | 📐 |
多轮优化迭代Pipeline | 先导化合物闭环优化流程 | 初始分子输入→评估分析→问题位点识别→结构优化→再评估→多轮循环→最优分子输出 | 初始分子、靶点结构、优化目标、约束条件、循环轮次 | 优化后先导分子、多轮迭代报告、结构-性质变化趋势、最优候选分子列表 | 1. 初始分子的全维度评估与问题位点识别;2. 针对性结构自动化优化;3. 优化后分子的重新评估与对比;4. 多轮设计-评估-优化闭环自动化执行;5. 迭代过程全记录与效果分析 | Optimization Agent、Molecule Agent、Evaluation Agent、全系列分子设计与评估模型 | 实现先导化合物的自动化闭环优化,快速提升分子活性、成药性,解决传统优化周期长的问题 | 先导化合物多轮优化、活性提升、成药性优化、结合亲和力提升 | 📐 |
六、教学与系统实战模块集
模块定位
项目的教学与落地载体,通过模块化课程与系统级实战,帮助用户从入门到完整构建AI驱动的药物发现系统,实现从「工具使用者」到「系统构建者」的转变。
模块名称 | 核心定位 | 核心学习目标 | 核心内容 | 配套资源 | 官方设计目标 | 适配人群 | 成熟度 |
Module 1:药物发现基础与数据体系 | 入门基础模块 | 掌握药物发现全流程、生物/化学数据基础与处理方法 | 1. 药物发现全流程详解;2. 药物研发痛点与AI的应用机会;3. 分子/蛋白/核酸数据获取与清洗;4. 主流分子表示方法(SMILES/Graph/3D);5. 药物发现数据标准化与管理 | 教学Notebook、示例数据集、数据处理代码模板 | 搭建药物发现与AI交叉领域的基础认知,掌握核心数据处理能力 | 入门学习者、跨领域入行人员、生物/化学背景科研人员 | ✅ |
Module 2:分子生成与建模 | 分子设计核心模块 | 掌握AI分子生成、建模与优化的核心方法与工程实现 | 1. 小分子生成模型原理与实现(VAE/扩散模型/GNN);2. 分子优化核心策略;3. 分子化学空间探索方法;4. 定制化分子库构建;5. 分子生成模型工程化落地 | 模型实现代码、示例Notebook、预训练模型权重、分子生成Pipeline模板 | 掌握AI分子设计的核心技术,能够独立实现小分子生成与优化 | AI工程师、药物化学研发人员、计算化学科研人员 | 📐 |
Module 3:蛋白/RNA/多肽设计 | 生物大分子设计模块 | 掌握蛋白/RNA/多肽的AI结构预测、设计与优化方法 | 1. 蛋白结构预测与从头设计;2. 蛋白-配体相互作用预测与分析;3. RNA结构预测与核酸药物设计;4. 多肽药物生成与优化;5. 生物大分子设计Pipeline构建 | 模型调用代码、设计案例Notebook、靶点设计示例、蛋白/多肽设计Pipeline模板 | 掌握生物大分子AI设计的核心技术,能够独立完成蛋白/核酸/多肽的设计与优化 | 蛋白工程科研人员、核酸/多肽药物研发人员、结构生物学家 | 📐 |
Module 4:大模型在药物发现中的应用 | 2.0核心升级模块 | 掌握大模型在药物发现全流程的应用方法与工程实现 | 1. 生物医药文献自动化解析与知识抽取;2. 大模型驱动的靶点发现;3. 疾病机制与药物作用原理的大模型推理;4. 自然语言驱动的分子设计;5. 生物医药领域大模型微调与应用 | 大模型调用代码、RAG实现模板、文献解析示例、靶点发现案例Notebook | 掌握大模型在药物发现中的核心应用,能够实现大模型与药物发现流程的深度融合 | AI工程师、药物研发人员、科研人员、技术负责人 | 📐 |
Module 5:AI Agent Drug Design | 系统核心突破模块 | 掌握AI Agent的架构设计、工具调用与多智能体协同机制 | 1. 药物发现场景的Agent架构设计;2. 工具调用系统实现;3. 单Agent功能开发与落地;4. 多Agent协同机制设计;5. 自动化科研系统的构建与调试 | Agent实现代码模板、工具调用示例、多Agent协同案例、系统调试指南 | 掌握AI Agent药物发现系统的核心设计与实现,能够独立开发定制化Agent | AI工程师、系统架构师、药物研发平台技术负责人、创业者 | 📐 |
Module 6:系统级项目实战 | 落地实战模块 | 从0到1完整构建AI驱动的药物发现系统,完成候选药物设计全流程 | 1. 系统架构设计与模块拆分;2. 自动化Pipeline构建与调试;3. 多模型系统接入与整合;4. 多Agent协作机制设计与落地;5. 完整候选药物设计案例实战与结果分析 | 完整系统源码、项目实战指南、全流程Pipeline示例、部署教程 | 实现从理论到落地的闭环,能够独立构建完整的AI药物发现系统,完成实际药物设计项目 | 全阶段学习者、创业者、药物研发团队技术负责人、跨领域研发人员 | 📐 |
生物智能:在生物先进产业场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能(Biology_and_AI);实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

生物产业+物理AI=生物智能
产业智能官:Science_and_AI
加入知识星球“生物智能研究院”:生物产业OT技术(自动化+机器人+工艺+精益)和新一代IT技术(云计算+物联网+区块链+大数据+人工智能)深度融合,在场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能;实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:Science_and_AI)发表的文章,除非确实无法确认,我们都会注明作者和来源,涉权请联系协商解决,联系、投稿邮箱:wolongzy@qq.com
