 夜雨聆风
夜雨聆风一个大问题:Hermes 中文对话环境下记忆插件失效
一、206 次对话,43 条事实
我从 4 月 9 日开始用 Hermes Agent,第一时间配了 Holographic 记忆插件——官方文档说它能自动提取偏好、习惯、决定,存进永久事实库。
前两周用的挺好,结果这两周,我让Hermes记住什么的时候,他总是说:「记忆快满了,我去删一条旧的,然后记住新的。」
按理说我配置了Holographic,不该满,所以我起了疑心,扫了一遍数据:
136 兆的对话数据库,近万条消息,但「记忆」部分只有 43 条结构化事实。平均每 5 次对话存下 1 条,每 224 条消息存下 1 条。翻了一遍这 43 条——没有一条涉及用户偏好:没有「喜欢简洁回答」,没有「项目用 Python 写公众号文章」,没有「写作流水线有固定步骤」。全是技术细节和工具配置。
不是「记得少」,是写入侧几乎没工作。
我开始审查源码。
二、架构解剖:坏在哪里
先交代 Hermes 的记忆是怎么工作的。不了解这套机制,无法定位故障根源。
Hermes 的记忆不是一整块,是一个双层镜像:
Layer 1: memory 工具 ├─ compact 槽位,容量 2,200 字符 ├─ 每轮对话自动注入 system prompt └─ 写入内容会镜像到 Layer 2Layer 2: fact_store 工具 ├─ 无限容量,SQLite + FTS5 全文搜索 ├─ HRR 向量(1024 维)支持代数推理 └─ 信任评分 + 矛盾检测设计意图是: 一条新事实通过 memory 工具写入 → 立即出现在 compact 槽位(本轮回话可见)→ 镜像写入 fact_store(通过这个去使用Holographic等记忆插件,实现永久保存)
两个层始终保持同步。
实际运行中,这个镜像结构出现了三个大坑。
大坑一:auto_extract 正则全是英文(核心根因)
auto_extract 是记忆系统的「自动捕手」。每轮对话结束后,它扫描你的消息,用正则匹配偏好、决策、习惯,自动写入记忆。
配置文件里写着 auto_extract: true,但它只认识英文。
plugins/memory/holographic/__init__.py 中 auto_extract 的定义区,9 条正则全部是英文句式:
re.compile(r'\bI\s+(?:prefer|like|love|use|want|need)\s+(.+)')re.compile(r'my (?:favorite|preferred|default) \w+ is (.*)')re.compile(r'we (?:decided|agreed|chose) (?:to )?(.+)')# 还有 6 条,全部是英文句式• 「I prefer Python for scripting」→ 匹配 ✓ • 「我喜欢用 Python 写脚本」→ 不匹配 ✗ • 「咱以后都用 Markdown 写」→ 不匹配 ✗ • 「记住,端口都要映射到主网络」→ 不匹配 ✗
206 次中文对话,auto_extract 对中文句式匹配了零次,啥也没记住。
大坑二:memory 槽位太小,却被当成了主仓库
memory 工具的容量只有 2,200 字符。一条中等复杂度的偏好加上上下文引用,轻松占掉 200 字符。十几次对话后,槽位满了,新事实开始挤掉旧事实。
agent 不知道还有 fact_store 这个无限容量的主仓库。它的 system prompt 里只提了 memory,所以它只往那个 2,200 字符的小槽位里塞。塞满了就覆盖旧的——fact_store 虽然无限容量,但 agent 根本不知道它的存在。
大坑三:镜像方向反了
所谓好记性不如烂笔头:正常人的大脑擅长短期记忆,容量有限;记事本擅长长期存储,容量几乎是无限的。
结果呢,因为Hermes 觉得他没啥可记的,导致让只有 2,200 字符的 memory 当了「大脑」(短期+入口),让无限容量的 fact_store 反而成了被动接收碎片的「记事本」。事实都塞进那个巴掌大的 memory,塞满了就覆盖旧的——fact_store 再大也白搭,因为它只是 memory 的「镜像」,不是主仓库。
三个大坑叠加的效果:中文的消息在 auto_extract 眼里全是盲区 → agent 只往 2,200 字符的 memory 槽位手动存 → 满了以后新事实覆盖旧 → fact_store 因为是「镜像」而非「主仓库」,只能被动接收从 memory 溢出的碎片。这就是文章开头说的那个问题——206 次对话,43 条事实,记忆插件形同虚设。
三、社区搜索解决方案:有人想过,但没修完全
我琢磨着使用中文和Hermes对话的大有人在,应该有人发现这个问题了。于是我去翻了 GitHub,5 个相关 issue 全修的是搜索侧和编码兼容:
连第三方 fork 的 holographic-zh 也只改了分词和 embedding,auto_extract 那 9 条英文正则未做任何修改。
暂未找到覆盖写入侧根因的 issue 或 PR。
四、修复方案:三层加固
找到病因之后,修复思路很明确:在两个文件里写提示词,再加一个代码补丁。三层各有侧重。
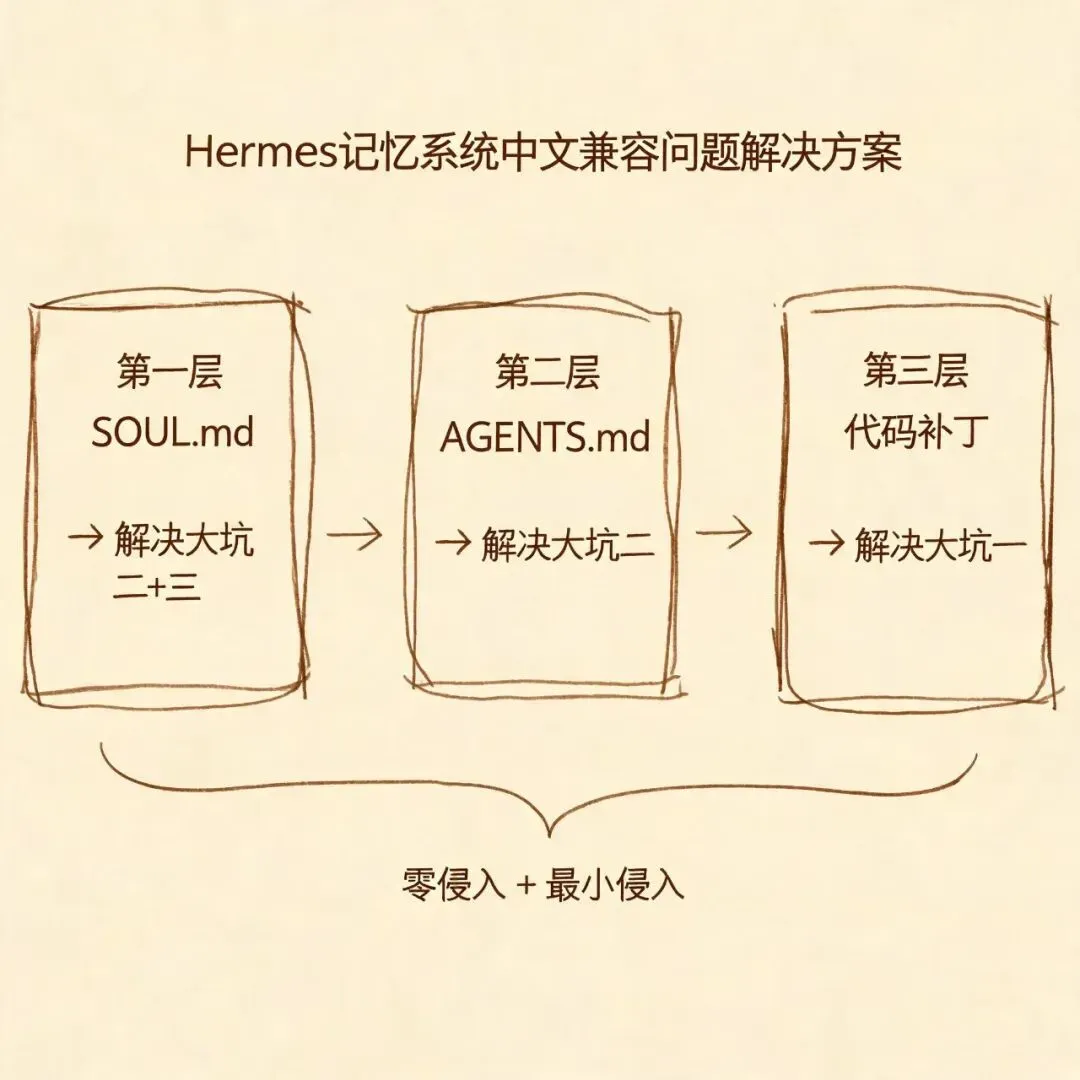
第一层:SOUL.md 内存优先级铁律(零侵入,100% 抗升级)
SOUL.md 是 Hermes 的系统级灵魂文件,放在 ~/.hermes/SOUL.md。agent 启动时必须加载。升级、重装、config 重置都不碰它——它是用户的私产。
在 SOUL.md 末尾追加 6 条铁律:
## 内存优先级铁律(Holographic Memory)- memory 工具容量极小(2,200 字符),放最精炼的身份信息和一行式偏好摘要。- 所有需要持久化的事实、用户偏好、项目约定、操作习惯,必须用 fact_store 工具写入。- 每轮对话中若透露了新的偏好/信息/决定/纠正/评论,必须在回复中主动调用 fact_store 存储。- 禁止以 memory 已满为由放弃存储——memory 满了就用 fact_store,两者互为补充。- fact_store 写入前先搜索去重,已有同类事实用 update 而非重复 add。- fact_store 写入后用 fact_feedback 标记质量,帮助信任评分训练。这 6 条铁律在 agent 启动时注入 system prompt,不依赖任何代码逻辑。对所有引擎通用——Holographic、Hindsight、Mem0,换哪个引擎都不受影响。
零行代码改动。升级零风险。
第二层:AGENTS.md 中文记忆提取规则(零侵入,100% 抗升级)
AGENTS.md 放在你的项目根目录,Hermes 进入该目录时会自动加载。在末尾追加一节「中文记忆提取规则」:
## 中文记忆提取规则若用户消息命中以下任一信号,必须调用 fact_store 存储:1. 显式指令:「记住」「以后都这样」「别用」「就用」2. 纠正/不满:「不对」「不是」「错」——需结合上下文判断是否为偏好表达3. 偏好/习惯:「我喜欢」「我习惯」「我一般」「我从来」4. 决定/规范:「我们决定」「约定是」「规矩是」「铁律是」5. 可复用事实:「项目用」「部署到」「端口是」存储规范:- category 用英文(user_pref / project / tool / general)- content 保留中文原文- 写入前先 fact_store search 去重第一层保证 agent 知道要去存,第二层保证它知道在什么场景下该存、怎么存。两层配合,都是零代码改动。
第三层:auto_extract 中文正则补丁 + 自动重打(最小侵入,1 个文件)
前两层解决了 agent 的「主动存储意识」,但 auto_extract 本身的正则盲区还在——如果用户没说出「记住」「别忘了」这类信号词,agent 仍可能漏过。必须修 auto_extract 本身。
在 _auto_extract_facts 函数的现有英文正则后追加 9 条中文模式:
# 中文偏好类(5 条)re.compile(r'(?:我|咱)\s*(?:喜欢|习惯|偏好|一般|总是|从不|永远|一直|爱)\s*(.+)'),re.compile(r'(?:我|咱)\s*(?:的)?\s*(?:习惯|偏好|默认|常用|最爱)\s*(?:是|用)\s*(.*)'),re.compile(r'以后\s*(?:都|永远|就)?\s*(?:要用|按|这样)\s*(.+)'),re.compile(r'记住[,,]?\s*(.+)'),re.compile(r'(?:别|不要|不许|不准)\s*(?:再|用)?\s*(.+)'),# 中文决策类(4 条)re.compile(r'(?:我们|咱们|大家)\s*(?:决定|约定|说好|定了)\s*(?:要|去|把)?\s*(.+)'),re.compile(r'(?:项目|工程|代码|这个)\s*(?:用|使用|需要|要求|依赖)\s*(.+)'),re.compile(r'(?:就|已|已经)\s*(?:用|定|选|决定)\s*(.+)'),re.compile(r'(?:规范|规矩|铁律|原则|标准)\s*(?:是|为)\s*(.*)'),改动量:1 个文件,9 行正则。
但还得解决一个问题:Hermes 频繁升级,执行hermes update 就会覆盖这 9 行。解决办法:生成一个补丁文件,放在 Hermes 的用户目录下(升级不会碰它),再利git post-merge hook机制设一个自动重打——每次升级完自动检查正则区有没有被覆盖,覆盖了就自动重打补丁。全程不需要手动干预。
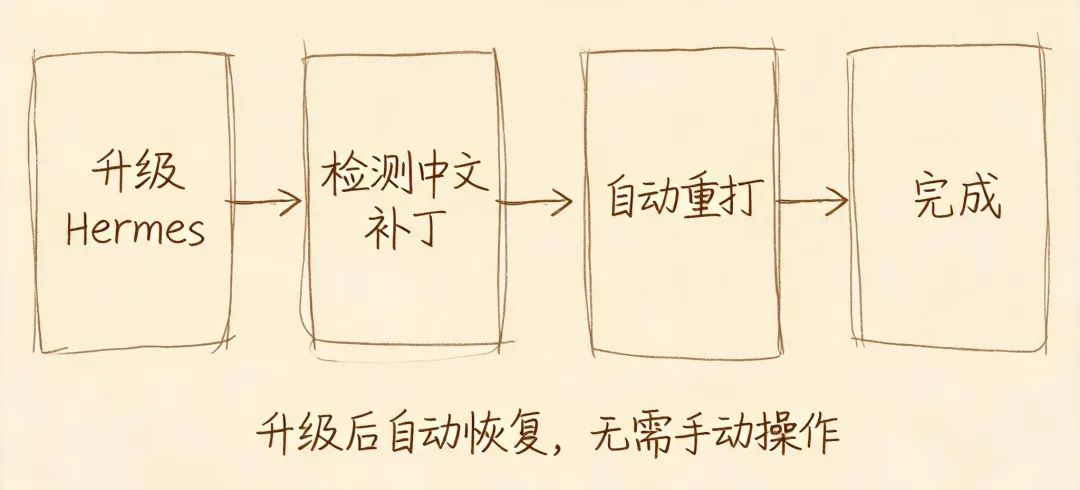
五、上手指南:一段 prompt 修复所有问题
不给你一步步的手动操作。把下面这段话复制,发给你的 Hermes Agent:
请帮我修复 Hermes 中文记忆问题。你需要做三件事:1. 检查 ~/.hermes/SOUL.md,在末尾追加以下内容(如果已存在相似内容则跳过):## 内存优先级铁律(Holographic Memory)- memory 工具容量极小(2,200 字符),只放最精炼的身份信息- 所有需要持久化的事实必须用 fact_store 工具写入- 每轮对话中透露了新信息必须在回复中主动调用 fact_store- 禁止以 memory 已满为由放弃存储- fact_store 写入前搜索去重- fact_store 写入后用 fact_feedback 标记质量2. 检查项目根目录的 AGENTS.md(如没有则创建),追加「中文记忆提取规则」节,包含 5 类触发信号(显式指令/纠正/偏好/决定/可复用事实)+ 存储规范(category 用英文,content 保留中文原文,写入前搜索去重)。3. 找到 hermes-agent 源码中 plugins/memory/holographic/__init__.py 的 _auto_extract_facts 函数,在现有英文正则后追加 9 条中文正则(偏好类 5 条 + 决策类 4 条),然后生成补丁文件 ~/.hermes/scripts/chinese-auto-extract.patch,并设置 git post-merge hook 自动重打。改动范围只在 auto_extract 正则区,不碰其他逻辑。全部改完后,重启 agent,告诉我改了什么。发完这段话后,你的 agent 会自己完成检查、加载、验证。预期输出:
• SOUL.md: 已追加 6 条铁律 • AGENTS.md: 已追加中文记忆提取规则 • init.py: 已追加 9 条中文正则,补丁和 hook 已就位
验证方式:跟 agent 说一句「我喜欢用暗色主题」,退出后查询 fact_store,应该能看到这条事实被自动存入了。
六、常见疑问
「为什么不用 holographic-zh 这个第三方中文记忆插件?」
holographic-zh 在搜索侧做了实实在在的改进——改了分词器、加了 embedding、调大了预取窗口,中文检索的准确度确实提升了。但它没有覆盖写入侧:auto_extract 那 9 条英文正则未做任何修改。也就是说,搜索变准了,但该存进去的中文事实还是没存进去。方案解决了搜索的问题,写入侧的根因还在,所以整体方案还不完整。
「三层够不够?」
够。第一层解决 agent 的存储意愿(知道该用 fact_store);第二层解决判断能力(知道什么时候该存);第三层解决 auto_extract 的语言盲区(中文输入也能自动匹配)。三层覆盖了从意识到行为到自动化的完整链路。
七、适合谁
如果你用 Hermes Agent 大量进行中文对话,这篇文章适合你。
如果都是英文对话,auto_extract 那 9 条英文正则对你已经够用了。但要注意一个隐蔽的坑:在英文环境中偶尔夹了中文偏好——比如「我喜欢 dark mode」——agent 不会主动存它,因为 auto_extract 匹配不了中文,而「我喜欢」也不是英文显式指令。但如果你说「Remember, 用 pnpm 别用 npm」,其中「Remember」被 agent 理解为显式记忆指令,agent 会手动存储——于是你以为记忆系统正常工作,其实漏了第一条。
这也是这个问题最隐蔽的地方:它不会报错,不会告诉你什么都没存。只是静默地丢失每一条中文偏好。
我是轩少,替你把 AI 的坑踩完,你跟着做就行。下期见。

注:本文工具及方法仅用于学习与公开资料整理,涉密单位请严格遵守本单位信息化安全规定。
