 夜雨聆风
夜雨聆风有一天下午,我盯着电脑上开着的二十几个标签页,突然意识到一件事,我花在「导航」上的时间,已经快赶上我花在「思考」上的时间了。
登录这个后台,复制这份数据,切到那个表格,填进去,再回来确认,再跳去另一个网站查个信息……这整个流程里,真正需要我脑子的部分,其实只有最初的判断和最后的拍板。中间那一大段,都是机械动作。
我当时想,如果有个东西能帮我把这些机械动作接管掉就好了。
OpenAI上周给了一个答案,不是我以为的那种答案,是一个更激进的答案。
他们上架了一个叫 Codex for Chrome 的浏览器扩展。表面看,这是个「帮你操作网页」的工具,但只要你稍微往深处想一想,就会发现这件事的分量远不止于此。

先说清楚它到底做了什么。
Codex for Chrome 装在你的 Chrome 浏览器里,你给它一个指令,它就自动去网上帮你干活。这本身不稀奇,市面上类似的浏览器自动化工具已经存在了好几年。
稀奇的地方在于,它用的是你「已经登录好」的 Chrome。
这句话听起来平平无奇,但你要是做过任何一点点自动化开发,或者自己折腾过爬虫、RPA 工具,就会立刻明白这意味着什么。
过去的所有类似工具,遇到需要账号的网站都是一道坎。要么你得把用户名和密码交出去,让工具替你登录;要么你得配置各种 OAuth 授权,走一遍繁琐的鉴权流程;要么工具干脆绕不过去,碰到登录墙就停了。这道坎不是技术问题,是信任问题,是权限边界的问题。
Codex for Chrome 的做法是,直接绕开这道坎。
它不问你要密码,它不走 OAuth,它什么鉴权流程都不走。它直接坐进你已经打开的 Chrome,用你早就登录好的 session,以「你」的身份进入那些网站,然后替你干活。
你公司的内部 OA 系统,你的 CRM 后台,你的 AWS 控制台,你存了几年私人数据的记账 App……只要你用 Chrome 登着,它全能进。
这是一个很关键的技术选择,它本质上是在说,AI 智能体可以直接继承人类在网络空间里已经建立起来的所有「身份信任」。不需要重新证明自己是谁,直接用你的名义行事。
怎么说呢,这个设计思路一旦说穿了,你会觉得它既天才又有点让人后背发凉。
天才的地方在于,它解决了 AI 智能体落地最难的那道坎。
我们聊 AI Agent 已经聊了很久了,大家都说 Agent 时代要来了,AI 要能真正帮人做事了,不只是给你一段文字,而是真的替你执行任务。但「执行任务」这件事,在现实世界里,意味着你得操作各种各样的系统,而这些系统的访问权限,几乎都是绑在账号上的。
这就是那道坎,AI 有能力,但没有账号。或者更准确地说,给 AI 账号这件事,在安全层面是一个噩梦。
Codex for Chrome 的方案,是把这个问题的解题方向整个换掉。不是「给 AI 一个账号」,而是「让 AI 以你的名义行事,用你的 session」。AI 还是没有独立的账号,但它能做的事,和有账号一模一样。
怎么形容这种感觉……有点像你雇了个助理,但没给他配办公室和工牌,而是直接让他坐在你的位置上,用你的电脑,以你的名义发邮件、审批文件。效率极高,但如果你不在场监督,后果也极难预料。

让人后背发凉的地方,也就在这里。
OpenAI 说这个扩展有安全机制,在执行「敏感操作」之前会先问你一声,比如点提交按钮、下载文件、查看你的浏览历史。这些节点需要你手动确认,AI 不会自己拍板。
这个设计的出发点是好的。
但我真正想说的问题,不在这些「敏感操作」上。那些节点固然重要,但它们是可见的风险点,是容易被意识到的风险点。更让我在意的,是那些介于「无关紧要」和「明显危险」之间的灰色地带。
AI 在帮你整理标签页的过程中,读取了哪些页面的内容?它在替你预填表单的时候,访问了哪些网站的数据?它在跨几个网站查信息的过程中,这些网站各自能看到什么请求、什么时间、什么频率?
这些都不算「敏感操作」,都不需要弹窗确认,但这些信息的流动,构成了一份关于你数字行为的极细颗粒度画像。
坦率地讲,用户在安装这个扩展的那一刻,其实做了一个非常大的信任决定,只是这个决定被包装在「帮你自动填表」这样无害的功能描述里,所以很多人可能没有意识到它的规模。
你信任的不是某一个具体操作,你信任的是一个能访问你所有登录状态的 AI 系统,能以你的身份在你登录的每一个网站上行动。这个信任半径,比你安装任何一个普通 App 时给的权限都要大。
我们来想一个具体的场景。
你让 Codex 帮你做一件很日常的事,从公司内部系统里拉上个月的销售数据,整理成一份摘要。
Codex 打开内部系统,用你的 session 登录,找到数据,读取,整理,给你一份摘要。
这个流程里,有几个问题值得想清楚。
第一,这份数据在被 Codex 读取和处理的过程中,经过了哪些节点?OpenAI 的服务器?还是全程本地处理?如果经过了远端,那这份「本来只能在公司内网访问」的数据,实际上已经穿越了公司的安全边界。
第二,你公司的 IT 团队,对这件事有没有感知?大概率没有。他们的系统日志里,看到的只是你的账号在正常访问数据,他们不知道「你」其实是一个 AI。这对企业的数据安全策略来说,是一个真空地带。
第三,这份摘要是怎么生成的?OpenAI 有没有用这份数据来训练模型?这个问题不是阴谋论,而是一个正当的数据权利问题。
我不是说 OpenAI 一定做了什么不好的事,我是说,这个工具让这些问题的边界变得比以前模糊了很多,而且模糊得很隐蔽,不容易被注意到。
从平台生态的视角看,这件事同样意味深长。
互联网的商业模式,很大程度上建立在「用户必须来我这里」这个前提上。你来我的网站,我给你展示广告,我采集你的行为数据,我让你在我的界面上完成所有操作,这是流量变现的基础逻辑。
但 Codex for Chrome 这类工具,把这个逻辑打了一个大问号。
如果 AI 替你去那些网站干活,你自己根本不打开那个页面,你只是在对话框里问一句话,然后等结果,那「流量」去哪了?广告给谁看?用户行为数据从哪里采集?
更大的问题是,很多平台的核心竞争力,就是「界面」本身,是那套交互设计,是用户在平台上停留的时间里产生的黏性。但如果 AI 接管了操作层,用户不需要真正「在」那个网站上,只需要拿到数据和结果,那界面这道护城河,就基本上不存在了。
对平台来说,这个冲击比任何一个竞争对手都要根本,因为它不是「另一个更好的平台来抢用户」,而是「用户跟你之间的中间层被重构了」。
以前是你用工具访问平台,现在是你用 AI 访问平台。这两者之间的差距,比表面看起来大得多。
这件事还有一个维度,我觉得讨论得还不够充分,就是「自动化」和「授权」之间的哲学关系。
当你告诉 Codex「帮我登几个网站查点信息,然后汇总给我」,你其实授权了什么?
你授权它访问那几个网站,这是明确的。但你授权它读取这些网站上的所有内容了吗?你授权它在这些网站上留下访问痕迹了吗?你授权它把这些网站的信息整合在一起,形成一个你原本需要手动操作才能完成的知识提取动作了吗?
这个问题之所以复杂,是因为「帮我查点信息」这个指令,在意图上是清晰的,但在操作路径上,它包含了太多你没有明确表达过同意的细节。
传统的软件授权模型,是把权限颗粒化,你同意这个权限,不同意那个权限,每个权限对应一个明确的功能。但 AI 智能体打破了这个模型,因为它的能力太灵活,它完成一个目标的路径是动态的,不能事先穷举。
这意味着我们需要一种全新的「意图授权」框架,用户表达的是目的,而不是操作步骤,但这个目的的边界,需要有机制来约束和验证。
OpenAI 目前的做法,是在「高风险操作」上加确认节点,这是一种最直觉的解法。但它是不是充分的?对于不同用户、不同场景、不同数据敏感度来说,这套阈值是否合适?这些问题,我认为还没有一个好答案。
说真的,我不是想把这件事写成一篇恐慌稿。
Codex for Chrome 解决的问题是真实的,AI 智能体需要能操作真实的网络环境,这个方向是对的,是必要的。如果 AI 永远只能在沙盒里生成文字,永远摸不到有账号保护的真实系统,那它就永远只是一个高级文字处理器,而不是一个真正的助手。
Codex 这类工具,是 AI 从「给你答案」走向「替你行动」的关键一步。这一步迈出去,AI 的实用价值会有质的飞跃,很多之前只能想象的场景,现在真的开始变得可能了。
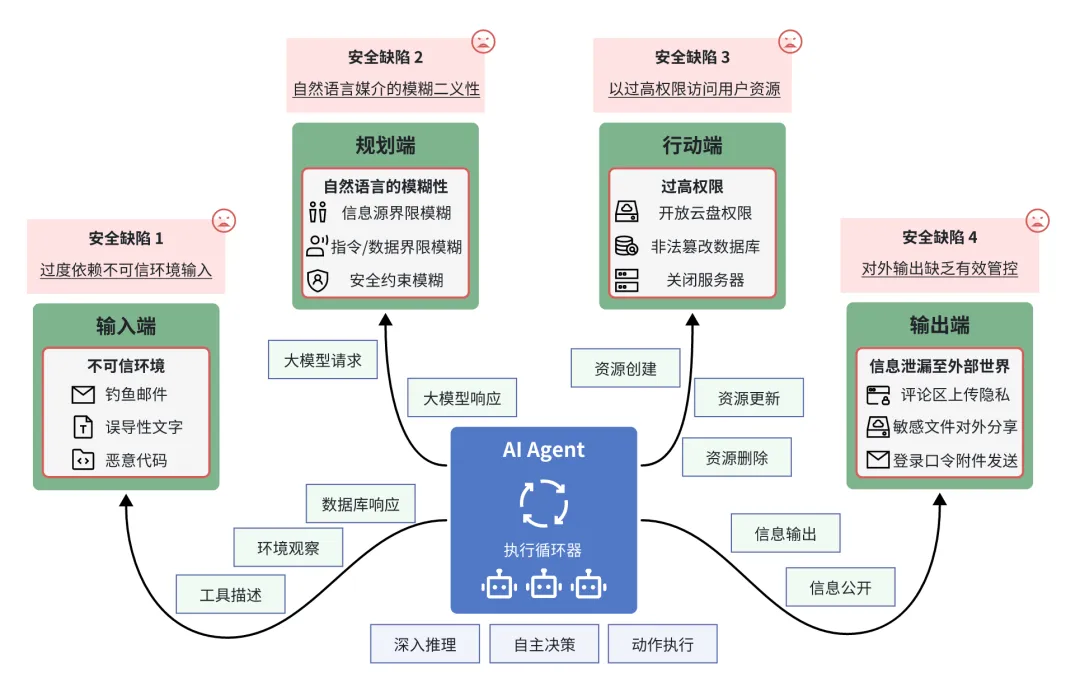
但这一步同时也意味着,AI 与互联网的关系,进入了一个新的阶段,一个需要我们认真重新思考「信任、权限、数据边界」的阶段。
过去我们谈 AI 的风险,更多是在谈「它会不会生成错误的内容」「它会不会被滥用来做假新闻」。这些当然重要,但它们发生在「信息」层面。
Codex for Chrome 把风险的层面提升到了「行动」层面。AI 不只是在帮你看世界,它开始帮你动手了,用你的手,在你的网络空间里,以你的身份。
我想到了一个也许过于文学化的比喻,但我觉得它是准确的。
以前的 AI,是一个坐在图书馆里帮你查资料的助手。它博学,它快,但它待在图书馆里,资料出不了门,操作也都发生在那个可控的空间里。
Codex for Chrome 之后的 AI,是一个拿着你的钥匙串的助手。你信任它,把你所有门的钥匙都给了它,让它帮你打理各种事。它进出你的网络空间,以你的名义签到、查数据、填表格、提交申请。你不用每次都陪着,它替你把事办了再来汇报。
这个模式的效率,毋庸置疑会高很多。
但你对这个助手的信任,不再只是「它会不会说错话」,而变成了「它会不会用对我那把钥匙」。两者之间,信任的深度和风险的量级,都不是一个数量级。
我们现在站在这个转变的起点上。用户、平台、监管机构、AI 公司,所有人都还在摸索这套新规则应该长什么样。
最后我想说一件比较私人的事。
我第一次看到 Codex for Chrome 的介绍,第一反应是「哇,这个真的能让我效率翻倍」。第二反应是「等等,这个东西能进我的哪些系统」。这两个反应几乎是同时发生的,中间没有时间差。
我觉得这个感受本身,就是一个很诚实的信号,就是我们很多人在面对这类工具时内心真实状态的写照。
我们既想要那份效率,又对那份效率背后的代价有一种本能的警觉,但这个警觉还没有成熟到能指导我们做出清醒决定的程度。
而这个空窗期,正是 AI 公司快速建立用户习惯的窗口期,也是监管规则最跟不上的阶段,也是用户最容易在不知不觉间完成大授权的时候。
我写这篇文章,不是劝大家不用 Codex for Chrome,也不是说 OpenAI 在做坏事。我只是觉得,当一项技术正在改变我们与数字世界之间的关系的时候,至少应该把这件事说清楚,让每个人都能在清醒的状态下决定自己愿意走多远。
这个选择,总归是你自己的。
你对这类「以你的身份行事」的 AI 工具,最担心的是哪个层面,是数据隐私,是误操作风险,还是别的什么?欢迎在留言区告诉我,我很好奇大家的直觉反应是什么。
