 夜雨聆风
夜雨聆风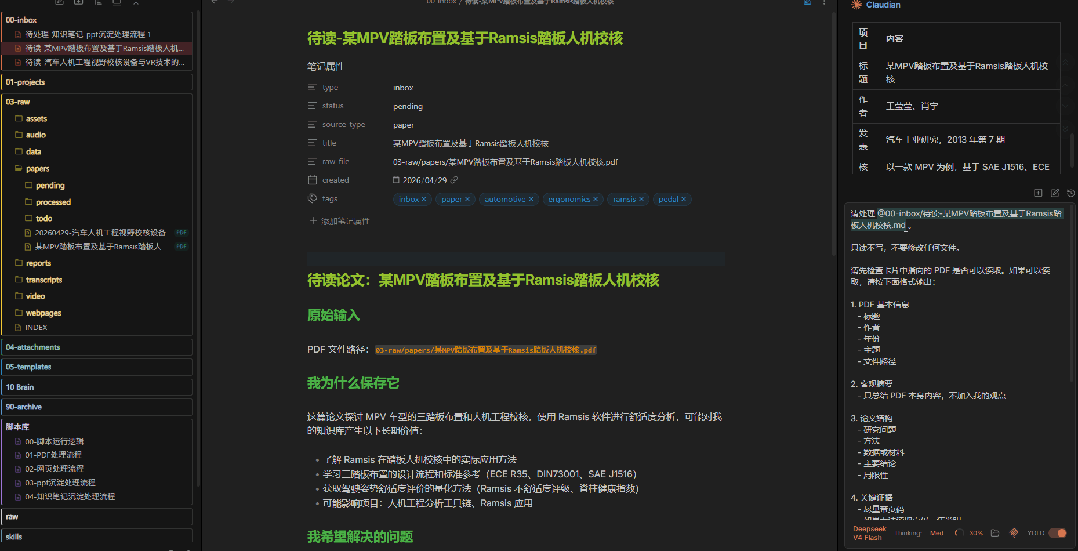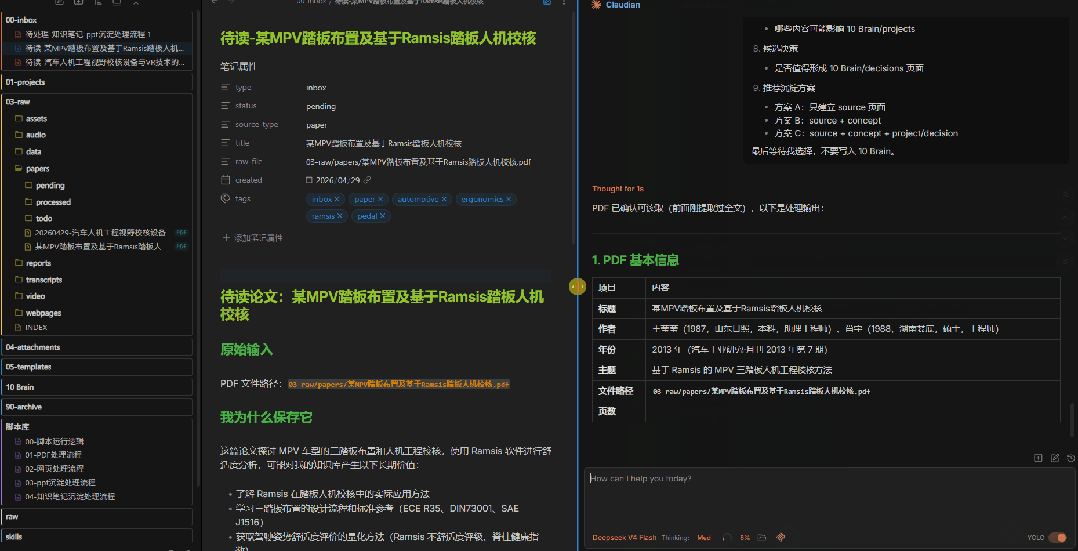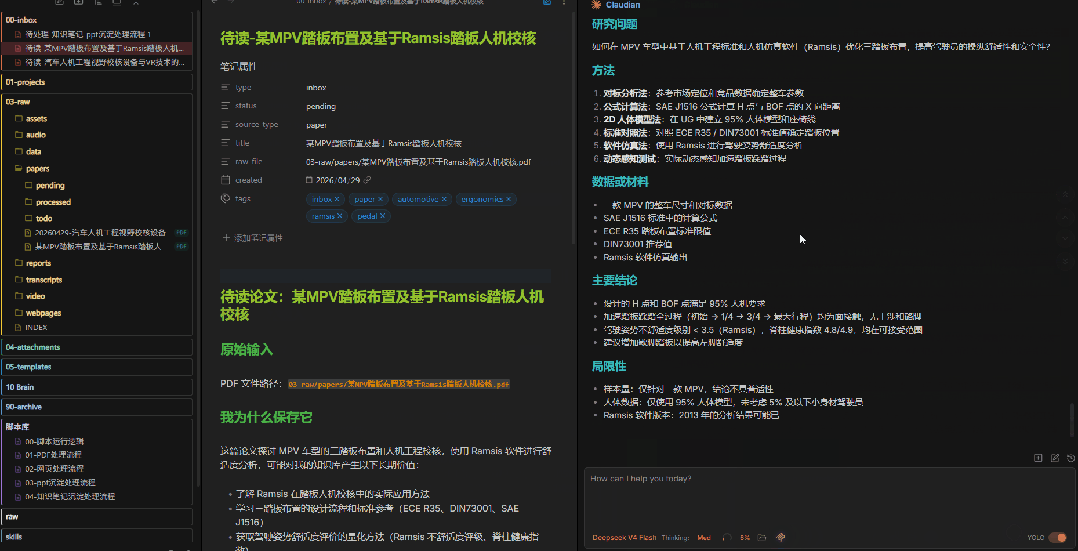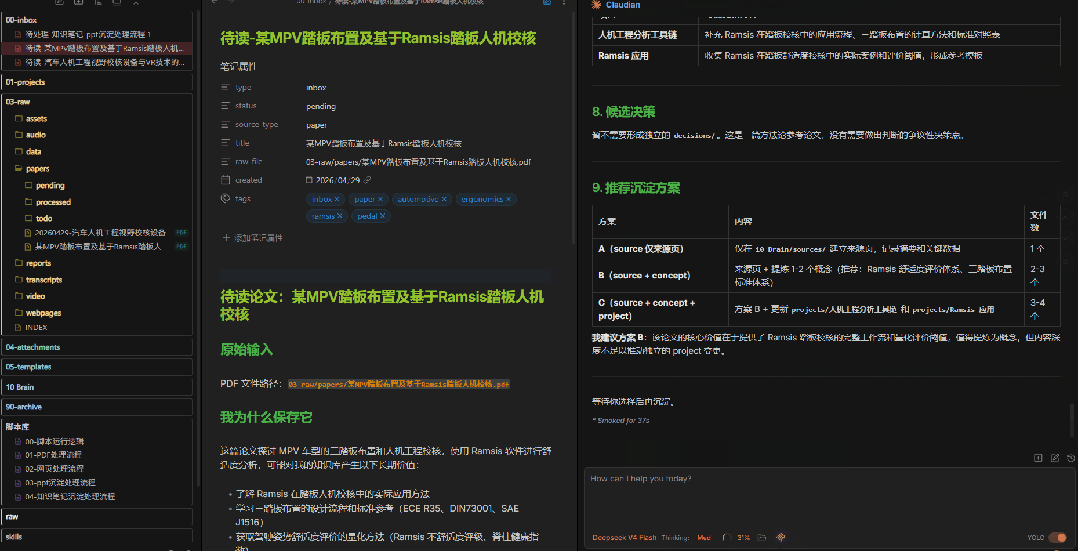
一个不懂代码的车辆工程师,能不能用好AI?
大家好,我是虎哥,二十年车辆研发经验的高工。
AI很热,工具很多,变化也很快。 但对我这样的传统工程师来说,真正的问题是:
它到底能不能帮我们解决实际工作中的问题?
我不敢说自己懂AI,也知道自己有很多局限。 但正因为这样,我的尝试可能更接近普通工程师的真实状态。
今天围绕 【如何将一篇PDF类的论文沉淀为"自有"的知识库知识】,分享一点我的实战和收获。
如果你是工程师、研究者,或者任何需要长期跟技术文档打交道的人,这套流程应该能给你一些启发。
欢迎交流。
1、核心目标
先一句话说清楚我们在做什么:
PDF长篇知识进入 → AI 提取候选观点 → 你选择认可观点 → AI 按你的选择沉淀进知识库这条流水线的关键不在AI提取得有多快,而在 "你选择"这三个字。
知识沉淀这件事,最难的不是整理,是判断。哪些值得留下?哪些跟你有关?哪些只是一家之言? AI可以帮你节省提取和整理的时间,但最终的选择权必须在你手上。让AI协助人,而不是AI替代人——这是整套流程的底层逻辑。
2、导入PDF文件至指定目录
首先,把原始PDF放入 03-raw/ 目录。这个目录是"冷库",专门放原始资料,原则上只读不修改。
然后把一条指令发给AI,让它自动生成一张处理卡片到 00-inbox/:
请导入 D:\迅雷下载\人机相关论文\某MPV踏板布置及基于Ramsis踏板人机校核.pdf 至 @03-raw/ 文件夹,并自动生成 `00-inbox` 处理卡片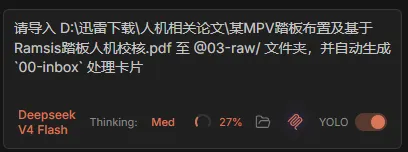
为什么要分两步(原始资料放 03-raw/,处理卡片放 00-inbox/)? 因为原始资料不是知识,经过提炼、批注、链接后的结构化Markdown才是。把两者分开,你就不会在知识库里堆满没处理过的PDF。
3、AI自主保存并生成暂存卡片
AI收到指令后,会:
03-raw/papers/ 目录下00-inbox/ 自动生成一张"待读"处理卡片整个过程是自动的,不需要你手动创建文件夹或写文件名。

4、得到卡片
卡片生成后,它的作用是提醒你"这里有份资料需要你处理"。
卡片里不会直接写结论,而是包含:
这些内容决定了后续AI往哪个方向提取信息。
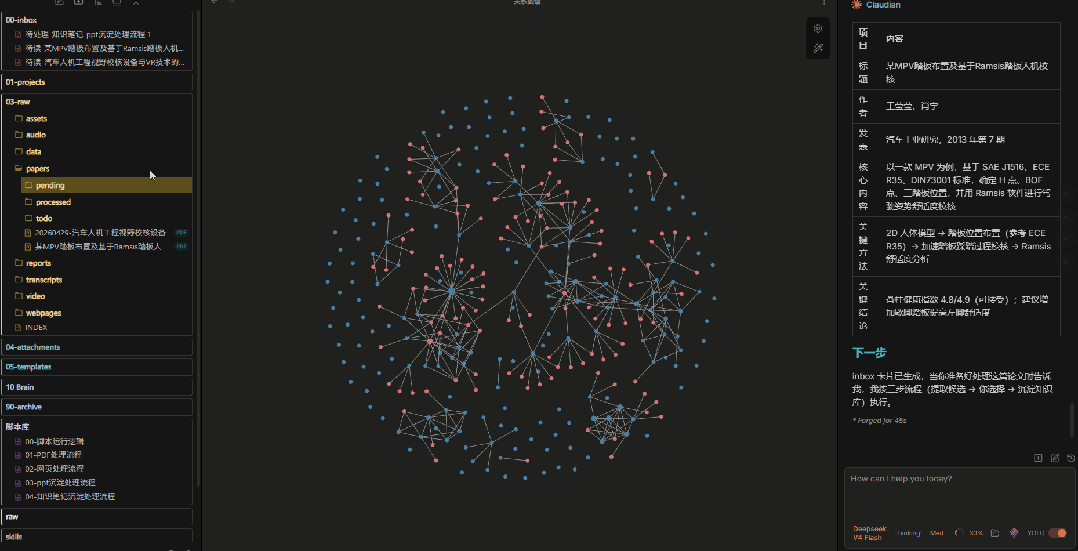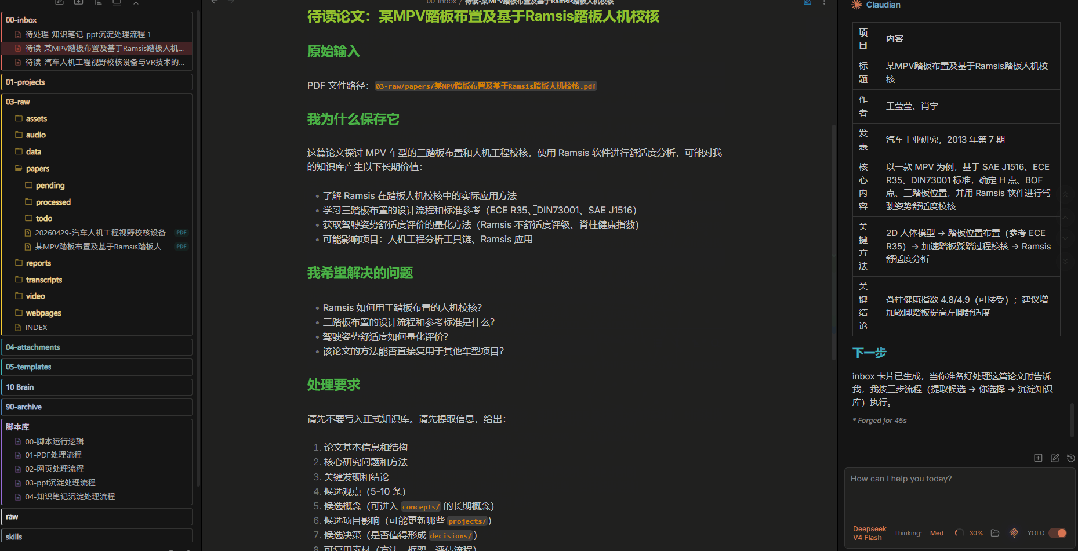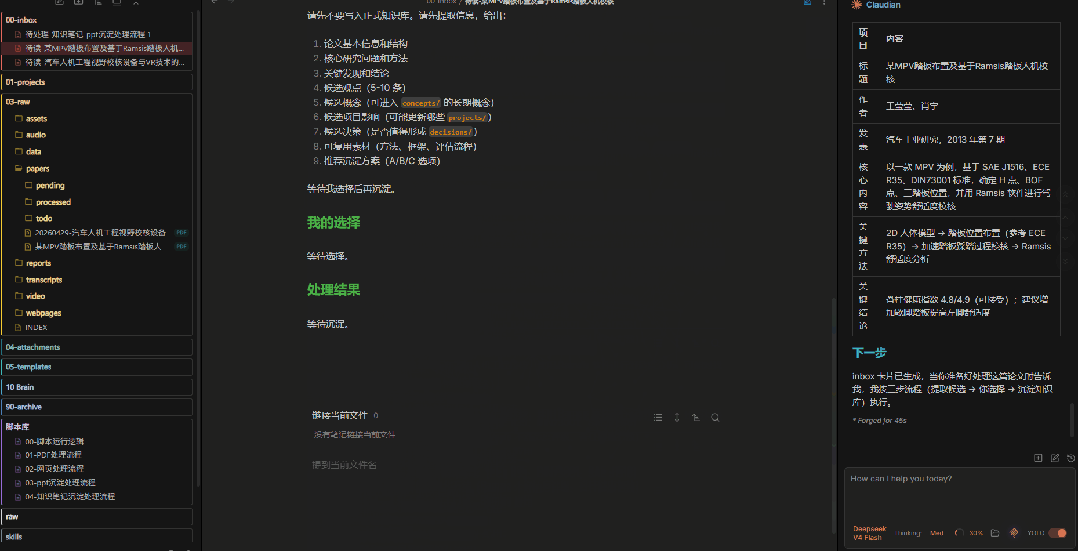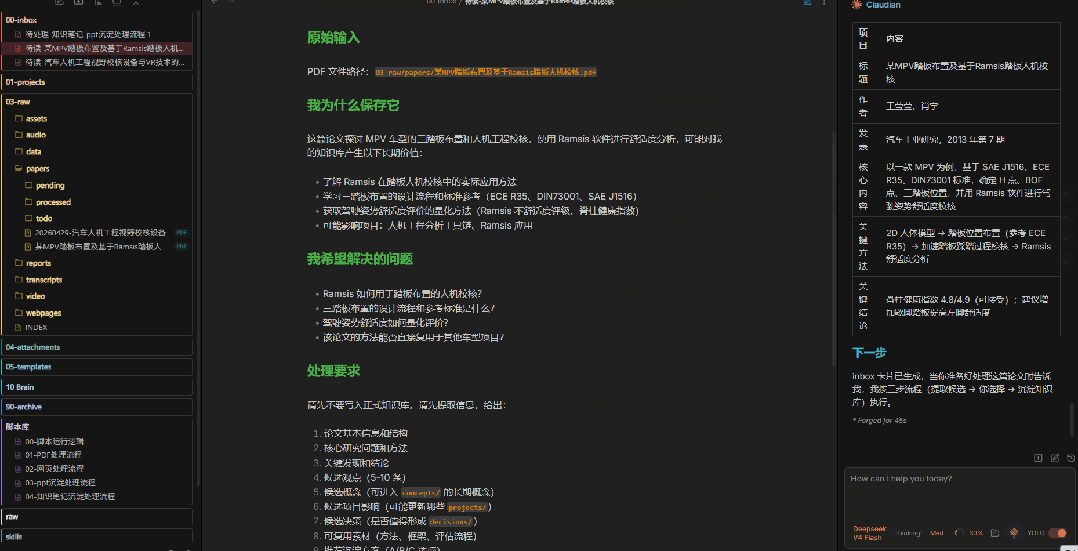
5、AI协助先输出候选观点,不要写入知识库
卡片就位后,到了最关键的一步:让AI先干体力活,把判断留给人。
我用的提示词是这样的:
请处理 @00-inbox/待读-某MPV踏板布置及基于Ramsis踏板人机校核.md 。只读不写,不要修改任何文件。请先检查卡片中指向的 PDF 是否可以读取。如果可以读取,请按下面格式输出:1. PDF 基本信息 - 标题 - 作者 - 年份 - 主题 - 文件路径2. 客观摘要 - 只总结 PDF 本身内容,不加入我的观点3. 论文结构 - 研究问题 - 方法 - 数据或材料 - 主要结论 - 局限性4. 关键证据 - 尽量带页码 - 如果无法读取页码,请说明5. 候选观点 - 给我 5-10 条可能值得沉淀的观点 - 注意:这些只是候选,不代表我的观点6. 候选概念 - 哪些内容适合沉淀到 10 Brain/concepts7. 候选项目影响 - 哪些内容可能影响 10 Brain/projects8. 候选决策 - 是否值得形成 10 Brain/decisions 页面9. 推荐沉淀方案 - 方案 A:只建立 source 页面 - 方案 B:source + concept - 方案 C:source + concept + project/decision最后等待我选择,不要写入 10 Brain。注意提示词里的关键约束:"只读不写""不要写入 10 Brain""等待我选择"。 这三句话是边界——AI只做提取和整理,不做最终判断。
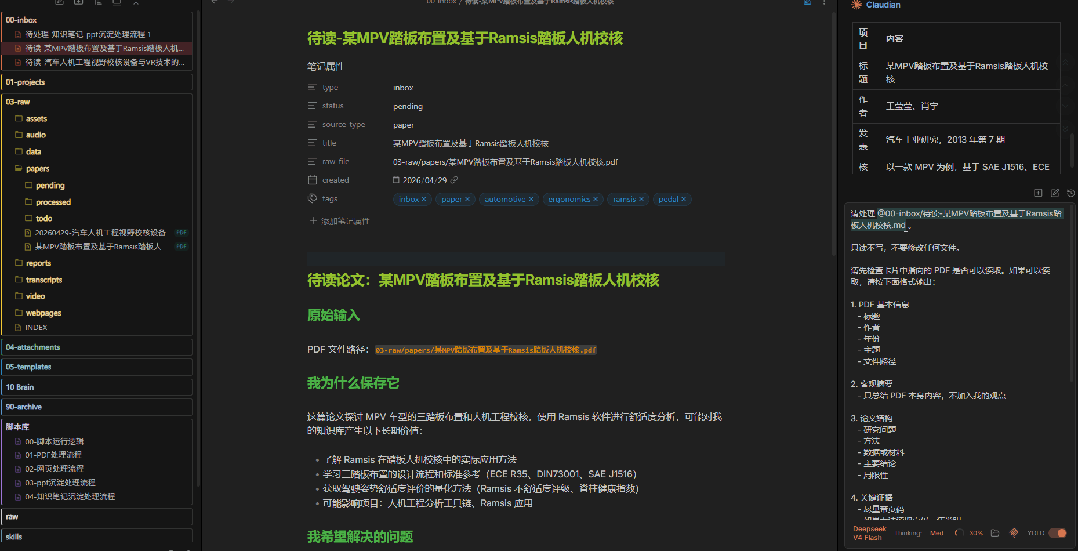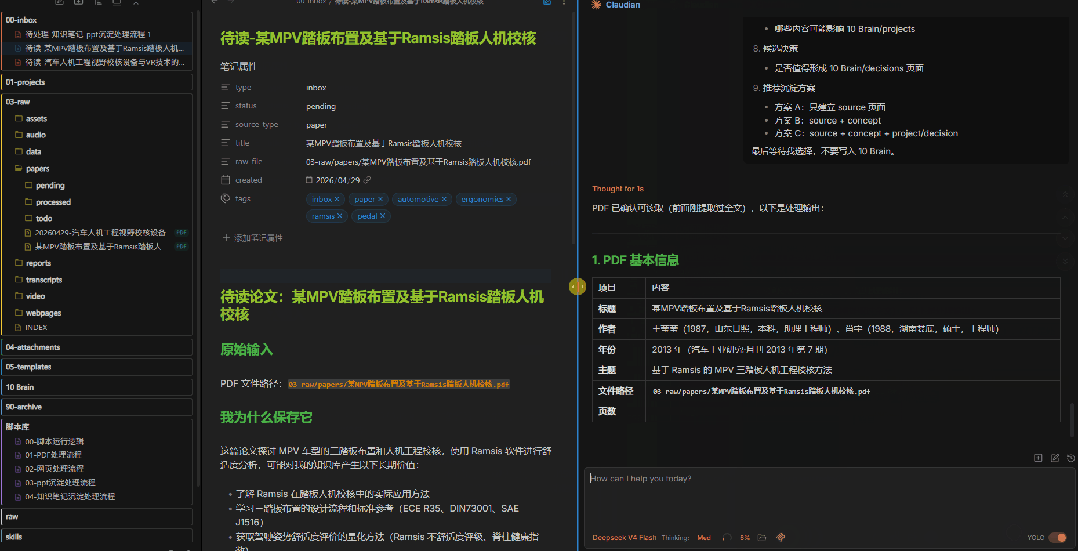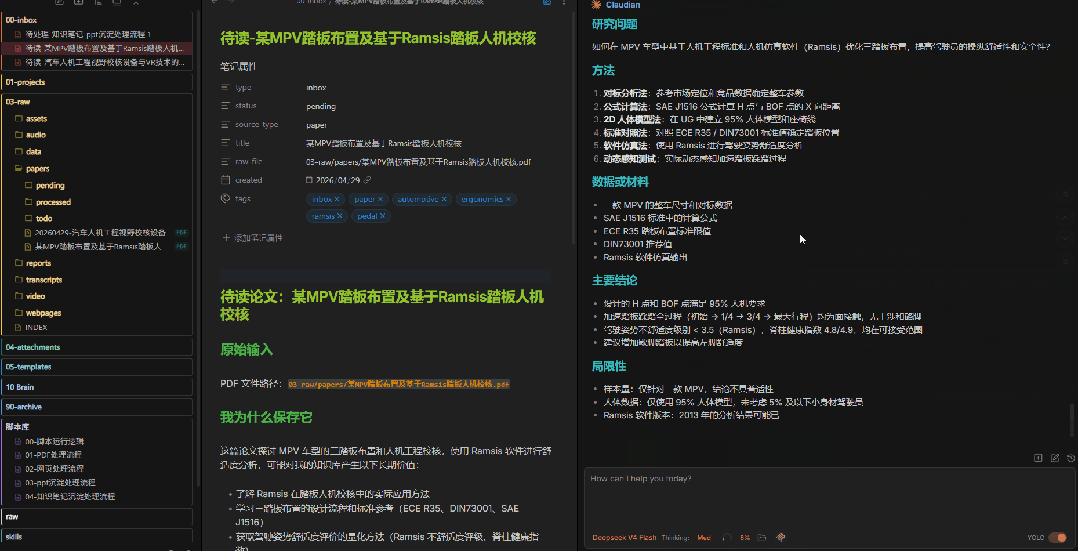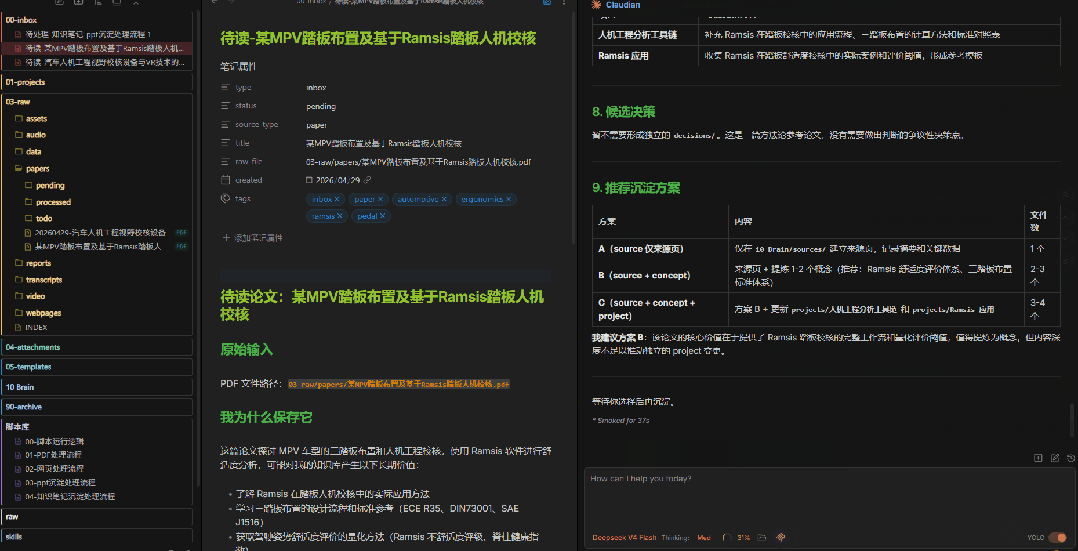
6、人工选择候选观点,内化为自己的观点,并制定沉淀计划
AI输出候选观点后,轮到你上场了。
你会看到AI列出的5-10条候选观点、候选概念和推荐方案。这时候你需要——像做选择题一样——勾选你认可的内容。
我用的是这个提示词:
我选择以下内容:候选观点:1、3、5候选概念:A、C候选项目影响:暂时不更新项目候选决策:建立一个 decision 页面,记录我决定采用观点 3 作为后续判断依据请先给我最终写入计划,包括:1. 会新建哪些文件2. 会修改哪些文件3. 每个文件写入什么内容先不要执行,等我确认。这一轮我加了一个保险:让AI先把写入计划列出来,我再确认一遍。 为什么? 因为AI可能会"理解过头",在你不注意的地方替你加了你没选的内容。 多一道确认,少一次后悔。
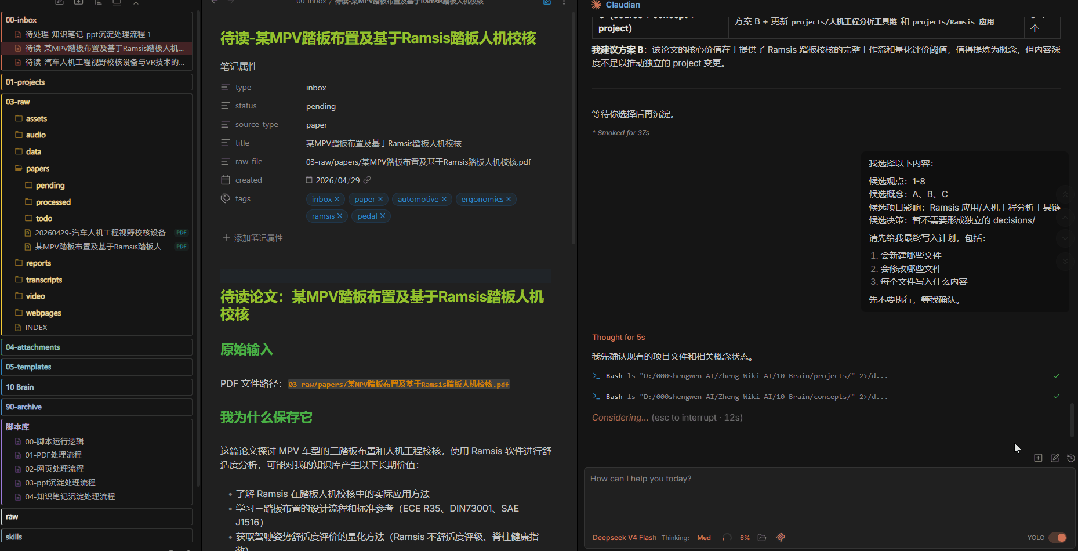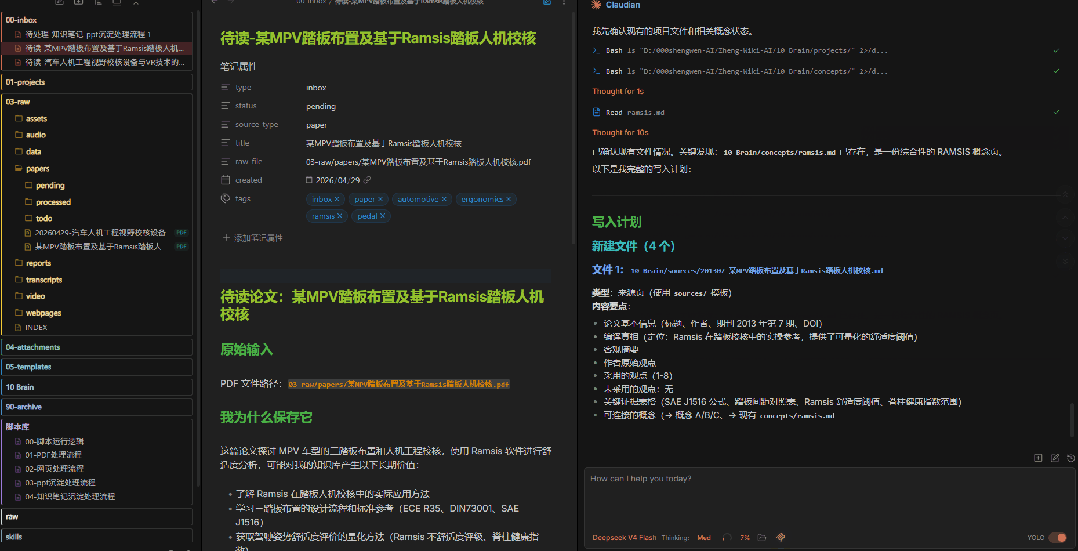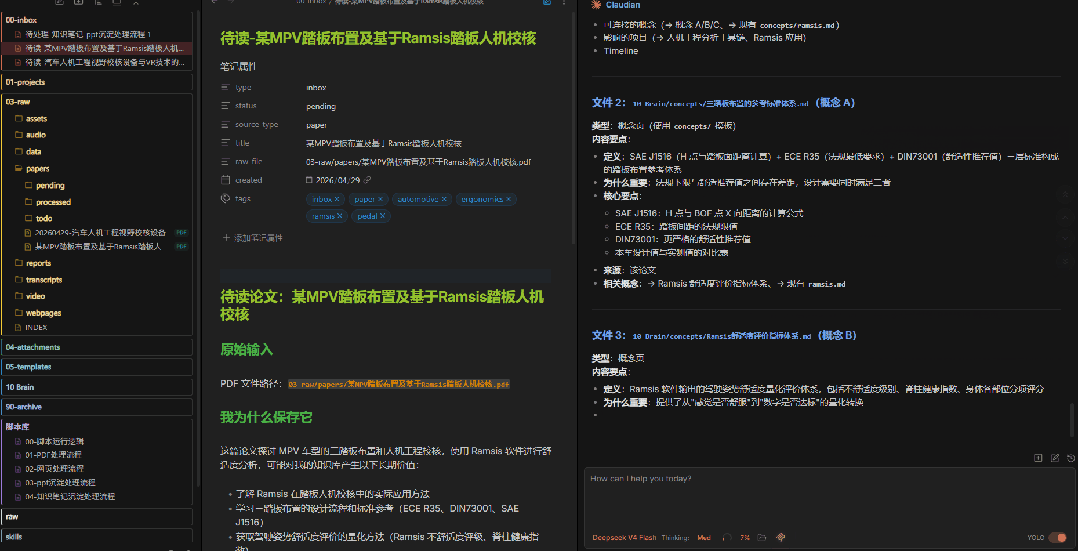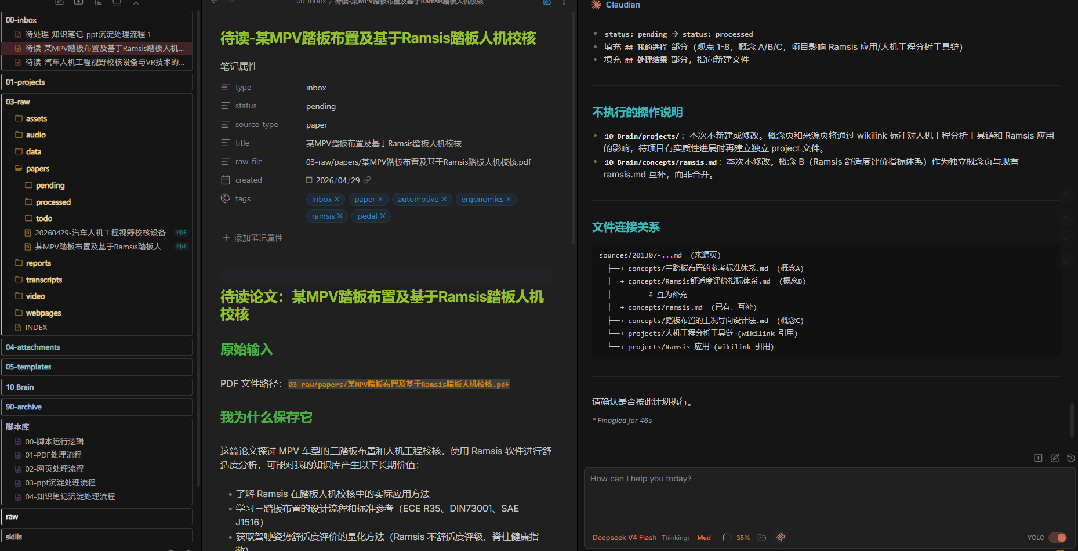
7、AI自动执行沉淀
计划确认无误后,说一句"可以执行",AI就会按照你确认的计划,把内容写入 10 Brain/ 正式知识库。
包括:
10 Brain/sources/ 来源页10 Brain/concepts/ 概念页10 Brain/decisions/ 决策页整个过程不需要你手动复制粘贴,也不需要你去翻目录找文件。
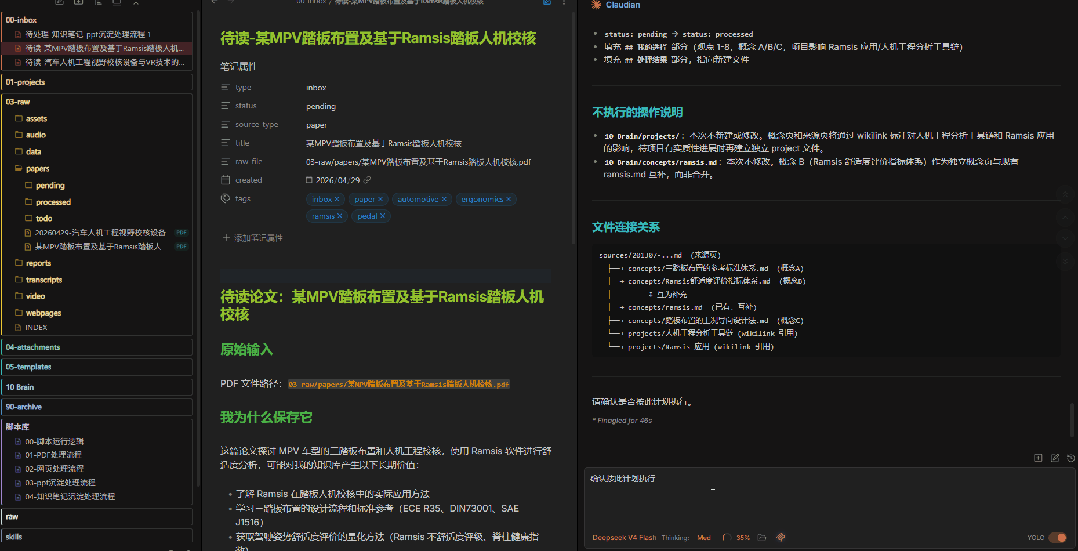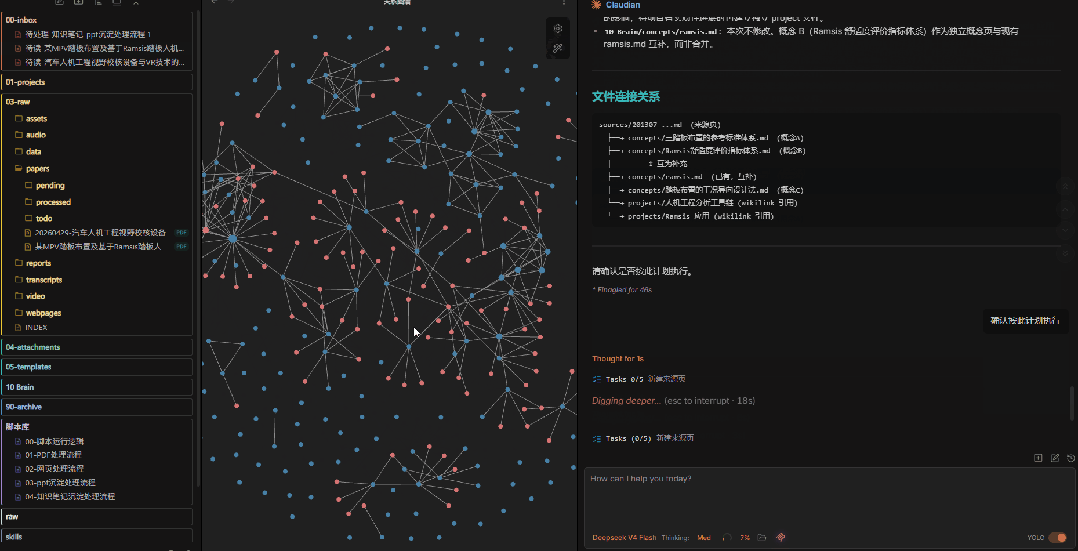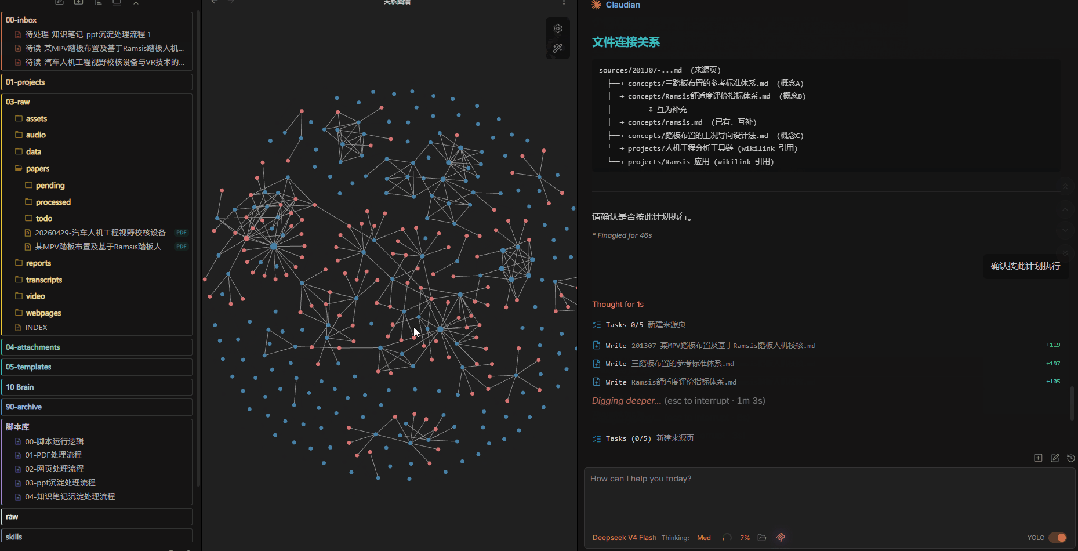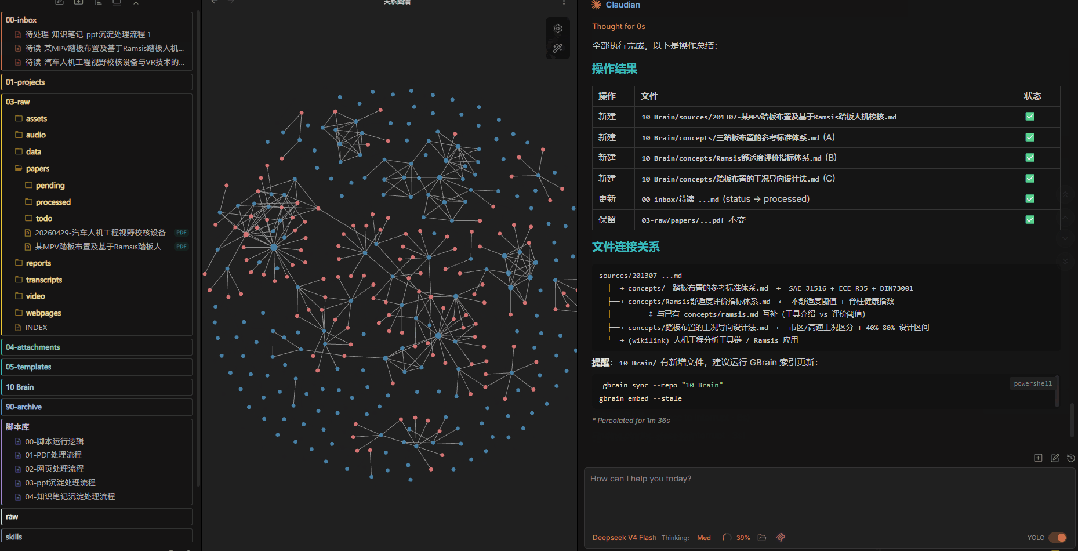
8、自动更新知识库索引
文件写入完成后,还有一个重要步骤:更新索引。
我的知识库使用 GBrain 做语义索引。写入新内容后,需要同步并重新生成 embedding,这样后续搜索时才能找到相关内容。
这一步也交给AI来做——它会自动执行索引更新命令。
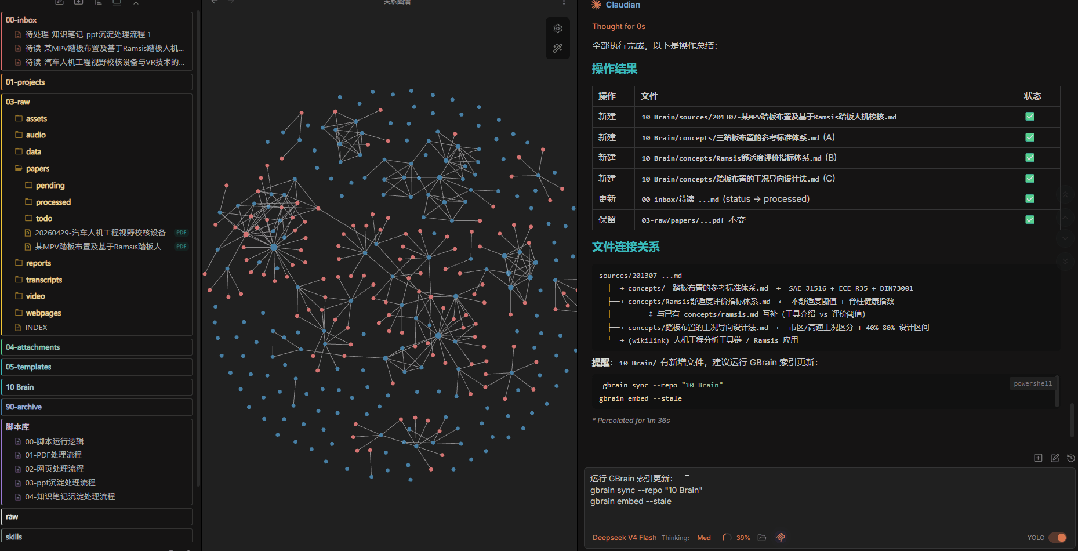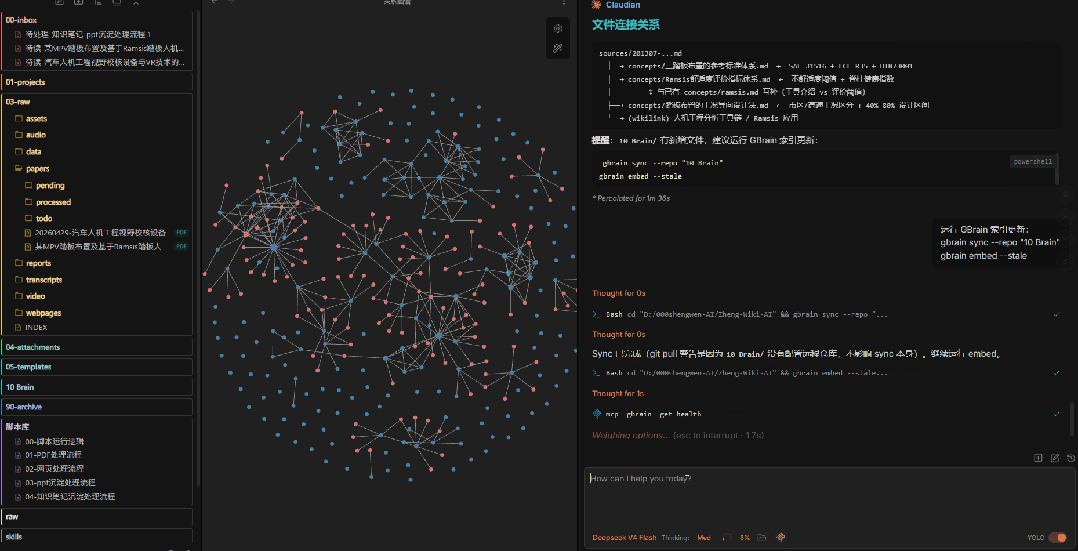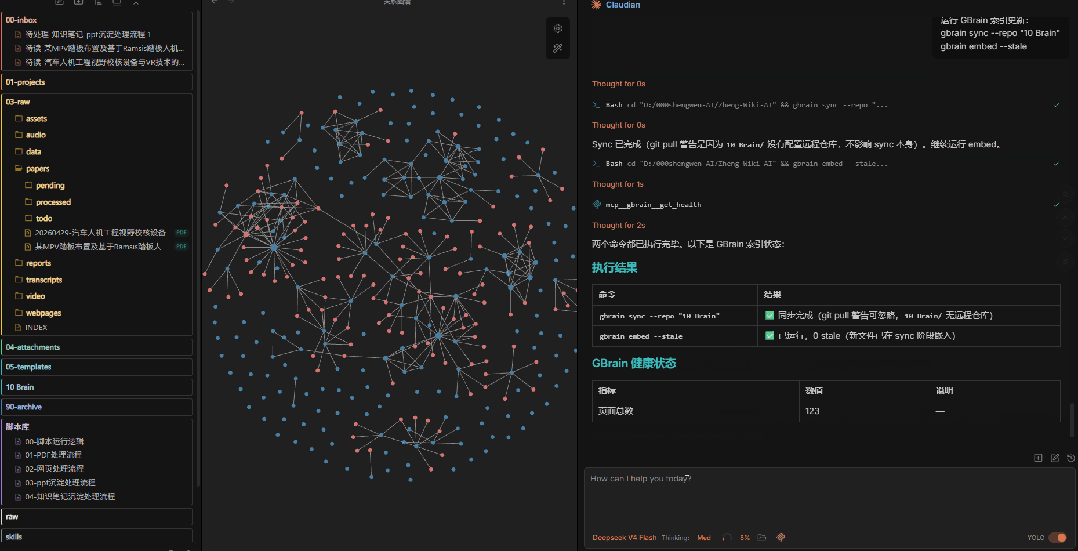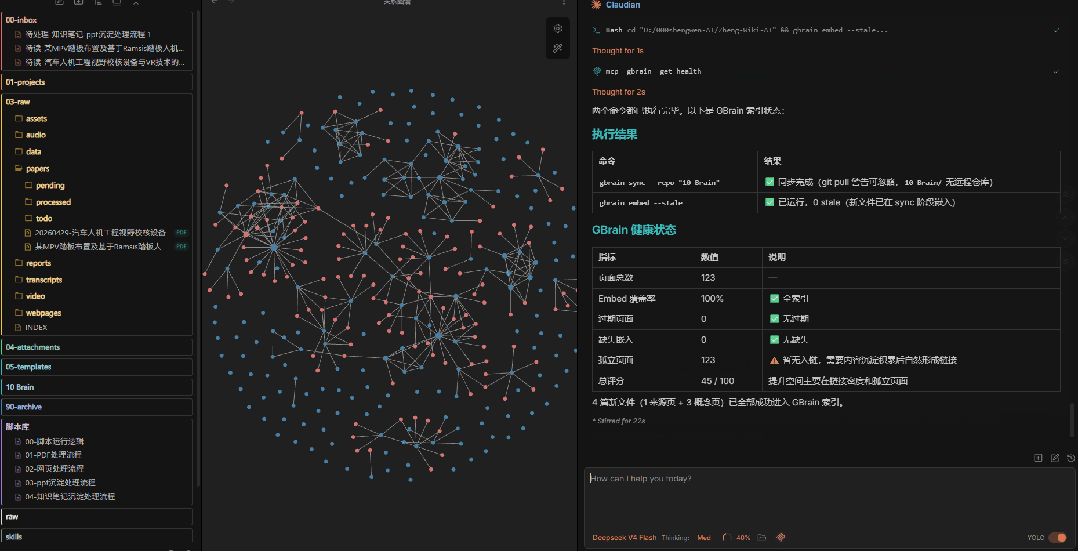
9、知识检索示例1
沉淀完成之后,验证一下效果。 我直接问了一个跟这篇PDF相关的问题,AI从知识库里找到了对应的内容并给出了回答。
这一步的意义在于检验:你沉淀的知识,到底能不能被找回来? 如果存进去了但搜不出来,那等于白存。
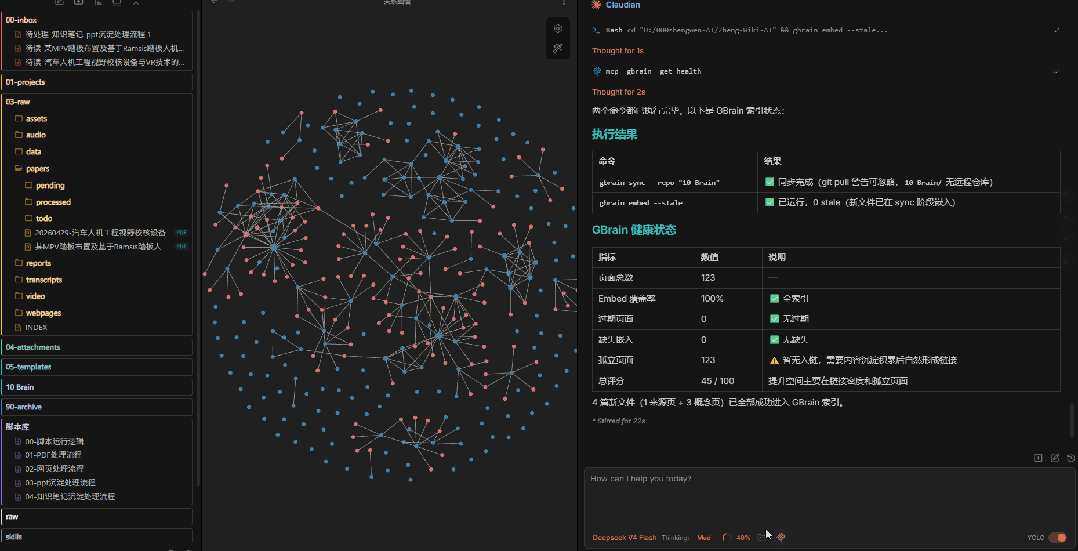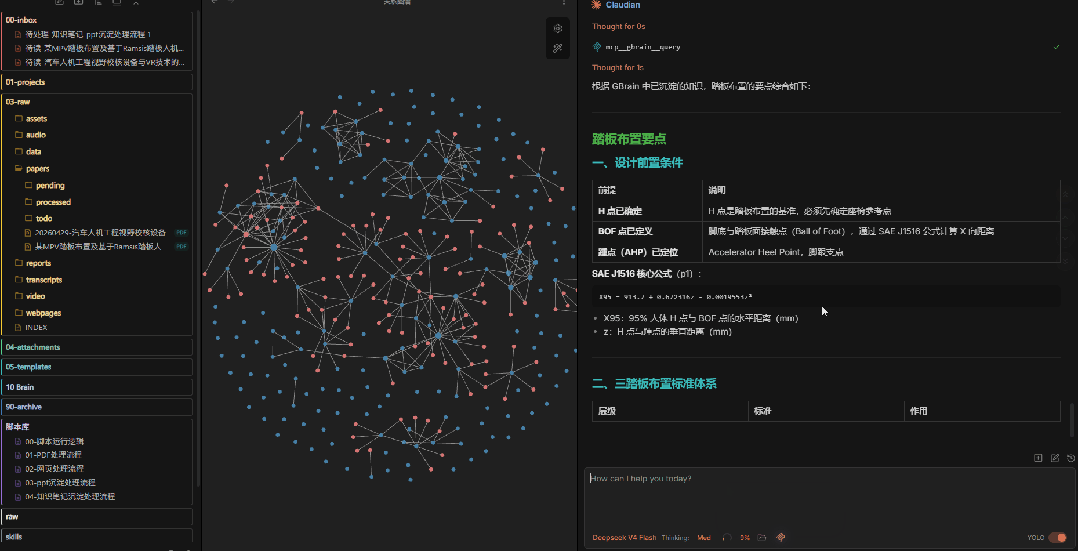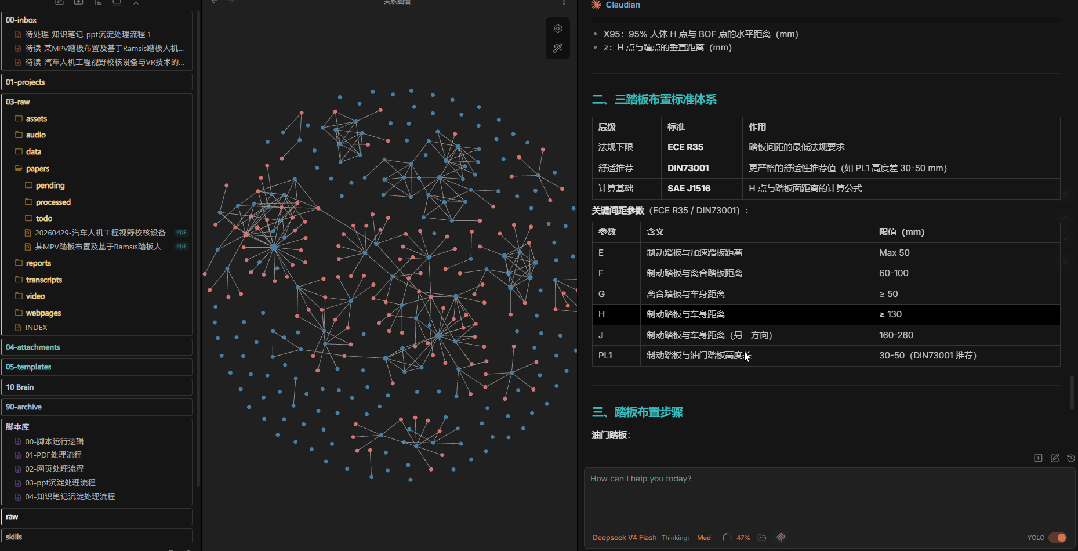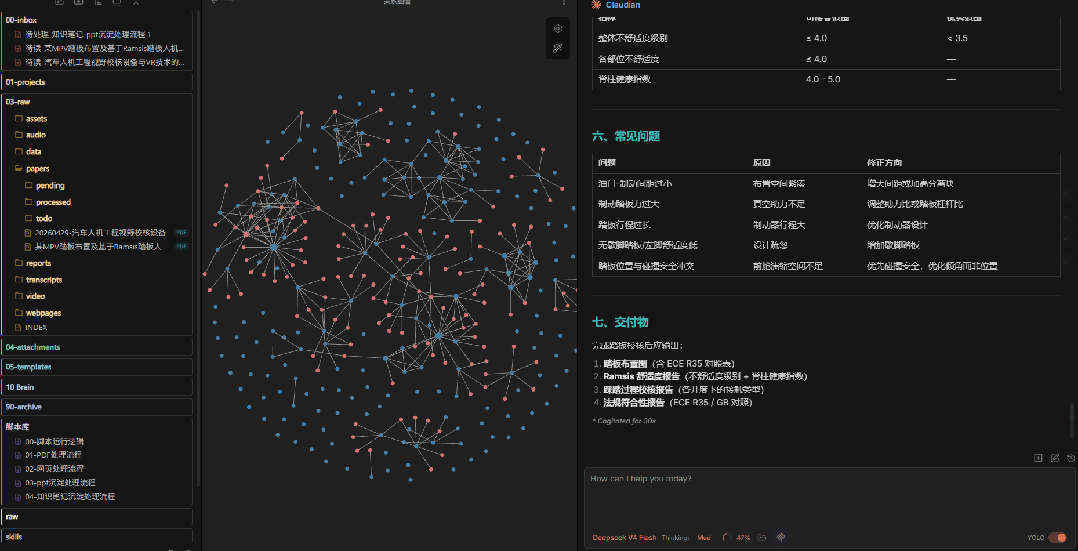
10、知识检索示例2
再试一个不同角度的问题,同样能命中。
这就是知识库的魔力:你不用记住每篇论文的细节,只要记住你关心什么问题。需要的时候,知识库会用你沉淀过的内容来回答你——而且答案里包含的是你认可的观点,不是AI的泛泛之谈。
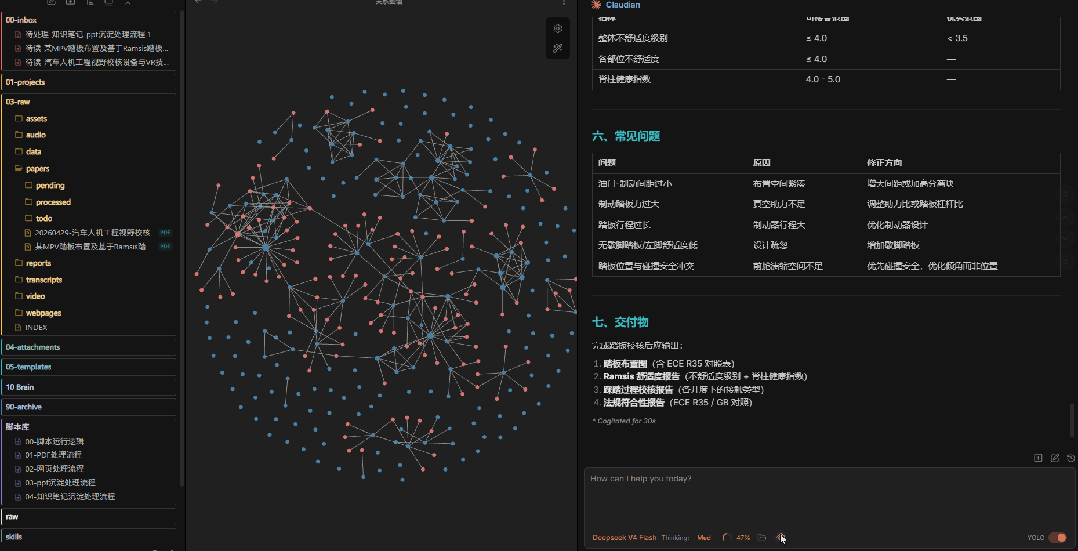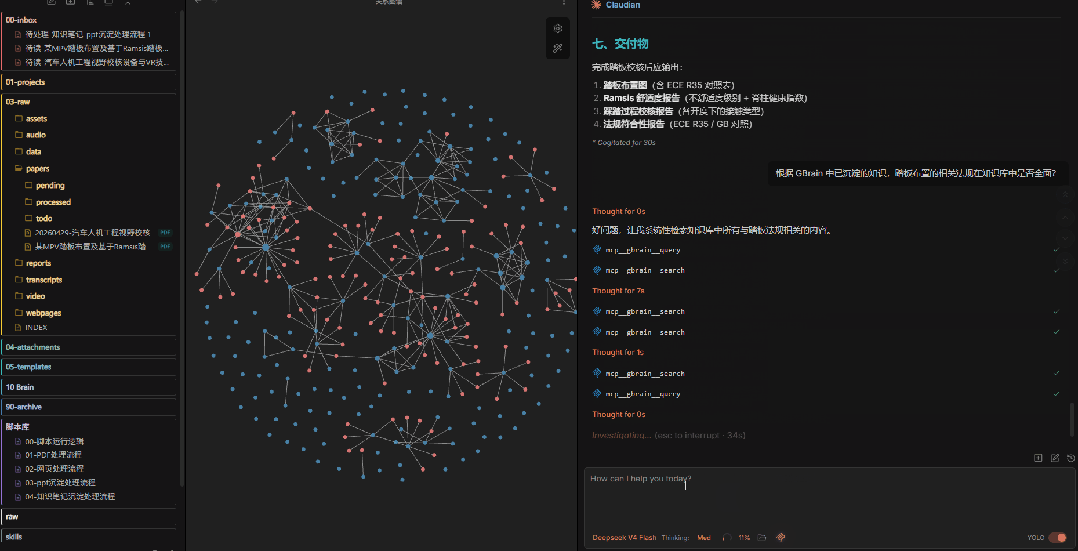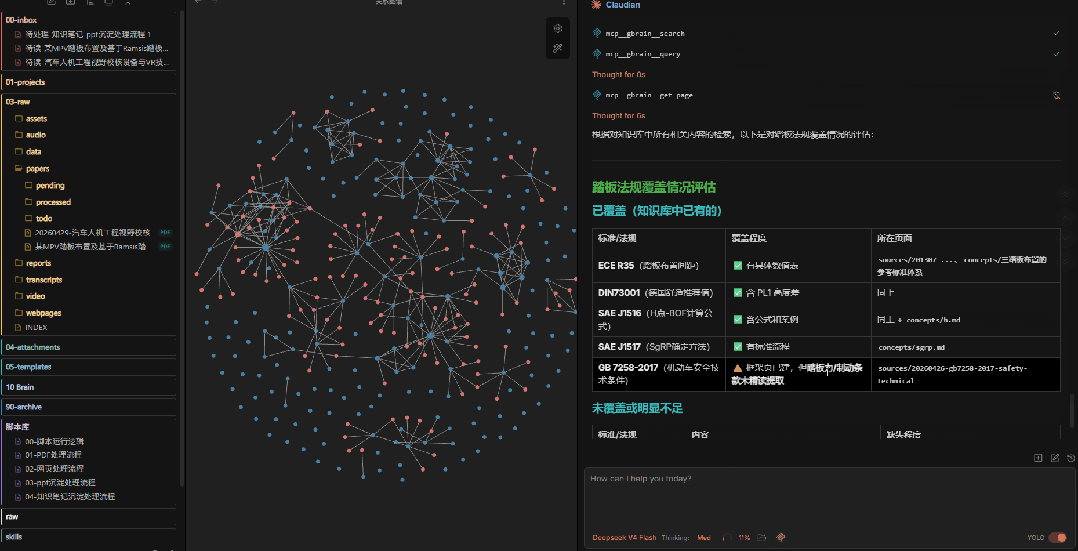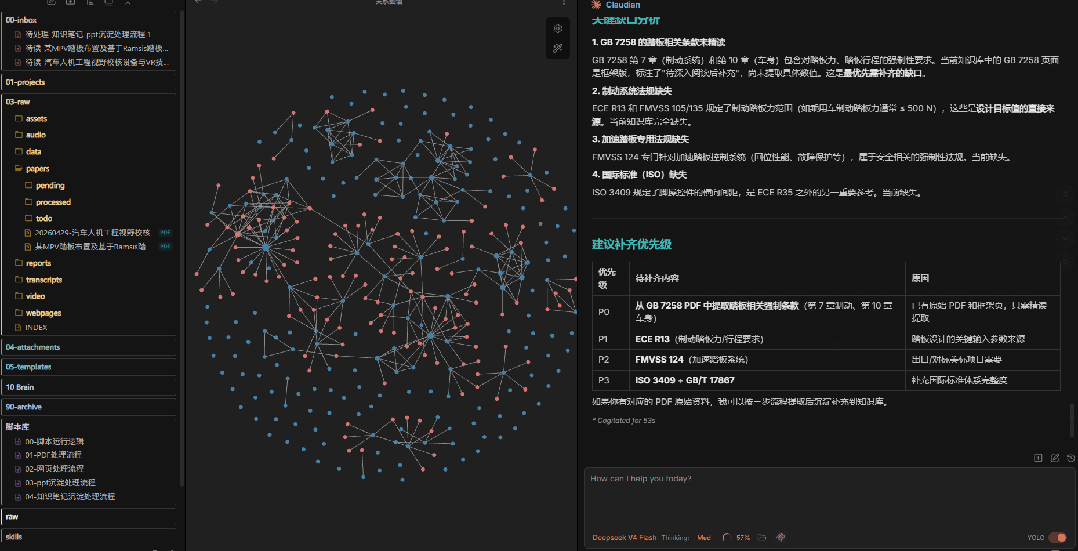
回过头来看,这套流程的核心价值其实就三条:
如果你也收藏了大量论文、报告、网页却不知道怎么消化,不妨试试这套流程。
我是虎哥,一个传统车辆研发工程师,也是一名AI学习者。 后续继续分享真实体验、踩坑和收获。欢迎留言交流。
