 夜雨聆风
夜雨聆风最近被问了很多次:公司想用大模型处理文档,合同、报表、各种扫描件,怎么搞?
说实话,这事儿没有标准答案。但有一套我自己跑通过的方案,今天拿出来聊聊。
用三个目前最主流的开源OCR模型,加上vLLM推理服务,搭一套多模态PDF解析系统。既能单独跑,也能接大模型做智能体。
企业AI落地,文档解析是绕不开的坎
这事儿我之前低估了。
企业里大量数据都在PDF里,扫描件、财务报告、合同、技术手册,五花八门。大模型再强,如果把这些文档的内容读错了,后面的问答、审核、分析全白搭。
传统OCR遇到复杂表格、公式、手写字,翻车是家常便饭。但现在新一代基于视觉大模型(VLM)的OCR工具不一样了,文字、表格、公式、图像一起识别,直接输出结构化的Markdown,大模型拿来就能用。
PDF解析的质量,某种程度上就是企业AI项目的天花板。
三个开源OCR,到底选哪个?
目前跑得比较好的三个项目:
MinerU,上海AI Lab出的,专门优化了"干扰信息过滤"。网页型PDF、带大量广告的文档,用这个效果最好,综合准确率大概在92-95%。
DeepSeek OCR,DeepSeek开源的文档解析模型。最大特点是"视觉压缩",识别精度没怎么牺牲,但算力消耗降下来了不少,速度和性能平衡得挺好。
PaddleOCR VL,百度飞桨团队随PaddlePaddle 3.3一起发的,0.9B的多语言OCR模型。公开榜单上成绩不错,中文场景支持很强。
问题来了:这三个到底哪个最好?
老实说,不知道。或者说,要看你的数据。
榜单数据有时候会针对评测集训练,拿到你自己的私有数据上跑,效果可能差很多。我见过好几个案例,某个模型在榜单上排第一,但用户拿自己的表格一测,发现识别率很糟糕。
所以实际做企业项目,通常的做法是:三个都部署,在自己的数据上跑一遍,再决定用哪个。
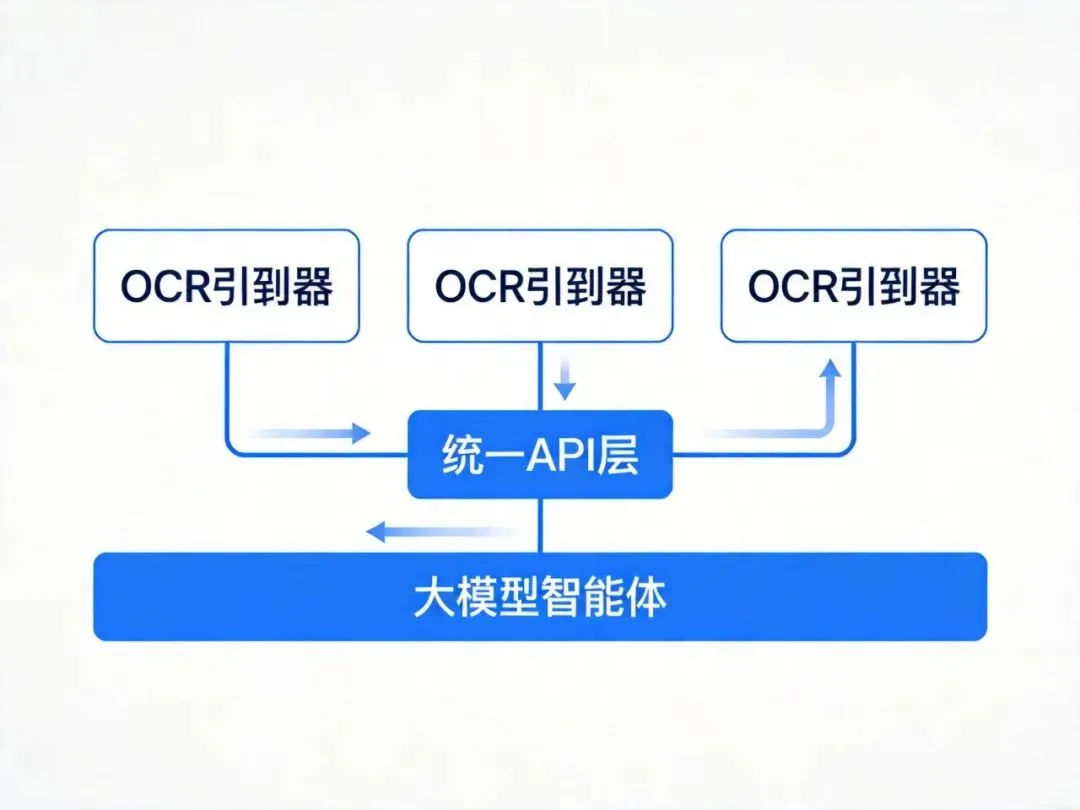
统一接口:三个模型,一套API
三个模型在后端用vLLM推理框架启动服务(速度快、显存占用小),前端统一一个接口对外。
上传PDF之后,界面上直接选"MinerU"、"DeepSeek OCR"还是"PaddleOCR VL",后端去调对应的服务,结果实时返回。
这样做有个好处:切换模型只改一个参数,业务代码完全不用动。哪天又出了个更好的OCR,换起来也不麻烦。
下面这张图是整体的架构思路:三个OCR引擎共用一套统一API,上层业务系统不用关心底层用的哪个模型。
接入LangChain + MCP,让OCR变成智能体的工具
有OCR服务还不够,至少在企业场景里不够。
文档处理通常是一条流水线:上传合同 → OCR解析 → 提取关键条款 → 合规审核 → 输出报告。每一步都要连起来,不可能手动操作。
LangChain 1.0已经支持MCP协议了,可以把OCR服务封装成Agent能调用的"工具"。审合同的Agent碰到附件PDF,自动调OCR工具解析,然后继续往下推理,全程不用人工介入。
整个链路:文档上传 → OCR解析 → 结构化数据 → 大模型推理 → 结果输出,一气呵成。
代码和部署方案可以直接领
上面这套系统的完整源码,包括三个OCR模型的本地部署流程、统一API接口代码,还有LangChain + MCP的接入示例,都整理好了。
文档智能体这个方向,我觉得是目前企业AI里最接地气的落地场景之一。如果你也在做类似的事,欢迎交流。
