 夜雨聆风
夜雨聆风今天是2026年5月5日,星期二,北京,天气晴
今天是五一假期第五天,假期最后一天。
我们继续回到知识图谱这个话题,谈谈应用,代码知识图谱用于项目文档生成进展。
代码文档工具(RepoAgent、CodeWiki)自动文档工具不理解代码之间的调用、依赖、结构,生成的文档碎片化、看不懂;把整个文件塞给大模型,一个项目要几小时,花钱多、速度慢。代码改了,文档不会智能更新,要么全量重生成(浪费),要么只改文件表面(漏改、不准)。
所以就引入图谱做一下,建代码知识图谱→按功能模块化→智能体写文档→精准增量更新,即:自动给代码仓库写文档、并自动更新文档,输入一堆源代码(Python/Java/JS等8种语言),输出完整、结构化、带架构图的项目文档(README+模块文档+API文档)。
来看这方面的工作,RepoDoc,从技术实现上,看下是怎么做的?顺便回顾下里面还有啥其他的方案?代码项目文档都咋做?
一、代码知识图谱用于项目文档生成思路RepoDoc
方案在《RepoDoc: A Knowledge Graph-Based Framework to Automatic Documentation Generation and Incremental Updates》,https://arxiv.org/pdf/2604.26523,https://github.com/SYSUSELab/RepoDoc,核心看实现细节。
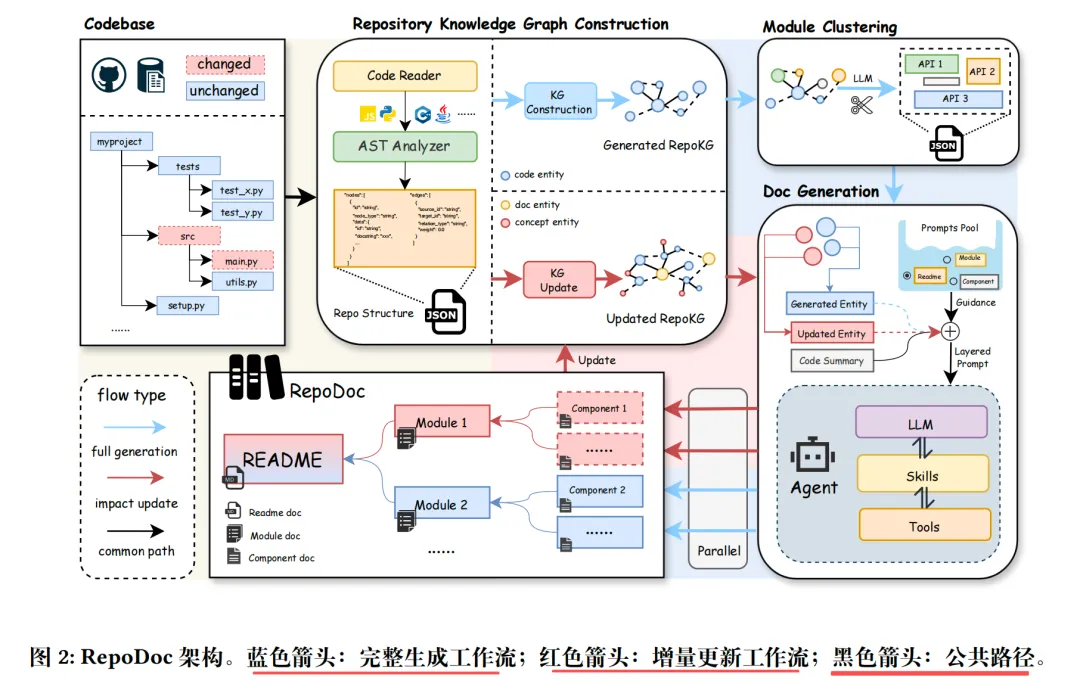
1、RepoKG仓库知识图谱构建
这一步目标是把代码变成一张语义关系图,让机器理解代码结构,看下具体实现拆解:
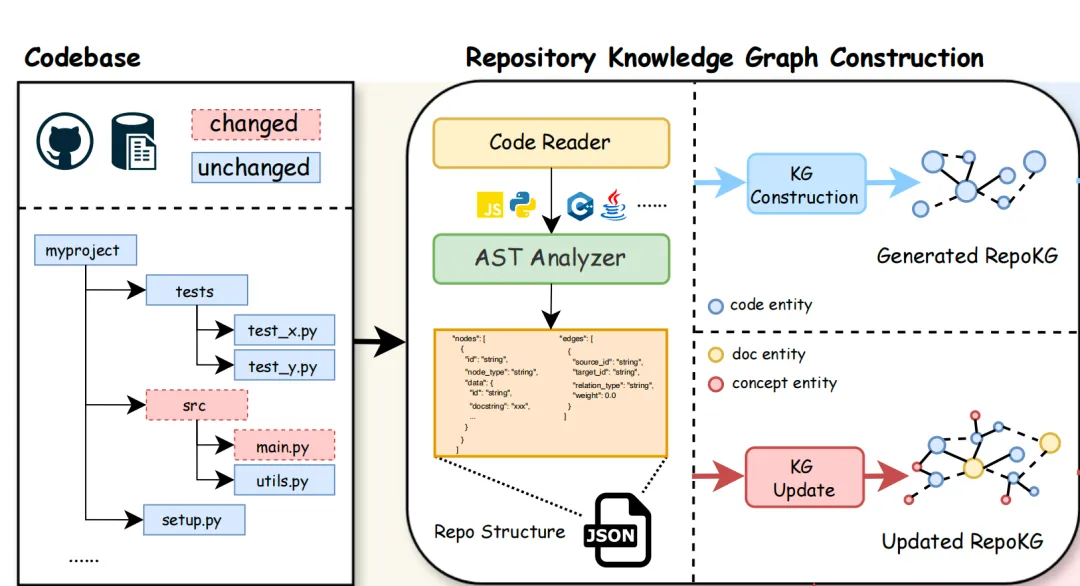
Step1.输入代码仓库(Python/Java/JS/TS/C#/C/C++/PHP等);
Step2.AST解析并提取函数/类/接口/模块等代码实体,每个实体记录源码、签名(参数、返回值)、可见性(public/private)、文件路径;
Step3.抽取导入/包含/继承/实现/调用4类结构关系;
Step4.DeepSeekV3.2语义增强,识别概念实体(如User、Auth、Cache)与语义影响关系(SemanticImpact);
Step5.建立文档-代码描述关系;
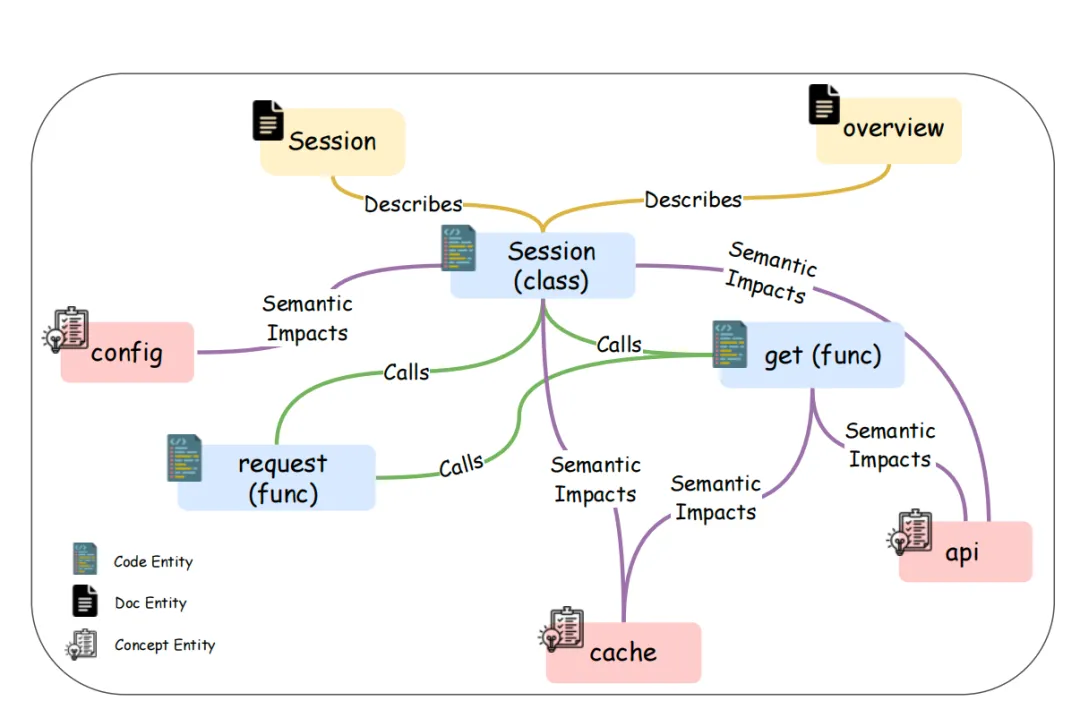
Step6.输出含3类实体(代码实体、概念实体、文档实体)、7类关系(调用、实现、继承、导入、包含、语义影响、描述)的RepoKG】;
示例如下:
2、模块聚类
这一步的目标是打破物理文件限制,按功能内聚把代码分成层次化模块。
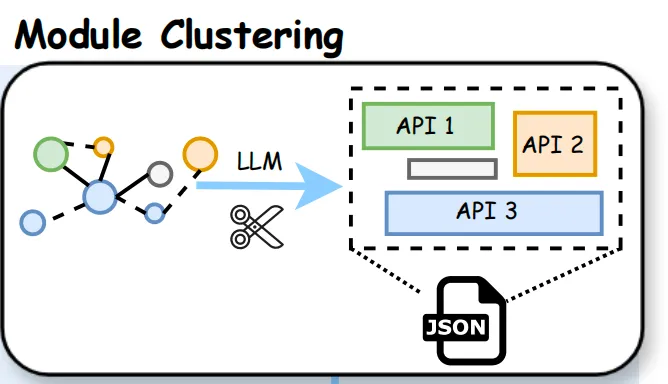
看下具体实现:
Step1.输入上一步的RepoKG;
Step2.基于DeepSeekV3.2自顶向下递归聚类,按照调用关系+导入关系+语义相似度分组;
Step3.按顶层K=5、子层K=3、4096token阈值拆分;
Step4.递归拆分超限模块;
Step5.模块结构存入RepoKG;
Step6.输出项目→模块→子模块→类/函数树形结构,示例如下:
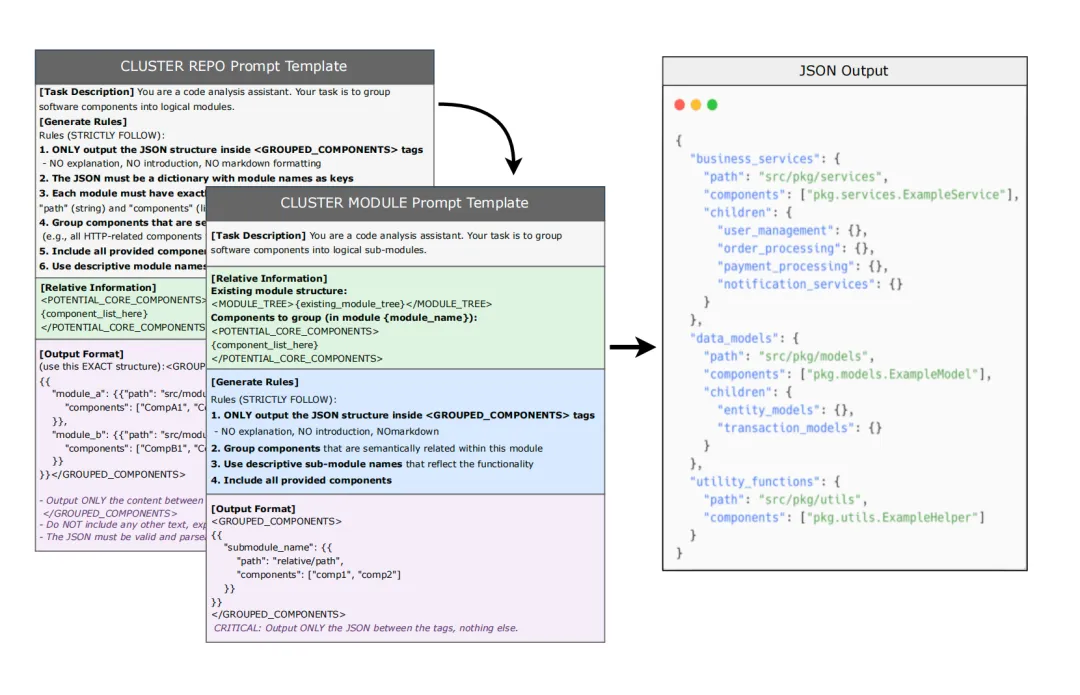
3、基于智能体的文档生成
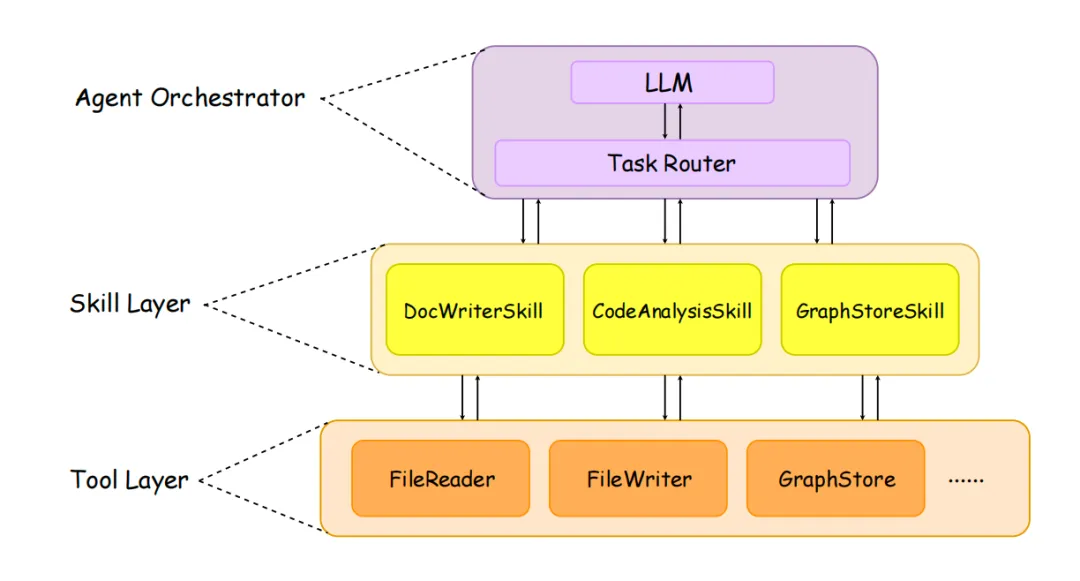
这一步的目标是生成README、模块文档、API文档,带交叉引用+Mermaid图,使用三层智能体(LLM做规划,TaskRouter分配任务)来实现,具体的:
Step1.输入RepoKG与模块结构;
Step2.以DeepSeekV3.2为智能体大脑,编排器规划并路由任务;
Step3.技能层执行代码分析/图谱查询/文档编写(DocWriterSkill写文档:参数表、用法示例、描述、Mermaid架构图+CodeAnalysisSkill分析代码逻辑、提取业务概念+GraphStoreSkill在RepoKG里精准查询相关代码,不读全文);
Step4.工具层提供读写/图谱存储/LLM调用能力(FileReader:读代码+FileWriter:写文档+GraphStore:操作图谱+LLMCaller:调用大模型);
Step5.自下而上生成(先生成最底层组件文档(函数/类),再生成模块文档(引用底层),最后生成顶层README);
Step6.并行生成+交叉引用+Mermaid架构图;
Step7.输出全套结构化文档(README.md、模块文档、API参考文档、自动生成的Mermaid架构图、交叉引用);
4、增量更新
代码改了,只更新受影响的文档,不全部重生成。
实现上,进一步拆解:
Step1.输入代码差异、旧RepoKG、旧文档;
Step2.AST变更检测,对比Git提交差异,被修改的代码实体,标记修改实体(哪些实体变了)与分类变更类型(新增、删除、签名修改、函数体修改);
Step3.RepoKG双向遍历,上游下游传播影响(在RepoKG上做双向遍历,向下游找谁调用/依赖我,向上游找我依赖/调用谁,只要有关系链相连,全部标记为受影响);
Step4.Kahn算法拓扑排序确定更新顺序(先底层,后上层);
Step5.仅选择性再生受影响文档(只重新生成受影响的文档片段、没改动的内容完全保留、自动更新交叉引用与架构图);
Step6.规则验证+GPT-5.2/Claude-Sonnet-4.6LLM校验引用与图表(规则检查链接有效、图表格式正确+LLM检查内容一致、描述准确);
Step7.输出更新后RepoKG与文档。
二、相关项目文档生成方案回顾
先来回顾下项目文档生成方案,讲两个,RepoAgent、CodeWiki。
1、RepoAgent
工作《RepoAgent: An LLM-Powered OpenSource Framework for Repository-level Code Documentation》(https://github.com/OpenBMB/RepoAgent,https://arxiv.org/pdf/2402.16667v1),总结起来就是按文件结构、全量注入上下文、文件级增量、仅Python,
功能上,通过全局结构分析、文档生成、自动更新三大核心流程,可生成含功能、参数、代码说明、注意事项、输出示例的结构化文档,支持与 Git 集成自动同步更新。
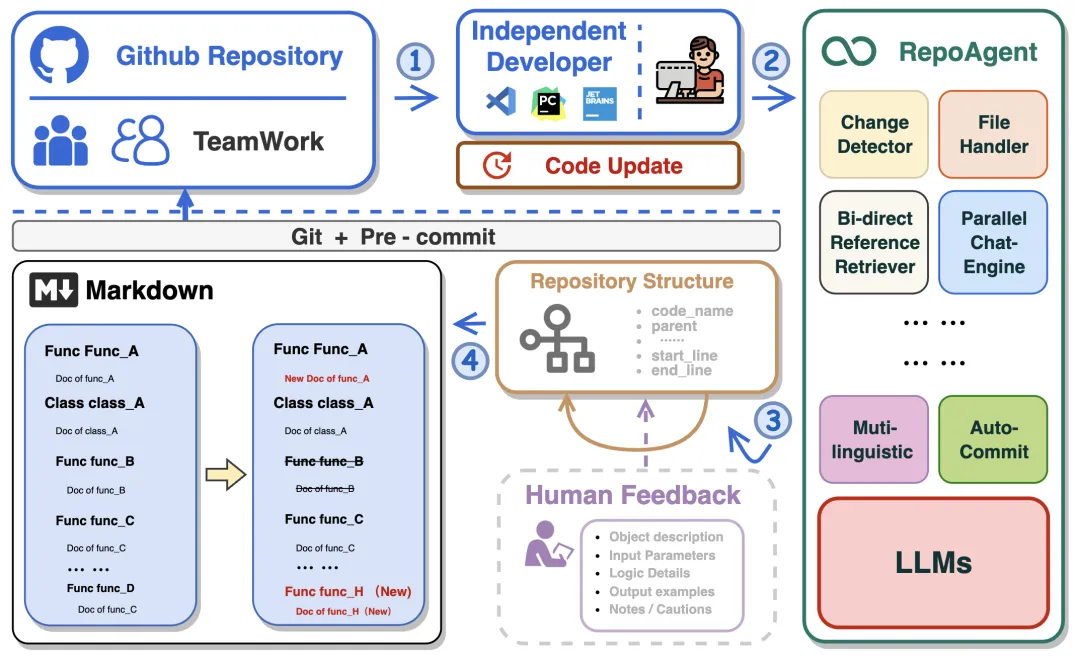
全局结构分析阶段,过滤非Python文件,通过AST解析类与函数元信息,构建项目树,保留代码语义层级关,用Jedi库提取调用者/被调用者双向引用,构建DAG图;
文档生成阶段,按自底向上拓扑序生成,确保子节点先完成,输出固定结构:功能、参数、代码描述、注意事项、输出示例。编译为Markdown,用GitBook渲染为Web界面。
文档更新阶段,集成Gitpre-commit钩子,自动检测代码变更,仅更新受影响对象文档,无需全量重构。但是,这也仅仅支持文件级变更检测,只能重新生成整个文件。
2、CodeWiki
另一个工作《CodeWiki: Evaluating AI’s Ability to Generate Holistic Documentation for Large-Scale Codebases》(https://github.com/FSoft-AI4Code/CodeWiki,https://arxiv.org/pdf/2510.24428),总结起来就是按代码大小分层、上下文爆炸、不支持增量、支持多语言。
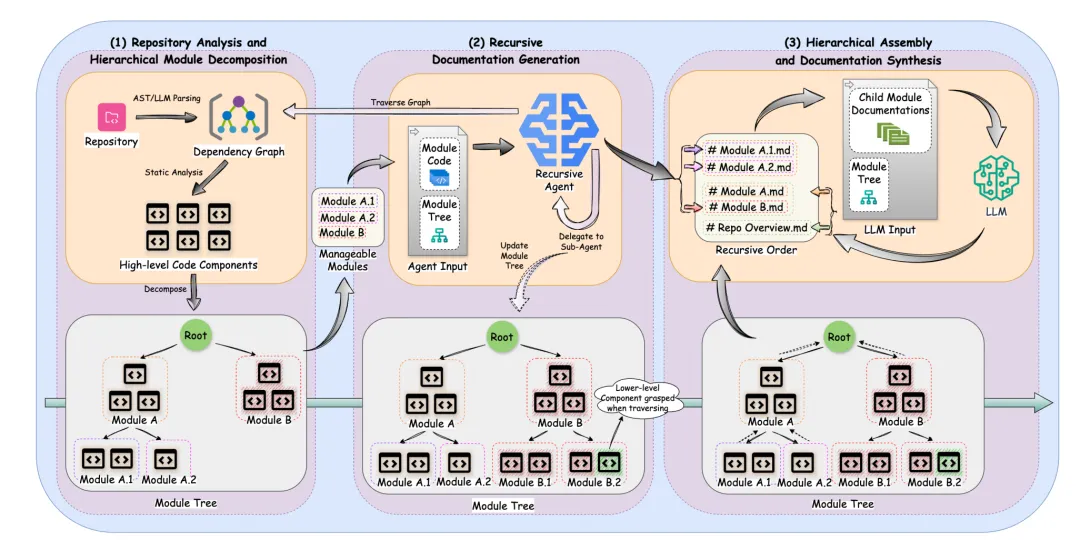
具体实现上,用Tree-Sitter解析AST构建依赖图,文档生成上采用递归文档生成方案,采用自下而上合成机制按照代码物理大小、token 数量限制递归拆分模块,不按功能内聚,只按文本长度拆分。
为叶子模块分配专属智能体,支持代码访问、依赖遍历、文档编辑。
最后,自底向上汇总子模块文档,从底层函数/类开始,向上汇总生成模块文档,生成包含图表的结构化文档。
参考文献
1、https://arxiv.org/pdf/2604.26523
2、https://arxiv.org/pdf/2510.24428
关于我们
老刘,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解等技术方向感兴趣,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。
