 夜雨聆风
夜雨聆风2019年,我开始用Notion。
2020年,换成了Obsidian。
2022年,开始用AI辅助阅读和整理。
2024年,我意识到一件事:我记录的东西变少了,但理解的东西变多了。
这个转变,才是AI真正改变知识管理的方式——不是让你更快地记录,而是让你重新思考为什么要记录。
01 那个「收集成瘾」的阶段

我曾经是一个严重的知识囤积癖。
看到好文章,剪藏。看到有启发的播客,下载字幕。看到大佬金句,复制到备忘录。Notion里建了十几个数据库,标签打得比图书馆还细。
最高峰的时候,我的Obsidian里有三千多篇笔记。
然后我意识到一个事实:我从来没有再打开过其中99%的内容。
收藏这个动作,给了我一种虚假的满足感——好像把知识放进了口袋,就等于我已经掌握了它。实际上,我只是把互联网变成了另一个积灰的书架。
这个阶段,大概持续了三年。
02 一个被忽视的事实:RAG为什么用久了跟第一天没区别
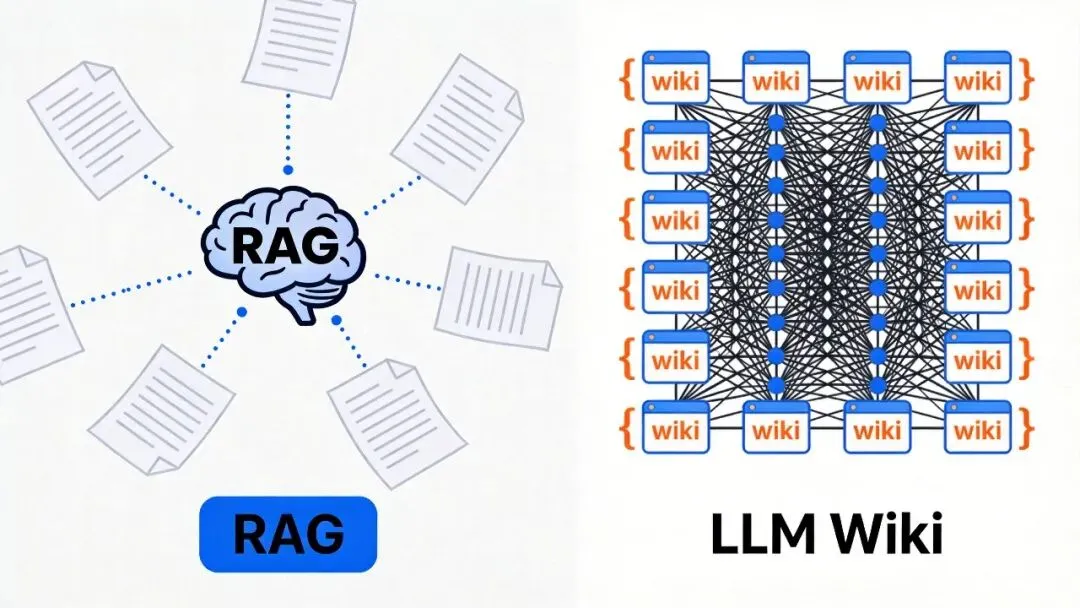
去年我搭了一套RAG知识库——把文档向量化,接上大模型,每次提问向量检索相关内容,LLM基于检索结果生成答案。
用了大概半年,我注意到一个让人不舒服的现象:它跟第一天用起来感觉没什么区别。
文档还是那些文档,答案还是每次从零推理。知识没有积累,上下文没有沉淀。
这其实是RAG设计上的根本局限:每次对话都是从零开始,互相独立。你用得越久,系统对你领域的「理解」不会比第一天更深。
这个问题,Andrej Karpathy去年就写文章指出了。他的解法不是改进RAG,而是一套完全不同的思路——LLM Wiki。
最近有个开源项目(Stars 5.8k+)把这个设计做成了全功能桌面应用。它代表了一种和RAG截然不同的哲学。
03 LLM Wiki:知识是被「编译」过的
传统RAG的逻辑:
用户提问 → 向量检索相关段落 → LLM基于段落临时生成答案 → 结束
LLM Wiki的逻辑是另一套:
导入文档 → LLM两步分析+生成 → 结构化Wiki页面持久存储用户提问 → 多相位检索 → 基于已编译知识库回答
区别在于:知识是被「编译」过的。
LLM读完你的文档后,不是直接存下来备查,而是先消化、分析、生成结构化的Wiki页面——带YAML frontmatter、带[[wikilink]]交叉引用、有来源追溯,然后这个Wiki会持续被维护和更新。
用得越久,Wiki越丰富,知识网络越稠密,回答质量越高。这跟「用了半年感觉一样」的RAG是根本不同的产品。
这正是我前面说的「笔记不是为了以后看,是为了现在想」的工程化实现。
04 两步思维链:先分析,再生成
LLM Wiki对Karpathy原始设计最关键的工程改进之一,是把文档处理拆成了串行的两个LLM调用:
第一步(分析): 提取关键实体、概念、论点;识别与现有Wiki内容的连接点;发现矛盾和知识张力;给出Wiki结构建议。
第二步(生成): 基于分析结果生成带frontmatter的来源摘要页;生成实体页、概念页(含交叉引用);更新index.md、log.md、overview.md。
先让LLM想清楚再写,比边读边写质量好得多。
这个设计映射到我自己的习惯上,就是我每天晚上的那个动作——问AI:「我今天读的东西里,有哪些观点是互相矛盾的?」 先分析,再生成结构化的理解,而不是囫囵吞枣地存进去。
05 知识图谱比标签更聪明
我曾经花很多时间给笔记打标签。
#工作 #投资 #AI #读书笔记 #方法论 ……然后发现,标签越细,越找不到东西。因为标签是我在记录时打的,但找东西是我在回忆时找的——两个时刻的心智模型完全不一样。
LLM Wiki的知识图谱给了一个更聪明的方案——它用四个信号综合计算页面之间的关联:
比纯向量检索要聪明:两篇都来自同一本书的页面,哪怕语义上看起来不相似,系统也知道它们之间的联系很强。
更重要的是,这套图谱会主动告诉你哪里有盲区——孤立页面(没有融入知识网络的节点)、稀疏社区(内容还比较松散的领域)、桥接节点(连接多个知识聚类的关键节点)。
系统发现盲区后,会自动触发深度研究——读取你定义的知识库目标,让LLM生成专项搜索查询,搜索后自动入库。
整个闭环是:知识库自己发现自己哪里不够,然后去学习,然后把新内容消化进来。
当你知道任何东西都可以被找到,你就不再执着于建立复杂的系统。你开始把精力放在真正重要的事情上——理解这个东西到底在说什么,以及它和我已经知道的东西有什么关系。
06 一个新的知识流

我现在每天的信息处理流程,大概是这样的:
早上:花十五分钟,快速浏览前一天收藏的内容,让AI帮我判断:「这篇文章解决了一个你正在面临的问题吗?」如果答案是没有,直接关掉。
中午:处理最重要的那一条,深入阅读,然后用自己的话复述。不是摘录原话,是真的把书合起来,然后跟自己说一遍:「这篇文章在讲什么,作者的核心观点是什么,我为什么同意或不同意。」然后把这段复述交给AI,让它指出我理解错的地方。
晚上:问AI:「我今天读的东西里,有哪些观点是互相矛盾的?」这个动作比任何单独阅读都更有价值——它强迫我建立知识之间的连接。
这个流程没有花哨的系统,没有复杂的标签,没有完美的数据库。
只有一条清晰的知识流:筛选 → 深度处理 → 连接。
07 什么没有变
说了这么多AI带来的变化,最后我想说一个没有变的东西。
「什么值得记录」这个问题,永远需要人来回答。
AI可以帮你筛选、帮你整理、帮你搜索、帮你复述、帮你发现知识盲区。但它无法替你回答的是:对你来说,什么是有意义的?
这个问题,来自你的人生目标、当前处境、价值观。这不是信息处理的问题,是关于「你想要什么样的人生」的问题。
LLM Wiki在设计上特意留了一个「人工审核」环节——标记需要人工判断的Review项目,系统不能替你决定一个知识点是否值得进入你的知识网络。
你越清楚自己要什么,AI就越能帮你找到和记住相关的东西。
结语
回顾这六年的知识管理折腾,我最庆幸的一件事,是在Notion最火的时候,没有花太多时间去配置那些精美的模板;在Obsidian工作流最火的时候,没有执着于建立完美的双向链接系统;在RAG最火的时候,没有花太多时间调参。
不是因为那些工具不好,而是因为一个错误的前提:以为建立一个完美的系统,就能解决「知识焦虑」的问题。
知识焦虑的本质,不是存储不够,而是方向不清。
AI解决的是前半段——让你更高效地筛选、理解和连接知识。
方向这件事,只有你自己能回答。
参考项目:LLM Wiki(github.com/nashsu/llm_wiki),Stars 5.8k+,基于Karpathy设计模式构建
文章由AI辅助生成
