夜雨聆风
夜雨聆风目标:将扫描版PDF(即图片格式,无法直接复制文字)文件,原格式转换成可编辑的Word (.docx) 文件。
实现思路:
PDF转Word通常做法是,将PDF转成文本,然后根据要求的Word格式,对文本进行修改,但有的时候PDF格式是各种各样的,可能字体、颜色、大小不一样,没有针对每个PDF生成原格式的Word。
下面我介绍一下我实现的思路:
拆PDF:将PDF的每一页,都变成一张清晰的图片;
转HTML:让AI识别图片上面所有内容,包含文字、字体、表格、标题,将内容以HTML格式输出;
转Word:用电脑上的Word软件打开HTML文件,然后“另存为” .docx 格式。
(温馨提示,Word也可以打开HTML文件)
还是老规矩,只展示最核心的、能跑通的代码,方便理解每一步在干什么。如果不想看过程,可以直接跳至文末,获取完整代码。
准备工作:
使用工具:Python
用到的库:os , requests , base64 , fitz (注意:安装时是 pip install pymupdf ),win32com (用于操作Word,安装命令: pip install pywin32 )
这里用到了两个大模型,都有免费token:
qwen-vl-max,来自阿里云百炼平台,负责看图识字并生成HTML。你需要去百炼平台申请一个API密钥。没有用OCR大模型,主要因为OCR大模型在生成HTML的时候效果不行
Qwen3-8B,用的是硅基流动的平台,负责检查和修正HTML格式。你也需要去相应平台申请API密钥。
如果嫌麻烦也可以用同一个平台的,只不过可能要花钱。
代码实现
import os#负责打开或者删除文件import requests#调用大模型import base64#将图片转成字符串,方便传输import fitz#将PDF分割成图片import win32com.clientdef pdf_to_image(pdf_path, total_pages):"""用PyMuPDF将PDF转为图片"""doc = fitz.open(pdf_path)for page_num in range(total_pages):page = doc[page_num]# 直接指定输出为 A4 尺寸 + 300DPIpix = page.get_pixmap(dpi=300,clip=fitz.Rect(0, 0, 595, 842) # 595×842 = A4 标准点数)temp_img = f"temp_{page_num}.png"pix.save(temp_img)doc.close()def image_to_html(image_path):#将图片转成字符串with open(image_path, "rb") as f:b64 = base64.b64encode(f.read()).decode("utf-8")"""调用qwen-vl识别图片,输出HTML格式"""resp = requests.post("https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions",headers={"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"},json={"model": MODEL,"messages": [{"role": "user","content": [{"type": "text", "text": "请识别这张图片中的所有内容,保持所有原格式和结构,以标准HTML格式输出。注意:保留标题层级、段落、列表、表格列宽和行高、不同段落的字体和颜色等格式。只输出HTML代码,不要有其他说明。"},{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{b64}"}}]}],"temperature": 0.1,"max_tokens": 4096},timeout=120)#提取转化内容raw_content=resp.json()["choices"][0]["message"]["content"]#print(raw_content)clean_text = raw_content.replace("```html", "").replace("```", "").strip()return clean_textdef html_bz(html_txt):API_KEY_Q = "硅基流动的KEY"MODEL_Q = "Qwen/Qwen3-8B"TSC= html_txt +'/n'+'你自己不要做额外修改,不要改变文本顺序,不要改变表格颜色和行高,如果html格式不符合word要求,只修改html格式即可,直接输出html代码,其他不要输出'resp = requests.post("https://api.siliconflow.cn/v1/chat/completions",headers={"Authorization": f"Bearer {API_KEY_Q}", "Content-Type": "application/json"},json={"model": MODEL_Q,"messages": [{"role": "user","content": TSC}],"temperature": 0.0,"max_tokens": 4092,"stream": False # 显式关闭流式输出},timeout=180)#提取转化内容html_f=resp.json()["choices"][0]["message"]["content"]return html_fdef html2word(OUTPUT_HTML,OUTPUT_WORD):# 获取当前文件夹路径(你的 .py 文件所在目录)current_dir = os.path.dirname(os.path.abspath(__file__))# HTML 路径html_path = os.path.join(current_dir, OUTPUT_HTML)# 最终要保存的 docx 路径(明确指定)docx_path = os.path.join(current_dir, OUTPUT_WORD)# 启动 Word 应用word = win32com.client.Dispatch("Word.Application")word.Visible = False # 隐藏 Word 窗口(True 则显示)# 新建文档doc = word.Documents.Add()try:# 打开 HTML 文件doc = word.Documents.Open(html_path)# 另存为 .docx 格式doc.SaveAs2(docx_path,16) # 16 = wdFormatXMLDocument (.docx)doc.Close()print(f"通过 Word 客户端另存为成功:{OUTPUT_WORD}")finally:# 关闭 Word 应用word.Quit()# 核心流程:PDF转图片→ 逐页解析 → 合并HTMLif __name__ == "__main__":# 核心配置(替换为你的信息)API_KEY = "阿里云百炼的KEY" # 在百炼控制台获取MODEL = "qwen-vl-max"PDF_PATH = r"D:\测试.pdf" # 待解析PDFOUTPUT_HTML = "output.html" # 输出html文件OUTPUT_WORD = "output.docx"#另存为docx文件#获取PDF总页数doc = fitz.open(PDF_PATH)total_pages = len(doc)doc.close()pdf_to_image(PDF_PATH, total_pages)print("完成PDF转图片")# 2. 逐页解析html_content = ''for page_idx in range(total_pages):# 转图片img_path = f"temp_{page_idx}.png"#输出htmlpage_html = image_to_html(img_path)html_content +='\n' + page_htmlprint(f"解析完第{page_idx+1}页")# 删除临时图片os.remove(img_path)# 3. 将非标准HTML转成标准HTML,并保存成html文件html_content = html_bz(html_content)with open(OUTPUT_HTML, "w", encoding="utf-8") as f:f.write(html_content)#4.HTML文件转WORD文件html2word(OUTPUT_HTML,OUTPUT_WORD)print(f"解析完成!结果已保存至 {html_content}")
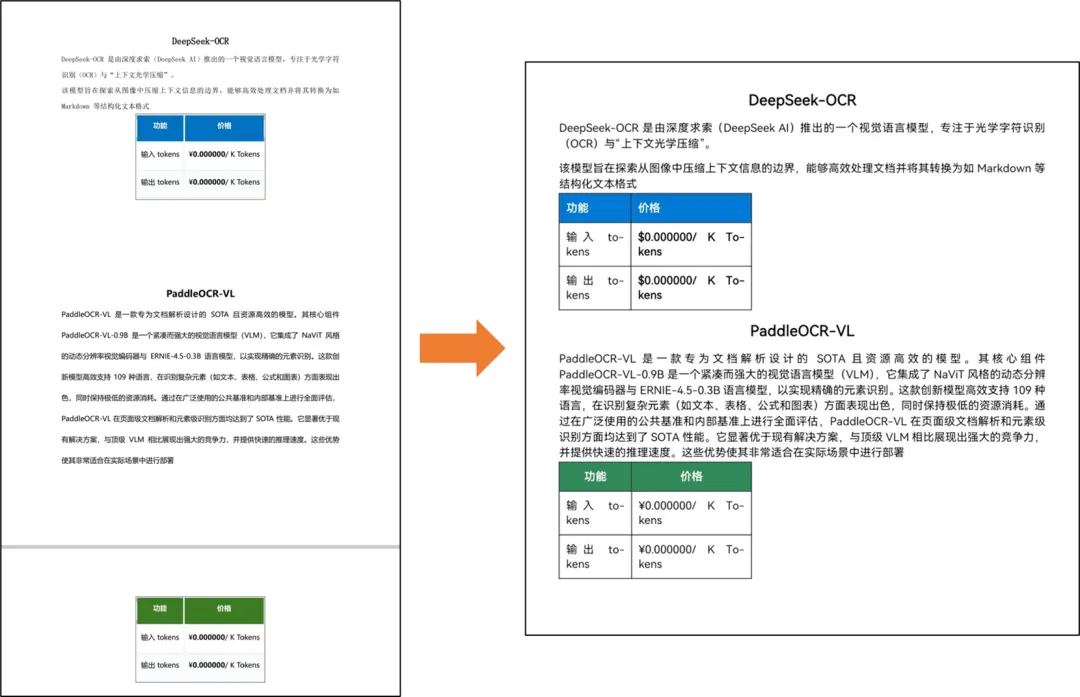
效果展示
左边是原PDF,右边是输出的word