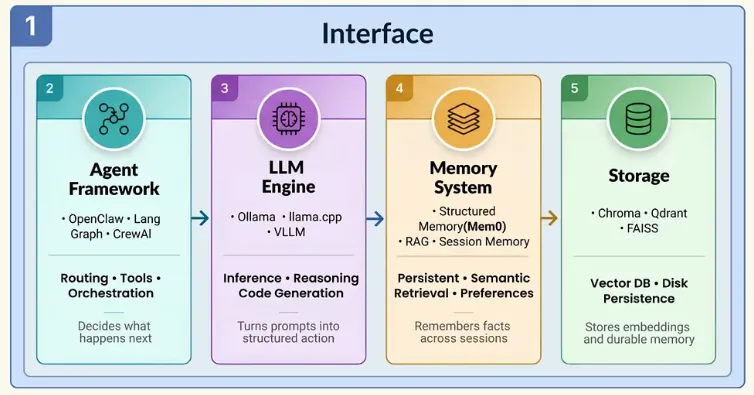
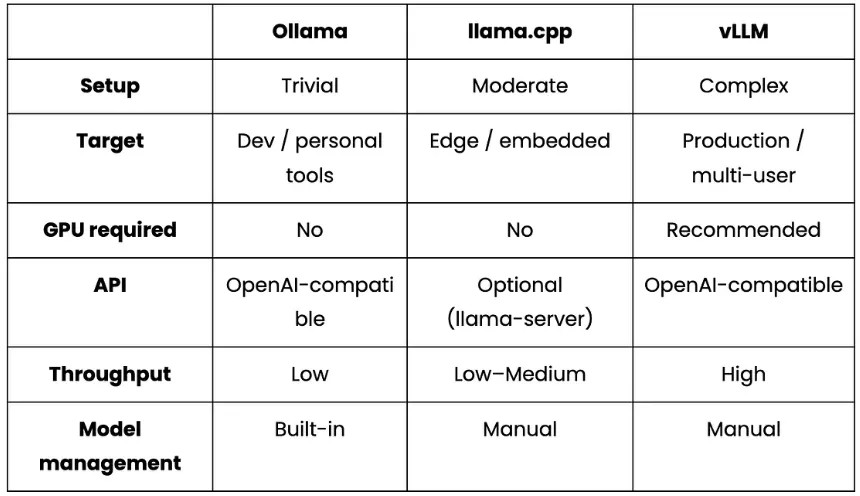
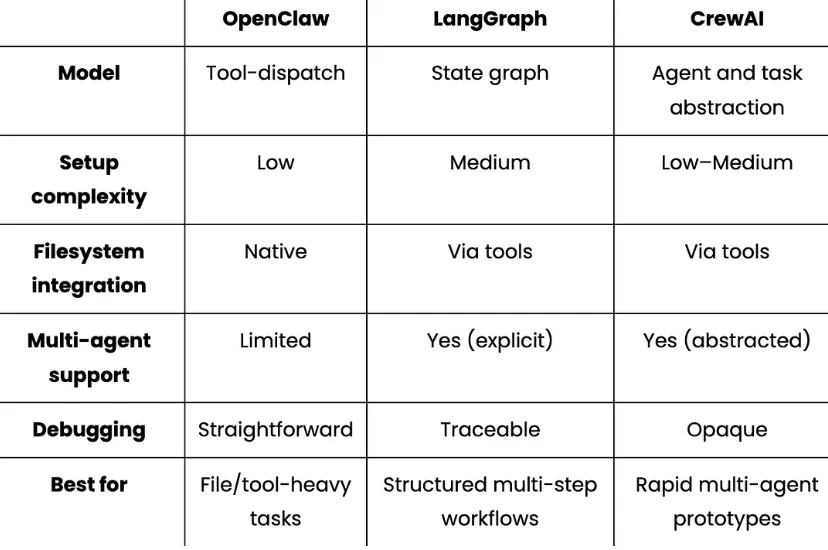
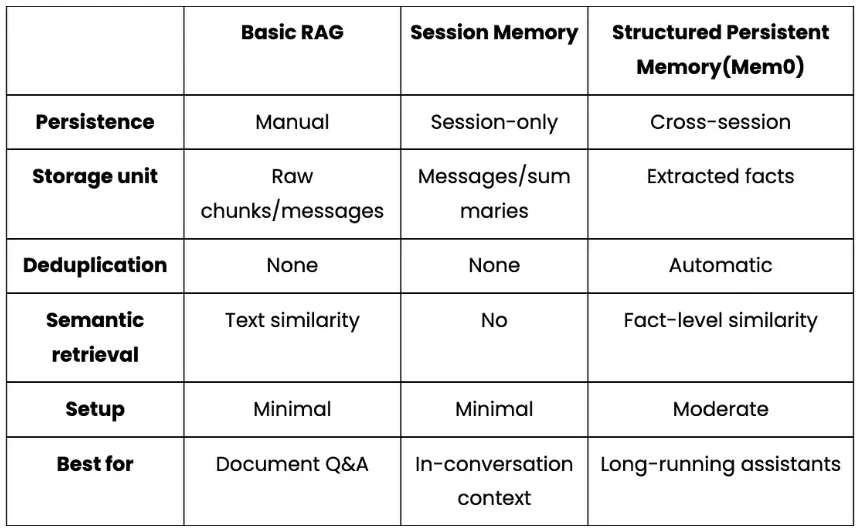
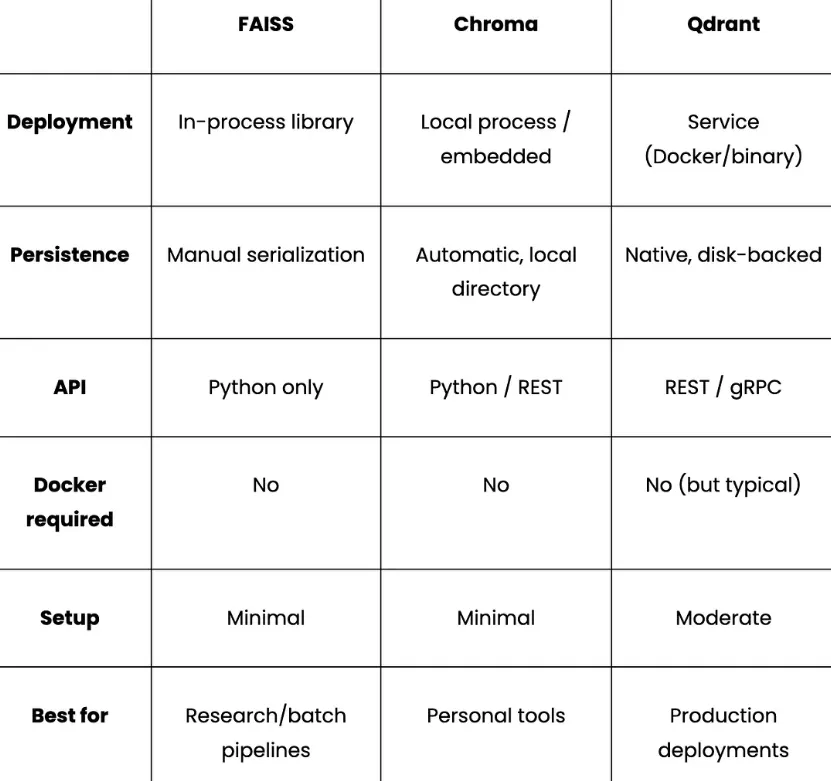
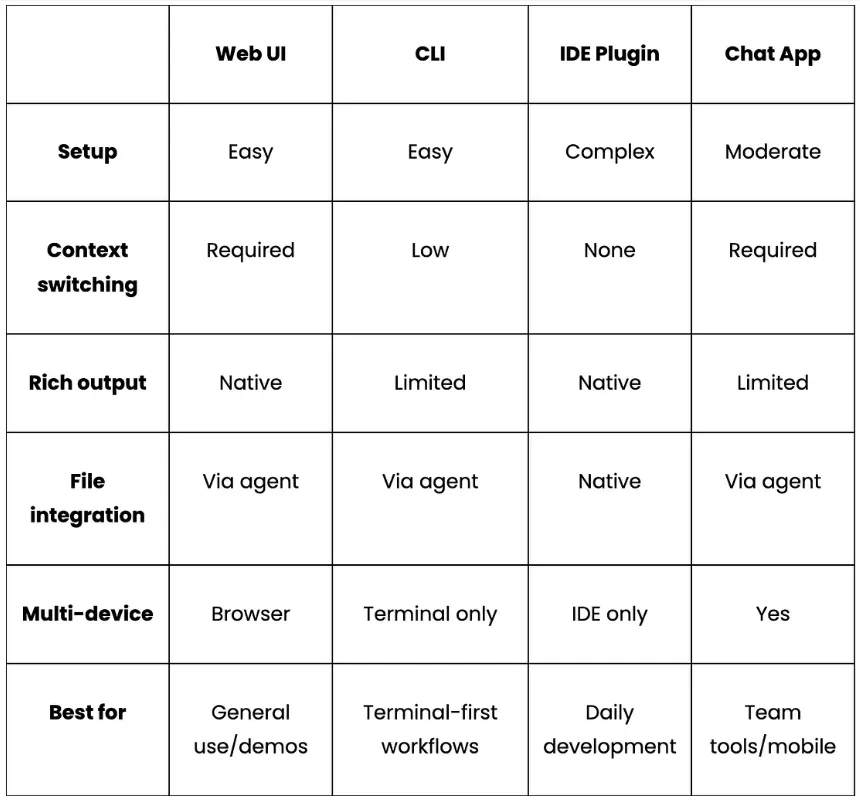
构建本地AI代理:模型、内存与编排实用指南 | 知著本地AI代理是一种系统,模型运行在您的硬件上,代表您执行操作,并在会话间保持上下文,而无需向外部API发送数据。与简单的聊天机器人会回应后忘记不同,客服可以在多个步骤中推理,使用工具,并随着时间积累知识。本地运行意味着你可以享受智能助手的好处,同时避免云托管替代方案带来的隐私权衡或API成本。构建本地AI代理需要五层:一层在硬件上运行推理的LLM层,一层负责路由和执行动作的代理框架,一层内存层让智能体随时间变得更智能,一层存储层持续保存其学习内容,以及一层连接实际工作方式的接口层。本文逐层解析,比较各种选项,并解释权衡,帮助你构建符合实际使用场景的方案。第一层:大型语言模型层这是引擎。该模型处理意图检测、代码生成以及堆栈其余部分依赖的任何结构化数据提取。其他的都是基于模型可靠能力构建的管道。主导本地推理领域的三大主要工具包括:奥拉玛: 这是进入本地推断的最简单切入点。只需一个命令安装,一个命令拉取模型,我们就能立即在localhost上运行一个兼容OpenAI的API。它还能处理模型管理、量化选择和上下文窗口,无需配置。不过,它并非为生产流量设计,更适合个人助理或开发者工具。ollama pull qwen3:8bollama pull nomic-embed-textLlama.cpp: 该库的层级比 Ollama 低一级。它是一个 C++ 推理引擎,直接运行量化的 GGUF 模型,无需任何守护进程或 HTTP 层。Llama.cpp 的内存占用极小,非常适合边缘部署如树莓派、嵌入式 Linux,以及 Ollama 过于庞大的硬件。权衡的代价是没有内置模型管理,且需要更多手动配置。vLLM:这是一个生产选项。它实现了PagedAttention和连续批处理技术,这些在云推理API中大规模使用。如果你构建的是服务多个用户或有实际吞吐量需求的系统,vLLM是合适的层。它需要完善的GPU基础设施,但比Ollama或llama.cpp更能扩展。实际上,对于单开发者本地助理来说,Ollama 是理想的默认配置,简单性优先于吞吐量。值得特别强调的是“qwen3:8b”型号,它能提供可靠的JSON意图检测,代码生成处理干净利落,并配备8GB显存。需要注意的一个特点是,它会将输出包裹成“<think>......</think>' 在返回实际内容前会被阻断,这会破坏处理原始响应的下游 JSON 解析器。修复方法是将“think: False”全局注入一个小截距:_orig_ollama_chat = ollama.chatdef _no_think_chat(*args, **kwargs): opts = kwargs.get("options") or {} if isinstance(opts, dict): opts.setdefault("think", False) kwargs["options"] = opts return _orig_ollama_chat(*args, **kwargs)ollama.chat = _no_think_chat使用“setdefault”意味着每个来电者在需要时仍可以明确选择进入思考模式。对于工具使用流程中的JSON提取和代码生成,思考模式增加了延迟,却不提升输出质量。第二层:代理框架层LLM层负责生成文本。而代理框架则决定如何处理和下一步该做什么。该层负责意图分类、动作路由和执行。OpenClaw 采用工具优先的方法,且是文件系统原生的。每个代理操作都是命令,发给声明的技能,比如创建文件、写代码、打开文件夹、运行shell命令。你写一个“SKILL.md”文件声明技能名称和调度方法,OpenClaw负责路由:- -name: local-ai-assistantdescription: Local AI coding assistant with persistent memorycommand-dispatch: toolcommand-tool: execcommand-arg-mode: raw-对于一个大部分操作是文件输入输出的编码助手来说,这种模式自然而然地契合。局限在于它不适合复杂的多步推理链或跨多个代理的协调。LangGraph 则采取相反的做法。你定义一个显式状态图,节点是 LLM 调用或动作,边是转移,框架则管理跨步骤的状态。权衡是前期设计工作,你需要先定义状态模式和图拓扑,然后再编写业务逻辑。对于简单的工具操作任务,这就是过度工程。对于复杂的多步流水线,它为你提供可追溯、可检查的每一步发生情况的记录。CrewAI通过定义带有角色的代理、描述的任务,以及框架的执行顺序和代理间通信,将抽象抽象提升到更高层次。这是实现多智能体原型最快的路径。缺点是这种抽象化使失败更难调试。实际上,OpenClaw 的“command-dispatch:tool”和“command-tool:exec”会在调用技能时告诉它切换到Python 脚本,使文件操作在框架内顺畅进行。无论你选择哪种框架,意图分类都是每个收到消息时首先执行的。带有正规表达式退回的两层LLM分类系统比单用两种方法更好地处理失败模式:def detect_intent(message: str) -> dict: try: resp = ollama.chat( model=OLLAMA_CHAT_MODEL, messages=[{"role": "user", "content": INTENT_PROMPT.format(message=message)}], options={"temperature": 0, "num_predict": 1024}, ) return extract_json(resp["message"]["content"]) except Exception: return keyword_intent_fallback(message)正则表达式的退回在LLM返回错误输出时捕捉了常见模式。关闭思考模式并保持温度为0时,LLM路径处理绝大多数请求,但后备方案是保持代理功能的关键。第三层:内存层记忆是区分适应你的代理和把每次对话都当作第一次的代理的关键。记忆有助于学习你的惯例、偏好和项目背景,并在不被要求的情况下应用它们。对于每个内存,核心问题都出在上下文内存。常见的解决办法包括启动时加载的“PREFERENCES.md”、长系统提示符、“CONTEXT.md”文件。这些都有一个共同缺陷,即它们存在于上下文窗口内,被上下文压缩、令牌限制和会话重启所抑制。然而,代理实际上需要的是存在于上下文窗口之外的内存,这些内存能持久存储,必要时语义检索,并随着事实变化不断更新。以下是一些适用于不同用例的常见内存方法:基础RAG(检索增强生成):这是最常见的方法,完全适合初学者。基本的RAG流程包括分块文档或对话历史,嵌入它们,并在查询时以最小设置方式检索最接近的顶部k块。限制在于它把内存当作文档存储,所以没有区分哪些是值得长期保留,哪些是一次性查询。会话范围内存(LangChain的“ConversationBufferMemory”、“ConversationSummaryMemory”等):这解决了会话内的一致性问题,使代理不会忘记你五条消息前说的话,摘要也能防止上下文窗口被填满。但它无法承受游戏重启。对于编程助理来说,这就是核心的差距。结构化持久存储(Mem0): 这把内存当作一类数据,而不是原始文本。系统不再逐字存储消息,而是利用LLM提取离散事实,然后将这些事实嵌入并存储到向量数据库中。检索时,查询被嵌入,即使当前消息使用的内容与存储时不同,也会返回语义相似的事实。事实会在会话间持续存在,并且可以随时间变化进行去重和更新。像 Mem0 这样的库实现了这种模式并支持本地模型,使得接线到基于 Ollama 的栈非常简单。实际上,如果你告诉一个基础的RAG系统,你更喜欢pytest,它会存储原始消息。像 Mem0 这样的结构化内存系统,会提取并存储离散偏好。下次你请求带测试的函数时,内存会返回“用户偏好pytest”,即使当前消息没有提到测试框架。将 Mem0 集成到本地 Ollama 设置中只需一个小的配置片段。你只需指向本地LLM、本地嵌入模型和选择的向量存储:from mem0 import Memoryconfig = { "llm": { "provider": "ollama", "config": {"model": "qwen3:8b", "ollama_base_url": "http://localhost:11434"}, }, "embedder": { "provider": "ollama", "config": {"model": "nomic-embed-text", "ollama_base_url": "http://localhost:11434"}, }, "vector_store": { "provider": "qdrant", "config": {"host": "localhost", "port": 6333, "embedding_model_dims": 768}, },}memory = Memory.from_config(config)memory.add("I always use type hints and pytest", user_id="dev")results = memory.search("write a utility function", user_id="dev")上述LLM块将Mem0指向“qwen3:8b”进行事实提取,将原始消息转化为离散存储偏好,而非逐字文本。嵌入模块使用“nomic-embed-text”在写入时将这些事实转换为向量,检索时嵌入查询。最后,'memory.search()' 是按意义检索内容,而不是关键词匹配。无论你的记忆方式如何,一个被低估的改进是写入存储前要过滤存储内容。你可以选择一个轻量级分类器,每次写入前运行,这样能保持内存层干净,检索质量也高。这里有一个代码片段,可以实现同样的操作:def _is_worth_storing(self, user_message: str) -> bool: response = ollama.chat( model=OLLAMA_CHAT_MODEL, messages=[{"role": "user", "content": SMART_MEMORY_PROMPT.format( user_message=user_message )}], options={"temperature": 0, "num_predict": 512}, ) data = self._extract_json_robust(response["message"]["content"]) return bool(data.get("worth_storing", False))分类器提示为模型提供了明确的区分示例:HIGH-VALUE (worth storing):- "I prefer TypeScript over JavaScript"- "I use pytest, never unittest"- "Always use Google-style docstrings"LOW-VALUE (discard):- "What does enumerate() do?"- "Write a retry decorator"- "Thanks"没有这个过滤器,向量数据库会被一次性请求填满,随着时间推移稀释检索质量。第4层:存储层记忆层决定记住什么。存储层是这些记忆实际上存放在磁盘上的。FAISS: 这是一个正在进行的库,速度快、经过良好测试,且没有基础设施依赖。所以,我们可以直接把它嵌入到Python进程中,它运行在内存中,或者序列化到磁盘。唯一的限制是操作上的,即持久化需要显式序列化调用,且没有HTTP API或内置复制。它对研究流程和批处理工作负载很有用,但对于长期运行且频繁重启的助理来说则更为脆弱。Chroma: Chroma 是开发者最简单的矢量数据库。它作为本地 Python 进程运行,并可选择嵌入式模式。数据会自动保存到本地目录。安装时只需执行以下命令:pip install chromadb对于一个拥有数千个存储信息的个人助理来说,Chroma 已经绰绰有余。它完全消除了对基础设施的依赖,但相较于Qdrant,过滤能力更为有限。Qdrant: 它作为一个正式的服务运行,暴露完整的 REST 和 gRPC API,支持有效载荷过滤和命名向量。Qdrant 设计用于部署数百万向量和并发查询。它作为独立服务运行,原生地存续到磁盘,并且在 Docker 重启后无需特殊处理即可存活:# Qdrant via Dockerdocker run -d - name qdrant-local -p 6333:6333 \-v $(pwd)/qdrant_storage:/qdrant/storage qdrant/qdrant以下是这些服务的简要比较:一个无声破坏问题的配置细节是,向量存储配置中的嵌入维必须完全匹配我们嵌入模型的输出维度。例如,“规范嵌入文本”模型产生768维向量。如果切换到不同的嵌入模型而不更新这个值,所有插入都会无声无息地失败。"vector_store": { "provider": "qdrant", "config": { "collection_name": "coding_assistant", "host": "localhost", "port": 6333, "embedding_model_dims": 768, # must match your embedding model exactly },}如果你想去掉 Docker 依赖,改配置里的“vector_store”提供者,堆栈的其他部分保持不变,Chroma 是直接交换。第5层:接口层这是堆栈的最后一层,最外层,塑造用户与代理的交互方式。合适的界面完全取决于代理在你现有工作流程中的位置。一些最常用的接口包括:网页界面: 这是本地代理最灵活的界面。它运行在浏览器中,支持格式化如 markdown、语法高亮代码、可折叠部分,并且跨操作系统无需安装即可运行。对于编码助手,网页界面可以在同一视图中并列显示当前文件、生成代码和代理的内存状态。CLI: CLI 是一种终端助理,能够自然集成到 shell 工作流中,可以将输出传输到其他工具,并且没有任何视觉开销。代价是丰富输出需要额外小心,多回合对话比聊天界面更尴尬。CLI最适合快速查找、文件操作和脚本化工作流程,比如你希望助手在现有终端会话中。IDE插件: 插件作为助手,嵌入在VS Code或JetBrains中,位于你正在编辑的文件旁边,可以看到哪个文件打开了,并内联建议编辑。权衡是 IDE 扩展需要了解特定的扩展 API,并在 IDE 更新时持续维护。作为一个每天使用的团队工具,这可能非常值得。聊天应用(Slack机器人、Discord机器人、Telegram集成):当助理需要跨设备访问或团队共享时,聊天应用很有意义。当你想通过多设备或随时随地联系客服时,聊天应用表现良好。编码助理的限制在于聊天界面并非为代码审查或文件编辑设计,但它们更适合问答、状态检查和轻量级请求。你可以通过下面的表格来理解这个比较:小结每个层级都会做出限制周围层级的决策。LLM的选择决定了代理框架调用的API形状。内存方法决定存储层需要支持什么。界面选择决定了输出格式的重要性。对于单开发者本地编码助手,最小化摩擦且保持每层可切换的栈:Interface: Web UI on localhost│Framework: OpenClaw - tool-dispatch, SKILL.md routing│LLM: Ollama for qwen3:8b(think mode disabled for JSON reliability)│Memory: Structured persistent memory with value filteringEmbeddings via nomic-embed-text│Storage: Chroma (zero infrastructure) or Qdrant (more robust)由于每一层都可以独立切换,我们可以从每个层级最简单的选项开始,随着需求增加逐步升级各个层。把Chroma切换到Qdrant,或者把Ollama切换到vLLM,不需要重建它上下的任何东西。在优化其他任何东西之前,值得早期投入的一层是内存。一个设计良好的持久内存层的适中本地模型,始终优于从零开始每个会话的更大模型。如果你想端到端运行这个栈,这里有运行本地 AI 代理流水线的完整源代码:完整源代码:https://github.com/AashiDutt/OpenClaw_Mem0_Oll本文源于数据驱动智能,仅供交流学习!END
 夜雨聆风
夜雨聆风