 夜雨聆风
夜雨聆风AI 文献工具的变化,不只是检索更快,而是研究者开始把“问题本身”交给系统处理。
 图注:跨学科研究的第一步,正在从输入关键词,转向描述问题并生成可核查的文献地图。
图注:跨学科研究的第一步,正在从输入关键词,转向描述问题并生成可核查的文献地图。
2026 年再看 AI 文献工具,一个明显变化是:不少研究者不再只把它当搜索框用。过去的动作是打开数据库、输入关键词、筛选年份、下载 PDF;现在更常见的起点,变成了把一个还不够成熟的问题写出来,让 AI 先帮助拆分方向、找出文献线索,再由人继续判断。
超能文献这次全学科升级,值得放在这个背景里看。它从原先更偏医学、PubMed 场景的使用方式,扩展到 PubMed、OpenAlex 等开放学术数据库,配合自然语言检索、专家模式、Deep Research、文档翻译和 Zotero 工作流。若只把它理解成功能变多,反而容易看小了。更重要的是,它把“找文献”这件事往前推了一步:从输入关键词,变成先整理问题入口。

最容易受影响的,是跨学科选题里的年轻研究者
研究生和青年科研人员,是这类变化里最典型的一群人。
他们的问题往往不是不会用数据库,而是不知道第一轮该怎么问。导师给了一个方向,题目还没收束,学科边界又不清楚:可能同时碰到医学、AI、材料、工程或社科方法。这个阶段如果直接靠关键词检索,很容易出现两种结果:搜得太窄,只看到自己熟悉的那一支;搜得太散,Zotero 里堆了很多 PDF,却没有形成脉络。
一个常见场景是,学生想了解“AI 辅助药物筛选中的可解释性方法近五年有哪些主要路线”。这句话看起来清楚,真正开始搜就会分叉:可解释性是指模型解释,还是分子表示?药物筛选是偏虚拟筛选、分子生成,还是临床前研究?论文线索该从 AI 会议找,还是从生物医学数据库找?
很多选题卡住,并不是因为文献不够多,而是第一张地图画得不稳。
这时更合适的做法,不是先逼自己凑出一组完美关键词,而是把问题写完整。例如:
“AI 辅助药物筛选中的可解释性方法近五年有什么主要路线?请关注生物医学和 AI 交叉研究,优先看综述、代表性方法论文和引用较多的研究。”
超能文献可以基于 PubMed、OpenAlex 等开放学术数据库,把这类自然语言问题拆成多组检索线索:drug discovery、virtual screening、explainable AI、graph neural network、molecular representation 等。专家模式下,系统会做查询重写、文献筛选、结果重排和一致性校验。多模型协作不能避免所有误差,但它能让第一轮探索少一些碰运气。
这里的重点不是“AI 替你读完论文”,而是它先把混乱拆开。
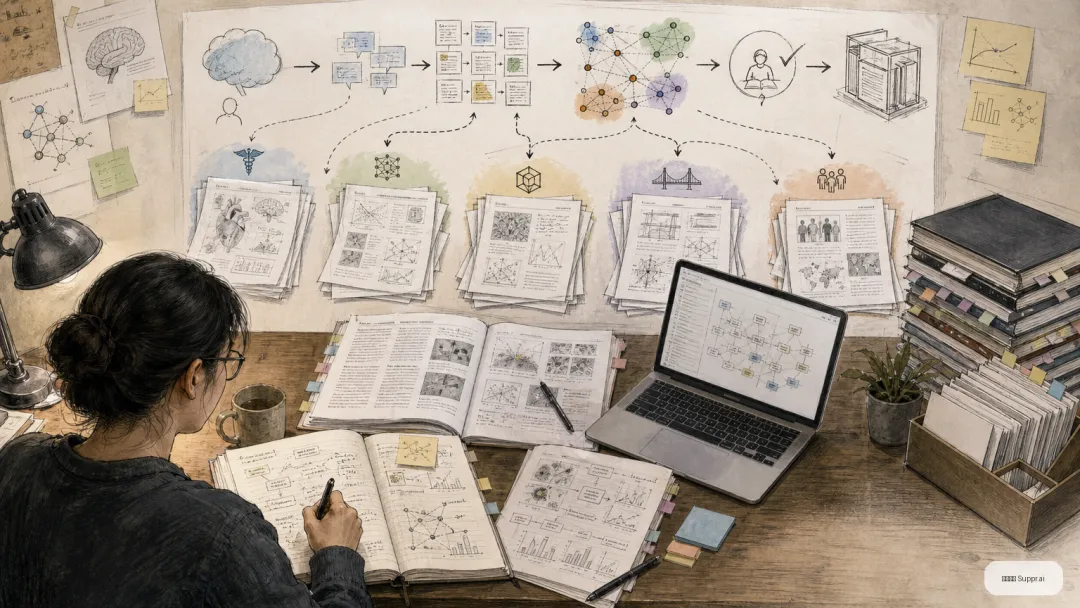 图注:一个更实用的流程:自然语言问题输入 → 查询重写与初筛 → 研究脉络提取 → 人工核查 → Zotero 沉淀。
图注:一个更实用的流程:自然语言问题输入 → 查询重写与初筛 → 研究脉络提取 → 人工核查 → Zotero 沉淀。
第一轮结果出来后,最好不要急着下载全文。更有价值的动作,是先看系统整理出的中文摘要、核心观点、研究脉络和思维导图:哪些论文像主线,哪些只是术语相近,哪些方法正在聚合,哪些争议还没有解决。Deep Research 生成的结构化研究报告初稿,也适合用来做综述准备或开题前的方向梳理。
但这份初稿不能直接变成正式结论。跨学科研究里,最容易出问题的地方不是漏掉一篇文章,而是把“词相近”误判成“问题相同”。研究者仍然要回到原文,核查实验设计、数据来源、方法适用范围和引用关系。AI 适合把候选路径铺开,真正决定哪条线值得追,仍然要靠人的研究判断。
最后,筛选过的文献和笔记进入 Zotero。超能文献接入 Zotero 的意义,不是让文献管理多一个入口,而是让“检索—理解—筛选—沉淀”连起来。对研究生来说,理想结果不是多存几十篇 PDF,而是形成一个能继续扩展的框架:核心问题是什么,方法路线分几支,关键论文是哪几篇,下一轮该追哪些引用链。

对教师和 PI,它更像是压缩前期准备时间
高校教师和 PI 的卡点不太一样。他们通常不缺判断力,缺的是时间。
准备课题材料、学术报告或进入相邻领域时,从空白文档搭框架成本很高。熟悉期刊、熟人推荐和既有阅读经验很有用,但也可能带来路径依赖。Deep Research 在这里更像一个“研究辅助初稿”:先整理问题背景、主要路线、代表性文献和潜在争议,再由研究者把时间放在关键引用核查、方法边界判断和材料重写上。
这不是把专家判断交给 AI。更准确地说,好的 AI 文献入口会让判断更早发生:哪些结论站得住,哪些只是摘要层面的相似,哪些文献值得进入正式材料。AI 在科研里的稳妥位置,通常不是替人下最终结论,而是缩短从空白到可讨论框架的距离。
对企业研发,它提供的是更宽的学术视野
企业研发和技术情报人员也会用到这类工具,但不必把它夸大成商业决策系统。现实中的技术问题很少只待在一个学科里:材料问题可能连着工程工艺,医疗器械可能连着算法评估,环境问题可能同时牵涉农业、化学和政策研究。
 图注:跨学科问题常常需要同时查看不同学科线索,OpenAlex 等开放数据库让入口更宽。
图注:跨学科问题常常需要同时查看不同学科线索,OpenAlex 等开放数据库让入口更宽。
对这类用户来说,更实际的用法是围绕一个技术问题做自然语言检索,先看相关论文、引用线索和研究脉络,再用结构化报告初稿辅助内部讨论。技术可行性、产品边界和商业判断仍然要由专业人员完成。AI 适合把早期信息面铺开,不适合替团队拍板。

真正变化的是研究入口
所以,超能文献全学科升级的重点,不只是覆盖医学、生命科学、材料、工程、AI/计算机、经济金融、法学社科、教育心理、环境农业、数学与基础科学等方向。覆盖面是前提,更关键的是能不能把这些方向放进同一个研究动作里:用中文或英文描述问题,让系统基于开放学术数据库理解问题、改写查询、初筛文献、组织脉络,再把结果沉淀成可核查的材料。
普通搜索框解决的是“我知道我要找什么”。但研究早期更常见的状态是:“我还不知道该怎么问。”这就是 AI 文献工具开始从搜索工具转向研究入口的原因。
当然,AI 仍然会犯错。开放数据库有覆盖边界,模型对相近概念的判断需要复核,引用信息也不应未经检查就写进正式文本。成熟的用法不是相信系统给出的每句话,而是让它把第一轮问题拆解和候选路径准备好,再由人完成更难的判断。
科研工作流里真正昂贵的,从来不是点击搜索按钮的几秒,而是把一个模糊问题变成可推进问题的那段时间。下一次进入陌生方向时,或许不必先从关键词开始,可以先把问题写完整。
想试试这种入口,可以访问 suppr.wilddata.cn。先让 AI 帮你搭出第一张可核查的文献地图,再决定往哪条路深挖。
