 夜雨聆风
夜雨聆风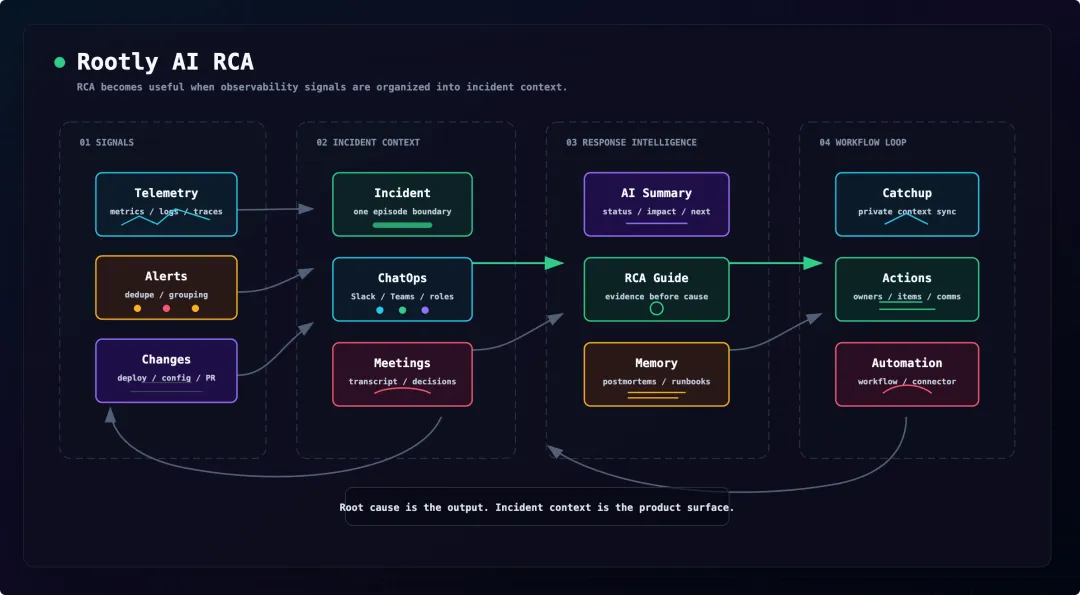
最近我看了 Rootly 在 AI SRE、RCA、On-call 和事故管理方向上的产品,感受挺明确。
它不是一家传统可观测性公司。它不靠自己采集全量 metrics、logs、traces 起家,也不是想重新做一个 Datadog、New Relic 或 Splunk。
Rootly 抓住的是另一个入口:事故发生之后,工程团队真正协作、判断、沟通和复盘的地方。
这件事对做监控、可观测性、AIOps、AI RCA 的厂商很有启发。
过去我们一直在帮客户“看见问题”:告警、指标、日志、链路、拓扑、dashboard、事件中心。可是生产事故真正发生的时候,客户最着急的通常不是“有没有数据”,而是:
现在到底发生了什么?谁应该来处理?最近谁改了什么?这些告警是不是同一个问题?以前有没有类似事故?上次怎么修的?现在应该先止血,还是继续查?事后哪些动作必须补上?
Rootly 的产品路线,正好围绕这些问题展开。
它给我的最大启发是:AI RCA 不能只从可观测性数据里长出来,还必须从事故上下文里长出来。
Rootly 不是替代可观测性,而是站在可观测性之上
很多人一听 AI SRE,会自然想到一个问题:是不是要重新做一个可观测性平台?
Rootly 的答案很明显:不是。
它连接客户已有的 Datadog、Grafana、New Relic、Sentry、Splunk、Honeycomb、CloudWatch、Alertmanager、Kubernetes、GitHub、GitLab、Jira、ServiceNow、Slack、Teams 等工具。
这些工具继续负责采集数据、触发告警、展示 dashboard、记录代码和工单。Rootly 做的是把这些信号拉进一个事故响应流程里。
告警来了,Rootly 可以创建 incident,拉起 Slack 或 Teams 频道,通知 on-call,分派角色,关联服务和团队,记录时间线,生成状态更新,创建复盘和 action items。
也就是说,它不抢底层 telemetry 数据底座,而是抢事故处理入口。
这点很聪明。
企业不会轻易迁移自己的监控和日志系统。一个公司可能已经在 Datadog、Grafana、Prometheus、Splunk、ELK 上投入了很多年,不会因为一个 AI RCA 功能就全部换掉。
但它有可能接受一个新的事故工作台,让这个工作台去连接现有工具,把告警、快照、代码变更、Kubernetes 事件、会议记录、复盘文档组织起来。
这就是 Rootly 的位置:不是数据采集层,而是 incident evidence layer。
告警不是事故,RCA 也不是告警解释
很多 AI RCA 产品容易从单条告警开始。
一条告警触发,AI 生成一段解释:“根因可能是数据库连接池耗尽。”看起来像一个 RCA,但真实生产里往往没这么简单。
事故不是一条告警。
一个真实事故经常是一串告警风暴:API 延迟升高、下游超时、Pod 重启、错误率上升、队列堆积、某个 region 报警、某个客户投诉、Sentry 报错暴增。
如果 AI 对每条告警单独写小作文,用户得到的不是 RCA,而是一堆更会说话的噪音。
Rootly 在 Alert Management 上做了 dedupe 和 grouping,这点非常关键。它会把重复告警合并,把相关告警聚合到同一个 leader alert,让团队围绕一个 incident episode 工作。
这看起来不像 AI 功能,但它是 AI RCA 的基础。
没有正确的事故边界,AI 很容易把不同问题混在一起,或者把同一个故障拆成多个孤立问题。
所以我越来越觉得,AI RCA 的第一步不是大模型,而是把告警组织成事故。
先回答“这是不是同一个问题”,再回答“这个问题为什么发生”。
🌽 可观测性 + AI 这套东西涉及的信息比较多,很多公司的人力主要投入在主营业务上,无暇他顾,如果您需要一个靠谱的乙方来帮您构建这套体系,欢迎联系我们做产品技术交流:https://flashcat.cloud/contact/
Rootly 的 AI 更像事故现场助理
Rootly 现在公开文档里最成熟的 AI 功能,不是最激进的自动修复,而是一批低风险、高频的事故现场能力。
比如自动生成 incident title。
事故刚开始的时候,标题经常很粗糙:“prod issue”“api down”“sev2 problem”。这种标题对当前处理勉强够用,但过几周再看,基本没有信息量。Rootly AI 会根据告警、timeline、早期上下文和 Slack 消息生成更可读的标题。
再比如 incident summarization。
它会把 incident metadata、alerts、timeline events、action items、communications、Slack messages、meeting transcripts 组织成当前事故摘要。这个摘要不是为了炫技,而是为了让所有人快速对齐:问题是什么,影响是什么,已经做了什么,还有什么没解决。
还有 incident catchup。
事故进行到一半,新的人加入频道,最怕问一句“现在什么情况?”因为这会打断所有人的节奏。Rootly 让用户在 Slack 里运行 /rootly catchup,生成一个只对自己可见的私有摘要。
这个功能很小,但非常贴近真实事故现场。
事故处理中,很多成本不是查一个日志,而是反复解释上下文。谁刚加入都要问一遍,谁交接都要总结一遍,谁写状态更新都要重新整理一遍。
AI 如果能把这些重复认知负担降下来,价值已经很实在。
AI RCA 不能忽略会议和聊天
Rootly 的 Meeting Scribe 也值得关注。
它可以加入 Zoom、Google Meet、Webex、Microsoft Teams 等事故会议,做转录、录制、speaker 识别、会议摘要,并把 transcript 和 summary 附到 incident。
为什么这件事重要?
因为很多根因分析需要的关键信息,根本不在指标、日志、链路里。
它在会议里。
某个工程师口头确认“刚刚 rollback 了”。某个负责人判断“问题不在数据库”。某个团队解释“这个 PR 只影响灰度环境”。incident commander 决定“先降级功能,别继续扩容”。客户成功团队确认“目前只影响某一批客户”。
这些信息如果没有被记录,事后做 RCA 就只能靠人回忆。
而人的回忆在事故之后通常并不可靠。大家都很累,细节会丢,时间点会模糊,很多当时被推翻的假设也会被遗忘。
所以 Meeting Scribe 这类能力,表面上是会议记录,本质上是把口头事故上下文变成可检索、可复盘、可被 AI 使用的证据。
这对可观测性厂商是一个很大的提醒:机器事实很重要,但事故事实同样重要。
机器事实告诉你系统发生了什么。事故事实告诉你团队当时怎么判断、怎么决策、怎么止血。
AI RCA 如果只看机器事实,容易缺半边上下文。
Rootly 的 AI SRE 宣传很激进,但文档很克制
Rootly 有一个 AI SRE 产品页,标题就是 AI SRE to Automate Root Cause Analysis。
它在这个页面里讲得很激进:分析 code changes、telemetry、past incidents,快速识别 root cause 和 fix;给 probable root causes、confidence scores、suggested fixes;发现 similar incidents;在 Slack 和 IDE 里帮助处理事故;自动生成 retrospectives。
这个方向很清楚。
Rootly 想做的不只是 AI 摘要,而是一个围绕事故生命周期工作的 AI SRE。
但我觉得这里需要保持一点判断力。
从公开文档看,Rootly 已经明确文档化、边界比较清楚的 AI 功能,主要还是标题、摘要、catchup、mitigation / resolution summary、Ask Rootly AI、AI Editor、Meeting Scribe、隐私和数据控制。
官方 FAQ 甚至明确说,Rootly AI 不会自动采取动作或修改事故属性,它提供的是 suggestions、summaries、contextual guidance,人类仍然控制决策和更新。
这说明 Rootly 在产品落地上其实很克制。
营销上讲 AI SRE 和自动 RCA,产品文档里强调人类确认、建议优先、不会自动改事故属性。
我认为这是对的。
企业级 AI SRE 不应该一上来就抢生产指挥权。更合理的路径是先让 AI 做低风险的事情:总结、解释、整理、找历史、起草沟通、生成复盘。等用户在这些场景里建立信任,再逐步走向自动调查、建议修复和受控执行。
信任不是发布会上喊出来的,是一次次小场景里攒出来的。
MCP 和 IDE 插件,是 Rootly 最值得关注的新入口
这次看 Rootly,我最感兴趣的其实是它的 MCP Server 和 Agent Plugins。
Rootly MCP Server 把 Rootly 的 incident data 和 actions 暴露给 Cursor、Windsurf、Claude Code、Gemini CLI、Codex 等 MCP-compatible clients。
这意味着,事故管理不一定只发生在 Rootly Web 或 Slack 里,也可以发生在开发者正在工作的 IDE 和 terminal 里。
Rootly 的 Agent Plugins 里有几个命令很有意思。
比如 /rootly:respond [id],可以拉取事故上下文、找历史相似事故、展示当前 on-call。
比如 /rootly:retro [id],可以帮助生成复盘。
最值得关注的是 /rootly:deploy-check。
它会分析当前 git diff 和历史事故,提醒类似变更是否曾经导致 outage。
这个方向很重要,因为它把 RCA 从“事故发生后分析”往前推到了“变更发布前预防”。
过去我们做 RCA,经常是在事故结束后问:这次是谁改坏了?
未来更好的体验应该是,在代码还没发出去之前,AI 就提醒你:这个改动和过去某次事故很像,最好检查一下这个依赖、这个配置、这个降级逻辑。
这才是组织记忆真正产生复利的地方。
历史事故不应该只在复盘库里躺着。它应该在下一次相似风险出现时自动浮出来。
组织记忆会成为 AI SRE 的核心资产
Rootly 的 MCP Server 里有 find_related_incidents 和 suggest_solutions 这类工具。
简单说,就是找相似历史事故,并从历史解决方案里挖掘下一步建议。
这件事听起来没有“自动根因分析”那么酷,但我觉得它非常接近真实 SRE 的工作方式。
一个资深工程师排障快,很多时候不是因为他现场推理能力比别人强很多,而是因为他见过类似问题。
他知道去年这个服务也因为某个配置出过事。他知道某个看起来像数据库的问题,其实上次是下游重试风暴。他知道某个告警经常是连锁反应,不是根因。他知道应该先找哪个团队、哪个人、哪个 dashboard。
这就是组织记忆。
AI SRE 真正有价值的地方,不是每次从零开始推理,而是把组织过去踩过的坑变成下一次事故的上下文。
事故中收集证据。事故后生成复盘。复盘里沉淀 action items。历史事故反哺下一次调查。类似变更在发布前被提醒。
这条闭环如果跑起来,AI SRE 就不只是一个聊天助手,而是组织可靠性经验的放大器。
Edge Connector 暗示了自动化的下一步
Rootly 还有一个 Edge Connector,运行在客户自己的环境里,通过 outbound-only polling 连接 Rootly 和内部系统。
它可以执行自动动作,也可以执行由用户手动触发的 callable actions。比如 critical alert 触发后重启服务,incident 创建时自动采集日志和诊断信息,触发 Ansible playbook,执行 rollback、扩容、清缓存,或者和内网 Jira、ServiceNow、自研系统集成。
这对 AI SRE 很关键。
AI 只做总结,价值有限。AI 能查证据,价值更高。AI 能在受控环境里触发诊断采集和半自动处置,价值会再上一个台阶。
但这里也最危险。
一个摘要错了,工程师可以改。一个建议错了,工程师可以忽略。一个自动执行的生产动作错了,后果完全不同。
所以 Edge Connector 这类能力必须配合权限边界:脚本白名单、只读默认、人工确认、审计日志、scoped API key、团队级权限、审批和回滚。
对国内客户来说,这一点更重要。
金融、运营商、能源、制造、政企客户,不会因为一个 AI demo 很惊艳,就把生产写权限直接交给 SaaS。更现实的路径是本地 connector、outbound-only、最小权限、工具 allowlist、全量审计。
AI SRE 要进生产,安全架构不是附加项,而是门票。
对国内可观测性厂商的启发
如果只看功能列表,Rootly 可能不像 Splunk 那样拥有完整 observability 数据底座,也不像 Resolve AI 那样把 multi-agent investigation 讲得很深。
但它抓住了一个很重要的事实:事故不是一个技术诊断问题,而是一个跨工具、跨团队、跨时间的协作问题。
所以 AI RCA 不能只做“日志总结”或“指标解释”。
它要处理的是完整事故流程:
告警如何聚合。事故如何创建。谁应该响应。哪个服务受影响。最近有什么变更。Slack 或飞书群里确认了什么。会议里做了什么决策。历史上有没有类似问题。当前判断有哪些证据。下一步动作是什么。复盘和 follow-up 有没有闭环。
对国内监控和 AIOps 厂商来说,我觉得可以按这个顺序做。
第一,先把告警变成 incident。不要让 AI 对每条告警单独写解释,而是先做 dedupe、grouping、episode、owner、service、environment。
第二,把 evidence 做成一等公民。指标图、日志模式、trace sample、拓扑路径、近期变更、Kubernetes 事件、工单、发布记录,都应该进入事故时间线。
第三,把协作入口做进去。国内不一定是 Slack,更多可能是飞书、企微、钉钉。事故在哪里处理,AI 就应该在哪里出现。
第四,先做低风险 AI。标题、摘要、catchup、状态更新、客户沟通、复盘草稿、follow-up 建议,这些场景高频、低风险,也最容易建立信任。
第五,再做调查包。候选根因、证据链、时间线、相似历史事故、近期变更、被排除假设、置信度、下一步验证命令。
第六,最后才做受控执行。先只读,再建议,再人工确认,再审批执行。不要一上来就讲全自动修复。
这个顺序不花哨,但比较接近企业真实采用路径。
最后的判断
Rootly 给我的最大启发是:AI RCA 的终局不是一个更聪明的聊天框,也不是一个“生成根因”的按钮。
它更像一个围绕事故生命周期运转的智能系统。
它要连接告警和事故,连接机器事实和人类判断,连接当前现场和历史经验,连接根因分析和后续行动。
Rootly 的路线是 incident-native。它不一定拥有最深的 telemetry 查询能力,但它拥有事故协作入口、时间线、复盘、on-call、会议、历史事故和 agent tool layer。
这对传统可观测性厂商是一个提醒:只拥有 metrics、logs、traces 不够。
未来 AI RCA 的竞争,很可能会发生在几个更底层的问题上:
谁能拿到完整事故上下文?谁能把告警组织成可处理的 incident?谁能把历史事故变成组织记忆?谁能让 AI 在 ChatOps 和 IDE 里自然工作?谁能把 RCA 输出变成行动、复盘和预防?
我越来越觉得,下一代 AI SRE 产品的核心,不是“更会回答问题”,而是“更懂事故现场”。
Rootly 不是这个方向的唯一答案。
但它已经把一个信号讲得很清楚:可观测性让我们看见异常,AI SRE 要让我们理解事故,并把经验带到下一次事故之前。
参考资料:Rootly 官网、Rootly AI SRE 产品页、Rootly 官方文档、AI / Alerts / Integrations / MCP Server / Agent Plugins / Edge Connectors 文档、Rootly 官方融资博客和 TechCrunch 报道。
