 夜雨聆风
夜雨聆风概述
在项目目录 openspec init
在你的IDE里,执行 /opsx-propose 一句话需求描述,spec自动分析为什么要这么做、需求和场景是什么、技术方案定义和实施任务清单,并在changes目录生成相关规范文档
/opsx-apply 根据changes目录的规范文档,逐条开发,直到全部任务清单都被完成
/opsx-archive 将本次需求归档到archive目录下,需求开发完毕
本文通过openspec进行实践,只用了20分钟 + 3美金的成本,就实现了多渠道新闻聚合功能,类似早期版本今日头条。
故事
从去年4月开始付费使用Windsurf算起,正式开始使用Agent产品已经超过一年。这一年来,随着Agent产品和大模型技术的不断发展,Agent可以做的事情越来越多,从早期只用来生成一些测试脚本,到现在可以把大型项目完全交给Agent去生成,这进步速度简直太快了。
虽然现在Agent已经强大无比,但是在平时工作中,还是有一小部分事情我是习惯由人来完成,而不交给AI。就是整体技术架构设计和产品的需求管理工作。产品目录可能类似如下结构:
.├── 01.brd 商业需求文档├── 02.mrd 市场需求文档│ ├── ca 竞品分析│ ├── users 用户分析├── 03.prd 产品总体需求说明├── 04.version 版本需求说明│ ├── v1.0.0.md│ ├── v1.0.1.md├── 05.technology 产品技术架构设计├── 06.operation 产品运营├── src 源代码,交给AI├── Makefile 管理整体构建和发布
姑且给我在使用的这种工作方式,称为“古法Agent开发”。
除了src源代码部分全部交给AI,其他部分还是由人来把握。因为在实践中发现,AI哪怕有了memory,但是实际做事的时候还是容易跑偏和缺乏宏观视野,解决技术和产品细节问题的时候往往会忽略战略方向和原则。如果源代码已经完成落地,再进行大幅调整,不仅仅会危害技术架构(缺乏整体规划的反复局部修改会导致技术架构腐化),还会导致巨幅的token消耗,直接推高产品的研发成本。
把这些产品研发中核心的工作继续交给人来掌控,可以在每个版本开发工作结束的时候,要求AI评估是否跑偏。例如为满足当前版本需求修改了接口,那所有调用该接口的代码和设计要统一进行修改并确保通过单元测试;例如已经被战略规划为付费功能的功能点,就不能在开发免费功能的时候顺手给开发进免费功能里。这些都是在实践中实际踩过的坑。
Agent现在可以独立接手全部代码工作,已经是时代的巨大进步,人只掌握核心的原则和方向,这把人从代码细节中解放出来,可以进行更宏观的思考,是人力资源的巨大解放。等于是,人的价值被提高了。
Openclaw火爆之后,网络上流传一句话,叫做“所有需要坐在电脑前的工作都会被AI取代”。
程序员的工作已经被取代了。Agent让人人都是程序员、人人都是产品经理成真。
刚刚把产品研发中剩余的那部分“核心”工作体系化、标准化,忽然发现了openspec这个产品。
试用了一下,发现,AI接管了所有代码工作之后,所谓的剩余的那部分“核心”工作,AI也已经完全可以接管了。
那些“核心”工作,目前的实际做法,往往是自己或者团队构思框架,然后和AI反复沟通讨论确认后的产品的市场定位、商业模式、功能需求定义、技术架构。这些事情,其实你只要提供足够充分的输入,AI已经可以独立完成。
下面来看看 OpenSpec 如何完成这些工作。
OpenSpec是什么
OpenSpec官网对自己的介绍是: 面向人工智能编码助手的规范驱动开发(SDD)。 AI 编码助手功能强大,但如果需求仅存在于聊天记录中,则其表现难以预测。OpenSpec 添加了一个轻量级的规范层,让您在编写任何代码之前就对要构建的内容达成一致。
OpenSpec是一个基于"规格驱动开发(Spec-Driven Development)“的工具,简单来说,就是给AI编程工具(OpenCode、Claude Code、Cursor、Windsurf等)装上的一套工作流骨架,在简单地只完成编码工作的基础上,增加了一套规范来提高研发的准确度。
它的核心就三个命令:
/opsx-propose <需求>:AI自动在 openspec/changes/<变更名>/ 下生成一整套规范文档
proposal.md:为什么要做(动机、范围、影响)
design.md:技术方案与取舍
specs/:结构化需求与验收场景
tasks.md:可勾选的实施任务清单
/opsx-apply:AI按照规范逐条实现任务,实时更新 tasks.md 的勾选状态
/opsx-archive:完成后把变更归档到带时间戳的目录,并把增量规格同步到主规格库
这套流程带来的直接好处是:
需求可审查:AI不是直接动手,而是先给你一份文档,你可以改、可以否
过程可追踪:每个任务都有明确状态,不会"黑盒跑飞”
结果可归档:每次变更都沉淀成规格文档,项目越大越有价值
OpenSpec如何做
传统Agent的问题,是缺少一个让人和AI先把"要做什么"对齐的环节。这在过去,是通过人在开发开始之前,和AI反复沟通达成,也就是“古法Agent开发”中,由人来完成的那些事情。
OpenSpec 就是来解决“古法Agent开发”中最后剩余的那一点还需要人来的工作这件事的。它把软件开发拆成三个阶段:提案(Propose)、实施(Apply)、归档(Archive),每一步都有明确产物,每一步你都能介入修改。AI从一个容易跑偏的代码生成器,进化成一个按规范办事的协作者。

下面把OpenSpec的完整工作流实际跑一遍,看看它到底能把"需求→设计→实现→验证"这条链路压缩到什么程度。
也看看未来的软件开发,还需要人吗?
安装
一句话安装OpenSpec:
npm install -g @fission-ai/openspec@latest在你的项目目录下初始化,这里我们假设自己要做一个美伊战争实时消息的新闻聚合系统,为明确这是openspec的实验项目,起个目录名就叫spec:
mkdir -p speccd specopenspec init
初始化时会让你选择开发工具(OpenCode、Claude Code、Cursor等),OpenSpec会以Skill(技能)的形式安装到你选择的工具里。之后所有操作都在开发工具里进行,直接用 /opsx-propose、/opsx-apply、/opsx-archive 这几个斜杠命令即可。
实战:从零构建一个新闻聚合系统
本次实战使用 GLM-5.1 @ OpenRouter,全流程消费约 $3。为了可读性,对部分AI输出做了中文翻译并省略了冗余内容。
第一步:提案(Propose)——让AI把需求写清楚
注意:官方文档中Propose写法是/opsx:propose,但实际环境中有的支持官方写法,更多的是用减号连接的命令/opsx-propose,具体写法可以输入前缀,看看提示出来的写法是什么,按照提示建议的语法来写即可
现在你就是你的老板,对AI下达一个一句话的任务:
/opsx-propose "获取美伊战争的最新消息"OpenSpec会自动在 openspec/changes/us-iran-war-news/ 下创建整套规范文档。下面是AI的完整思考与产出过程:
/opsx-propose "获取美伊战争的最新消息"Thinking: 用户要求我使用“OpenSpec 提议”技能提出一项新的变更。主题是“获取美伊战争的最新消息”,意思是“获取有关美伊战争的最新消息”。让我先加载“openspec-propose”技能。→ Skill "openspec-propose"Thinking: 用户想要就“获取美伊战争的最新消息”(Get the latest news about the US-Iran war)提出一项变更。让我按照技能步骤进行操作。首先,我需要从描述中提取一个驼峰命名法的名称。比如 us-iran-war-news 或者 get-us-iran-war-latest-news。让我先创建变更目录。...# Todos[•] Create proposal.md artifact[ ] Create design.md artifact[ ] Create specs artifacts[ ] Create tasks.md artifact[ ] Show final status# Get proposal artifact instructions$ openspec instructions proposal --change "us-iran-war-news" --jsonThinking: 现在我需要研究一下这个项目的内容,以便了解其背景情况。同时,我还要查看现有的规格目录和项目结构。此外,用户想要“获取美伊战争的最新消息”(获取有关美伊战争的最新资讯)。...# Todos[✓] Create proposal.md artifact[•] Create design.md artifact[ ] Create specs artifacts[ ] Create tasks.md artifact[ ] Show final status# Check status after proposal$ openspec status --change "us-iran-war-news" --json# Get design artifact instructions$ openspec instructions design --change "us-iran-war-news" --json# Get specs artifact instructions$ openspec instructions specs --change "us-iran-war-news" --jsonThinking: 现在我需要创建 design.md 文件以及相关规格说明。该提案明确了三项功能:1. news-fetcher - 从多个新闻源获取美伊战争相关新闻数据2. news-processor - 对原始新闻进行结构化处理、摘要生成与事件分类3. news-query - 提供按时间、类别、关键词查询最新美伊战争动态的接口I can create both the design.md and the specs in parallel since they both only depend on proposal.md (which is done).Let me create them all.现在 design 和 specs 都已就绪 — 正在并行创建它们。...# Wrote openspec/changes/us-iran-war-news/specs/news-fetcher/spec.md## ADDED Requirements### Requirement: 多源新闻抓取系统 SHALL 支持从多个新闻源(REST API、RSS feed)抓取美伊战争相关新闻数据,包括国际通讯社、主流英文媒体和中文新闻源。#### Scenario: 成功从 API 新闻源抓取数据- **WHEN** 系统按配置的轮询间隔向已注册的 API 新闻源发起请求- **THEN** 系统返回该源的最新新闻条目列表,每条包含标题、正文摘要、发布时间、来源标识和原始 URL#### Scenario: 成功从 RSS 新闻源抓取数据- **WHEN** 系统按配置的轮询间隔解析已注册的 RSS feed- **THEN** 系统提取 feed 中的新闻条目,解析为标准化的新闻数据格式#### Scenario: 新闻源不可用时的降级处理- **WHEN** 某个新闻源请求失败(超时、HTTP 错误、解析异常)- **THEN** 系统记录错误日志,跳过该源继续处理其他源,不影响其他新闻源的抓取### Requirement: 新闻数据标准化系统 SHALL 将不同来源的原始新闻数据转换为统一的结构化格式,包含标题、正文摘要、发布时间、来源标识、原始 URL、抓取时间戳。#### Scenario: 不同格式新闻的标准化- **WHEN** 系统收到来自 API 和 RSS 两种不同格式的原始新闻数据- **THEN** 系统将两种格式的数据均转换为统一的结构化对象,字段完整且类型一致### Requirement: 定时轮询调度系统 SHALL 支持对每个新闻源配置独立的轮询间隔,并按间隔自动执行抓取任务。#### Scenario: 按配置间隔轮询- **WHEN** 新闻源 A 配置的轮询间隔为 15 分钟,新闻源 B 为 30 分钟- **THEN** 系统分别按 15 分钟和 30 分钟的间隔对 A 和 B 发起抓取请求### Requirement: 请求频率控制系统 SHALL 实现请求频率控制与退避策略,避免因高频请求被新闻源限流或封禁。#### Scenario: 触发限流后的退避- **WHEN** 新闻源返回 429 状态码或响应头中包含限流信息- **THEN** 系统对该源执行指数退避策略,暂停请求并逐步恢复### Requirement: 新闻去重系统 SHALL 对抓取到的新闻进行去重处理,避免同一事件的不同源重复报道被重复存储。#### Scenario: 基于标题相似度的去重- **WHEN** 两条新闻发布时间在 24 小时内,且标题相似度超过阈值(默认 0.8)- **THEN** 系统将较晚抓取的新闻标记为重复,不重复存入主数据#### Scenario: 不同事件不被误合并- **WHEN** 两条新闻标题有部分相似但实际描述不同事件- **THEN** 系统将两条新闻均保留,不进行合并...# Check status after design and specs$ openspec status --change "us-iran-war-news" --json# Get tasks artifact instructions$ openspec instructions tasks --change "us-iran-war-news" --json# Wrote openspec/changes/us-iran-war-news/tasks.md## 1. 项目初始化与基础架构- [ ] 1.1 初始化 TypeScript + Node.js 项目,配置 tsconfig、ESLint、Prettier- [ ] 1.2 安装核心依赖(axios、cheerio、rss-parser、better-sqlite3、类似度计算库)- [ ] 1.3 定义新闻数据标准类型(NewsItem 接口:标题、摘要、发布时间、来源、URL、类别、关键要素等)- [ ] 1.4 初始化 SQLite 数据库,创建新闻存储表(含去重标记字段)和新闻源配置表## 2. 新闻抓取模块 (news-fetcher)- [ ] 2.1 实现新闻源配置管理:支持注册 API 类型与 RSS 类型新闻源,配置轮询间隔- [ ] 2.2 实现 REST API 新闻抓取器:封装 HTTP 请求,解析响应为标准 NewsItem 格式- [ ] 2.3 实现 RSS feed 新闻抓取器:解析 RSS XML,提取条目并转换为标准格式- [ ] 2.4 实现定时轮询调度器:按各源配置的间隔自动触发抓取任务- [ ] 2.5 实现请求频率控制与指数退避策略:检测 429/限流响应,自动调整请求频率- [ ] 2.6 实现新闻源健康检查:记录连续失败次数,自动降级不可用源- [ ] 2.7 实现标题相似度去重:对 24 小时内新闻计算标题相似度,超过阈值标记为重复## 3. 新闻处理模块 (news-processor)- [ ] 3.1 实现新闻摘要生成:调用 LLM API 对原始正文生成 200 字以内中文摘要- [ ] 3.2 实现关键词规则分类器:为军事行动、外交动态、经济制裁、人道主义等类别定义关键词规则集- [ ] 3.3 实现 LLM 辅助分类:当关键词规则无法覆盖时,调用 LLM 进行语义分类并返回置信度- [ ] 3.4 实现关键信息提取:提取事件时间、地点、涉及方、事件类型等结构化字段- [ ] 3.5 实现处理流水线:将摘要生成→分类→信息提取串联为异步处理管线## 4. 新闻查询模块 (news-query)- [ ] 4.1 实现按时间范围查询接口:支持最近 N 小时和自定义起止时间- [ ] 4.2 实现按事件类别筛选:支持单类别和多类别筛选- [ ] 4.3 实现关键词搜索:对标题和摘要进行多关键词组合搜索- [ ] 4.4 实现查询结果排序:默认按发布时间倒序排列- [ ] 4.5 组合查询:支持时间范围 + 类别 + 关键词的复合查询条件## 5. 集成与测试- [ ] 5.1 集成三个模块(fetcher → processor → query)为完整流程- [ ] 5.2 编写 news-fetcher 单元测试:模拟新闻源响应,验证抓取、标准化、去重逻辑- [ ] 5.3 编写 news-processor 单元测试:验证摘要生成、分类和信息提取的输出格式- [ ] 5.4 编写 news-query 单元测试:验证各类查询条件下的返回结果准确性- [ ] 5.5 编写端到端集成测试:从模拟数据源抓取→处理→查询完整链路验证...# Todos[✓] Create proposal.md artifact[✓] Create design.md artifact[✓] Create specs artifacts[✓] Create tasks.md artifact[✓] Show final status所有制品已创建完成 ✅Change: us-iran-war-news位置: openspec/changes/us-iran-war-news/制品 说明proposal.md 动机与范围:为什么需要美伊战争新闻聚合系统,新增哪些能力design.md 技术设计:Pull+定时轮询架构、多源聚合、标题相似度去重、关键词+LLM混合分类、TypeScript+Node.js+SQLitespecs/news-fetcher/spec.md 新闻抓取规格:多源抓取、数据标准化、定时调度、频率控制、去重specs/news-processor/spec.md 新闻处理规格:摘要生成、事件分类(关键词+LLM)、关键信息提取specs/news-query/spec.md 新闻查询规格:按时间/类别/关键词查询、组合搜索tasks.md 20 项实施任务,分5组:项目初始化→抓取模块→处理模块→查询模块→集成测试所有制品已创建!可以开始实施。运行 /opsx-apply 或让我开始实现任务。
才做了第一步,你就已经拿到了一份结构完整、可审查的需求文档。此时你可以逐份打开 proposal.md / design.md / specs/*.md / tasks.md,修改任何不符合预期的地方,增删需求、调整技术选型、细化任务粒度,都只是改Markdown而已。调整好了,再进入下一步。

作为产品经理,过去你和产品经理吵三天的需求评审,现在 AI 三分钟交出一份让你说不出话的文档。
作为老板,有没有:“怎么实现我不管,我要的是结果”的既视感。
第二步:实施(Apply)——让AI按清单干活
确认规范无误后,一句话启动实施:
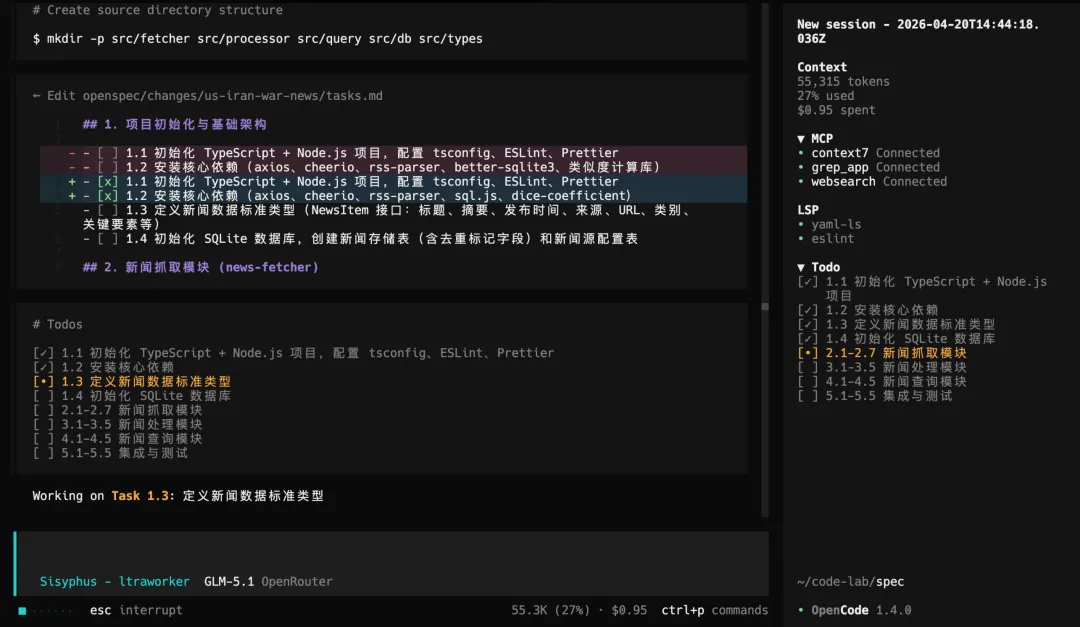
/opsx-applyThinking: 用户希望我执行/应用“us-iran-war-news”这一 OpenSpec 更改。让我按照以下步骤操作:1. 选择这个变化内容——从上下文来看,是“美伊战争新闻”2. 检查状态3. 获取申请说明4. 读取上下文文件5. 展示进展6. 执行任务首先,我将检查任务状态并获取操作说明。使用方式:us-iran-war-news(若需更改,请使用 /opsx-apply <其他> 选项)# Check change status and schema$ openspec status --change "us-iran-war-news" --json# Get apply instructions$ openspec instructions apply --change "us-iran-war-news" --json...# Todos[•] 1.1 初始化 TypeScript + Node.js 项目,配置 tsconfig、ESLint、Prettier[ ] 1.2 安装核心依赖[ ] 1.3 定义新闻数据标准类型[ ] 1.4 初始化 SQLite 数据库[ ] 2.1-2.7 新闻抓取模块[ ] 3.1-3.5 新闻处理模块[ ] 4.1-4.5 新闻查询模块[ ] 5.1-5.5 集成与测试# Initialize npm project$ mkdir -p src && npm init -y# Wrote package.json# Wrote tsconfig.json# Wrote .prettierrc# Wrote .eslintrc.jsonNow install dev dependencies for task 1.1 + 1.2 together (they overlap):# Install all dependencies(安装环境的过程,略)# Create source directory structure$ mkdir -p src/fetcher src/processor src/query src/db src/types← Edit openspec/changes/us-iran-war-news/tasks.md## 1. 项目初始化与基础架构- [ ] 1.1 初始化 TypeScript + Node.js 项目,配置 tsconfig、ESLint、Prettier- [ ] 1.2 安装核心依赖(axios、cheerio、rss-parser、better-sqlite3、类似度计算库)- [x] 1.1 初始化 TypeScript + Node.js 项目,配置 tsconfig、ESLint、Prettier- [x] 1.2 安装核心依赖(axios、cheerio、rss-parser、sql.js、dice-coefficient)- [ ] 1.3 定义新闻数据标准类型(NewsItem 接口:标题、摘要、发布时间、来源、URL、类别、关键要素等)- [ ] 1.4 初始化 SQLite 数据库,创建新闻存储表(含去重标记字段)和新闻源配置表## 2. 新闻抓取模块 (news-fetcher)Working on Task 1.3: 定义新闻数据标准类型# Wrote src/types/index.ts/** 事件类别枚举 */export type EventCategory =...# Todos[✓] 1.1 初始化 TypeScript + Node.js 项目[✓] 1.2 安装核心依赖[✓] 1.3 定义新闻数据标准类型[✓] 1.4 初始化 SQLite 数据库[✓] 2.1-2.7 新闻抓取模块[✓] 3.1-3.5 新闻处理模块[✓] 4.1-4.5 新闻查询模块[✓] 5.1-5.5 集成与测试Implementation CompleteChange: us-iran-war-newsSchema: spec-drivenProgress: 26/26 tasks complete ✓Project Structuresrc/├── index.ts # App 集成入口├── types/index.ts # 标准类型定义 (NewsItem, NewsSource, EventCategory 等)├── db/index.ts # SQLite 数据库层 (sql.js)├── fetcher/│ ├── index.ts # 模块导出│ ├── fetchers.ts # API/RSS 抓取器│ ├── scheduler.ts # 定时轮询调度器 + 去重 + 保存│ ├── rate-limiter.ts # 频率控制与指数退避│ └── dedup.ts # Dice 系数标题去重├── processor/│ ├── index.ts # 模块导出│ ├── classifier.ts # 关键词规则分类器│ ├── llm.ts # LLM 摘要/分类/提取 (可插拔客户端)│ └── pipeline.ts # 处理流水线└── query/└── index.ts # 组合查询 (时间/类别/关键词)tests/├── fetcher.test.ts # 13 tests├── processor.test.ts # 12 tests├── query.test.ts # 14 tests└── integration.test.ts # 9 testsTest Results: 48/48 passing ✅All tasks complete! You can archive this change with /opsx-archive.整个过程中,AI会逐条勾选 tasks.md,你随时可以打断、审查代码、调整方向。因为每个任务粒度都很小(几十行代码级别),即使返工成本也很低。
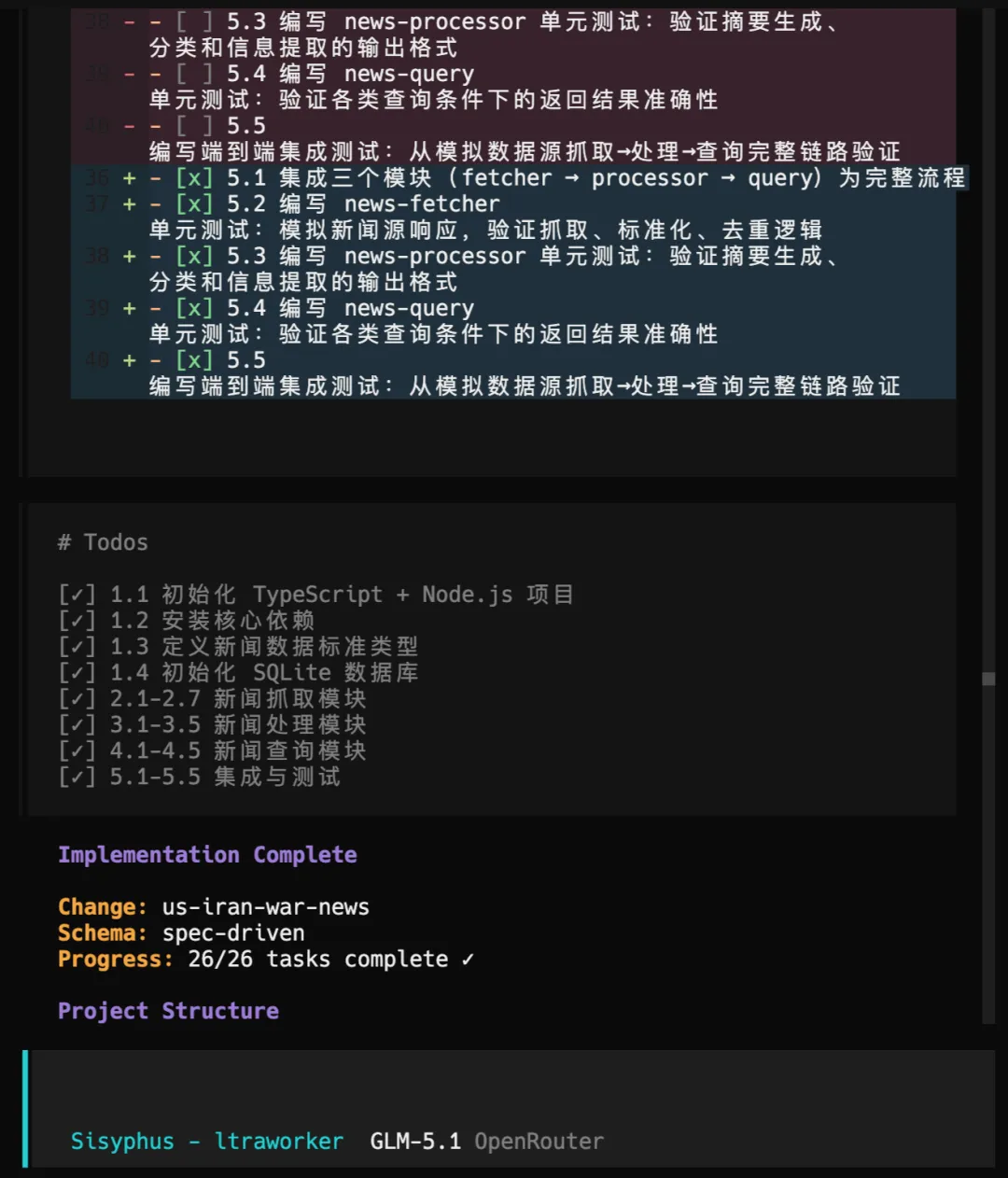
第二个命令执行完毕,整个软件已经开发完毕,可以运行使用了。
第三步:归档(Archive)——沉淀为项目资产
全部任务完成后,确认交付的软件功能正确之后,就可以归档这次变更:
/opsx-archive归档过程中,OpenSpec会检查所有制品与任务是否完成,并把本次新增的增量规格同步到主规格库 openspec/specs/:
Thinking: 用户想要将一项更改进行存档。根据对话背景,该更改的内容是“美伊战争新闻”。接下来让我按照步骤操作:1. 从上下文可以推断出其名称的变更 - 是 "us-iran-war-news"2. 检查工件完成情况3. 检查任务完成情况4. 评估差值规格同步状态5. 执行存档操作6. 显示摘要...# Questions# 问题需要将 3 个差异规格同步至主规格(位于 openspec/specs/ 目录下)。现在进行同步以保留规格定义,还是选择不同步直接存档?立即同步(推荐)Archive CompleteChange: us-iran-war-newsSchema: spec-drivenArchived to: openspec/changes/archive/2026-04-20-us-iran-war-news/Specs: ✓ Synced to main specs (openspec/specs/news-fetcher/, news-processor/, news-query/)All artifacts complete. All tasks complete (26/26).
openspec项目开发环境界面
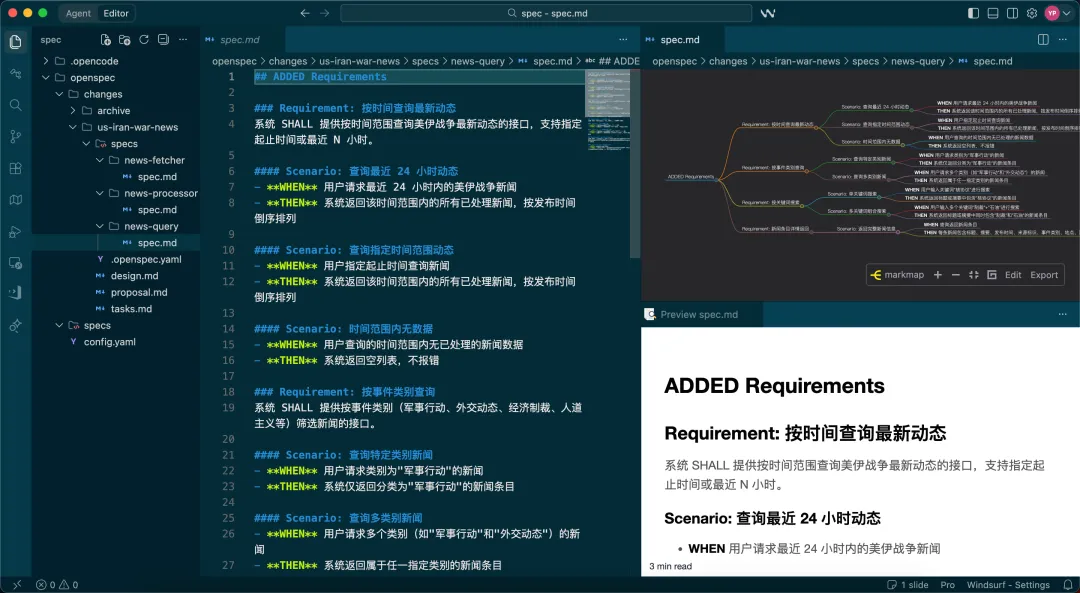
归档后,代表着本版本需求开发完毕,可以开始下一个阶段的工作了。 你现在可以重复这个过程,不断地迭代改进自己的产品。
最终经过多次迭代后的产品界面截图:
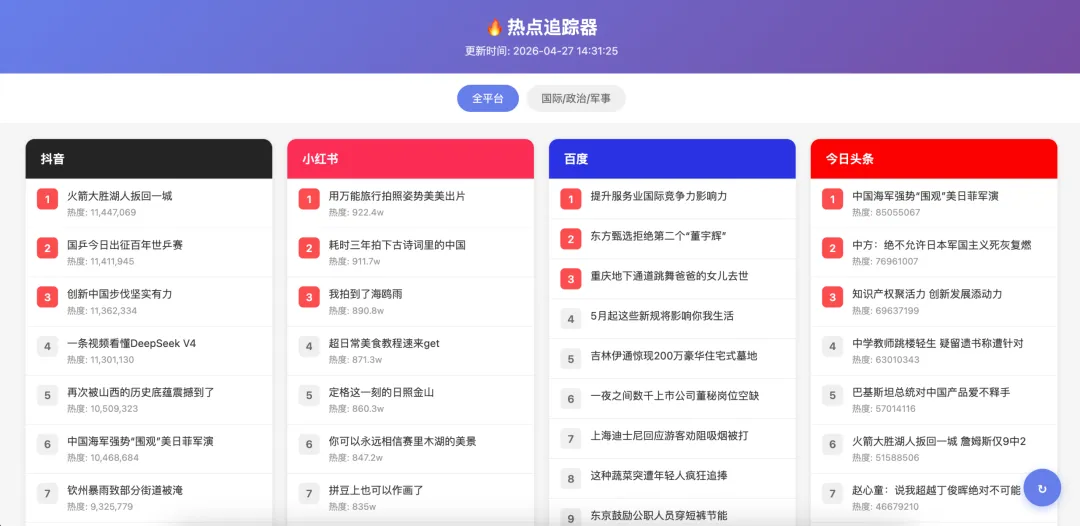
此时已经拓展成了全类别新闻汇聚,前端为web页面,后端为多渠道新闻信息抓取分类汇总。
openspec目录结构
.├── changes│ ├── archive 归档目录│ │ └── 2026-04-20-us-iran-war-news 已经归档的需求│ │ ├── design.md│ │ ├── proposal.md│ │ ├── specs│ │ │ ├── news-fetcher│ │ │ │ └── spec.md│ │ │ ├── news-processor│ │ │ │ └── spec.md│ │ │ └── news-query│ │ │ └── spec.md│ │ └── tasks.md│ └── us-iran-war-news-1.1 下一个版本要开发的需求│ ├── design.md│ ├── proposal.md│ ├── specs│ │ ├── news-fetcher│ │ │ └── spec.md│ │ ├── news-processor│ │ │ └── spec.md│ │ └── news-query│ │ └── spec.md│ └── tasks.md├── config.yaml└── specs 主需求规格沉淀于此├── news-fetcher│ └── spec.md├── news-processor│ └── spec.md└── news-query└── spec.md
openspec目录结构
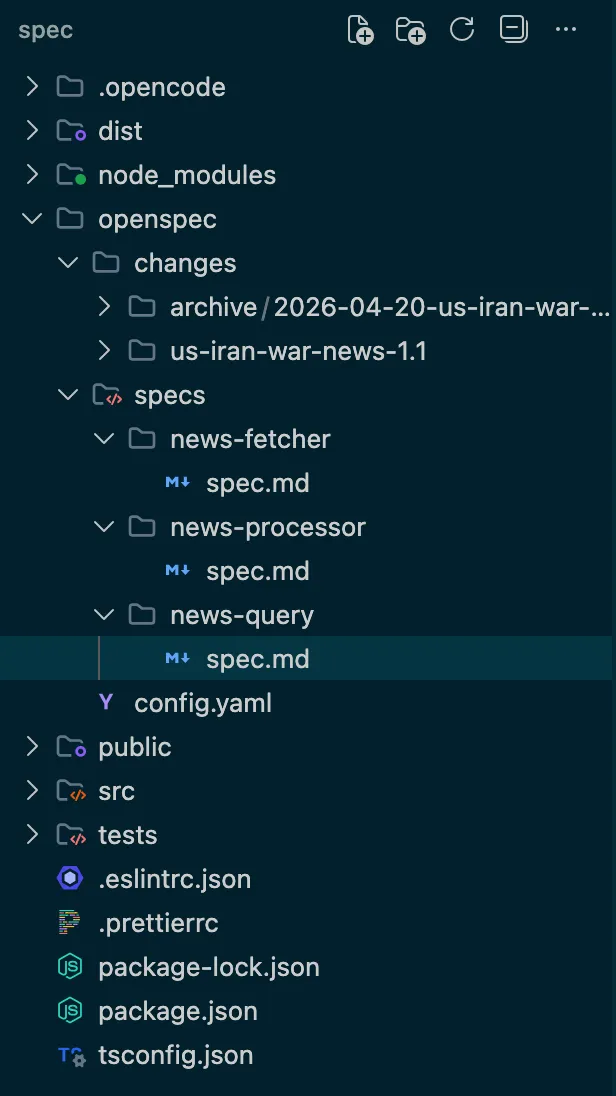
可以说,和我自己实践的“古法Agent开发”方法论异曲同工,但区别是,openspec把这套方法论体系化、技能化、工具化了,可以让任何用户直接使用,而无需每个人都去重新沉淀管理经验。
谁应该用OpenSpec
跑完一整轮之后,我对OpenSpec的定位有了更清晰的判断:
对没有技术背景的小白用户:这是一把神兵利器。你只需要用自然语言描述想要什么,AI会帮你把需求结构化,你做的事只是"审阅文档、点同意",最后就能拿到一个可跑的工程。
对程序员:OpenSpec本质上是一套"规格驱动开发"的方法论封装。熟练的开发者自己写几个Skill也能实现类似效果,但很难做得像OpenSpec这样体系完整、阶段清晰。把它当作一套现成的工作流骨架直接用,更划算。
对产品经理:自己手写PRD可控性更强,但速度慢。用OpenSpec让AI先出一版结构化需求文档,再在此基础上修改调整,一个版本需求能省下好几个小时,尤其适合快速探索期的新功能。
没错,也就是说,适合任何使用AI工作的人。
“古法Agent开发 vs OpenSpec” 对照表
OpenSpec命令速查表
一、 CLI 环境管理命令 (Terminal)
openspec init | 初始化项目 | |
openspec update | 更新技能文件.md 指令文件。 | |
openspec config | 交互式配置 | |
openspec list | 列出所有变更 (Changes) | |
openspec show [name] | 查看详情 | |
openspec validate | 格式校验 |
二、核心流程命令
命令 功能描述 核心产物
/opsx:propose 发起提案。根据自然语言描述,一键生成初始方案。 proposal.md, specs/, tasks.md
/opsx:explore 技术探索。深度扫描代码库,分析变更的可行性和影响点。 完善的 design.md 或 specs/
/opsx:apply 执行任务。让 AI 按照 tasks.md 中的清单逐项编写代码。 实际的代码实现 (Codebase)
/opsx:archive 合并与归档。将变更规范合并到主库,并存档当前 Change。 归档 openspec/changes/
三、扩展流程命令
需要通过 openspec config profile 开启后使用。
/opsx:new:仅启动一个新变更,不立即生成所有产物,适合边想边做。
/opsx:continue:引导生成流程中的下一个环节(如从 Proposal 到 Spec)。
/opsx:ff (Fast-Forward):快速直达,一次性生成所有规划文件。
/opsx:verify:检查当前实现是否与 Spec 描述的功能点匹配。
视编辑器不同,命令中的冒号可能写为减号连接符。 更多命令信息可以参考官方文档:https://github.com/Fission-AI/OpenSpec/blob/main/docs/getting-started.md
小结
OpenSpec做的事情很朴素:把软件开发里最经典的"先设计后实现"的最佳实践,用一套轻量的文档buff叠加在AI身上,让它先写规范、再写代码、最后归档沉淀。
OpenSpec输出的,是项目里长期可维护、可反复迭代的知识资产,它的价值在于帮助用户驾驭住了AI这头猛兽。
如果你正在头疼Agent干活跑偏,花十分钟试试OpenSpec,你可能会收获一件强大的利器。OpenSpec 把方法论工具化,进一步降低了软件产品研发的入门门槛。
这也许是产品经理最后一次写需求文档了。
未来3年内80%的初中级产品经理、软件工程师岗位可能都会消失。
对此,你怎么看,欢迎评论区留言。
