夜雨聆风
夜雨聆风这篇文章是官方版本VibeVoice安装指南,操作有一定的复杂度,如果你希望跳过繁琐的排坑环节,直接获取一套稳定运行的‘开箱即用’方案,我也提供付费的私有化部署与技术支持服务,欢迎通过公众号私信交流,把专业的事交给实操过的人。
VibeVoice介绍
现在的语音 AI 很多,但要做到长时间、高保真、还要像人一样有“聊天感”,其实非常难。VibeVoice 就是为了解决这些痛点而生的“全能选手”。
VibeVoice 的一项核心创新在于其采用了连续语音标记器(声学和语义),运行频率极低,仅为 7.5 赫兹。VibeVoice 的一项核心创新在于其采用了连续语音标记器(声学和语义),运行频率低至 7.5 赫兹。这些标记器在有效保留音频保真度的同时,显著提高了处理长序列的计算效率。VibeVoice 采用了一种下一个标记扩散框架,利用大型语言模型(LLM)来理解文本上下文和对话流程,并通过扩散头生成高保真的声学细节。相比传统模型,它可以像人类大脑一样,在处理长篇大论时依然保持逻辑清晰,而且合成的语音非常有“情感起伏”。
VibeVoice三大模式详解 (重点)
模式一:VibeVoice-ASR(长音频识别)
首先是 ASR 模式,也就是语音转文字。它最强的地方在于: - 超长续航:
它可以一次性处理长达 60 分钟的音频,不像普通 ASR 需要切成小段。 - 结构化输出:
它不仅能转文字,还能告诉你谁在什么时候说了什么(包含角色、时间戳和内容)。
模式二:VibeVoice-TTS(长篇多角色语音合成)
第二种是 TTS 模式。这是做播客或广播剧的神器! - 90分钟超长合成:
一次性生成 90 分钟的对话,语气前后连贯,不会断气。 - 四人同台:
支持多达 4 个不同的角色,每个人的音色、情感都极其自然,就像真人在录音室对话一样。
模式三:VibeVoice-Streaming(实时流式 TTS)
最后是 Streaming 模式,专为实时交互设计的“轻量版”。 - 极低延迟:
它的模型参数只有 0.5B,首字响应时间低于 300 毫秒。 - 边打字边说话:
支持流式文本输入,你可以像聊天一样输入,它会实时生成语音,非常适合给 AI 助手当“嘴巴”。
本地安装部署
git clone https://github.com/microsoft/VibeVoice.gitconda create -n vibevoice python=3.10 -yconda activate vibevoice安装pytorch
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu130安装依赖
pip install -e .模型下载
网盘链接:https://pan.quark.cn/s/170ef8889bae下载模型,把models文件放到项目根目录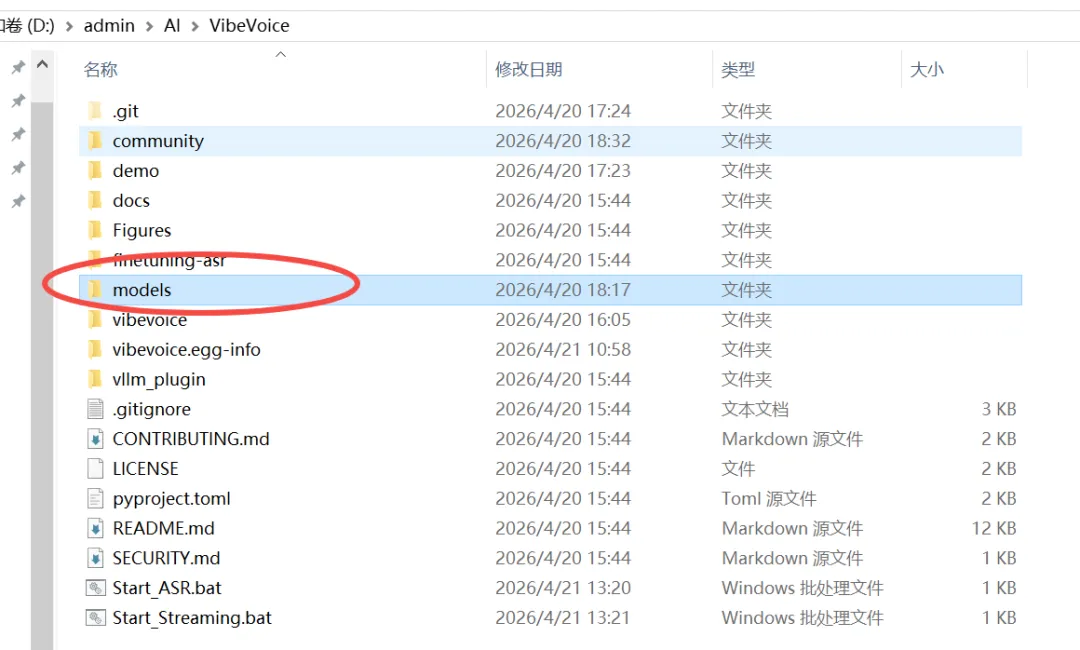
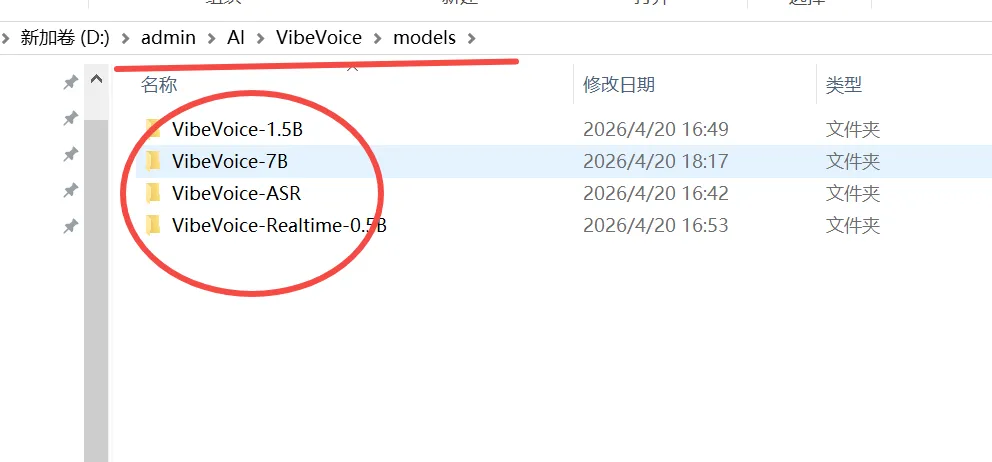
也可使用命令进行模型安装,如果已下载上面网盘模型,此步骤可跳过,仅仅作为笔记存在语音转换为文字(Speech-to-Text)模型
huggingface-cli download microsoft/VibeVoice-ASR --local-dir ./models/VibeVoice-ASR --local-dir-use-symlinks False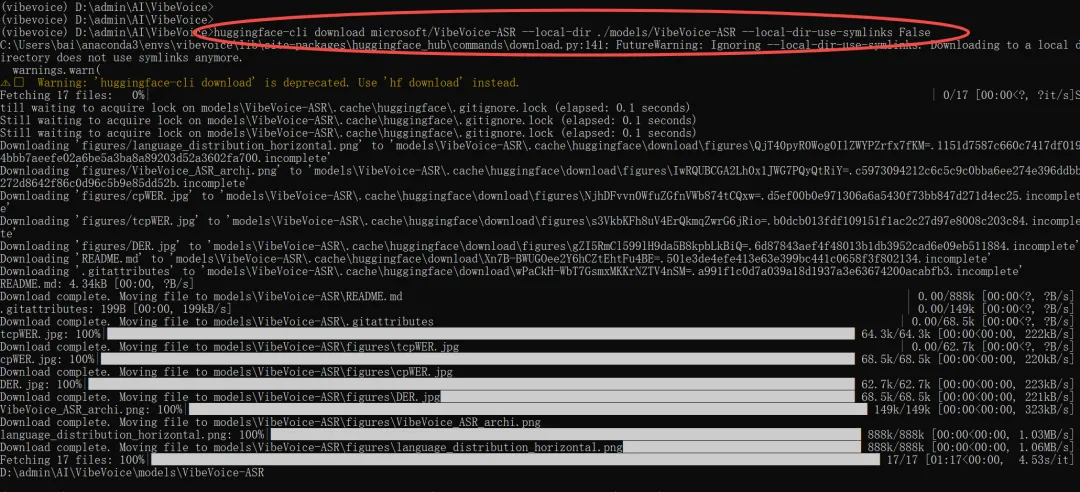
将文字转换为语音(Text-to-Speech)1.5B模型
huggingface-cli download microsoft/VibeVoice-1.5B --local-dir ./models/VibeVoice-1.5B --local-dir-use-symlinks False7B模型
huggingface-cli download vibevoice/VibeVoice-7B --local-dir ./models/VibeVoice-7B --local-dir-use-symlinks False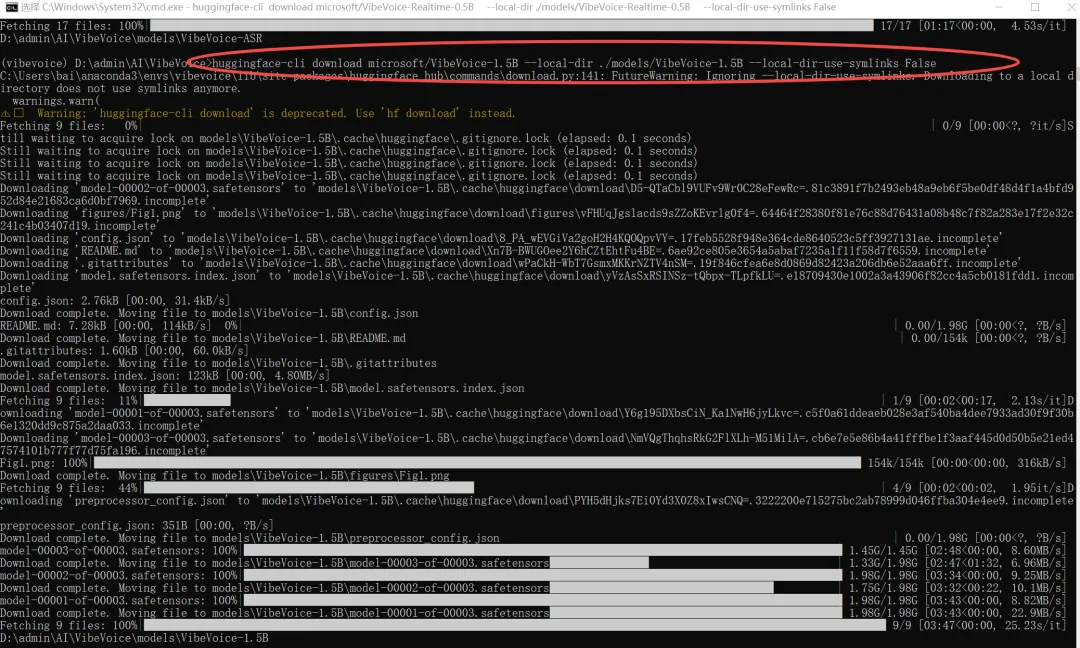
实时文本转语音(首次语音输出的延迟约为300毫秒)
huggingface-cli download microsoft/VibeVoice-Realtime-0.5B --local-dir ./models/VibeVoice-Realtime-0.5B --local-dir-use-symlinks False
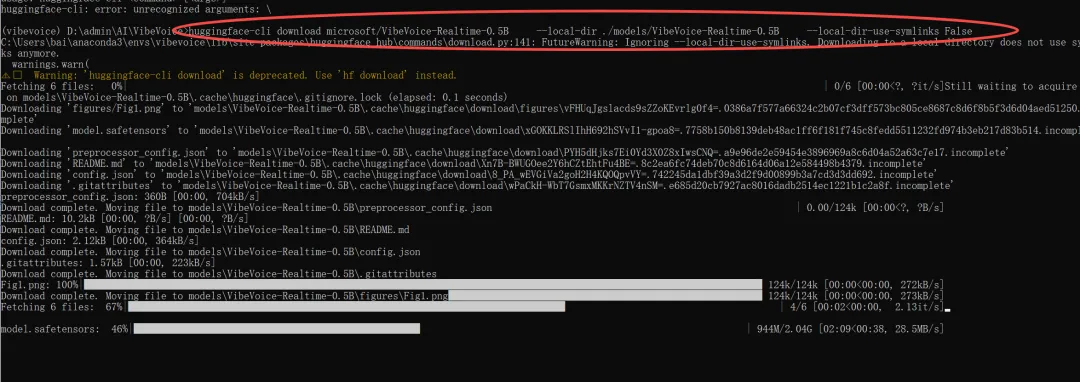
启动ASR语音转文本
在网盘里已编写了启动bat,双击运行
也可使用命令启动 ASR Demo:
python demo/vibevoice_asr_gradio_demo.py --model_path ./models/VibeVoice-ASR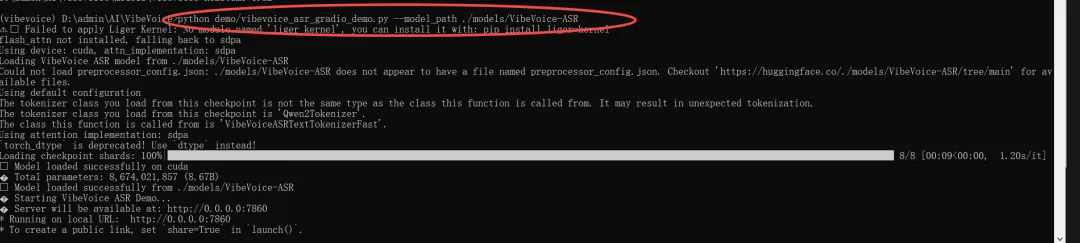
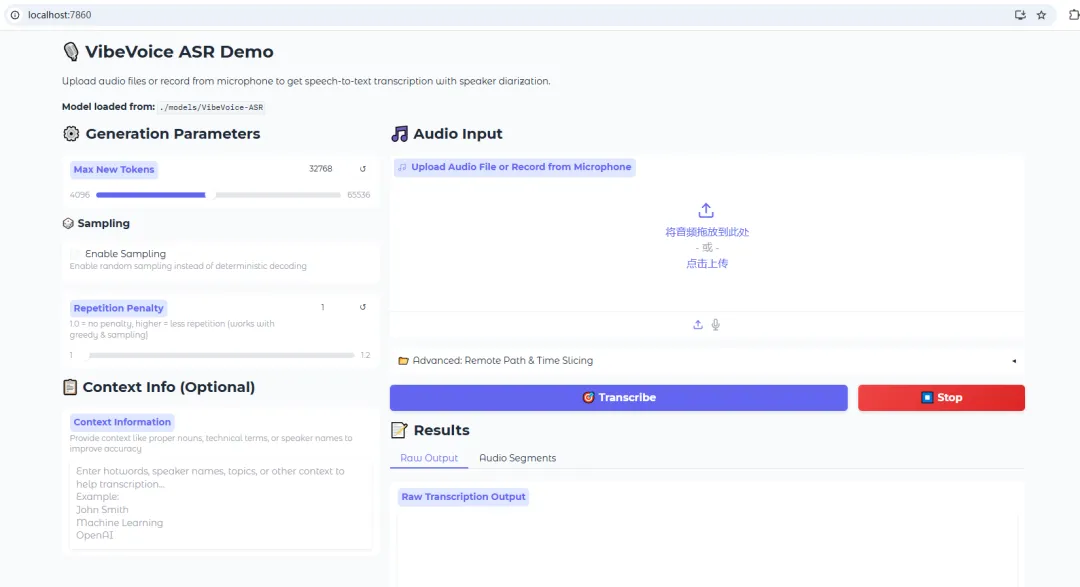 显存占用情况
显存占用情况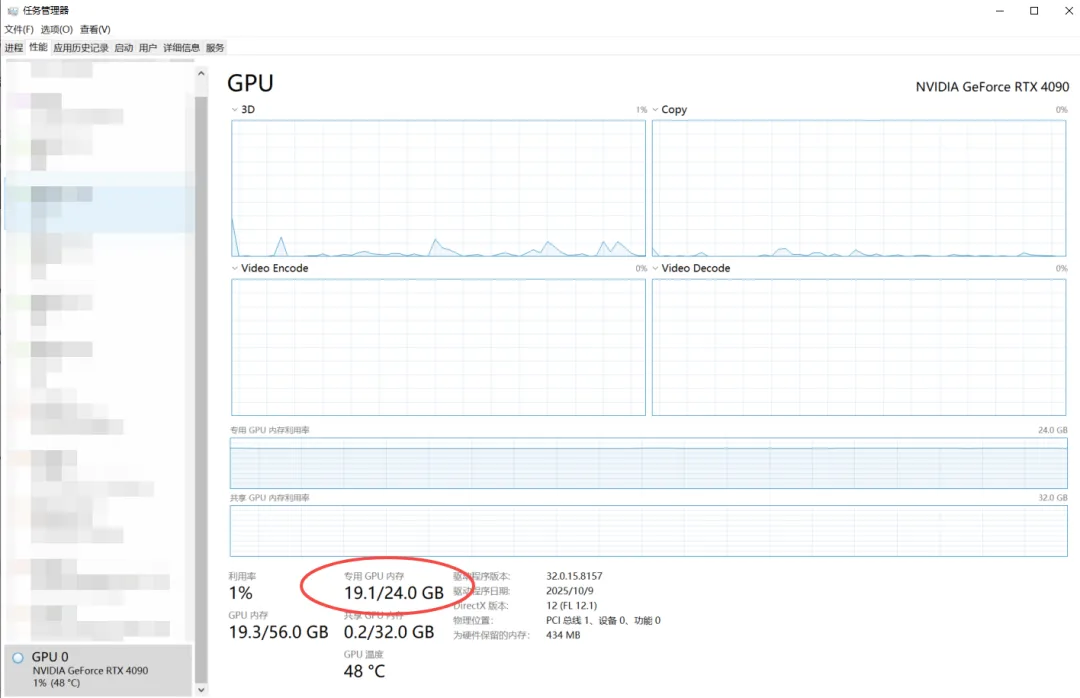 使用中显存占用情况
使用中显存占用情况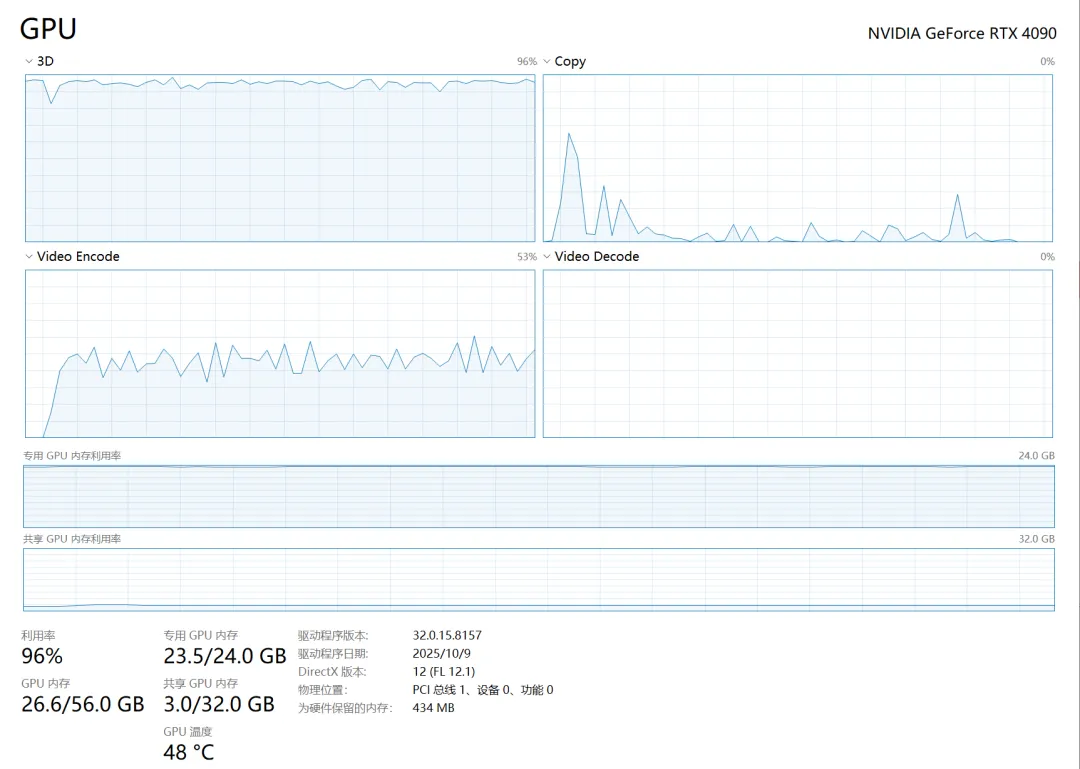
实时文本转语音Streaming启动
在网盘里已编写了启动bat,双击运行
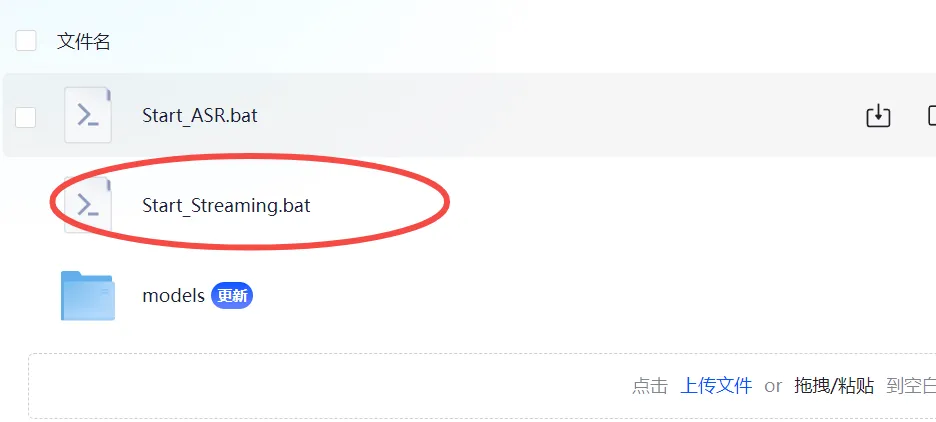
也可使用命令进行启动
python demo/vibevoice_realtime_demo.py --model_path ./models/VibeVoice-Realtime-0.5B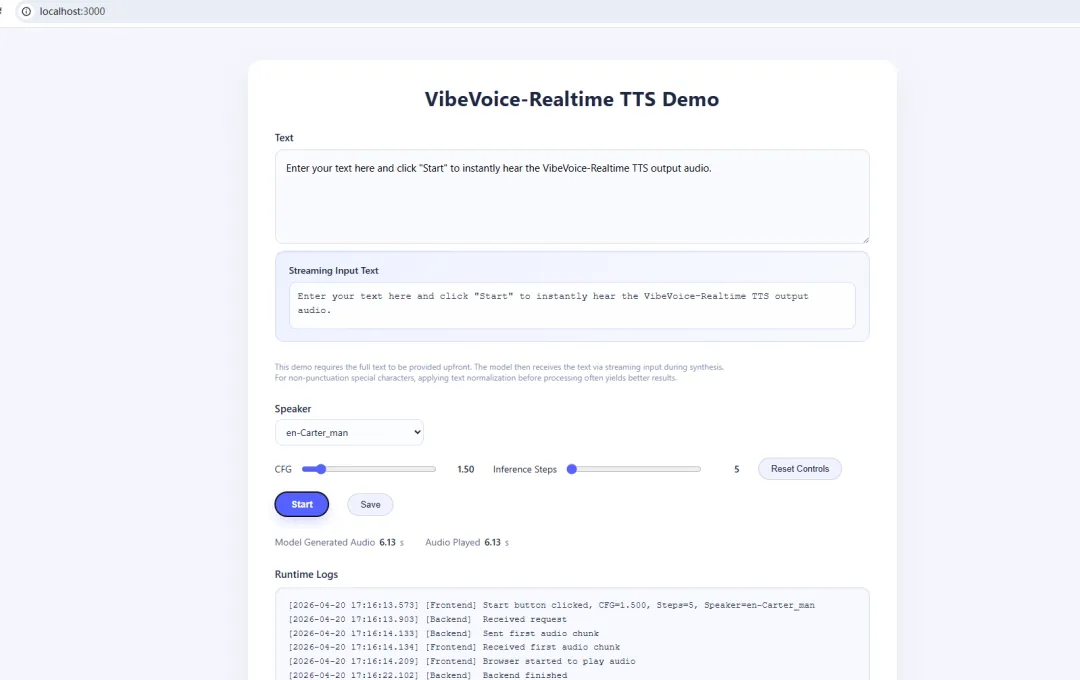 显存占用情况
显存占用情况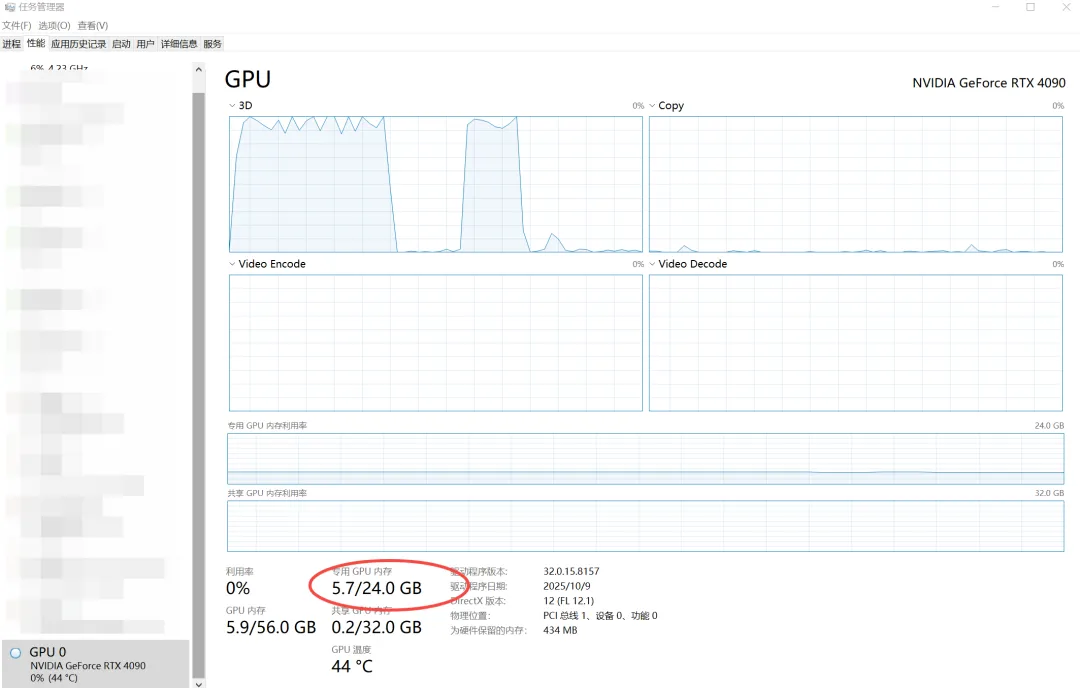
文本转语音TTS启动
python demo/gradio_demo.py --model_path ./models/VibeVoice-1.5B这里直接报错了,因为被滥用,所以官方去掉了这个程序,具体文档见https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-tts.md