 夜雨聆风
夜雨聆风本指南将教你如何使用 MCP、Python 和结构化证据层,构建一个能够深度检验投资假设的专业金融研究助手。
💡 引言
大多数金融 AI 工具通常只擅长一件事:总结股票信息。你询问苹果、英伟达或特斯拉,它们会给你一个清晰的价格走势概览、一些比率,可能还有一些公司背景。这确实很有用,但一旦任务涉及到真正的研究,它们就显得力不从心了。
真正的研究通常始于一个观点,而不是一个股票代码。交易员、分析师或产品团队更可能问:“苹果看起来很有吸引力,因为其下行风险已得到控制,且业务质量保持高位。数据真的支持这一点吗?”
这是一个完全不同的问题。简单的摘要无法妥善回答,因为系统需要检验假设本身,而不仅仅是描述公司。
在本教程中,我们将构建一个金融研究助手(Financial Research Copilot)。它能接收自然语言编写的投资假设,通过 EODHD 的 MCP 服务器获取历史价格和基本面数据,将这些输入转化为结构化的证据,并返回一份带有结论的研究备忘录。
🚀 助手产出的核心成果
在进入开发流程之前,先看看我们要构建的最终产出。理解这个项目最简单的方法就是看一个真实的例子。
假设用户输入:
我认为苹果(AAPL)很有吸引力,因为下行风险已得到控制,且业务质量保持高位。你能测试一下 AAPL 过去 180 天的数据吗?
助手不会返回一个松散的摘要,而是将其转化为一份结构化研究备忘录:
1. 待审假设 (Thesis under review)
由于下行风险受控且业务质量持续高位,苹果公司具有吸引力。
2. 支持性证据 (Supporting evidence)
在过去的 180 天里,最大回撤限制在 -13.82%,表明下行风险相对可控。盈利指标强劲,营业利润率为 35.37%,净利润率为 27.04%。资本回报率很高,ROA 为 24.38%,ROE 为 152.02%,表明资产利用效率高且资本效率强劲。增长指标支持业务持续走强,季度收入同比增长 15.70%,盈利同比增长 18.30%。前瞻性预估也保持乐观,预计盈利增长 9.68%,收入增长 6.87%。
3. 削弱假设的证据 (Evidence that weakens the thesis)
过去 30 天的净每股收益(EPS)修正为负(-3),表明分析师情绪有所恶化。
4. 缺失证据 (Missing evidence)
所提供的数据集中没有重大缺口。
5. 结论 (Verdict)
部分支持 (partially_supported) —— 支持性证据多于矛盾性证据,但假设未得到完全确认。
6. 底线评估 (Bottom-line assessment)
苹果公司在利润率、回报率和持续增长的支持下,展现了强劲且一致的业务质量。在观察期内,下行风险相对受控,但并非微不足道。然而,负面的盈利修正引入了一些谨慎情绪,使得该假设虽得到支持,但尚未盖棺定论。
这个例子清晰地展示了项目的目标:我们不是在构建一个简单的“信息搬运工”,而是一个能够根据市场和基本面数据进行逻辑验证并给出结构化判断的系统。
🔍 为什么它与普通股票助手不同?
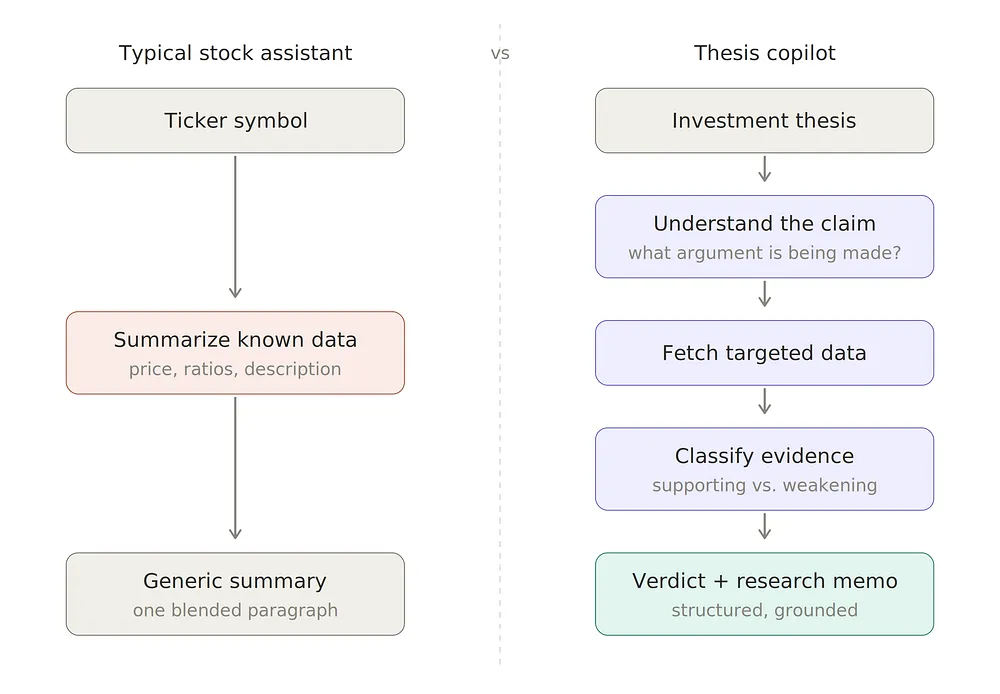
普通股票助手以股票代码为起点,试图解释发生了什么。这在问题比较宽泛时很有用,但面对具体的投资观点时就显得不足。
本项目则从相反的方向出发。输入不是“告诉我关于苹果的情况”,而是一个断言。这改变了系统的工作任务:它必须测试该断言的每个部分,决定什么支持它,什么削弱它,并明确还有什么是缺失的。
这种转变塑造了整个工作流。流水线不再止于检索和总结,而是必须解析假设、将数据映射到正确的证据类型并给出结论。
🛠️ 工作流与项目结构
在高层级上,该助手遵循一个简单的序列:
将用户的假设解析为结构化请求。 通过 MCP 获取历史价格和基本面数据。 将这些输入转化为市场和业务信号。 将信号映射为支持、矛盾和缺失的证据。 给出结论并编写最终备忘录。
项目结构:
project/
├── client.py # MCP 访问层:负责连接、调用工具、错误处理
├── core.py # 核心逻辑:假设检验、数据处理、信号计算
└── test.ipynb # 测试与演示:Jupyter 笔记本,用于端到端验证
1️⃣ 构建 MCP 客户端 (client.py)
MCP(Model Context Protocol)访问层负责与数据源连接。保持这一层轻量化,有助于后续逻辑的推理。
创建 client.py:
import time
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
class EODHDMCP:
def __init__(self, apikey, base_url=None):
self.apikey = apikey
self.base_url = base_url or "https://mcp.eodhd.dev/mcp"
self._tools = None
def _url(self):
return f"{self.base_url}?apikey={self.apikey}"
def _open(self):
return streamablehttp_client(self._url())
async def list_tools(self):
if self._tools is not None:
return self._tools
async with self._open() as (read, write, _):
async with ClientSession(read, write) as s:
await s.initialize()
resp = await s.list_tools()
self._tools = [t.name for t in resp.tools]
return self._tools
async def call_tool(self, name, args, trace_id, timeout_s=30, retries=2):
last = None
for attempt in range(retries + 1):
t0 = time.time()
try:
async with self._open() as (read, write, _):
async with ClientSession(read, write) as s:
await s.initialize()
out = await asyncio.wait_for(s.call_tool(name, args), timeout=timeout_s)
dt = time.time() - t0
meta = {
"trace_id": trace_id,
"tool": name,
"args": args,
"latency_s": round(dt, 3),
}
return out, meta
except Exception as e:
last = e
if attempt < retries:
await asyncio.sleep(0.5 * (attempt + 1))
raise last
这里最重要的两个方法是:list_tools() 用于检查服务器暴露的工具,call_tool() 是整个项目调用的核心,它封装了超时、重试和元数据记录。
2️⃣ 设置核心逻辑 (core.py)
core.py 承载了实际的假设检验逻辑。首先,我们设置导入、API 客户端、限制条件和辅助函数。
import json
import re
import time
import uuid
import asyncio
from datetime import date, timedelta
import numpy as np
import pandas as pd
from openai import OpenAI
from client import EODHDMCP
# 配置参数
eodhd_api_key = "你的 EODHD API KEY"
mcp_base_url = "https://mcp.eodhd.dev/mcp"
openai_api_key = "你的 OpenAI API KEY"
model_name = "gpt-4o" # 或你使用的模型
max_lookback_days = 365
max_tool_calls = 10
max_tickers = 5
mcp = EODHDMCP(eodhd_api_key, base_url=mcp_base_url)
oa = OpenAI(api_key=openai_api_key)
# 辅助函数:日志记录、日期计算、状态管理
def log_event(event, trace_id, **extra):
payload = {"event": event, "trace_id": trace_id, "ts": round(time.time(), 3)}
payload.update(extra)
print(json.dumps(payload, default=str))
def get_dates_from_lookback(days):
end = date.today()
start = end - timedelta(days=int(days))
return start.isoformat(), end.isoformat()
def make_state():
return {"tool_calls": 0, "tool_trace": []}
def bump_tool_call(state, meta):
state["tool_calls"] += 1
state["tool_trace"].append(meta)
if state["tool_calls"] > max_tool_calls:
raise RuntimeError("tool call budget exceeded")
def to_text(out):
# 将 MCP 输出转换为纯文本的工具函数
if isinstance(out, str): return out.strip()
if hasattr(out, "content"):
try:
parts = [item.text if hasattr(item, "text") else str(item) for item in out.content]
return "\n".join(parts).strip()
except: pass
return str(out).strip()
3️⃣ 将提示词解析为结构化请求
用户不会每次都发送格式完美的请求。他们更可能写一段散漫的文字。我们需要将原始提示词转化为四个字段:ticker(代码)、lookback_days(回溯天数)、thesis(假设)和 mode(模式)。
def parse_request(text):
prompt = f"""
你正在为一个金融假设检验助手提取字段。请返回如下格式的 JSON:
{{
"tickers": ["AAPL"],
"lookback_days": 180,
"thesis": "具体的假设陈述",
"mode": "single"
}}
规则:
- 仅提取明确提到的代码。
- 若有多个代码,mode 为 "watchlist";若只有一个,为 "single"。
- 若未提及时间框架,默认使用 180 天。
- 将月转换为 30 天,年转换为 365 天。
- 保持假设陈述简洁且符合原意。
- 仅返回 JSON。
用户请求:
{text}
""".strip()
r = oa.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
)
raw = r.choices[0].message.content.strip()
return json.loads(raw)
随后通过 enforce_limits(parsed) 函数对提取的内容进行清洗和边界控制(如限制最大代码数量和回溯时长),确保工作流的可控性。
4️⃣ 获取数据:历史价格与基本面
一旦请求被解析,下一步就是拉取数据。
async def fetch_prices(ticker, start_date, end_date, trace_id, state):
args = {"ticker": ticker, "start_date": start_date, "end_date": end_date, "period": "d", "order": "a", "fmt": "json"}
out, meta = await mcp.call_tool("get_historical_stock_prices", args, trace_id)
text = to_text(out)
bump_tool_call(state, meta)
df = pd.DataFrame(json.loads(text))
# ... 数据清洗逻辑 ...
return df
async def fetch_fundamentals(ticker, trace_id, state):
args = {"ticker": ticker, "include_financials": False, "fmt": "json"}
out, meta = await mcp.call_tool("get_fundamentals_data", args, trace_id)
text = to_text(out)
bump_tool_call(state, meta)
return json.loads(text)
这些函数通过 MCP 封装,自动继承了超时和重试机制,并通过 bump_tool_call 追踪 API 使用情况。
5️⃣ 构建第一层证据:价格信号
价格历史不仅仅是数字,它是证据层。它能测试关于下行控制、风险、动量和收益质量的断言。
def compute_price_signals(prices_df):
# ... 计算逻辑 ...
# 计算总收益 (ret_total)、年化波动率 (vol_annualized)
# 最大回撤 (max_drawdown)、趋势斜率 (trend_slope)
# 收益波动比 (ret_to_vol)
return signals
关键点:我们不是让模型去从原始价格中瞎猜,而是先用 Python 计算出明确的信号,让后续的推理步骤基于事实而非模糊的解释。
6️⃣ 构建第二层证据:基本面信号
基本面数据让输出不再泛泛而谈。
def compute_fundamental_signals(fundamentals):
# 提取利润率 (ProfitMargin)、营业利润率 (OperatingMargin)
# 资产回报率 (ROA)、净资产收益率 (ROE)
# 营收增长、盈利增长、估值倍数 (P/E)、Beta 等
# 以及分析师的 EPS 修正数据
return signals
这些字段让我们能以非常具体的方式测试业务质量、估值合理性和前瞻性预期。
7️⃣ 假设分类与证据构建
在助手给出判断之前,它需要先理解正在处理哪种类型的主张。我们通过 classify_thesis 将假设分类(如 controlled_downside, business_quality, valuation_attractive 等)。
最后,build_evidence_blocks 函数将这些分类、价格信号和基本面信号结合起来,把它们分装进三个“桶”:支持性证据、矛盾性证据和缺失证据。
8️⃣ 生成最终备忘录
最后一步是将所有结构化的信号和证据交给模型,由它撰写最终的备忘录。由于之前的步骤已经完成了繁重的数据处理和初步分类,模型现在只需专注于叙述性合成。
🏁 总结与启示
通过这个实战,我们构建了一个不仅仅是“会说话的股票摘要”,而是一个能够严谨验证逻辑的 AI 智能体。
其核心思路在于:
- 结构化先行
:不直接让 LLM 处理原始数据,而是先通过 Python 预处理为确定性的信号。 - MCP 协议的威力
:通过标准化的接口,轻松接入高质量的金融数据源。 - 证据驱动
:强制系统寻找“支持”和“反对”的两面性证据,减少 AI 的幻觉和偏见。
笔者锐评
看完这篇文章,我不禁在想,国内的金融 AI 产品大多还停留在“问答机器人”或者“研报摘要”的阶段。正如文中所言,真正的研究是从一个假设(View)开始的。
在中文互联网环境下,我们拥有海量的财经资讯,但缺乏像 MCP 这样标准化的数据交互协议,导致很多 AI 助手在调用实时、深度数据时依然显得捉襟见肘。这篇文章给国内开发者的最大启示是:AI 的价值不在于它能说多少话,而在于它能在多大程度上替代人类进行繁琐的逻辑验证和数据对齐。
未来的金融 AI,不应该只是一个“聊天框”,而应该是一个内置了严谨金融逻辑和实时数据流水线的“思维外挂”。
求点赞 👍 求关注 ❤️ 求收藏 ⭐️你的支持是我更新的最大动力!
