夜雨聆风
夜雨聆风

为了避免各位错过最新的推文教程,强烈建议大家将“科研后花园”设置为“星标”!



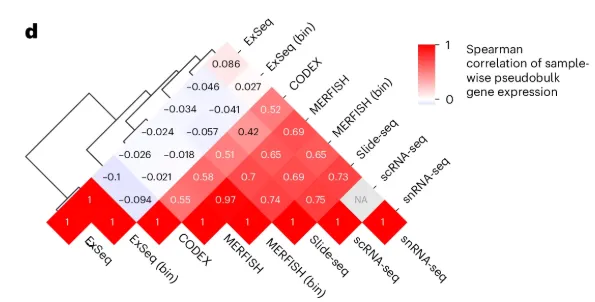
在数据分析中,我们经常面临这样的问题:几十个甚至上百个变量(比如基因、代谢物、调查指标、经济数据)之间,谁和谁关系近?谁和谁对着干?它们之间有没有自然的组团?相关性热图 + 聚类树正是回答这些问题的利器。今天,我们就用R语言从原始数据出发,一步步绘制一张下三角相关性热图 + 变量聚类树的组合图。图中既有相关系数的颜色和数字,又有变量的层次聚类关系。最关键的是——代码完全通用,你只需要替换自己的数据,就能一键出图!
一、这张图到底长啥样?有什么用处?
图形构成:
左侧:变量的层次聚类树(基于距离,比如Bray-Curtis或欧氏距离)
右侧:下三角相关性热图(Spearman或Pearson相关系数 + 色块 + 数字)
对角线:变量名称直接标注在右侧(不覆盖数值)
颜色:负相关→蓝色,正相关→红色,白色→无相关,颜色越深相关性越强
核心用途:
快速识别正相关/负相关较强的变量对
通过聚类树发现模块化(抱团)的变量群体
适合变量数量在10~60个之间的任何数据集(丰度、浓度、评分、指标等)
二、数据格式与预处理
你的数据只需要是一个行为样本、列为变量的数值矩阵(可以是微生物OTU丰度、代谢物峰面积、地区经济指标、学生成绩等)。
我们的代码会:
对变量进行聚类(所以需要对原始矩阵转置)
计算变量间的Spearman相关系数(可改成Pearson)
绘制下三角热图 + 聚类树组合
三、完整R代码(可复制运行)
######### 正三角相关性热图 + 聚类树(通用版)#########setwd("你的工作路径") # 请修改# 加载包library(ggplot2)library(vegan) # 计算Bray-Curtis距离(可换成其他距离)library(ggtree)library(ape)library(reshape2)library(dplyr)library(aplot) # 用于拼图 insert_left# 读取数据(行为样本,列为变量)df <- read.table("data.txt", header = TRUE, check.names = FALSE, sep = "\t", row.names = 1)# 1. 对变量进行层次聚类(基于Bray-Curtis距离,可改)df_dist <- vegdist(t(df), method = "bray") # 转置后对变量聚类df_hc <- hclust(df_dist, method = "complete")df_tree <- as.phylo(df_hc)# 2. 计算相关性矩阵(Spearman方法,可改)df_log <- log10(df + 0.000001) # log转换避免零值问题(可选)df_cor <- cor(df_log, method = "spearman")# 3. 按聚类顺序重排相关矩阵df_cor_reorder <- df_cor[df_hc$order, df_hc$order]# 4. 保留下三角(右上角设为NA,避免重复)df_cor_reorder[upper.tri(df_cor_reorder)] <- NA# 5. 在右侧增加一列空白,用于后续放置变量名标签mat_blank <- cbind(df_cor_reorder, blank = NA)colnames(mat_blank)[ncol(mat_blank)] <- " "# 6. 转换为长格式(适合 ggplot2)df_melt <- melt(mat_blank, varnames = c("Var1", "Var2"), value.name = "cor")df_melt$cor <- round(df_melt$cor, 2)# 7. 对角线标签数据(单独添加变量名)diag_labels <- data.frame(Var1 = colnames(df),Var2 = colnames(df),label = colnames(df))# 8. 绘制聚类树(只显示拓扑结构,不显示枝长)p_tree <- ggtree(df_tree, size = 0.6, branch.length = "none",ladderize = FALSE, show.legend = FALSE)# 9. 绘制下三角相关性热图p_heat <- df_melt %>%ggplot() +geom_tile() +geom_text() +geom_text()# 10. 组合图形:树放在热图左侧,宽度比 1:5p_heat %>% insert_left(p_tree, width = 0.2)
最后将图形调整至合适大小并导出为PDF格式,导入**AI或PS**等修图软件中对图形进行旋转及美化即可!!!
四、结果解读与图形美化
4.1 怎么读这张图?
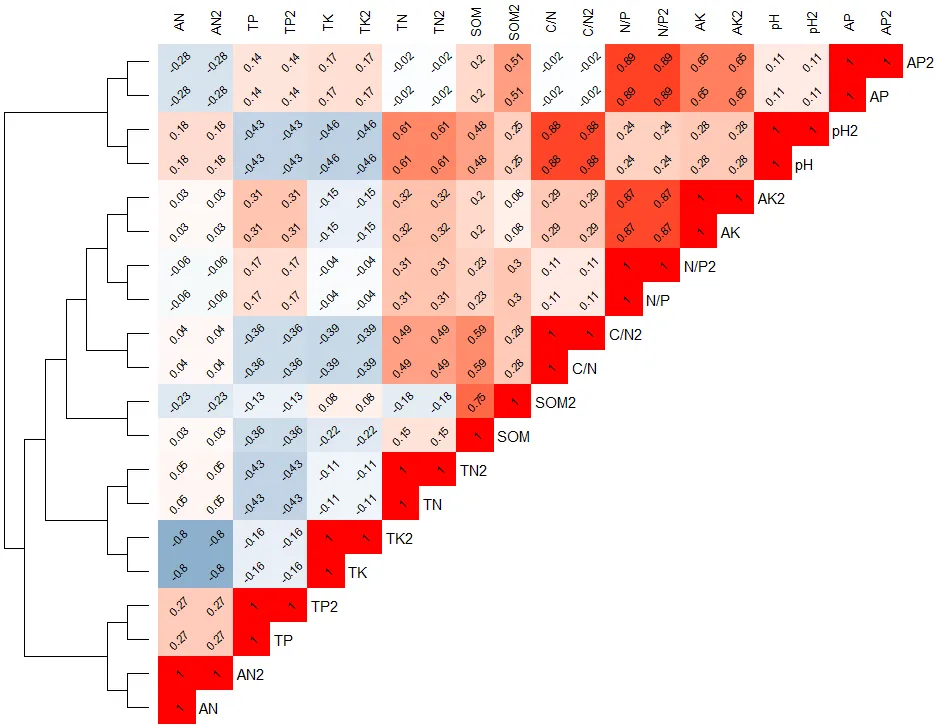
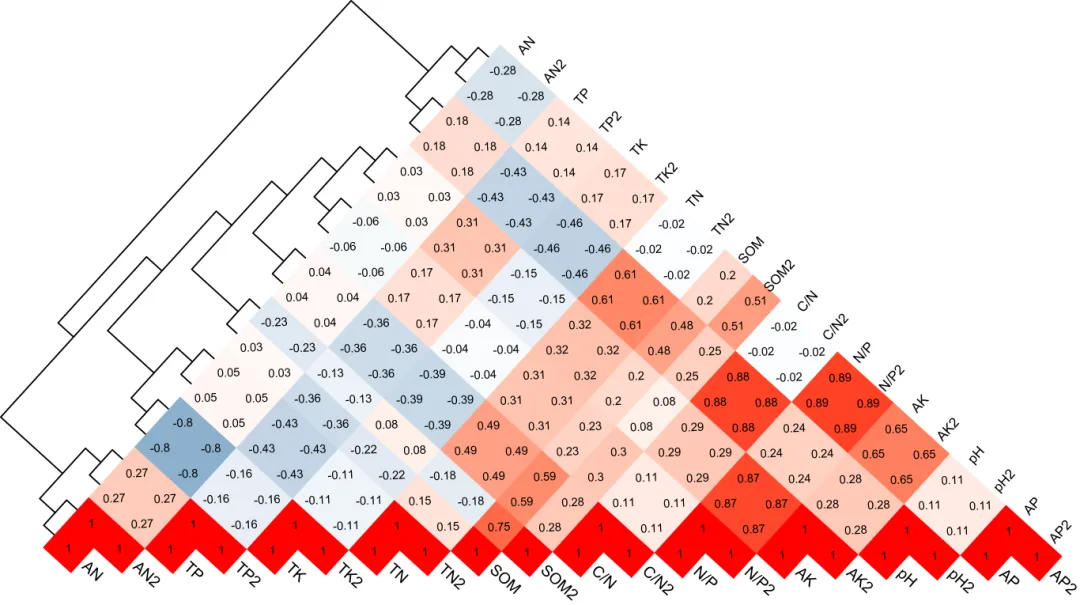
左侧的树:每个叶子是一个变量,树的分支结构反映了变量之间的相似性(基于Bray-Curtis或欧氏距离)。越早合并在一起的变量,在原始数据模式上越相近。
右侧热图:只有下三角有颜色和数字,避免信息冗余。颜色从蓝到红表示相关系数从-1到+1。
对角线:变量名被巧妙放置在热图右侧的空白列中,不覆盖数值。
数字:每个格子里的数值是具体的相关系数(保留两位小数),方便精确阅读。
4.2 常见调整
method = "pearson" | |
vegdist(..., method = "euclidean")dist(..., method = "manhattan") | |
geom_text(aes(label = cor)) | |
low, mid, high 参数 | |
size 参数,或全局设置 theme(text = element_text(size = 12)) | |
axis.text.x 的 size 或旋转角度 |
五、常见问题(FAQ)
Q1:为什么我的树和热图的行顺序对不上?A:需要确保聚类顺序 df_hc$order 被正确应用到热图的行和列。我们的代码已经通过 df_cor[df_hc$order, df_hc$order] 做了重排,并且热图的 aes(Var2, Var1) 会使用 Var2(列)为x轴、Var1(行)为y轴。只要 Var1 因子水平也是按照 df_hc$order 设置的,就不会错位。
Q2:我想在热图中添加显著性星号(*)怎么做?A:需要额外计算每个相关系数的p值,然后将其星号作为新列合并到 df_melt 中,再使用 geom_text(aes(label = sig)) 叠加。
Q3:我的数据不适合做log转换?A:可以跳过 df_log <- log10(df + 0.000001) 这一步,直接使用原始数据计算相关系数。但注意原始数据量级差异大时,Spearman相关不受影响,Pearson可能受极端值影响。
Q4:insert_left 报错“找不到函数”A:安装并加载 aplot 包即可:install.packages("aplot")。
六、总结
这张“下三角相关性热图+聚类树”组合图将变量聚类和变量间相关性集中展示,特别适合在探索性数据分析阶段快速发现变量间的内在结构。整个流程完全用R实现,可复现性强,且不依赖于特定领域数据。
希望这篇教程能帮助你更高效地展示自己的数据关系。有任何问题或更好的建议,欢迎在公众号后台留言!
希望这篇教程对大家的科研绘图有所帮助!欢迎关注科研后花园公众号,获取更多科研绘图技巧。
公众号:科研后花园原创教程,转载请注明出处
PS: 以上内容是小编个人学习代码笔记分享,仅供参考学习,欢迎大家一起交流学习。


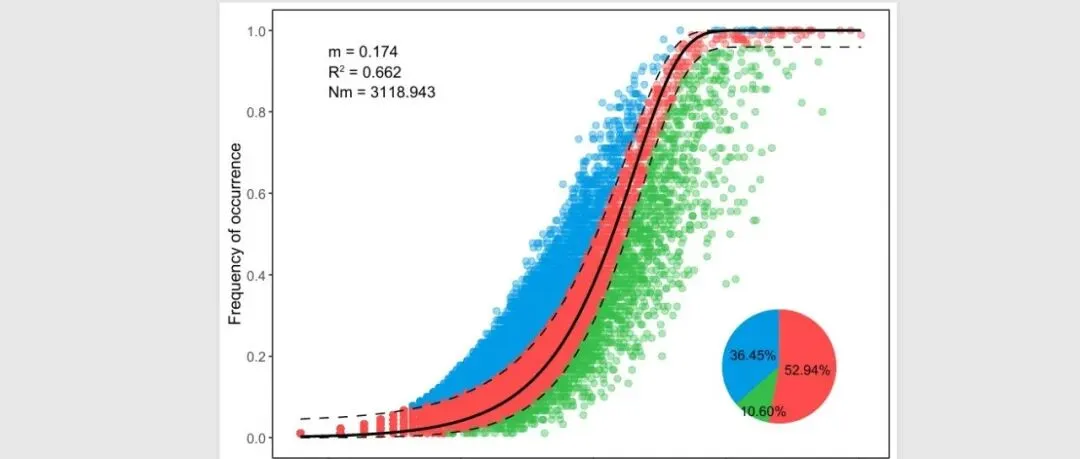
「R绘图模板」中性群落模型:解密微生物群落构建的“随机密码”!!!
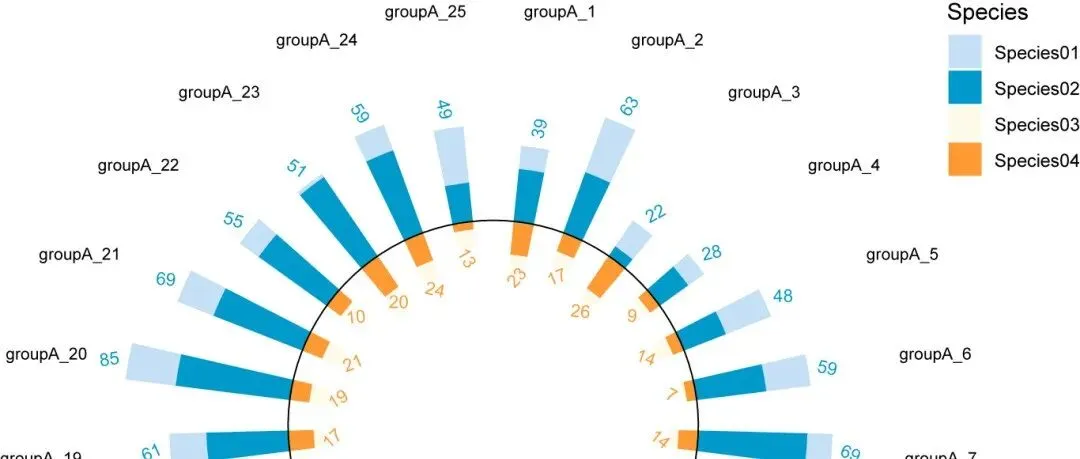
「R绘图模板」环形双向柱状堆积图+标签:让数据“内外兼修”!!!
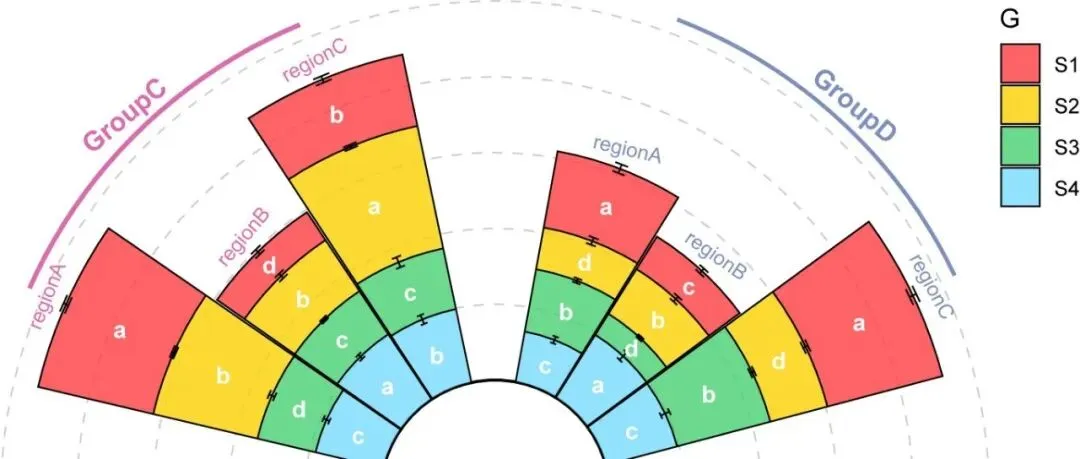
「R绘图模板」环形并列柱状堆积图+误差线+组内显著性字母标记!!!
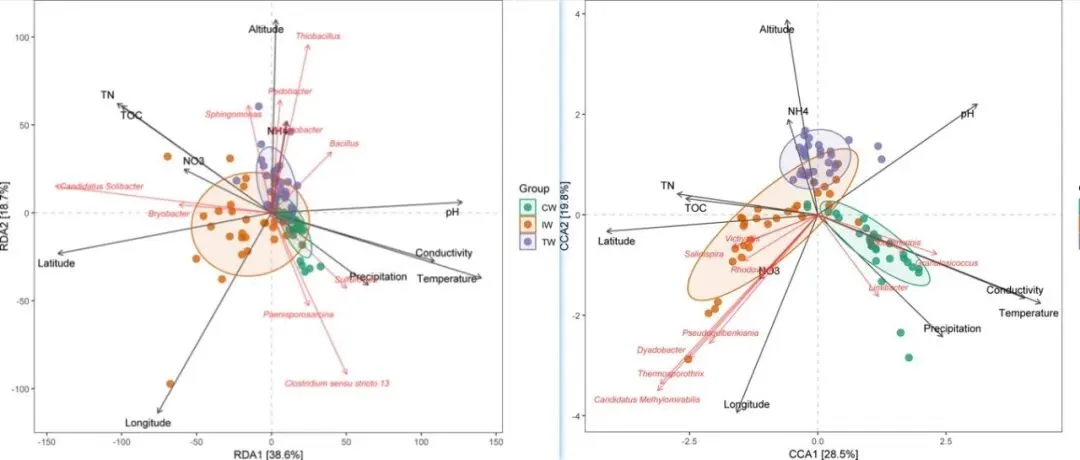
「R绘图模板」RDA&dbRDA&CCA可视化!!!
「R绘图模板」Communications Earth & Environment | 组合图系列—曼哈顿图+Venn图展示富集OTU情况!!!
「R绘图模板」Science Advances | 组合图-并列柱状图+饼图+折线图!!!
「R绘图模板」J. Agric. Food Chem. | 分面组合图-字母标记显著性柱状图+传统显著性标记箱线图!!!
「R绘图模板」主成分分析(PCA)+各类型边缘图!!!
「R绘图模板」Field Crops Res. | 组合图系列—三元图+条形图展示微生物丰度信息!!!
「R绘图模板」Nat. Commun | 复杂tree注释—分支颜色+多层离散热图+分组条形图!!!
「R绘图模板」多色系热图+分组气泡图!!!
「R绘图模板」配对连线图+均值点及连线+显著性+嵌套分组!!!