 夜雨聆风
夜雨聆风关注我,学习更多实用Python知识
📌 经常收发PDF文档的小伙伴注意了!
🛠️ 前面分享了如何用Python自动提取PDF中的信息:用Python玩转PDF:文字提取/图片抓取/转PPT技巧(附完整代码)
🎯 今天把它做成带界面的工具——【PDF信息提取工具】文字、图片、表格一键批量提取,500页PDF只需几秒,支持单个文件或整个文件夹批量处理!
🛠️ 代码核心(实现框架):
- **PyMuPDF(fitz)**:读取PDF文字和图片- **pdfplumber**:智能识别PDF中的表格结构- **openpyxl**:将表格保存为Excel格式- **PySide6(Qt)**:构建图形界面,操作丝滑- **QThread**:后台处理大文件,界面不卡顿💡 不懂代码没事,用现成打包好的工具!
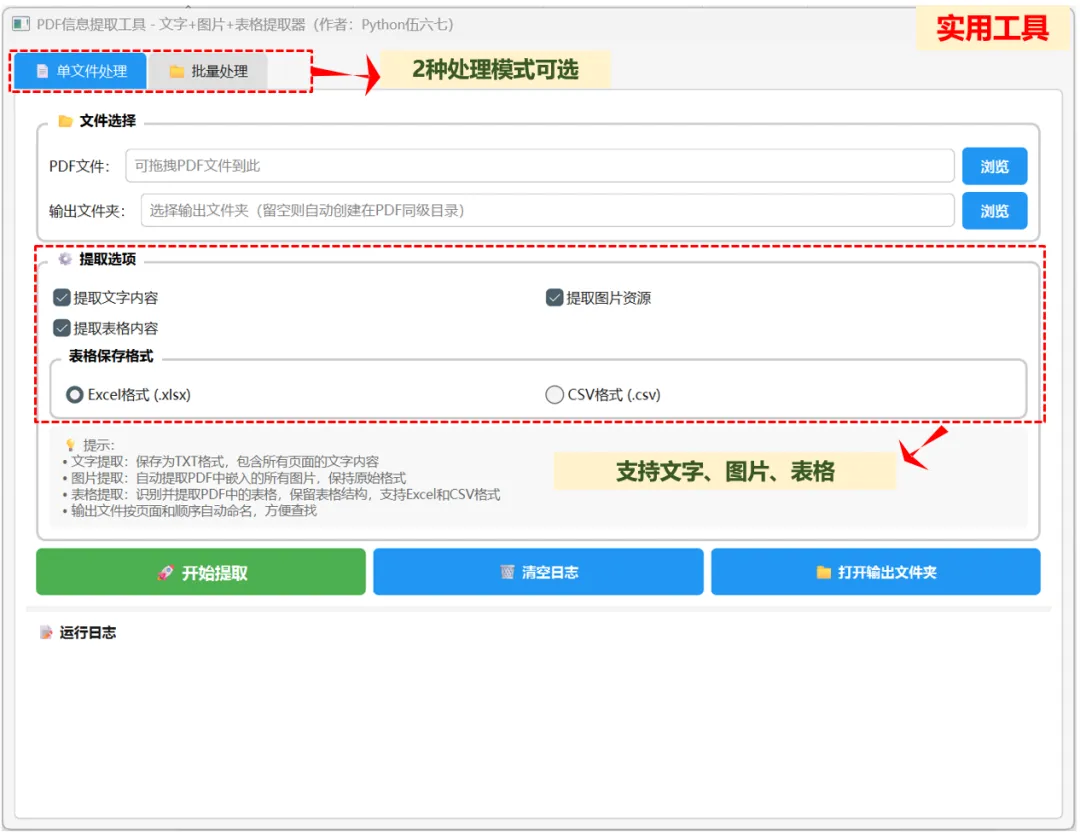
🎯 工具界面一览
✨ 功能简介:
✅ 多种信息提取:文字、图片、表格都能提取
✅ 批量处理:一次处理整个文件夹所有PDF,速度快
✅ 分类存放:提取的内容自动放进不同子文件夹
✅ 拖拽即用:PDF文件直接拖进窗口,自动填路径
✅ 实时进度:进度条可见,后台处理不卡顿
✅ 一键打开:提取完成自动跳转输出文件夹
🎬 操作步骤(简单4步):
①拖入PDF文件:直接把PDF文件或文件夹拖到窗口
②勾选提取项:文字、图片、表格(提取啥就勾啥)
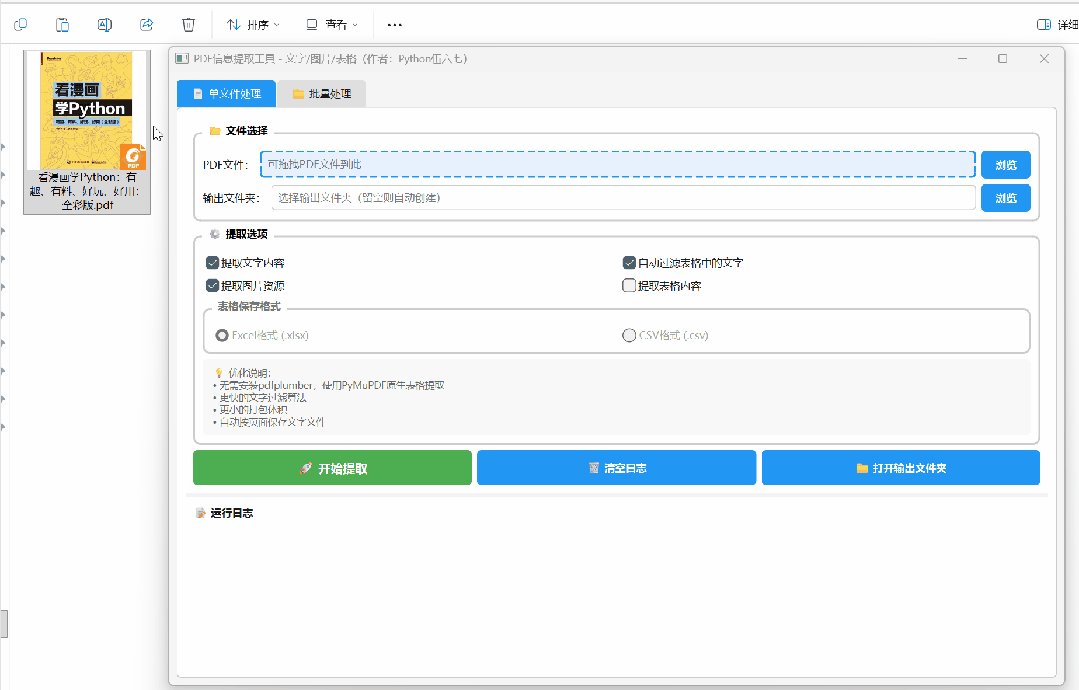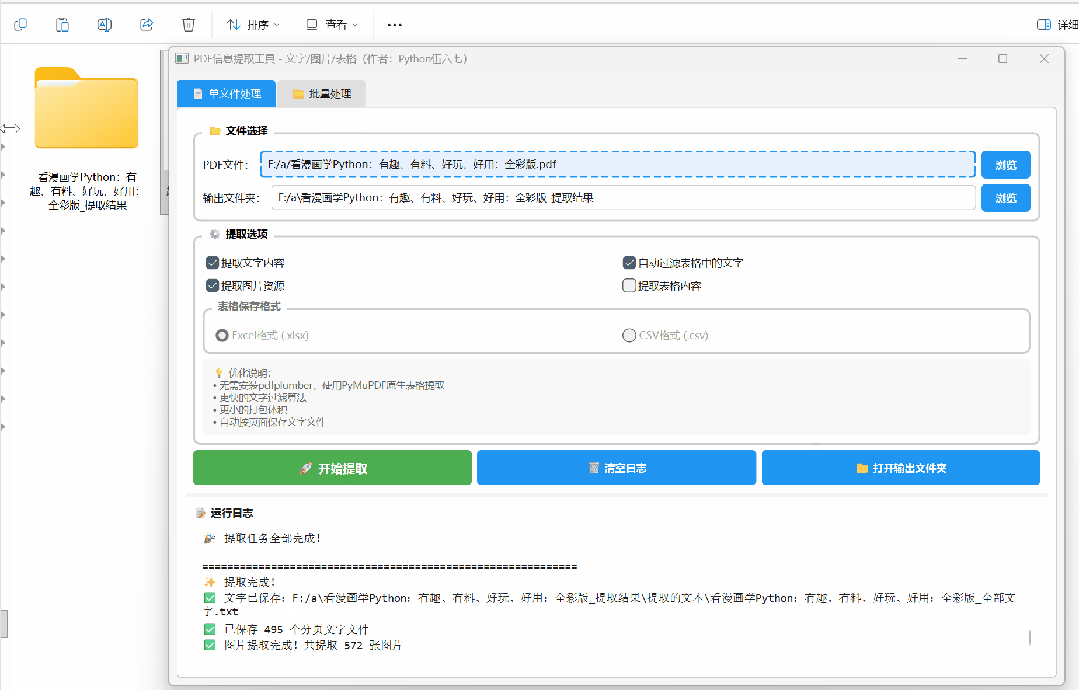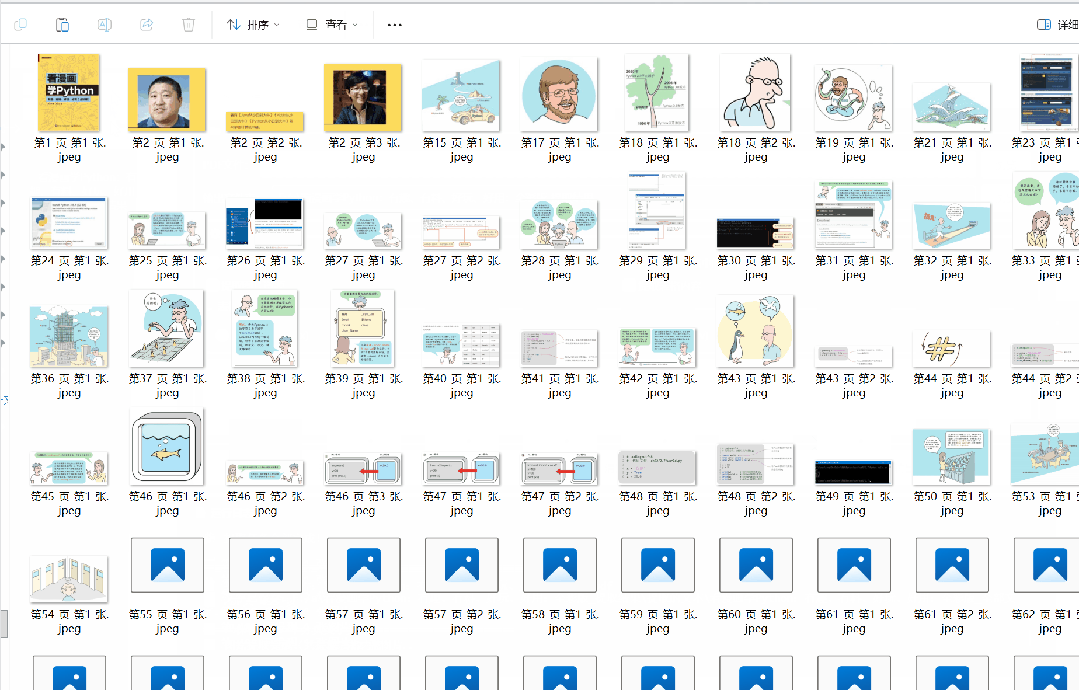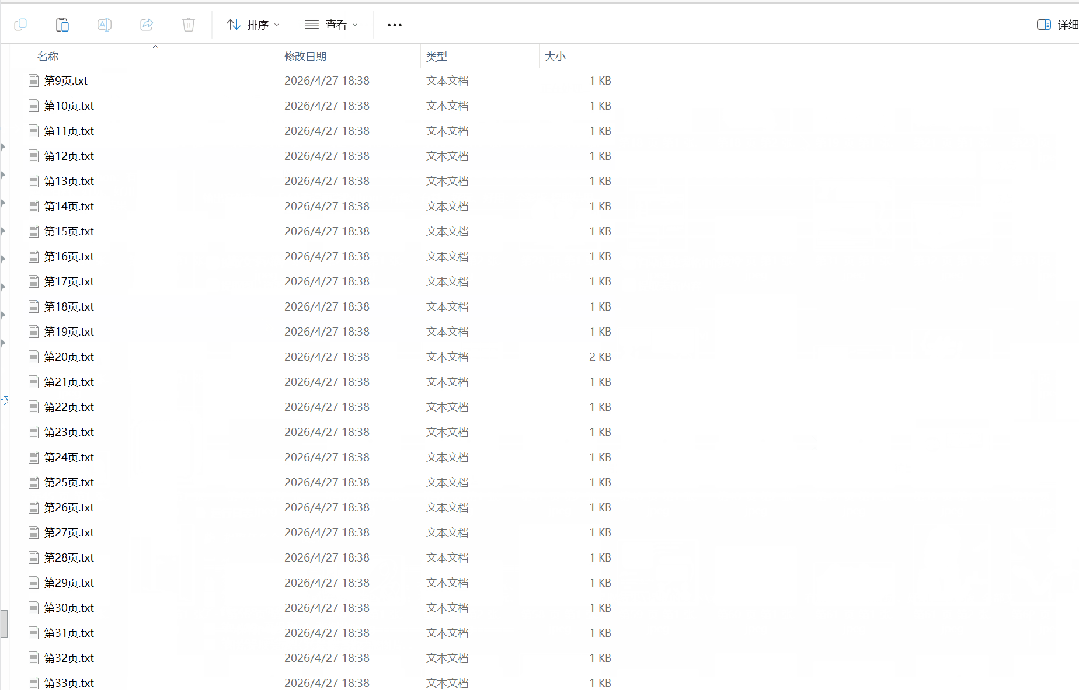
③点击开始:喝口水的功夫,自动提取完成
④打开文件夹:文字、图片、表格自动分类保存
🎬 提取示例:
🔒提取前的状态:

✅提取后的状态:
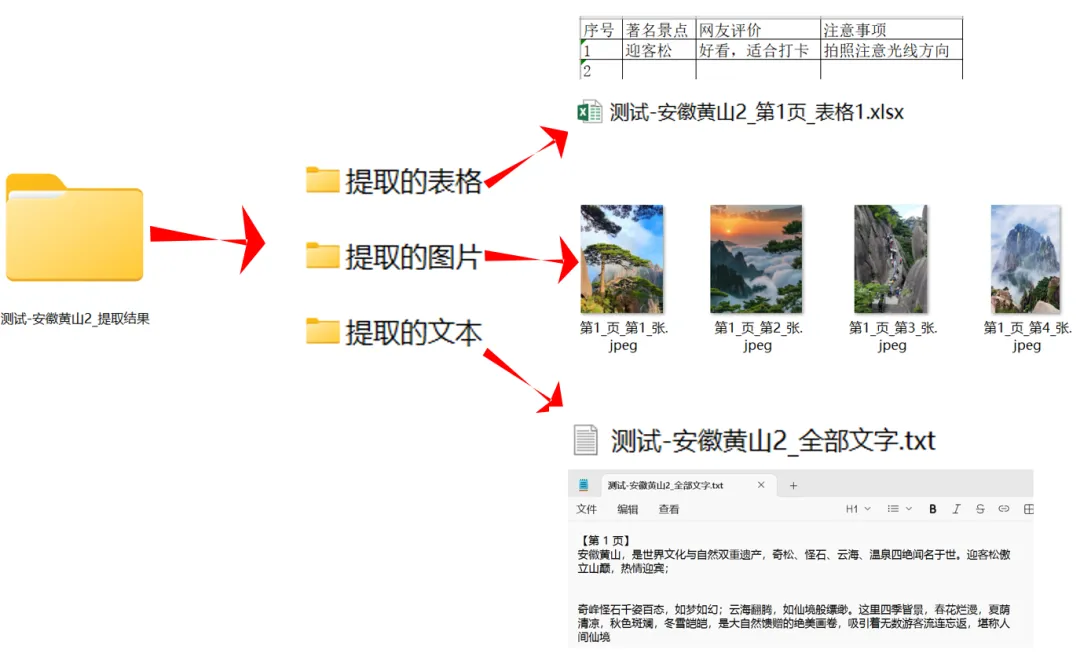
🔒电子书提取前的状态:
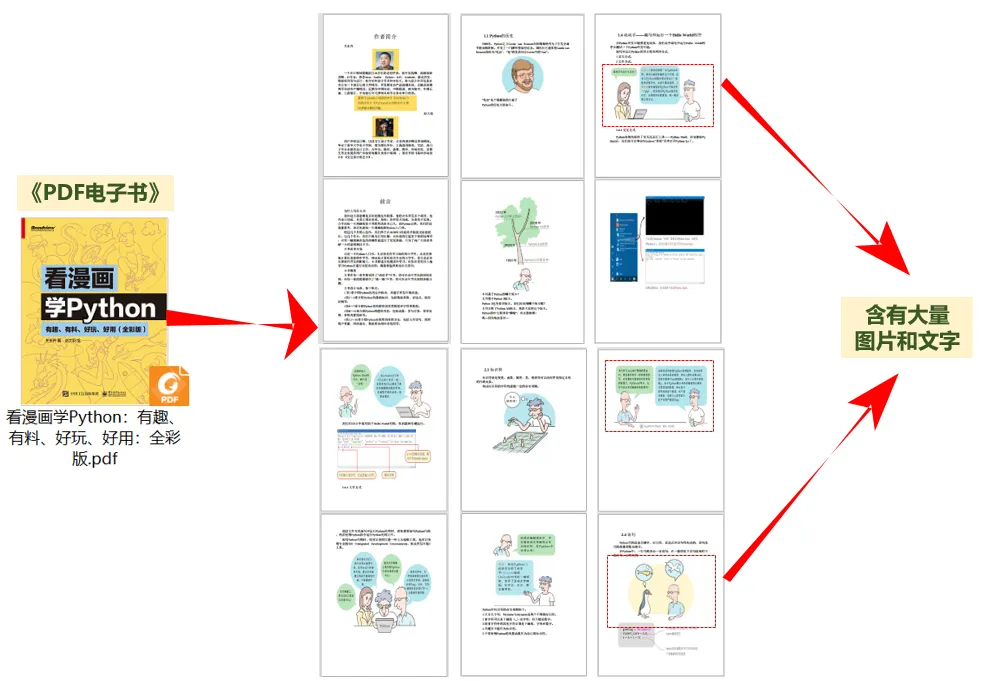
✅提取后的状态:
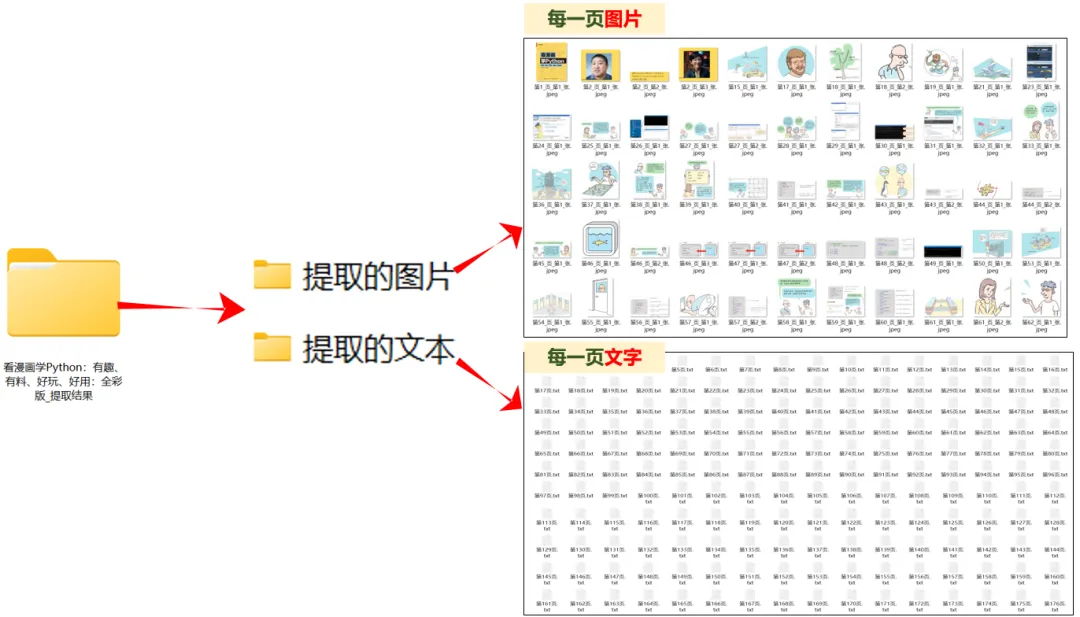
✅几百页的PDF电子书,被瞬间拆分成图片+文字,分页存放!
💬 常见问题
Q:会破坏原PDF文件吗?
A:不会!只"读取"内容,原文件完整保留,零风险
Q:能同时提取文字+图片+表格吗?
A:当然!一次性勾3个选项,全部提取分开保存
Q:页面多的PDF会卡吗?
A:实测500页PDF(含图片)10秒不到处理完不卡顿
Q:能批量处理多个PDF吗?
A:可以!选择"批量处理"模式,拖入整个文件夹,自动处理所有PDF文件,每个结果保存在独立子文件夹
Q:表格提取准确吗?
A:基于pdfplumber智能识别,普通表格基本完美保留,复杂表格(合并单元格、无边框)也能识别大部分结构
Q:表格支持什么格式?
A:支持Excel(.xlsx可用WPS/Office打开)通用格式,任何表格软件都能打开
📥 如何领取工具?
第①步:点赞,关注本公众号
第②步:后台发消息:数字"88"了解工具获取方法
✅无需代码基础,下载即用,一键运行!
📚 更多效率提升工具 ?
✅若需资料包和exe工具,后台发送”88“获取!
✅回复 "知识岛"关注知识分享区(获后续资料更新)💬 结 语
💡 关注我,每周分享Python干货×技巧
📌 如果这篇文章对你有帮助,欢迎:
👍 点赞 | ⭐ 收藏 | 🔄 分享给朋友
一起用 Python,让办公更轻松,让效率飞起来!🚀

👇点击阅读往期文章
