夜雨聆风
夜雨聆风
(一)Gen-AI生成题与人工真题在IRT测量特性上的总体特征
IRT分析侧重在题目参数估计、模型与数据拟合性以及试卷信息量三个方面。
1.两类试题在难度与区分度参数上的比较
运用IRT2-PL模型和同时校准估计方法,得到人工真题与Gen-AI生成题的题目参数和考生能力参数估计值,具体见图1、表1。
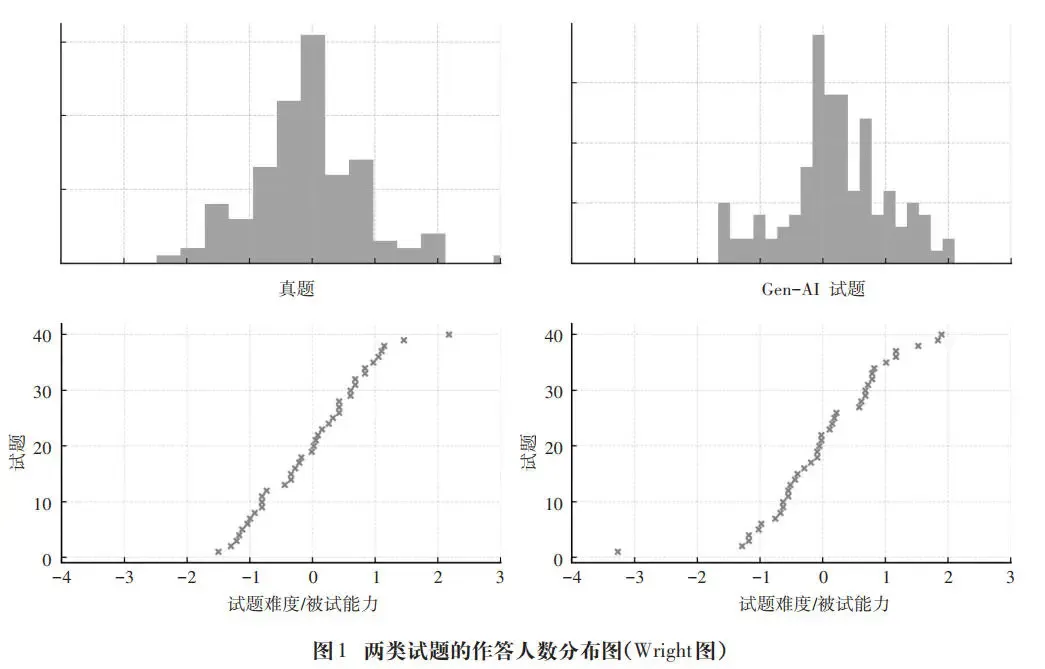
由图1可知,人工真题与Gen-AI生成题的难度分布相似,均集中在难度值(-2,2)区间,既包含了一定数量的容易题和难题,又包含较多中等难度试题,为区分不同能力水平考生提供了保障。此外,考生的能力分布近似正态,集中在(-2,0)区间,被题目难度分布区间(-2,2)完整覆盖,从而避免了因题目难度与考生能力错配而导致的测量信息不足等问题。
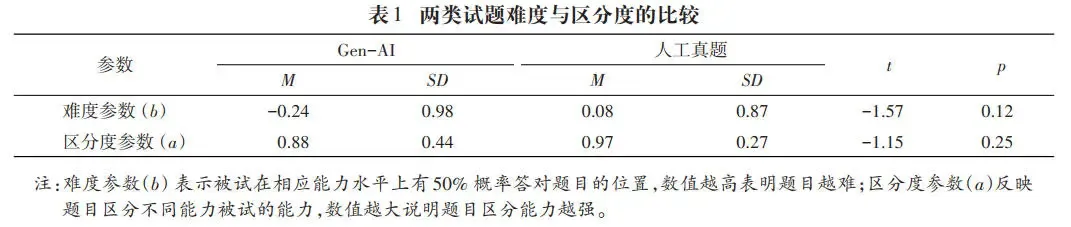
由表1可知,Gen-AI生成试题与人工真题在难度与区分度的均值未呈现显著差异(p>0.05),说明两类试题在整体难度和区分度上较为一致,即Gen-AI生成的语法选择题在难度与区分度方面接近标准化真题。
2.两类试题在模型拟合程度上的比较
IRT假定考生能力水平高于题目难度时答对概率较高,低于题目难度时答错概率较高。如果大量考生在某个试题上的作答表现不符合上述规律,则该题目被认定为表现异常,即IRT模型与数据拟合不良。评估模型与数据拟合性指标主要有Infit和Outfit两类,以均方Mean-Squares或标准化Z值表示。其中,Outfit是题目特别难或特别容易时考生作答表现异常的指标,Infit是题目难度与考生能力水平接近时的考生作答表现异常指标,二者的理论值是1.0,理想区间是(0.5, 1.5)或(0.7, 1.3)。如果outfit MNSQ值远高于1.5,可能是该题太难导致低水平考生随机作答,也可能是该题太容易但有不少高水平考生答错。如果infit MNSQ值远高于1.5,说明考生在试题难度与自身能力水平接近时表现失常。这两类情况都会损害IRT模型与数据的拟合性,具体结果见表2。

由表2的t检验结果可知,在模型数据拟合性指标表现方面,Gen-AI生成试题与人工真题接近,二者无显著差异,但这两类试题的具体情况并不相同。其中,Gen-AI生成题目中有2道题的Infit MNSQ不在理想区间,G13和G23均低于0.7;有7道题的Outfit MNSQ不在理想区间,低于0.7的有G10、G13、G21和G35,高于1.3的有G9、G24和G33;人工真题中有1道题的Outfit MNSQ不在理想区间,即A3低于0.7。由此说明,Gen-AI生成试题的异常作答表现比率略高于考生在人工真题上的异常作答表现。然而,如果使用(0.5,1.5)区间值作为模型与数据拟合良好的标准,则Gen-AI生成题与人工真题的IRT模型与数据拟合程度都达到合格水平。
3.两类试题在测验信息分布上的比较
测试信息函数可以揭示测验在不同能力区间的测量精度[38]。本研究中两类试题的测试信息曲线在整体形态上高度相似,均在能力水平θ≈0附近达到峰值,具体见图2。
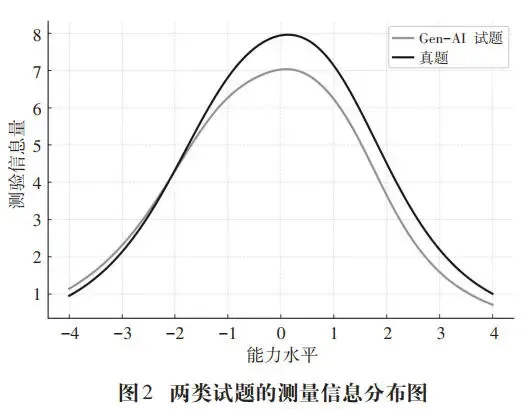
由图2可知,两类试题在中等水平学生中能提供最高的测量精度,可以较为有效地捕捉该区间学生的能力差异。从经典测量学视角来看,θ=0通常代表样本均值水平,曲线在此位置达到峰值说明这两类试题合理覆盖了大部分学生的能力水平,避免测量精度过度偏向能力过低或过高的学生。此外,人工真题在峰值区域提供的信息量更多,说明其在区分中等水平学生能力时更具优势;Gen-AI命题的曲线虽然峰值略低,但是在θ≈(-2,-1)的低分组区间呈现更为平缓且持续的覆盖,说明Gen-AI命题在对低水平考生的能力估计中更能维持相对稳定的信息量,不会因题目难度过高导致测量效度急剧下降。这一差异在实际测评中具有重要意义。
在高职院校,英语基础较弱的学生较多。正是因为Gen-AI自动命题在该区间能提供更为均衡的信息覆盖,所以其在日常作业和教学诊断中能够更好地满足此类学生的需求。对人工真题而言,其在中等能力区间表现更高精度,因此更适合高利害考试。总体而言,这两类试题的信息函数曲线均符合测量学预期的特征,既能对大多数学生所处的能力区间实现较高的测量效率,也能在不同能力水平区间发挥各自优势。
总体上,Gen-AI生成题与人工真题在难度分布、区分度水平、拟合度结果及测试信息函数等综合分析结果上都较为相近。虽然两类试题在局部参数上存在细微差别,但总体趋势显示其难度与区分度控制合理,拟合度良好,能够在受试学生的主要能力范围内提供有效测量。
(二)Gen-AI生成试题与人工真题作答响应时间差异分析
本研究中,学生作答Gen-AI生成题的平均时间为29.83秒/题,作答人工真题的平均时间为31.25秒/题。进一步分析正确作答的题目发现,学生对Gen-AI生成题的平均响应时间为28.47秒,低于人工真题的30.12秒。对于错误作答的题目,Gen-AI出题的平均响应时间为31.92秒,略低于人工真题的32.45秒。
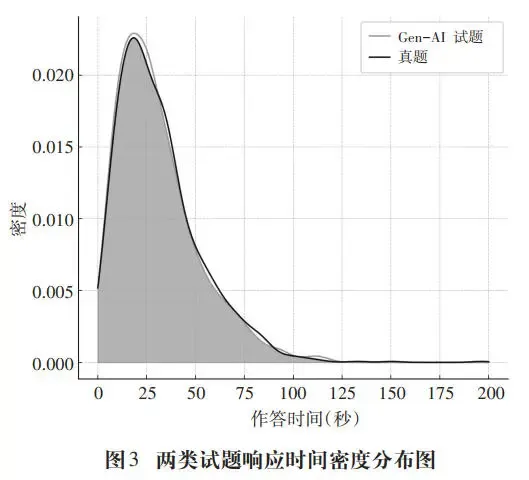
从以下两个层面对试题平均响应时间进一步分析:1)项目层面,以题目为单位,先计算每一道题的平均作答时间,再比较两类试题差异;2)试卷层面,以学生的每一次作答为独立观测值,将所有作答记录纳入统计分析。由此,可以同时考察题目整体特征与个体作答行为之间的差异情况。t检验发现,两类试题的平均响应时间差异无论在项目层面(t=-0.21,p=0.84)还是在作答层面(t=-0.27,p=0.79)均未达到显著水平。
图3为两类试题的响应时间密度分布图,进一步支持了这一结论,两类试题的分布曲线在主要区间高度重叠,说明学生在两类测验中的作答时长基本一致。
(三)Gen-AI生成题与人工真题干扰项质量的比较结果
有效干扰项通常更容易吸引低分组学生,从而增强试题区分度;无效干扰项则几乎无人选择,或更易被高分组学生选中,缺乏应有的区分作用。
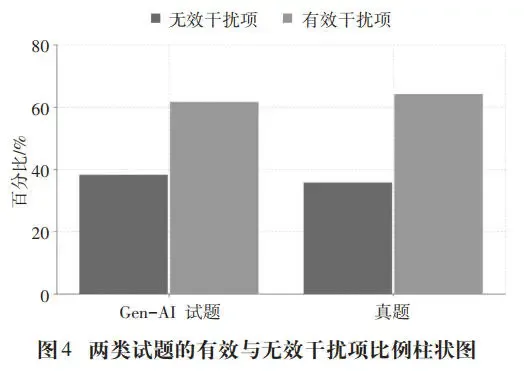
图4为Gen-AI生成试题与人工真题在干扰项分类上的总体分布情况。对两类试题的有效干扰项的比例进行卡方检验,结果显示χ²(1)=1.25, p=0.26,未达到统计学显著水平。这表明两类试题的有效干扰项的比例无显著差异。根据学生测试数据分析结果,在Gen-AI生成的120个干扰选项中,74个为有效干扰项,46个为无效干扰项;在人工真题的120个干扰项中,77个为有效干扰项,43个为无效干扰项。Gen-AI生成试题的干扰项合格率达到61.7%,接近人工真题的64.2%。可见两类试题在干扰项质量上整体接近。
从具体题型来看,语法选择题的选项往往在形式和结构上接近,因此Gen-AI更容易通过规则化的要求生成具有迷惑性的干扰项。以下四个例题分别来自Gen-AI生成试题(例1、例2)和人工真题(例3、例4)。

Gen-AI在语法题生成过程中能较好地模拟正确选项的表面特征,生成与之高度相似的干扰项,从而使其在语法题中的命题质量接近人工命题。因此,上述四道例题各个选项的选择分布呈现出相似规律。这一发现与前文统计分析结果一致,进一步解释了为何Gen-AI生成试题中有效干扰项的比例能够接近人工真题。在语法题这一知识点规则化、变体相对有限的题型中,Gen-AI生成的干扰项已基本达到与人工命题相当的质量水准,为其在英语测评中的应用提供了实证依据。
四、结论与讨论
本研究采用IRT方法对比分析Gen-AI生成的英语语法选择题与真题差异,结果发现:二者在难度、区分度、模型与数据的拟合度、学生作答响应时间及题目的有效干扰项比例等方面无显著差异;在生成试题的峰值信息量和模型拟合度方面,Gen-AI生成试题与真题相比略显不足。
在难度方面,本研究与Bhandari等研究发现[12-13]一致,但不同于部分研究提出的Gen-AI生成试题整体偏易等结论[25,27,29]。在区分度方面,本研究与Mendoza等研究发现[26]一致,但与Zhang等研究结论[28]不同,该差异可能是由题型特征不同引起的。有研究发现,Gen-AI在语法类结构清晰的题型上表现出较强的生成能力,在需要高阶认知能力的阅读理解题中则表现较弱[29-30]。在作答行为方面,学生在两类试题上的响应时间差异不显著,并在项目层面与作答层面的分析结果保持一致。这在一定程度上说明Gen-AI生成试题的内容效度较好[33],题意表达清晰,学生在理解题意方面无须耗费更多时间。此外,干扰项设计被视为Gen-AI自动生成选择题的主要瓶颈[34],但本研究发现两类试题干扰项的质量接近。该发现与医学领域自动命题研究中报告的干扰项质量不足[9-10]形成鲜明对比,由此说明学科特征对Gen-AI命题质量具有重要影响。医学类试题涉及高度专业化的知识,而英语语法题考点规则明确、变式有限,使得Gen-AI更容易生成合理的干扰项。值得注意的是,在英语听力和阅读题型中,Gen-AI自动生成的干扰项质量偏低[18-20],这说明同一学科内的不同内容也会影响Gen-AI的命题质量。因此,将Gen-AI生成试题应用于正式考试时,应结合学科与内容特点,在训练数据、命题指令、题目参数控制、干扰项质量及专家反馈等方面建立更加系统化的试题质量保障机制。
综上,Gen-AI自动生成英语语法试题的质量接近真题水平,且成本低、效益高。教师可根据教学内容快速生成质量接近标准化考试的题目,提供丰富的课后作业和课堂小测资源,大幅降低人力成本和时间消耗,促进教学与反馈衔接。本研究对其他学科自动命题研究亦具有借鉴价值。对于同样具有规则化、结构化特征的学科内容(如数学基础运算、物理公式应用等),Gen-AI可能展现出与语法题相似的命题效果;而对于需要高阶认知能力或复杂推理能力的学科内容,则需要根据学科特点调整命题策略。因此,各学科教师在应用Gen-AI进行命题时,应充分考虑学科、题型特征,坚持人机协作模式,教师需审阅、修订和优化生成内容,以确保试题的可靠性[42],使Gen-AI在教育测评中发挥更大作用。
本研究存在的主要局限及未来改进方向有三点:第一,样本群体仅来自一所高职院校学生,未来可扩大样本学校和班级范围以增强结论的普适性;第二,仅聚焦英语学科语法选择题而未涉及其他题型,未来可扩展到其他更多学科与题型的相关研究;第三,研究所用Gen-AI模型为Grok3,可能存在模型类别间差异。未来可进一步探索指令工程、模型微调等对命题质量的提升作用,推动Gen-AI在教育测评中的科学化、规范化应用。

- End -