 夜雨聆风
夜雨聆风救大命!1000+页图片PDF没法编辑?Umi-OCR直接封神
有没有人跟我一样,遇到过这种崩溃时刻?
拿到一份1000+页的PDF,本想复制里面的文字做整理、做笔记,结果点开才发现——全是图片扫描件!不管是Ctrl+C还是选中复制,要么没反应,要么复制出来一堆乱码,熬了大半天,连一行有效文字都没提取到😭
其实这种“图片PDF”,本质上就是把纸质文档扫描后存成了PDF格式,电脑只认它是“图片”,不认里面的文字。这时候,就需要「OCR识别软件」来救场——它能像人眼一样“看懂”图片里的文字,把图片转换成可编辑、可搜索的文本,1000+页也能批量搞定,不用手动逐页打字!
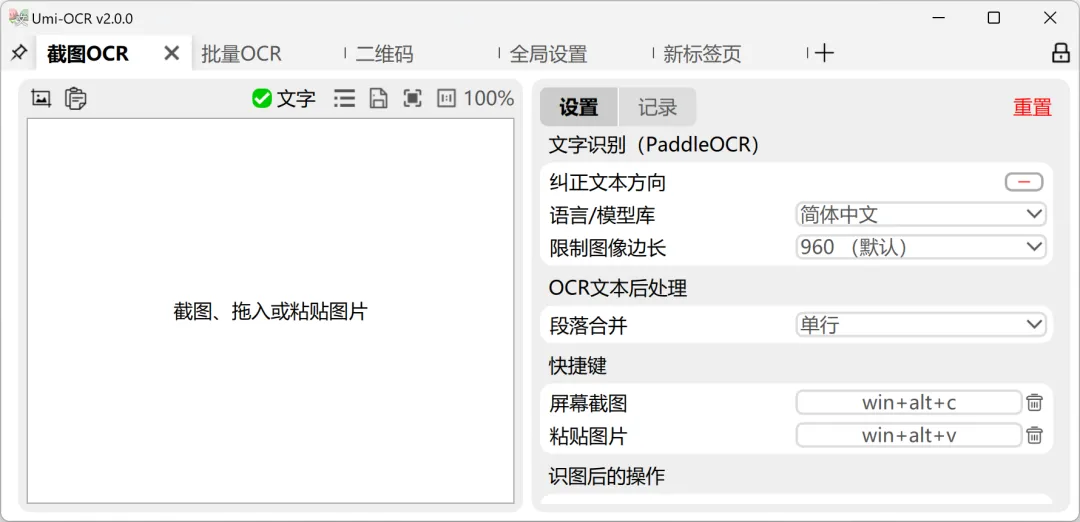
今天给大家安利一款最实用、零成本的OCR工具——Umi-OCR,不管你是学生党、上班族,还是需要处理大量文档的职场人,不管是1000+页图片PDF,还是单页扫描件,它都能轻松hold住,看完直接上手,再也不用被图片PDF折磨!
「Umi-OCR」下载:https://pan.quark.cn/s/9b4405cac887
操作指南(超简单,一看就会)
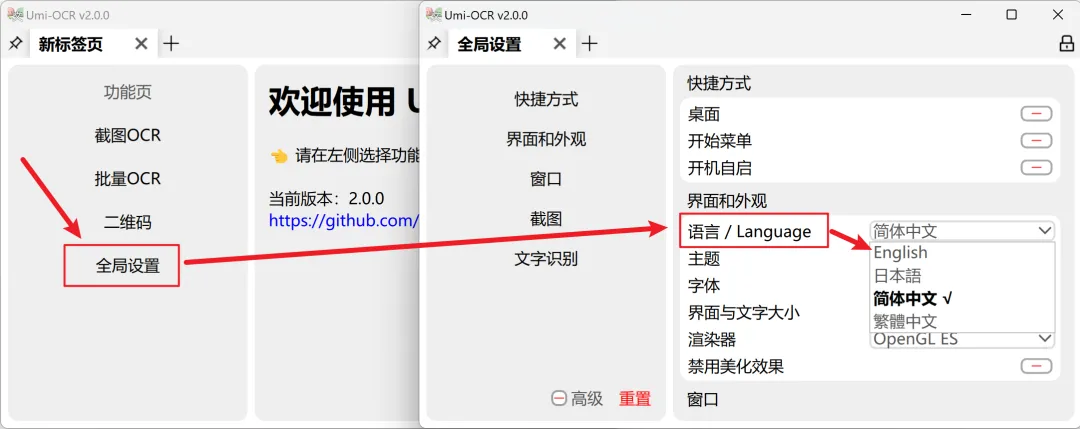
1. 下载解压:去官网或GitHub下载Umi-OCR安装包,解压后找到「Umi-OCR.exe」,双击直接运行(不用安装,绿色无广告); 2. 导入文档:打开软件后,直接把1000+页的图片PDF拖入软件界面,勾选“PDF文档识别”(默认勾选,不用手动修改); 3. 设置参数:语言选择「简体中文」(重点!能大幅提高识别准确率,避免乱码),输出格式优先选「双层PDF」(既保留原图排版,又能自由复制文字),也可根据需求选Word;
4. 开始识别:点击“开始识别”,软件会自动批量处理,1000页大概需要几十分钟(具体看电脑配置,可后台运行,不影响正常办公、刷剧); 5. 查看结果:识别完成后,软件会自动打开输出文件夹,双击文件就能编辑、复制文字,再也不用手动逐页打字啦~
