 夜雨聆风
夜雨聆风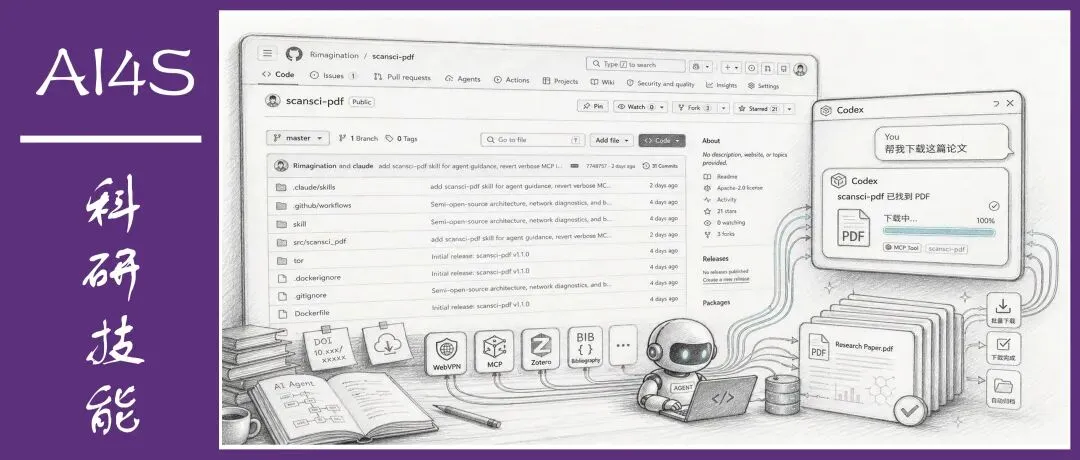
导语
每个科研人都经历过这种时刻。
你刚读完一篇综述,里面有 15 篇论文你想看原文。你点开 DOI 链接跳转网页,点进去猛然发现学校没有订阅。你把 DOI 一个个复制到 Sci-Hub,前 3 篇顺利下载,第 4 篇开始 404。
15 篇论文,搞了一个半小时。
这种事我做过很多遍。每次都想,有没有一种办法,让这个过程自动化?让 AI 帮我下?
今年年初,Openclaw很火。我让小龙虾帮我找一篇论文的 PDF。它很认真地搜了一圈,然后跟我说「抱歉,我无法直接下载付费论文的 PDF 文件」。
很多事情都是这样,你认为它一定能实现,但它耗费大量 tokens 就是做不好。
后来的几个月,我几乎放弃养虾了。直到我刷到一篇小红书的帖子。

可惜,我发现博主采用的EZproxy方法并不适用于我的学校,甚至大陆高校都不适用。我当时就一个想法,我要参考 Github 上所有相关的项目,自己做一个最好用的。
于是就有了 scansci-pdf。
在说怎么用之前,先聊聊 MCP 和 Skill 是什么
MCP,全称 Model Context Protocol,Anthropic 在 2024 年底发布的一个标准协议。你可以把它理解成 AI Agent 的 USB 接口。以前你买个新鼠标,得装个专用驱动,现在 USB 一插,系统自动识别。MCP 干的就是这个事,你给 Agent 装一个 MCP 服务,它就自动多了对应的一批能力,不需要改任何代码。
但光有 MCP 还不够。MCP 提供的是底层工具,就像你有了一堆零件,但还得有人告诉你怎么组装、什么时候用哪个。这就是 Skill 的作用。Skill 是一套智能指令,它告诉 Agent 面对不同场景该怎么编排这些工具。比如你说「帮我下载这篇论文」,Skill 会指导 Agent 先判断你的输入是 DOI 还是 arXiv ID,选哪种下载策略,失败了怎么重试。
scansci-pdf 采用的就是 MCP + Skill 双层架构。MCP 层提供 21 个底层工具,Skill 层负责场景识别、流程编排和错误处理。你跟 Agent 说一句话,Skill 自动把这句话翻译成一连串工具调用,中间出问题还会自动换方案。
你可以把 MCP 想象成厨房里的各种厨具,Skill 就是菜谱。厨具再好,没菜谱也做不出一桌好菜。
scansci-pdf 装上之后,你的 Agent 就有了完整的论文获取能力。底层 21 个 MCP 工具覆盖论文搜索、PDF 下载、引文导出、WebVPN 管理、Tor 匿名访问。上层 Skill 负责理解你的意图,自动选择最佳执行路径。
核心是它的下载逻辑。当你调用下载的时候,scansci-pdf 不是去一个地方找 PDF,它是同时去 13 个地方找。Sci-Hub、Unpaywall、OpenAlex、SemanticScholar、Crossref、DOAJ、EuropePMC、CORE、PMC、LibGen、出版商直链、OA 发现网络,13 个源同时开跑,谁先返回有效 PDF 就用谁的。
就像赛马。你不需要知道哪匹马今天状态好,你只需要让它们一起跑。
安装,一句话的事
你不需要记任何命令。直接跟 Agent 说一句话就行。
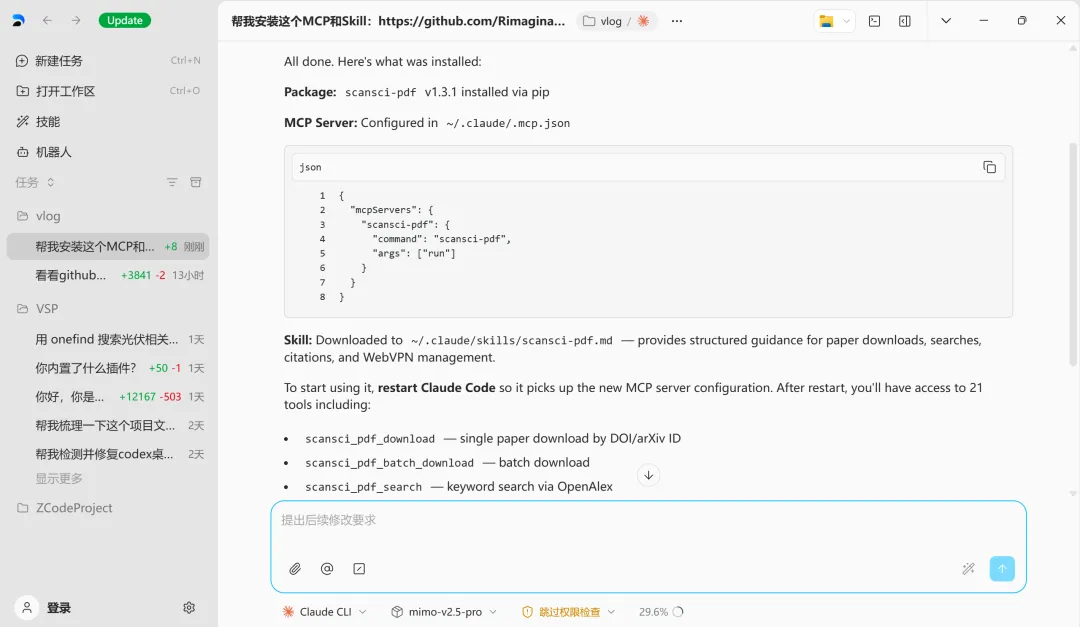
帮我安装这个MCP和Skill:https://github.com/Rimagination/scansci-pdf
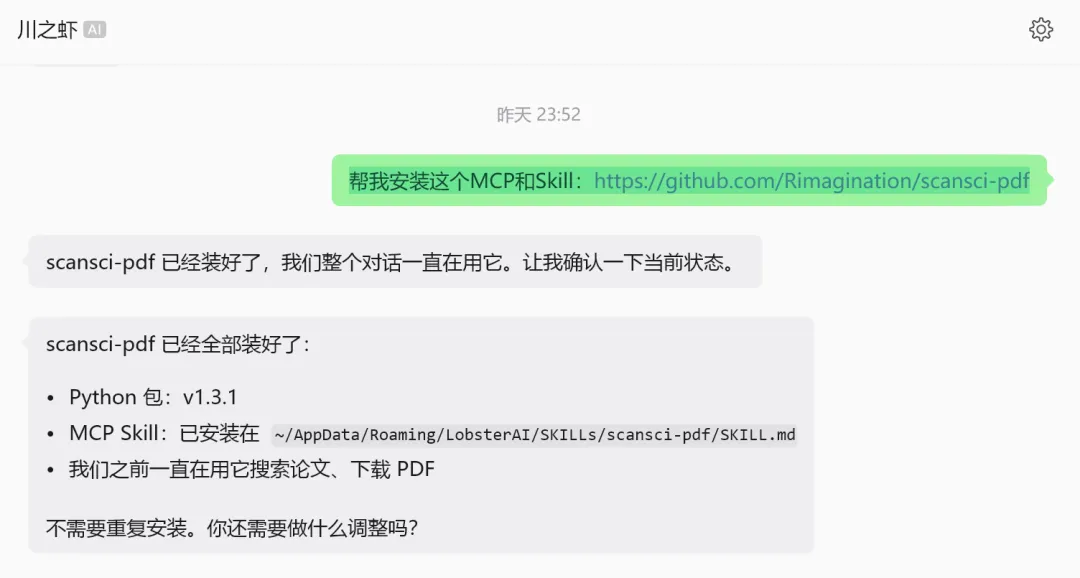
Agent 会自动完成所有事情:检测 Python 版本、pip 安装、环境检查、配置 MCP。装完直接能用。
更新也一样。
更新一下这个MCP和Skill:https://github.com/Rimagination/scansci-pdf
完事。
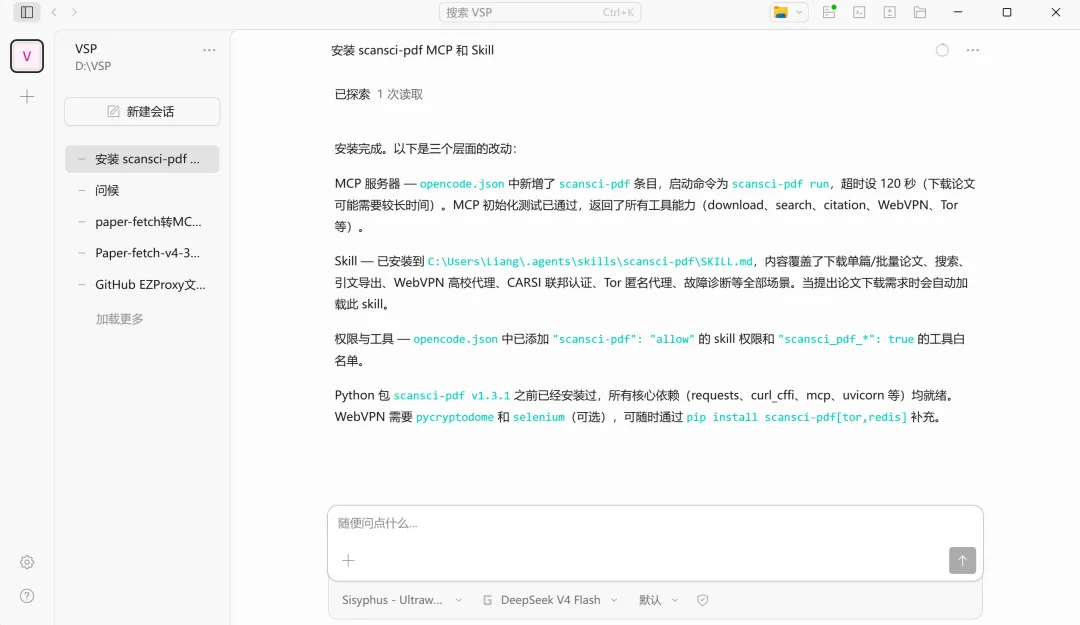
如果你非要手动操作,那就是 pip install -U scansci-pdf,然后在配置文件里加上 MCP 服务器地址。但说实话,没必要。一句话能搞定的事,为什么要记命令?
当然了,codex/claude code/opencode/z code都可以一句话安装。
第一步,下载单篇论文
装好之后,最基础的用法就是下载单篇论文。
你跟 Agent 说「帮我下载这篇论文」,然后丢一个 DOI 过去。
帮我下载 10.1038/nature16489
Agent 会自动调用 scansci_pdf_download 工具,几秒钟后告诉你结果。
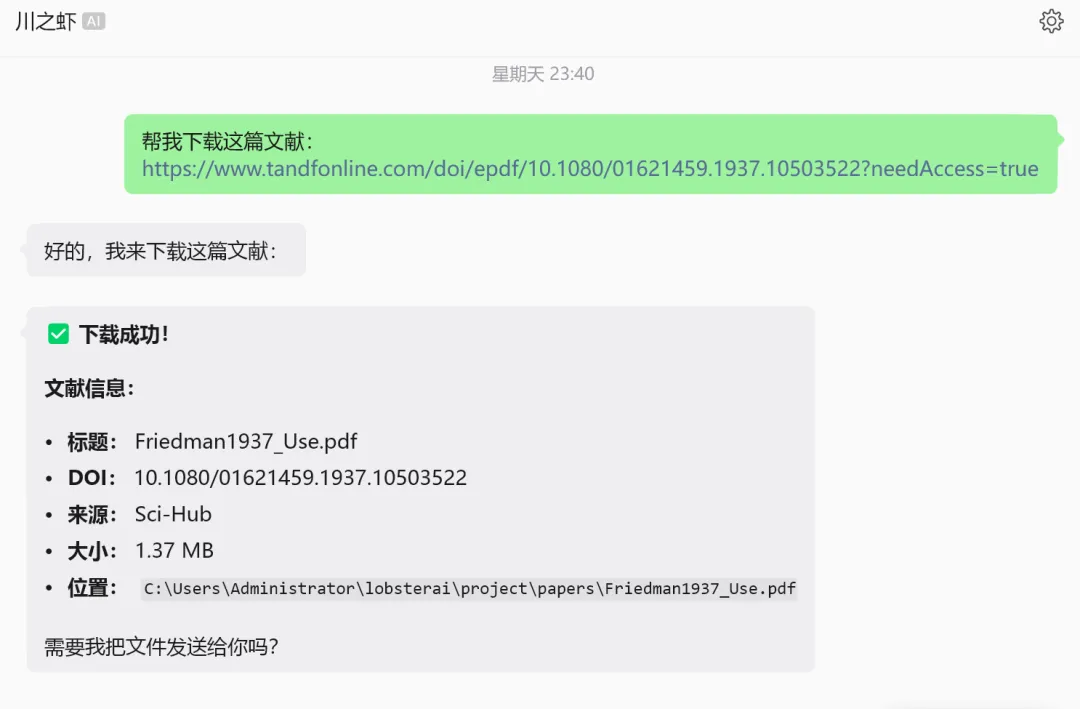
注意那个文件名。它不是给你一个 10.1038_nature16489.pdf 这种机器才看得懂的名字,而是自动重命名成了 Diaz2016_Global.pdf,作者、年份、关键词,一眼就知道是哪篇。
4 种下载策略
scansci-pdf 支持 4 种下载策略,你可以根据场景选择。
fastest 是默认策略,13 个源同时竞赛,谁快用谁。日常用这个就行。
oa_first 是开放获取优先。它会先试 Unpaywall、OpenAlex、DOAJ 这些合法的 OA 源,找不到再试 Sci-Hub。适合你在意版权合规性的时候用。
scihub_only 只用 Sci-Hub 和 LibGen。适合你已经知道这篇论文只有 Sci-Hub 上有的时候。
legal_only 只用合法源。出版商直链、Unpaywall、OA 网络,不碰 Sci-Hub。如果你使用的是codex,它大概率会直接采用这个策略,因为它内置了很多合规性约束。
你可以在跟 Agent 对话的时候指定策略,比如「用 OA 优先策略下载这篇」,Agent 会自动把参数传过去。
第二步,批量下载
这个是我最爽的场景。
你跟 Agent 说:
帮我搜索植物功能性状领域近5年高被引论文,下载前20篇
也可以说:
帮我下载生态学家Ian Wright的被引数TOP前20的论文
Agent 会先调用 scansci_pdf_search 搜索,拿到候选列表展示给你。你确认之后,它调用 scansci_pdf_batch_download,20 篇论文同时开始下载。
默认 10 个并发线程,20 篇论文大概 5 到 10 分钟搞定。
搜索功能支持按年份筛选、按引用量排序。你可以这样组合条件。

搜索 2020 年以后关于 machine learning 的论文,按引用量排序,下载前 10 篇
Agent 会自动把 year_from=2020、sort=cited_by_count、limit=10 这些参数拼好。
断点续传
批量下载的时候如果中途中断了(比如网络断了、Agent 超时了),不用担心。scansci-pdf 会自动保存进度。下次你跟 Agent 说「继续上次的下载」,它会从断点续传,已经下好的不会重复下载。
并发配置
默认 10 个并发线程。如果你网络好、源响应快,可以调高。
帮我把 batch_workers 改成 20
Agent 会调用 scansci_pdf_config_set 修改配置。如果你网络不稳定或者 Sci-Hub 限流,可以调低到 5,避免被封。
第三步,WebVPN 机构代理
有些论文学校有订阅,但必须通过校园网或者 WebVPN 才能访问。scansci-pdf 支持 100 多个中国高校的 WebVPN,包括清华、北大、浙大、上交、复旦、南大、中科大等。
设置流程分 5 步。
第 1 步,启用 WebVPN 并设置学校
帮我设置清华 WebVPN
Agent 调用 scansci_pdf_config_set 启用 WebVPN,然后调用 scansci_pdf_vpnsci_set_school 设置学校为「清华大学」。
第 2 步,登录 CAS 认证
登录 WebVPN
Agent 调用 scansci_pdf_vpnsci_login,会打开浏览器跳转到学校的 CAS 登录页面。你正常输入账号密码登录就行,登录完成后 Agent 自动保存 cookie。
第 3 步,测试连接
测试一下 WebVPN 能不能用
Agent 调用 scansci_pdf_vpnsci_test,用一篇已知的论文测试 WebVPN 通道是否正常。
第 4 步,通过 WebVPN 下载
用 WebVPN 帮我下载 10.1126/science.ady6805
Agent 调用 scansci_pdf_download,参数 use_vpnsci=true,通过学校代理访问出版商。
第 5 步,批量用 WebVPN 下载
用 WebVPN 批量下载这批论文
跟普通批量下载一样,只是 Agent 会自动加上 use_vpnsci=true 参数。
支持的学校列表
你可以跟 Agent 说「帮我查一下支持哪些学校的 WebVPN」,它会调用 scansci_pdf_vpnsci_schools 列出所有支持的高校。也可以搜索特定学校,比如「搜一下有没有浙大」。
WebVPN 的局限
WebVPN 不是万能的。它只能访问学校已经购买了订阅的出版商。如果你的学校没有 Science 的订阅,通过 WebVPN 访问 science.org 还是会 403。另外 WebVPN 的 session 有时效性,过期了需要重新登录。
第四步,故障排查
下载失败是常有的事,scansci-pdf 内置了一套诊断系统。
一键网络诊断
帮我做一下网络诊断
Agent 调用 scansci_pdf_network_diagnose,会自动检测 DNS 解析、代理配置、Tor 状态、FlareSolverr 连通性,然后告诉你哪里出了问题、怎么修。
下载失败的常见原因和解决方案
Sci-Hub 404,论文太新还没收录,解决方案是换 oa_first 策略试试,或者通过 WebVPN 访问出版商直链。
Cloudflare 403,出版商有反爬防护,解决方案是安装 FlareSolverr。FlareSolverr 是一个专门绕过 Cloudflare challenge 的工具,用 Docker 一行命令就能起。
docker run -d -p 8191:8191 ghcr.io/flaresolverr/flaresolverr起了之后,scansci-pdf 会自动检测到并使用。
网络超时,国内访问某些源不稳定,解决方案是配置代理。这个不过多解释。
自适应健康评分
scansci-pdf 会记录每个源的历史成功率和响应时间,自动给每个源打分。失败的源会被降权,成功的源会被优先使用。你可以随时查看评分。
帮我看一下各个下载源的健康状况
Agent 调用 scansci_pdf_source_scores,展示每个源的评分。
进阶技巧
.bib 文件导入
如果你已经有一个 .bib 文件,里面列了几十篇参考文献,可以直接让 Agent 导入并批量下载。
帮我导入这个 bib 文件并下载所有论文
Agent 调用 scansci_pdf_import_bib,自动从 .bib 文件里提取 DOI,然后批量下载。省去了你一个个复制 DOI 的麻烦。
引文导出
下载完论文之后,你可以让 Agent 导出引文格式。
把这篇论文的 BibTeX 给我
Agent 调用 scansci_pdf_citation,返回 BibTeX 格式的引文。直接粘到 LaTeX 或者 Zotero 里就能用。支持 BibTeX、RIS、EndNote 三种格式。
Tor 匿名访问
如果你在某些网络环境下访问 Sci-Hub 被封,可以用 Tor。scansci-pdf 内嵌了 Tor,不需要你单独装 Docker 或者配置 Tor 浏览器。
帮我安装并启动 Tor
Agent 会先调用 scansci_pdf_tor_install 下载 Tor 二进制(大约 30MB),然后调用 scansci_pdf_tor_start 启动 SOCKS5 代理。下载的时候设置 use_tor=true 就走 Tor 通道了。
如果在防火墙严格封锁 Tor 的网络里,可以用桥接模式。
用桥接模式启动 Tor
Agent 调用 scansci_pdf_tor_start(use_bridges=true),启用 obfs4 桥接绕过封锁。
适用范围和局限性
能做什么
scansci-pdf 覆盖了科研工作中论文获取的绝大部分场景。DOI 下载、arXiv 下载、批量搜索下载、机构代理访问、引文导出、Zotero 推送,这些日常高频操作都支持。13 个下载源并行竞赛,100 多个高校 WebVPN,尽量让每一篇论文都能搞到手。
做不到什么
不能保证 100% 成功率。以下几种情况可能会失败。
论文太新。有些论文刚上线几天,Sci-Hub 还没收录,OA 源也还没索引到。这种情况等几天再试通常就好了。
出版商防护太强。Science.org 的 Cloudflare 防护是出了名的严格,即使通过 WebVPN 也可能被 403。目前 Scopus/ScienceDirect 也有类似问题。FlareSolverr 能缓解,但不是所有情况都管用。
网络环境太差。在某些防火墙严格的网络里,Sci-Hub 域名被 DNS 污染,Tor 被封锁,WebVPN 不可用。这时候需要配置代理,或者用 Tor 桥接模式。
学校没买某些出版商的订阅。WebVPN 只是个代理通道,它不能凭空变出学校没有的订阅。如果你的学校没有 Nature 的订阅,通过 WebVPN 访问 nature.com 还是会 403。
跟同类工具的区别
GitHub 上有不少论文下载工具,比如 scidownl、paper-dl、arxiv-dl、scholarpy 等。它们各有侧重,但大多数基于单一数据源,要么只走 Sci-Hub,要么只走 Unpaywall,源挂了就没办法了。
scansci-pdf 的核心差异在三个地方。
第一,多源并行竞赛。不依赖任何一个单独的源。Sci-Hub 挂了,Unpaywall 接上;Unpaywall 没有,LibGen 补上。13 个源互相备份。
第二,Agent 原生。不是命令行工具加了个 wrapper,而是从设计之初就面向 AI Agent。采用 MCP + Skill 双层架构,底层 21 个 MCP 工具覆盖搜索、下载、管理、诊断全流程,上层 Skill 负责场景识别和流程编排。你跟 Agent 说话就行,不需要记任何命令。
第三,机构代理集成。把 WebVPN 做成了内置功能,而不是让你自己去拼 URL、手动过认证。100 多个高校一键配置,CAS 登录自动保存 cookie。
关于 scansci
scansci-pdf 是 scansci 科研工具品牌的一部分。我们在做的事很简单,用 AI 降低科研工具的使用门槛。
论文下载只是第一步。我们的目标是让科研工作流里的每一个重复性操作都能被一句话搞定。
欢迎访问我们的官网:https://www.scansci.com
总结
scansci-pdf 的核心价值不是「又一个下载工具」,而是它通过 MCP + Skill 双层架构,把论文下载这件事变成了 Agent 的原生能力。MCP 提供 21 个底层工具,Skill 负责智能编排,以前你得手动操作的事,现在一句话搞定。
免责声明:本文仅用于介绍科研工具的技术实现与使用方式,请读者在下载和使用论文时遵守所在地区法律法规、出版方版权政策及机构授权协议。禁止将本文提到的工具用于商业用途,否则后果自负。
参考链接
- scansci-pdf项目: https://github.com/Rimagination/scansci-pdf
- scansci官网: https://www.scansci.com
