 夜雨聆风
夜雨聆风最近 Hermes 很火。
不少原本按照 OpenClaw,也就是“龙虾”这条路线搭建本地 Agent 的人,开始重新评估自己的系统:要不要迁移?要不要重装?要不要干脆把旧环境卸掉,转向 Hermes?
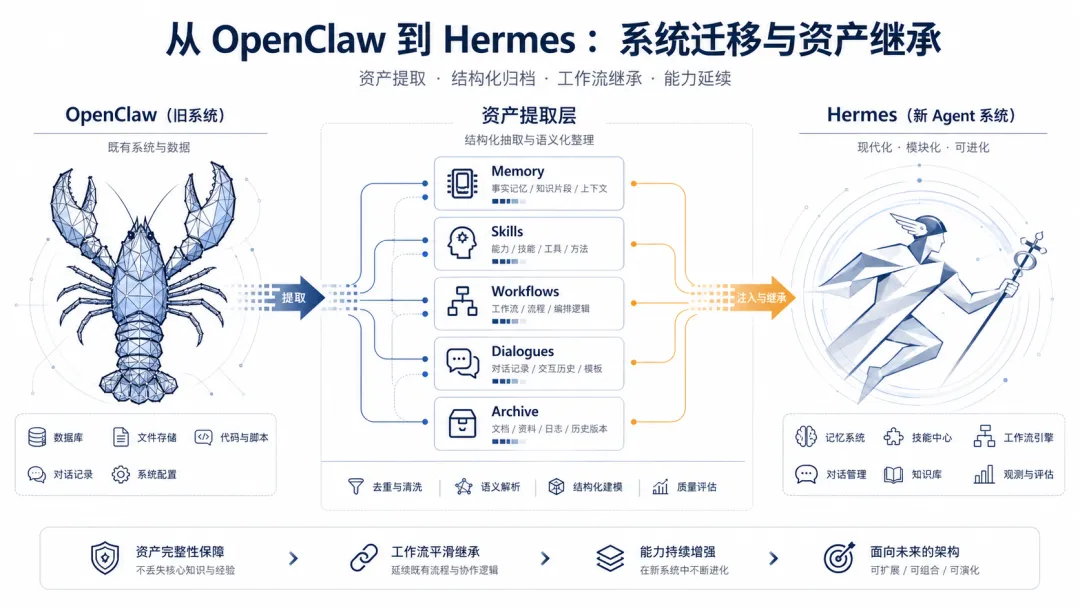
从工具层面看,这当然是一个很正常的选择。
一方面,OpenClaw 更偏 Node.js 生态,插件、前端、运行时都带着很明显的 Node 工程气质;Hermes 则更偏 Python 主导的 Agent 系统,更容易和本地脚本、数据处理、记忆系统、自定义自动化流程结合起来。
另一方面,从我这段时间的实际运行情况看,OpenClaw 虽然很有想象力,但也确实遇到过一些工程化问题:插件配置复杂、迁移路径不够轻、局部场景下甚至出现 CPU 爆满。对于一个希望长期运行的个人 Agent 来说,这种“不知道什么时候又被吃满资源”的不确定性,会让人天然想重新审视整个系统。
所以,新框架出现,旧环境变乱,插件冲突,配置积累太多,运行资源也开始让人不放心,迁移似乎就成了一件顺理成章的事。
而且 Hermes 也确实提供了面向 OpenClaw 的迁移支持。按理说,只要把该导的内容导出来,把该迁的路径迁过去,事情就可以结束。
但我这次没有急着把它当成一次普通迁移。
因为我突然意识到:过去一个多月,我和 Agent 的互动已经留下了大量产物。
这些产物不只是聊天记录。
里面有我反复使用过的 Skill,有被纠正后沉淀下来的 Memory,有越来越稳定的内容生产流程,也有一些看似零碎但其实很重要的协作习惯。
如果这时候只是简单卸载、搬家、重装,那就太可惜了。
所以我更愿意把这次从 OpenClaw 转向 Hermes 的过程,看成一次难得的“资产清算”。
不是为了怀旧,而是为了回答一个问题:
这一个多月里,Agent 到底给我留下了什么?
很多人第一次用 Agent,都会有一个错觉:
只要它能调用工具、能保存记忆、能帮我自动化处理任务,我就已经拥有了一个“长期可积累”的 AI 系统。
但真正的问题,往往不在安装那一刻出现。
而是在你准备卸载它、重装它、迁移它、换一台机器继续用它的时候。
你打开目录一看,里面什么都有:
对话正文 Skill 目录 本地记忆数据库 插件配置 浏览器缓存 附件下载 创作草稿 任务记录 工具调用日志 一堆你已经不记得来源的临时文件
这时候你会突然意识到一件事:
你以为自己要卸载的是一个软件,其实你面对的是一个已经和你一起工作过一段时间的 Agent。
它不是一个干净的程序包。
它更像一个旧办公室。
桌面上有文件,抽屉里有便签,电脑里有项目记录,白板上还有没擦干净的流程图。你当然可以一键清空,但那样删掉的不只是垃圾,也可能是你过去几个月一点点磨出来的工作习惯。
所以,卸载 OpenClaw 之前,真正该问的问题不是:
怎么删干净?
而是:
这个 Agent 到底给我留下了什么?
一、Agent 不是一个目录,而是一团混合资产
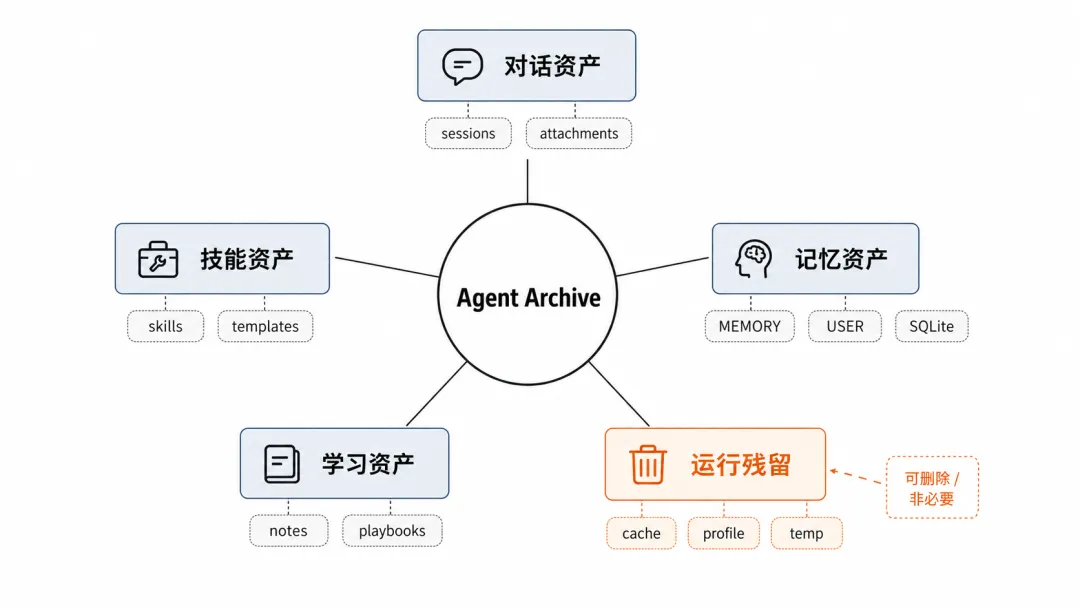
很多人会把 OpenClaw、Hermes、各种本地 Agent 框架,当成一个“工具”。
工具坏了,重装。
配置乱了,删除。
插件冲突了,清空。
这个想法没错,但只对了一半。
因为 Agent 一旦开始长期使用,它就不再只是工具本身,而会慢慢积累出五类资产:
这五类东西如果混在一起,就会变成一场“数据赌博”。
你不知道哪些以后还有用,也不知道哪些删掉就真的没了。
所以,卸载之前第一步,不是备份整个目录,也不是马上清空。
而是先做一次资产盘点:
哪些是长期资产,哪些只是运行噪音?
二、对话不要只当聊天记录,要当“证据仓”处理
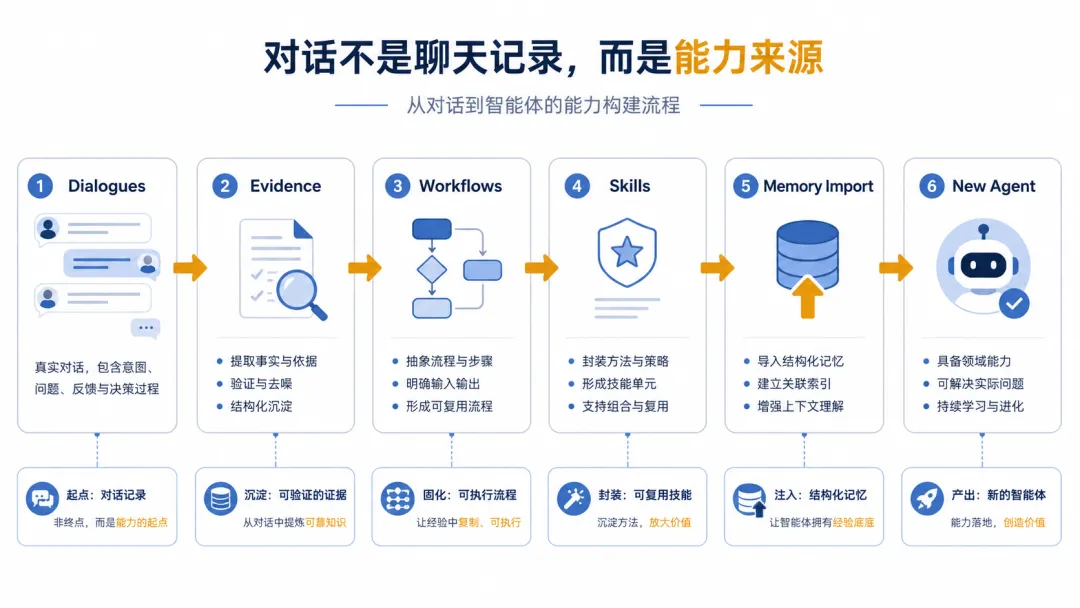
大多数人对 AI 聊天记录的理解是:
这是对话日志,偶尔回头看看就行。
这个理解太低估它了。
一段完整的 Agent 对话,至少包含四种证据:
第一,它记录了你当时想解决什么问题。
第二,它记录了 AI 调用了什么工具、走了什么路径。
第三,它记录了哪些方案被你接受,哪些被你否定。
第四,它记录了你和 Agent 之间逐渐形成的协作习惯。
换句话说,对话不是聊天残留,而是 Agent 的工作日志。
比如同样是“帮我研究一个 GitHub 仓库”,一次成熟的 Agent 对话里可能会出现这样的流程:
先读取项目说明和 README 再查看目录结构 再分析核心模块 再对比同类项目 再总结架构优劣 最后给出可落地建议
这就不是普通聊天了。
这是一个可复用的研究流程。
如果你把这些对话全部丢掉,新 Agent 当然还可以回答问题,但它不知道你过去是如何定义“好答案”的。
所以我建议把对话资产单独归档成几类:
daily_reviews/:按日期归档的重要对话 formal_flows/:已经稳定的工作流 skill_drafts/:可能沉淀为 Skill 的片段 transparency_samples/:用于回看 Agent 如何决策的样本 attachments/:对话中产生或引用的附件
这样,对话就不再是一堆旧消息,而是一个可以反复开采的证据仓。
三、Skill 不要整包搬走,要先分层
很多人在迁移 Agent 时,会直接把 skills/ 目录整个打包。
这当然比不备份好。
但问题是,原始 Skill 目录里常常混着三种东西:
已经稳定可复用的正式 Skill 某次任务中临时写出来的半成品 Skill 只是看起来像 Skill 的说明文档或脚本残片
如果你直接整包迁移,短期很省事,长期会越来越乱。
更好的做法,是把 Skill 分成三层:
1. 正式 Skill
这些是已经多次使用、边界清楚、输入输出稳定的能力。
比如:
GitHub 仓库研究 微信文章读取 内容选题生成 公众号排版整理 本地文件归档 安全扫描
这类 Skill 应该进入正式目录,例如:
custom_classified/2. Agent 角色壳
有些内容不是技能,而是角色边界。
比如:
这个 Agent 应该叫你什么 它应该用什么语气回答 它在什么场景下应该谨慎 它什么时候应该先给结论 它不应该做哪些过度发挥
这类内容应该进入:
agents_curated/3. 待拆迁知识
还有一些内容既不是 Skill,也不是 Persona,而是方法文档、操作经验、配置指南。
它们可以先进入:
learned_documents_migration/以后再慢慢拆成 Skill、Memory 或 Workflow。
这一步的意义在于:
你不是在搬一个旧目录,而是在整理一套可继续使用的能力资产。
四、真正最不能丢的,往往不是 Skill,而是 Memory
Skill 很重要,但如果只能保一个东西,我会优先保留记忆数据库。
原因很简单:
Skill 决定 Agent 会做什么。
Memory 决定 Agent 知道你是谁。
一个没有 Memory 的 Agent,就像一个能力很强但刚入职的新员工。
它也许会写代码、会读文档、会整理资料,但它不知道你之前做过哪些项目,不知道你偏好什么格式,不知道你讨厌什么废话,也不知道你已经纠正过它哪些错误。
所以,卸载前要重点检查这些内容:
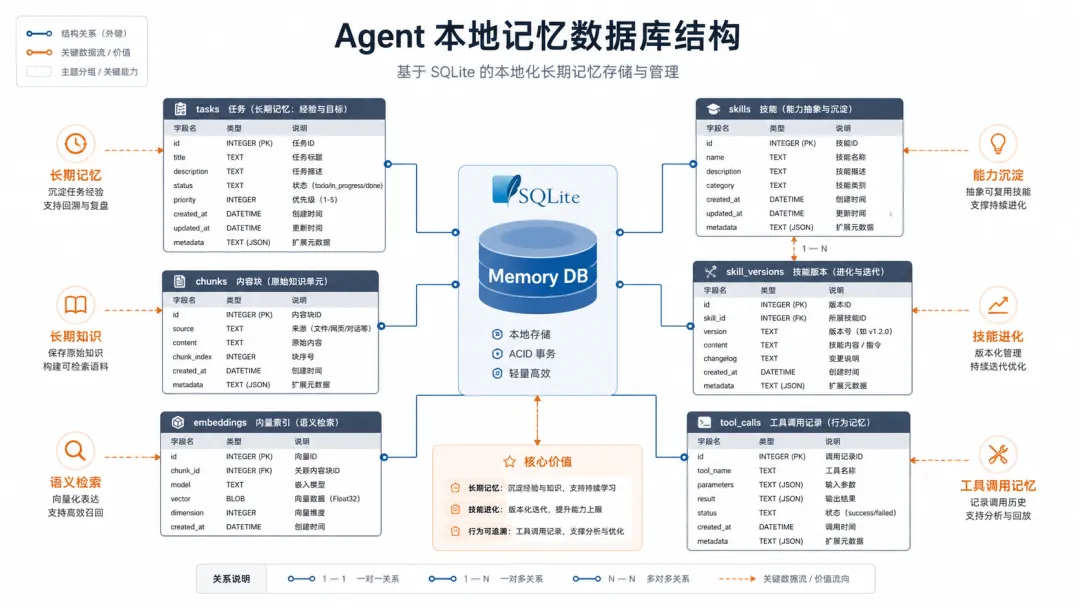
MEMORY.mdUSER.mdmemory/YYYY-MM-DD.md.learnings/ERRORS.md.learnings/LEARNINGS.md.learnings/FEATURE_REQUESTS.mdlocal_memos_db/memos.sql尤其是本地 SQLite 数据库。
很多时候,真正长期积累的东西并不在 Markdown 文件里,而在数据库里:
任务历史 技能版本 分块记忆 向量索引 工具调用记录 用户偏好 纠错记录
这类数据一旦丢了,你丢掉的不是配置。
你丢掉的是这个 Agent 和你一起工作过的痕迹。
所以我建议:
数据库原件单独备份 额外导出一份 SQL 再导出一份可读 Markdown 摘要 最后为新 Agent 生成一份 MEMORY_IMPORT.md
这样即使未来原插件不用了,你也不至于被格式锁死。
五、最隐蔽的一类资产:心理契约
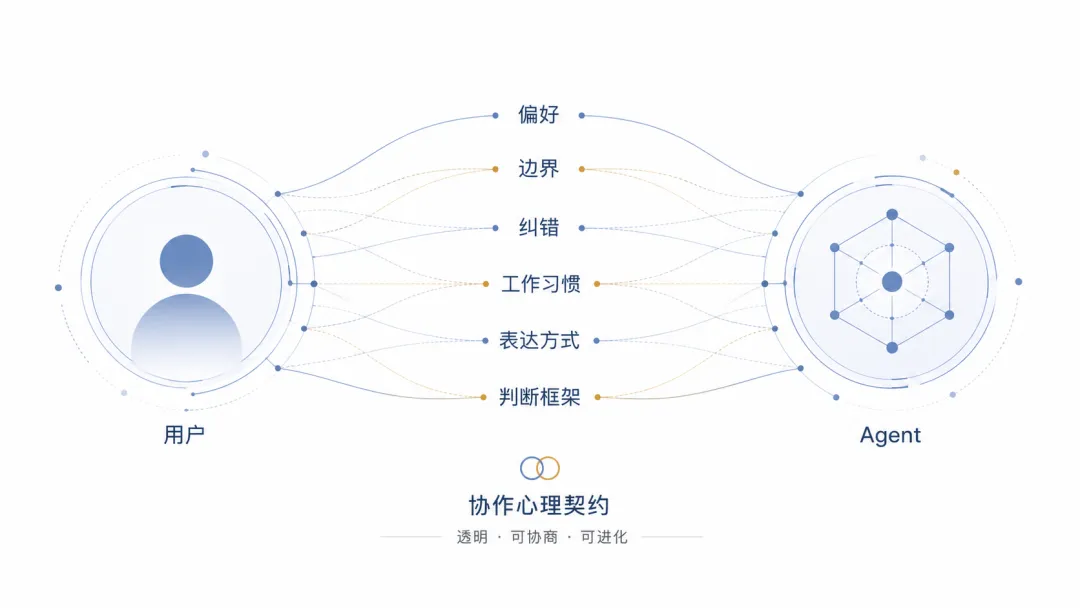
除了对话、技能和记忆,还有一类东西最容易被忽略。
我把它叫做:
心理契约。
它不是心理诊断,也不是玄学画像。
它指的是你和 Agent 在长期协作中形成的判断边界、表达偏好和工作默契。
比如:
你喜欢“结论先行”,不喜欢铺垫太长 你喜欢结构化输出,但不喜欢空泛表格 你做技术文章时,不希望过度幻想化 你对历史、数学、技术名词的准确性要求很高 你会反复把一个项目从想法讨论到 PRD、架构、任务拆解 你不是只要灵感,而是要能落地的系统方案
这些东西不一定会出现在配置文件里。
它们往往藏在对话里:
你纠正过什么,你拒绝过什么,你反复追问过什么,你在哪些地方说过“继续”,又在哪些地方说“不要这样”。
这类内容决定了新 Agent 是否“懂你”。
所以,迁移时不要只导入事实记忆,也要整理一份协作说明:
USER_WORKING_STYLE.md- 用户偏好:结论先行,结构清晰,避免空话- 内容偏好:公众号文章要克制、真实、有工程感- 技术偏好:喜欢 PRD、架构图、任务拆解、验收标准- 风险边界:涉及历史、技术事实时,不要乱编- 交互方式:可以主动拆成系列,不必强行融合成一篇这份文件的价值,可能比某个单独 Skill 还大。
因为它不是告诉 Agent “做什么”,而是告诉它:
怎样和你一起做事。
六、该删的也要删:不是所有东西都值得留
归档不是囤积。
如果你什么都舍不得删,最后得到的不是资产库,而是一个更大的垃圾堆。
以下内容一般不必长期保留:
浏览器缓存 空壳 Profile CLI 补全脚本 临时下载残留 已失效的运行状态 无法追溯来源的中间文件 纯临时日志
判断一个文件该不该留下,可以用三个问题:
它能不能帮助新 Agent 更懂我? 它能不能帮助新 Agent 更会做事? 它能不能证明某个重要任务或决策是怎么发生的?
三个问题都是否,那就不要留恋。
Agent 资产管理里,最重要的能力不是备份,而是筛选。
七、一套可复用的归档目录
如果你准备卸载、重装或迁移 OpenClaw,可以参考这样的目录结构:
agent_archive/├── 01_memory/│ ├── MEMORY.md│ ├── USER.md│ ├── daily_memory/│ ├── learnings/│ └── memos.sql│├── 02_skills/│ ├── custom_classified/│ ├── skill_drafts/│ └── deprecated/│├── 03_workflows/│ ├── github_research_flow.md│ ├── wechat_article_flow.md│ ├── project_prd_flow.md│ └── troubleshooting_flow.md│├── 04_dialogues/│ ├── daily_reviews/│ ├── formal_flows/│ ├── transparency_samples/│ └── attachments/│├── 05_creator_assets/│ ├── wechat_drafts/│ ├── xiaohongshu_notes/│ └── image_prompts/│└── 99_to_review/这个结构不是为了好看,而是为了让新 Agent 能够重新接上旧 Agent 的工作脉络。
Memory 告诉它:你是谁。
Skill 告诉它:它会什么。
Workflow 告诉它:复杂任务怎么做。
Dialogue 告诉它:这些能力是怎么长出来的。
Creator Assets 告诉它:哪些内容还能继续发布。
99_to_review 则给暂时判断不了的东西一个缓冲区。
八、卸载不是归零,而是提纯
到这里,我们就可以重新理解“卸载 OpenClaw”这件事了。
它不应该只是删除程序。
它更像一次资产清算。
你要把真正有价值的东西从运行残留里捞出来:
从对话里捞出流程 从流程里捞出 Skill 从 Skill 里捞出方法论 从 Memory 里捞出长期偏好 从纠错记录里捞出协作边界 从草稿里捞出还能继续发布的内容
当你完成这一步,OpenClaw 就不再只是一个工具。
它会变成一套你能迁移、复用、继续生长的 Agent 资产体系。
所以,下次卸载之前,别急着删目录。
先问自己一句:
我是不是已经把这个 Agent 的大脑带走了?
结语
如果你也在折腾本地 Agent、多 Agent、OpenClaw、Hermes 或各种 AI 工作流,建议从今天开始给自己的 AI 系统建立三个目录:
memory/skills/workflows/这三个目录,才是你真正的 AI 资产底座。
软件可以重装,框架可以替换,模型可以升级。
但你和 AI 一起磨出来的记忆、技能和流程,别让它们跟着一次卸载消失。
