 夜雨聆风
夜雨聆风作者:Harshit Joshi, Priyank Shethia, Jadelynn Dao, Monica S. Lam 机构:Computer Science Department, Stanford University |
现实世界的文档问答面临巨大挑战。分析师需要在多个文档和每个文档的不同部分之间综合证据。然而,随着文档集合的增长,任何固定的 LLM 上下文窗口都可能被超出。一种常见的解决方案是将文档分解为块,并从块级输出组装答案,但这引入了聚合瓶颈。 SLIDERS是一个通过结构化推理对长文档集合进行问答的框架,将关键信息提取到关系数据库中,使系统能够通过 SQL 而非连接文本在持久的结构化状态上进行可扩展推理。 |
🏗️传统方法:将文档分块后用 LLM 拼接推理,面临聚合瓶颈 ✨SLIDERS:提取到数据库,用 SQL 进行可扩展推理 |
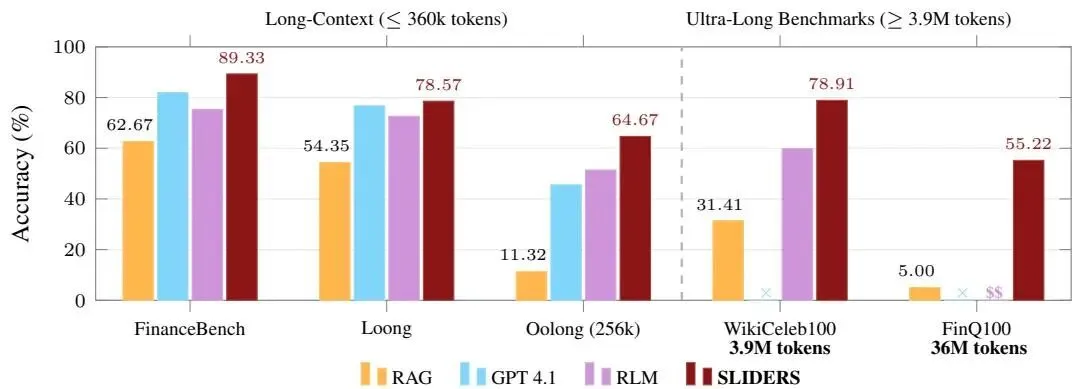 图1::长上下文和超长基准测试的准确率 |
01研究背景
准确地对长文档或多文档语料库进行问答,对于金融、等知识密集型领域的分析至关重要。分析人员经常需要综合分散在单份报告多个页面中或跨越集合中数千份报告的证据。
然而,即使拥有百万 token 的上下文窗口,现代大语言模型在现实世界的文档分析中仍然力不从心,现实的语料库仍然远超单次处理所能涵盖的范围。
聚合瓶颈问题:将文档分割成较小的片段,并从分块输出中组装答案。随着分块数量的增加,系统必须聚合并推理从所有分块输出中提取的证据,最终重新创建了它本来要避免的上下文过长问题。
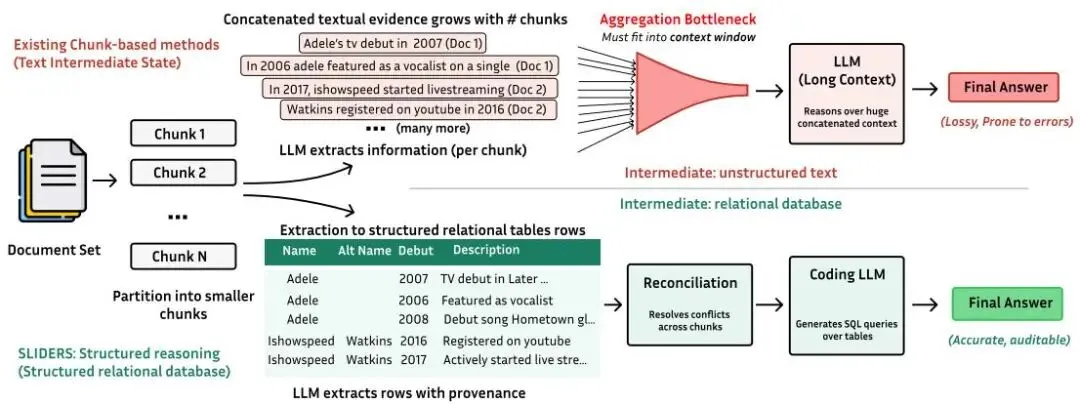 图2:基于分块的方法重新生成了长上下文问题 |
| 💡 核心思路:结构化推理 不依赖 LLM 对拼接的分块输出进行推理,而是将关键信息提取到关系数据库中,将非结构化文本转换为持久的结构化状态。推理简化为查询:在数据库上执行 SQL 来聚合、比较和计算提取的证据。 |
| 🔄 数据协调阶段 独立提取的记录通常为同一底层事实提供重叠、部分或冲突的视图。数据协调利用来源、提取理由和元数据来检测和修复重复、不一致和不完整的记录。 |
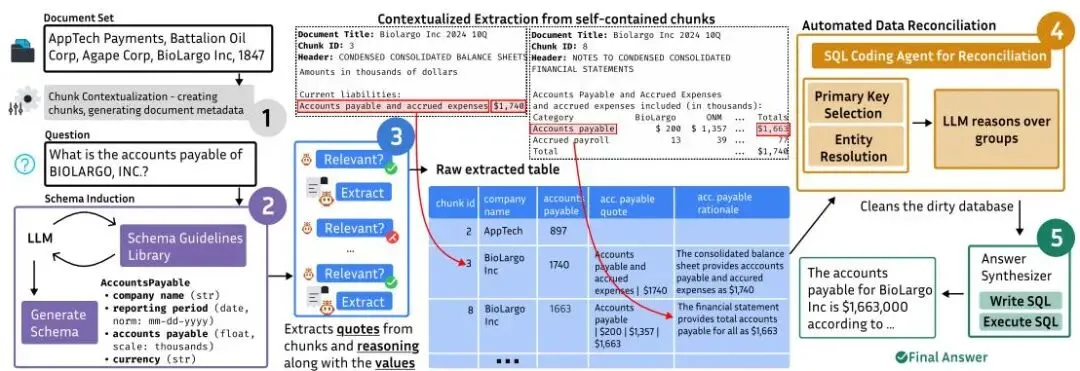 图3:SLIDERS 概述,展示分块上下文化、模式归纳、结构化提取、数据对齐和问答过程 |
在三个适合强大基础 LLM 上下文窗口的长上下文基准测试中,SLIDERS 的表现优于所有基线,平均超过 GPT-4.16.6 个百分点。在包含 100 个文档、总计 3.9M token 和 36M token 的两个新基准测试上,SLIDERS 在 Wikipedia 上达到 78.91% 的准确率,在金融文档上达到 55.22%。
02技术方案
| 📍 上下文分块 在分块之前用元数据增强每个文档,全局部分包含标题和文档级描述,局部部分捕获章节标题、表格和图片标题。将每个文档分割为多个块,同时保持语义和结构的一致性。 |
| 📍 模式归纳 生成具有多个表的关系模式。表模式包含模式名称和一组字段,每个字段定义字段名称、语义描述、数据类型、度量单位、刻度和规范化规则。 |
| 📍 相关性门控提取 在提取之前引入一个相关性门。对于每个块,模型首先确定文本是否包含与模式实体相关的证据;只有当这个门通过时,才执行提取,防止将假阳性注入到数据库中。 |
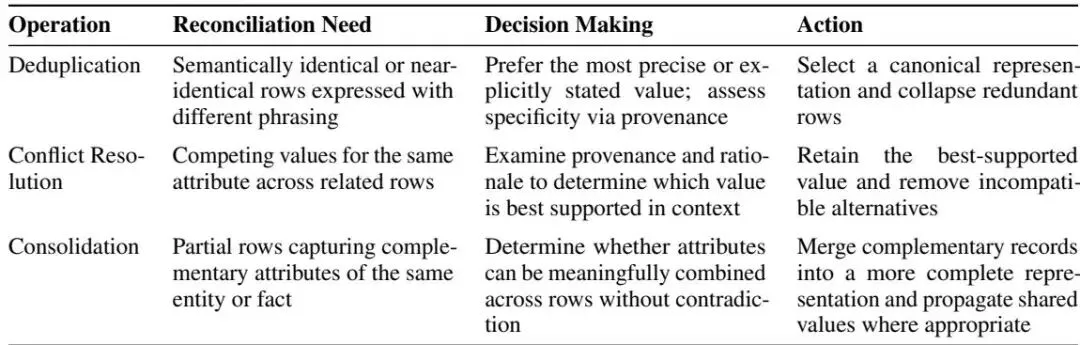 表1:用于数据协调的执行器智能体 |
| 📍 数据协调 文档在不同粒度级别上分发、重复和完善信息。协调通过将重叠、部分或冲突的记录对齐到一致的关系状态来应对这一挑战。按主键将行分组,在小的、语义一致的分区中协调重叠的证据。 |
| 📍 协调智能体 对于每个记录分区,协调智能体使用来源、提取理由和文档级元数据来确定证据应该如何集成。智能体编写 SQL 程序以通过检查行内容、值分布和支持证据来确定需要去重、冲突解决或整合操作中的哪一个。 |
03实验分析
我们在三个"长上下文"基准测试上评估 SLIDERS,这些测试的输入可以适配大多数前沿模型的上下文窗口,最多包含 36 万词元。
FinanceBench:单文档金融问答基准测试,包含 150 个关于上市公司的问题 Loong:多文档问答基准测试,涵盖金融(中英文)、法律(中文)和学术论文(英文) Oolong:明确专注于聚合的长上下文推理基准测试,模型需先分类数据点再聚合 |
📊观察结果 1:SLIDERS 在所有长文档集问答任务上都优于所有基线方法 📋观察结果 2:出处跟踪增强了可审计性和可解释性 🔓观察结果 3:SLIDERS 也与开源 LLM 有效配合 |
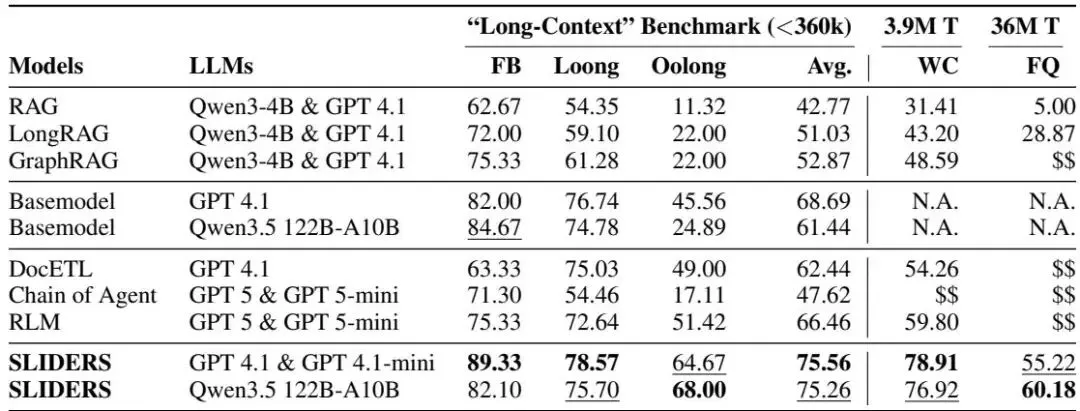 表3:长文档问答基准测试的性能比较 |
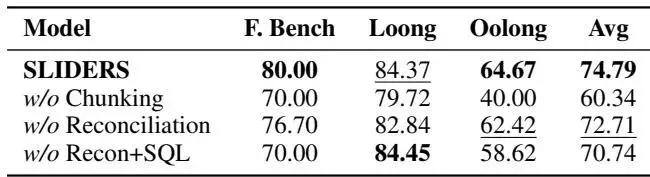 表4:在验证集上的消融研究 |
| 🚀 超长文档集基准测试 引入两个超过当前前沿模型上下文窗口的文档集基准测试:WikiCeleb100(390 万词元)和 FinQ100(3600 万词元)。SLIDERS 在 WikiCeleb100 上达到 78.9% 的准确率,在 FinQ100 上达到 55.2% 的准确率。 |
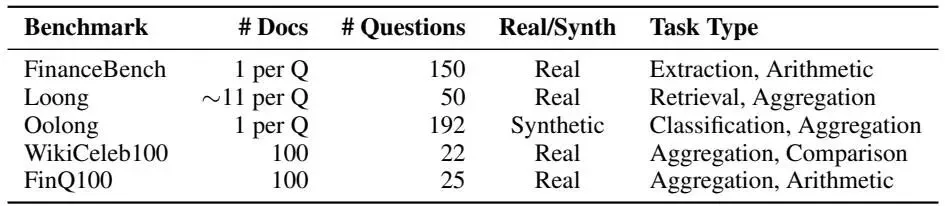 表2:基准测试统计数据 |
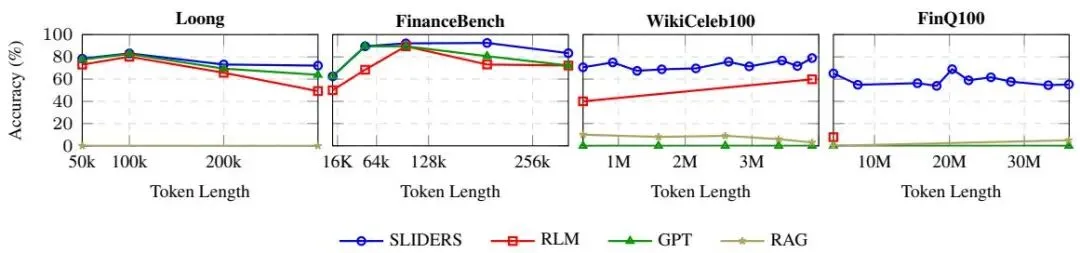 图5:基准测试中准确率与词元长度的关系 |
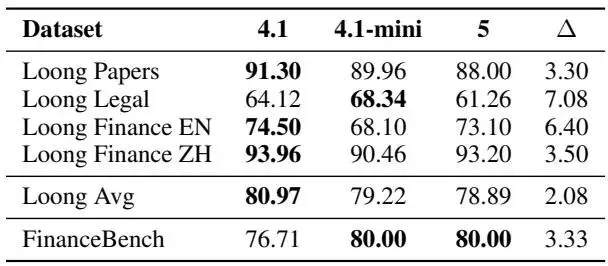 表5:模式归纳模型的准确率 |
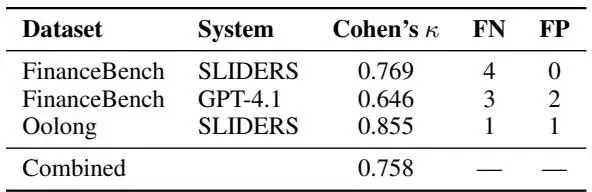 表6:50个问题的人工评估 |
| 💰 成本分析 平均每题成本为 0.76 美元。与 RLM 相比,SLIDERS 达到相等或更低的成本。对于 WikiCeleb100,GPT-4.1 将花费约 121.60 美元,而 SLIDERS 仅花费 13.10 美元。 |
| 🔄 协调代理分析 调和代理运行效率非常高,平均每个主键组仅需 1.28 �迭代即可完成数据调和工作。对于大型金融语料库,主要引发必须解决的冲突,而多文档传记语料库更经常需要跨部分重叠证据的合并。 |
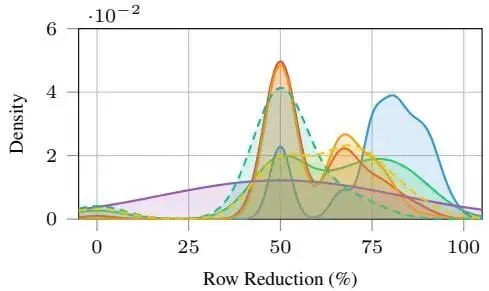 图6a:行减少分布 |
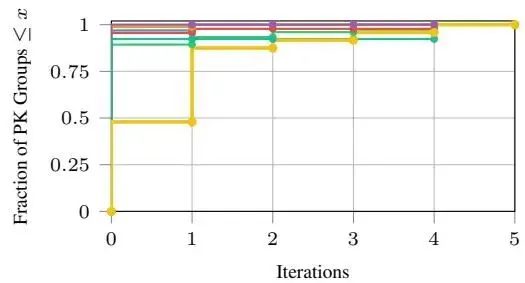 图6b:解决迭代次数 |
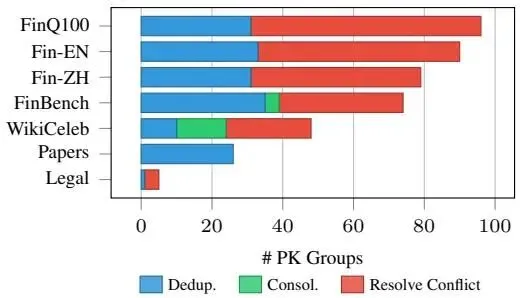 图6c:操作分解 |
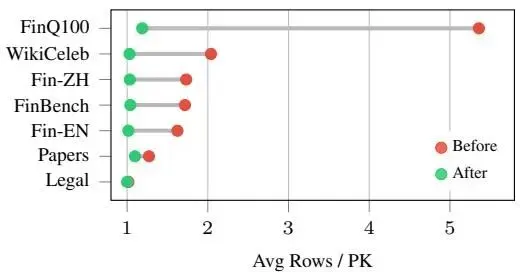 图6d:调和前后每键行数 |
总体而言,调和不仅仅是删除重复行:它将嘈杂的局部提取转换为近规范的结构化表示,每主键约 1 行。 |
✓总结
本文提出了 SLIDERS 框架,通过结构化推理实现对长文档集合的问答。核心创新在于将文档中的关键信息提取到关系数据库中,并利用 SQL 进行推理,将自然语言问答问题转化为结构化数据处理问题。 数据调和阶段充分利用来源信息、提取理由和元数据,能够有效检测和修复重复、不一致和不完整的记录,确保数据的准确性和完整性。 在三个标准的长上下文基准测试中,SLIDERS 优于所有基线方法,平均准确率比 GPT-4.1 高出6.6 个百分点。在规模分别为 3.9M 和 36M token 的两个新基准测试中,SLIDERS 比次优基线分别提高了约19 个百分点和约32 个百分点。 调和代理的运行效率非常高,平均每个主键组仅需 1.28 次迭代即可完成数据调和工作。平均每道题目的处理成本仅为 0.76 美元,低于 RLM 等基基线方法。 综上所述,SLIDERS 框架不仅在准确率上超越了现有的最先进方法,而且在效率和成本控制方面也展现出明显优势,为长文档问答任务提供了一个强有力的解决方案。 |
🔗 相关资源:
项目官网:https://slidersiders.genie.stanford.edu/
GitHub 仓库:https://github.com/stanford-oval/sliders
