 夜雨聆风
夜雨聆风
一道高难度数学竞赛题摆在桌上,一个人苦思冥想可能卡住,但如果让八个高手各自独立解题,再请一位裁判审视所有答案、对比推理过程、指出谁对谁错、甚至从错误中提炼出正确路径——最终给出答案的正确率,会远高于任何一个人单打独斗。
来自美团 LongCat 团队的新论文揭示的事实:当前那些看起来架构精巧、组件繁多的 AI 智能体系统——拥有编排器、子智能体、记忆模块、技能库——真正驱动它们表现的底层机制,其实就等于这场“小组讨论”。
论文将这一机制定义为重型思考(Heavy Thinking),认为其本质不是某个具体系统架构的衍生特征,而是一种具备可抽象性、可训练性与可移植性的内在技能。
复杂的壳,简单的核
过去几个月,AI 智能体的架构越来越复杂。Claude Code 有技能库,CodeX 有代码沙盒,Hermes 有多智能体协调,各种框架各有各的编排器、记忆组件和工具调用链。这些系统在数学、编程等复杂推理任务上确实取得了亮眼的成果。
但一个根本问题被绕过了:到底是哪部分真正在起作用?
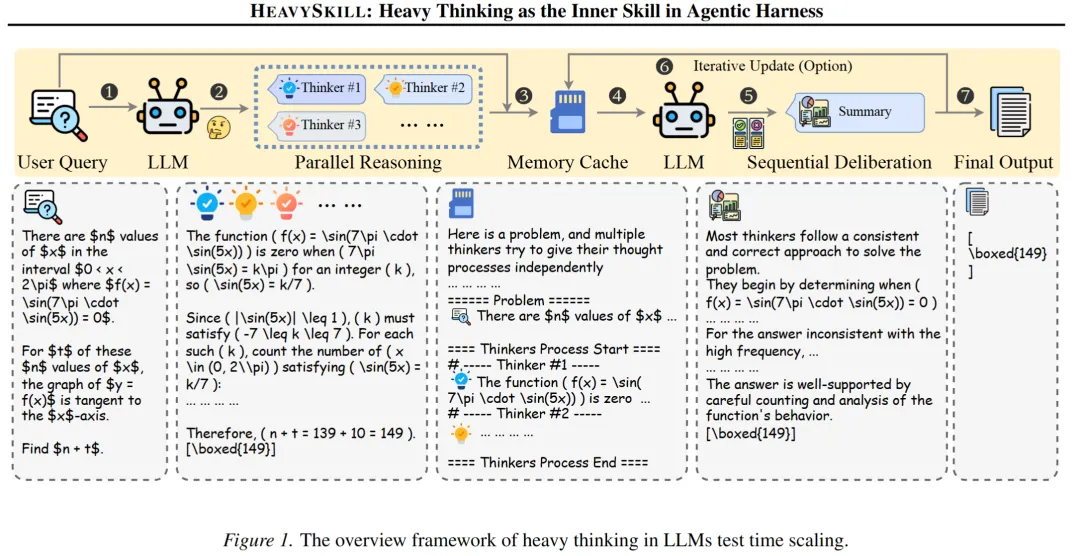
HeavySkill 的作者们回望了这些系统的运行模式,发现了一个共性:编排器模型通常在一个循环中运行,激活多个子智能体并行执行任务,然后把结果汇总输出。不管外面套了多少层壳,这个核心循环可以抽象为两个阶段——
并行推理:让同一个问题被独立地思考多次,产生多条推理轨迹。 顺序审议:把所有轨迹交给一个模型,让它分析、对比、综合,最终给出一个答案。
仅此而已。并行思考,再审议。作者指出,这“可以被简化为并行思考和总结的两阶段工作流”。
不投票,只审议
你可能会说:多条推理路径然后汇总,这不就是“多数投票”(Majority Voting)吗?让模型跑 K 次,哪个答案出现次数最多就选哪个。
HeavySkill 的实验结果表明:审议远比投票聪明。
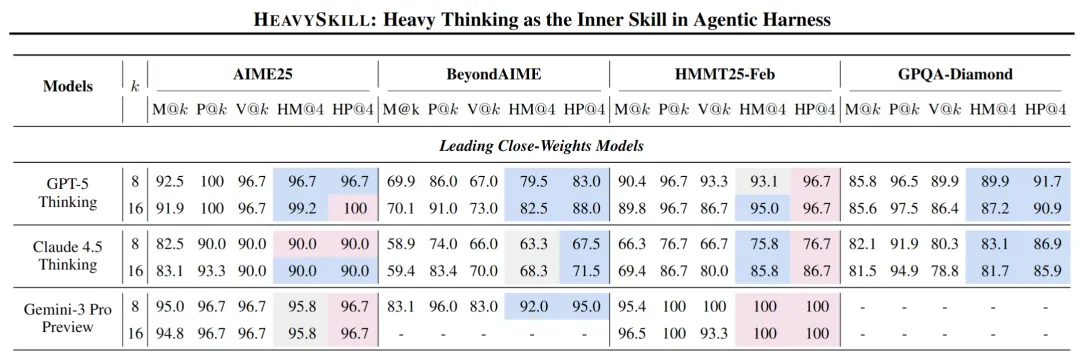
在涵盖 AIME 数学竞赛、BeyondAIME、HMMT 和 GPQA 等多个 STEM 基准测试中,重型思考的平均准确率(Heavy-Mean@K)稳定超越了多数投票(Vote@K)。特别是在更难的测试上,差距尤为明显。以 GPT-5 Thinking 在 BeyondAIME 上的表现为例,K=8 时投票准确率是 67.0%,而重型思考达到 79.5%;K=16 时差距更大,投票 73.0% 对比重型思考 82.5%。
关键原因在于:审议模型不是简单地数人头。论文中的审议提示词明确要求模型“坚持专业性和批判性思维原则,仔细辨别这些思考过程”,并且指出“正确答案可能来自极少数思考者,甚至没有思考者给出正确答案”时,模型应当“从错误经验中学习并重新思考”。

这就像一位资深裁判:他不会因为三份卷子写了同一个答案就直接采信,而是会逐条检查推理链条,找到逻辑上真正站得住的结论。
审议能“无中生有”
研究发现,审议模型有时可以得出一个在所有原始推理路径中均不存在的正确答案。
具体而言,若八位独立解题者的个体答案均不正确,但各自推理过程中包含部分有效的观察——例如,A识别出关键约束条件但计算失误,B采用了正确的方法却遗漏了某一推理步骤,C的推导方向正确但存在数值偏差——审议模型在综合审视所有推理轨迹时,能够将散布于不同错误路径中的正确片段加以整合,并重新推导出一个任何单一轨迹均未触及的正确结论。
论文通过实证数据支持这一结论:在近半数的实验情境中,重型审思的“潜力上限”指标(Heavy-Pass@K)超越了原始推理路径的理论上限(Pass@K)。以DeepSeek V3.2 Thinking在HMMT25上的表现为例,8条原始推理路径中至少有一条正确的理论上限为100%,而审议后4条输出中至少有一条正确的比例同样可达100%——但后者是审议模型在自身“再推理”基础上取得的成果,并非单纯的路径选择结果。
这表明,审议不仅是一种选择机制,更是一种综合与重构过程。
什么样的模型适合当“裁判”
直觉上的假设是:审议阶段应该用最强的模型。但实验给出了一个反直觉的发现。
研究者固定并行推理阶段使用 R1-Distill-Qwen-7B(一个相对较小的模型),然后尝试用不同的模型来执行审议。结果发现,即使用 Qwen2.5-32B-Instruct——一个在独立解题时表现不如 R1-Distill-Qwen-7B 的模型——来做审议,最终效果仍然优于单纯的单次推理。而且,审议阶段使用更强的模型确实能带来更好的结果。
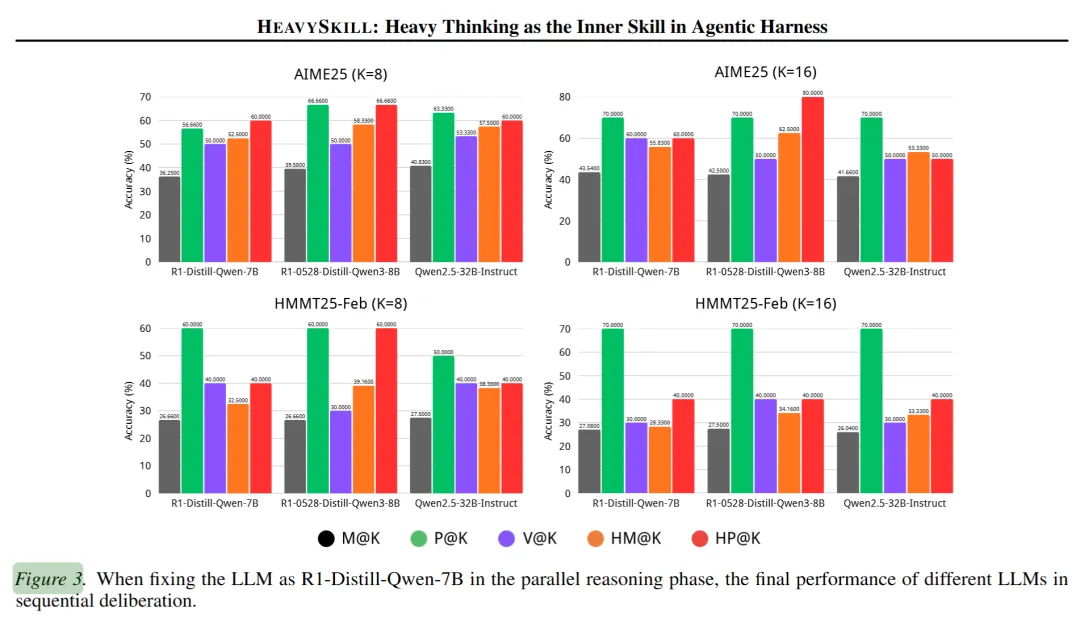
这揭示了一个重要洞见:审议阶段更依赖模型的分析与综合能力,而非纯粹的推理能力。一个擅长阅读、比较、归纳的模型,即便自身独立解题不算顶尖,也能在审议角色上发挥价值。这同时也暗示了一种优化策略——可以用擅长推理的小模型生成轨迹,再用擅长综合的大模型来审议,各取所长。
审议更多轮次效果会更好吗
人类在面对难题时,往往会反复打磨自己的想法。HeavySkill 也设计了迭代审议机制:把第一轮审议的结果作为额外的“专家意见”加入记忆缓存,再进行新一轮审议。
实验显示,随着迭代轮次增加,平均准确率(HM@K)确实持续上升。但硬币的另一面是:潜力上限(HP@K)反而下降了。这意味着每多一轮迭代,模型虽然更稳定地给出不错的答案,但产出“突破性正确答案”的能力反而被削弱了。
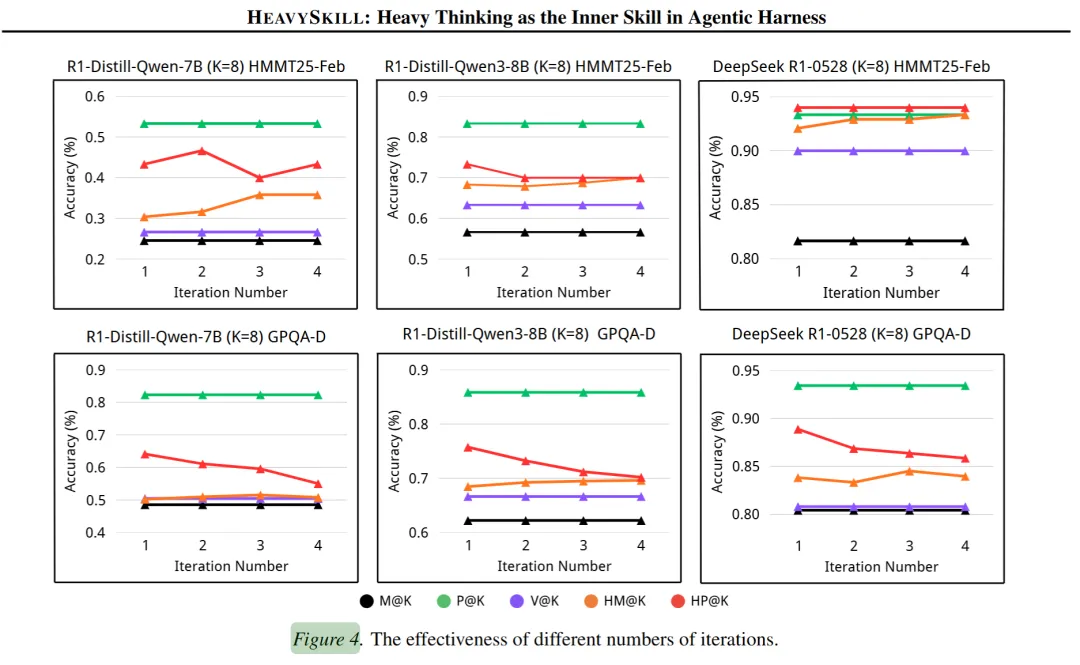
原因在于信息干扰。早期审议生成的内容会累积在记忆缓存中,后续轮次容易受到这些信息的偏见影响,思考空间被压缩。这揭示了一个关键权衡:审议的深度与信息一致性之间存在张力。
Skill 封装
除了工作流,HeavySkill 最具实践价值的贡献是把整个两阶段流程蒸馏成了一份纯文本的技能文件。
这份文件用自然语言描述了:什么时候该启动重型思考(遇到复杂推理任务时)、怎么启动(派出多个独立思考者)、怎么审议(批判性地分析而非简单投票)、最终怎么输出(只给答案,不给元分析)。它没有任何代码依赖,可以直接注入任何支持技能加载的智能体框架——Claude Code、Hermes、自定义编排器都可以用,无需修改框架本身的代码。

这和论文的核心论点遥相呼应:重型思考不是某个系统的附属品,而是一种可移植的内在技能。就像一个人学会了“先多角度思考再总结”的思维习惯后,无论在哪个团队、用哪种工具,都能自然地运用它。
强化学习是否能让这个技能更强
既然重型思考是一种可学习的技能,那是否可以通过强化学习(RLVR)来训练模型做得更好?
初步实验给出了肯定的信号。研究者选取了通过率较低的题目,用并行推理生成轨迹作为训练数据,对 R1-Distill-Qwen-7B 进行 RLVR 训练。在前 100 步训练中,模型的审议能力稳步提升,Heavy-Mean@4 指标提高了约 10%。
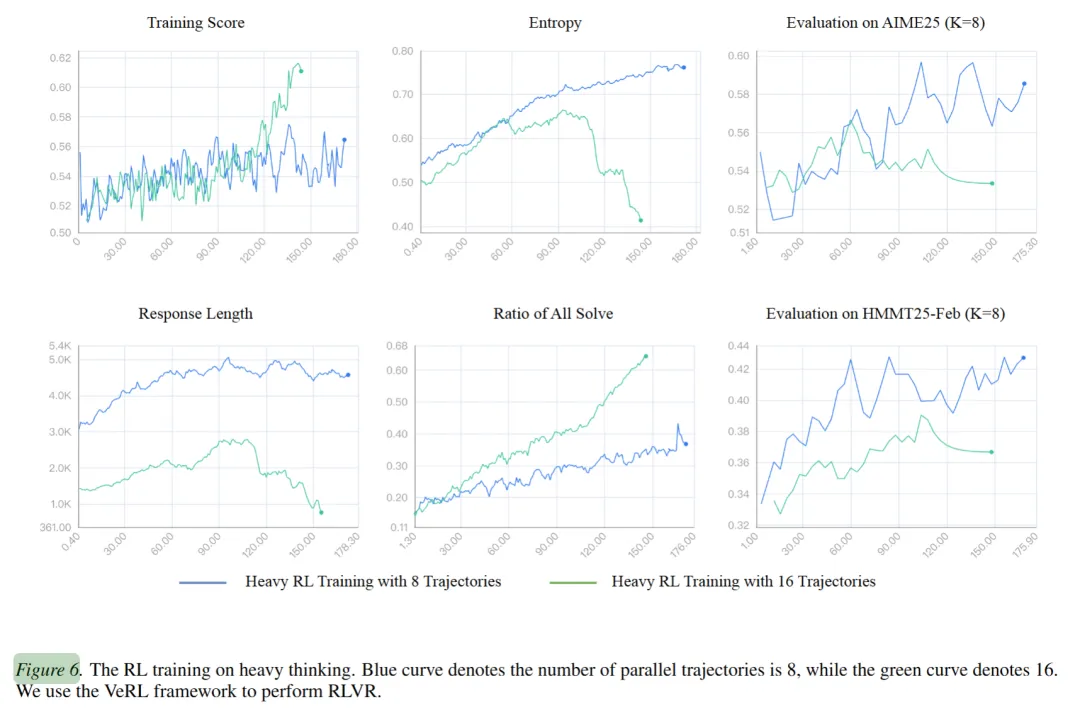
但训练稳定性取决于配置:当使用 8 条轨迹时训练过程平稳,而 16 条轨迹时则出现了“熵坍缩”——模型丧失了多样性,输出趋于单一。作者认为这主要受限于模型的最大序列长度,更长的缓存内容可能导致训练信号被截断。
尽管如此,这个方向的意义不容忽视:重型思考的“宽度”(并行轨迹数)和“深度”(审议质量)都可以通过强化学习来优化,这指向了一条让模型自我进化的路径。
它不能做什么
重型思考并非万能。在主观偏好类的任务上(如 Arena-Hard,一个评估对话质量的基准),审议带来的收益微乎其微,甚至有时略微负面影响。道理很直观:对于“哪种回答风格更好”这类问题,多条路径的“平均值”未必比单条精心打磨的回答更讨喜。
迭代审议也并非越多越好,过深的迭代会侵蚀答案多样性。强化学习的训练稳定性还需进一步解决。
论文自身也承认,这些发现“需要进一步探索”。
研究意义
论文没有发明一个新方法,而是拨开了复杂系统的迷雾,让我们看清了真正在起作用的机制。
当智能体框架越来越复杂、组件越来越多的时候,很容易产生一种错觉:性能提升来自架构的精巧。但这项研究指出,底层真正驱动力是一种简单而普适的模式——多想几遍,然后好好想一想这些想法。
而且,这种模式并非系统的属性,而是模型可以内化的技能。它可以被写成一份文档、加载到任何框架、通过强化学习进一步强化。这意味着我们不必依赖越来越庞大的系统架构来提升推理能力,而是可以让模型本身变得越来越擅长“深度思考”。
在追求更强推理能力的路上,这或许是一条比堆砌架构更本质的路径。
Arxiv:2605.02396
