 夜雨聆风
夜雨聆风调研日期: 2026年5月7日
调研范围: 2023-2025年最新论文与开源项目
应用场景: BMS电池管理系统(SOC估计、滞回建模、静置电压预测)
一、评估标准(Rubric)
在筛选和评估模型时,采用以下五个维度:
1. 模型轻量化程度
- 优秀: 参数量<1M,FLOPs<100M,支持INT8量化,可在STM32/ESP32等边缘设备运行
- 较差: 参数量>10M,需要GPU/NPU支持,仅能在服务器或高端边缘设备运行
2. 时序建模能力
- 优秀: 能有效捕捉长程依赖(>1000时间步),支持多变量输入,对非平稳信号鲁棒
- 较差: 仅支持短序列,无法处理多变量时序,对噪声敏感
3. BMS任务适配性
- 优秀: 有BMS领域应用案例,支持电流/电压/温度多模态输入,能建模电池非线性动态特性
- 较差: 无相关应用,输入输出格式不匹配电池数据特点
4. 创新性与影响力
- 优秀: 2023-2025年发表,高引用/Star数,提出新的建模范式或机制
- 较差: 传统架构简单改进,无显著创新点,关注度低
5. 开源与可复现性
- 优秀: 完整开源代码,提供预训练模型,有详细文档和示例,社区活跃
- 较差: 仅论文无代码,或代码不完整,无法直接复现
二、重点模型架构调研
2.1 状态空间模型(State Space Models)
2.1.1 Mamba / Mamba-2
论文:
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2023)
- Mamba-2: State Space Duality (ICML 2024)
核心创新:
- 选择性状态空间(Selective SSM): 传统SSM对所有输入一视同仁,Mamba引入选择机制,让模型能关注或忽略特定输入,类似Transformer的注意力但计算复杂度为O(L)而非O(L²)
- 硬件感知算法: 采用FlashAttention类似的内存优化策略,通过并行扫描(parallel scan)算法实现高效训练
- Mamba-2改进: 速度提升2-8倍,引入状态空间对偶性(SSD)理论框架,统一了SSM和注意力机制
架构特点:
输入 → 线性投影 → 选择性SSM层 × N → 输出
↓
扩张卷积(d=4)
核心架构图(来源:论文原文):
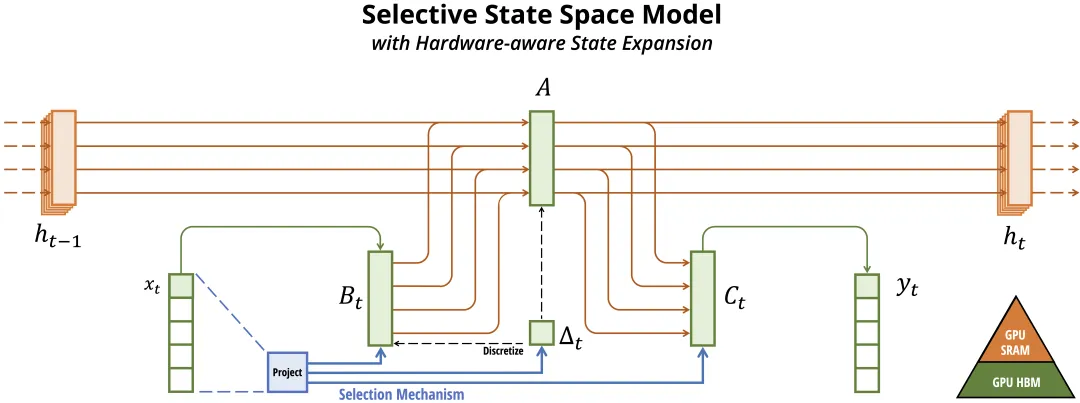 图:Mamba选择性状态空间模型架构(来源:arXiv:2312.00752)
图:Mamba选择性状态空间模型架构(来源:arXiv:2312.00752)
架构详解:
Mamba的核心是选择性状态空间模型(Selective SSM),灵感来源于连续时间状态空间模型(如S4)。其数据流如下:
- 输入投影:将输入
xt ∈ Rd通过线性层映射到隐空间 - 选择性参数化:根据输入动态生成SSM参数
(Bt, Ct, Δt),而非使用固定参数——这是"选择性"的含义 - 离散化:将连续时间的SSM参数通过零阶保持(ZOH)离散化为递推关系
- 状态更新:
ht = Āt h- + B̄t xt,其中Āt, B̄t由离散化得到 - 输出投影:
yt = Ct ht,再通过线性层映射回输出空间
输入输出说明:
- 输入:
[Batch, SeqLen, Dim]— 任意长度的时间序列,支持多变量 - 输出:
[Batch, SeqLen, Dim]— 同形状的输出(序列到序列)或[Batch, PredLen](序列到标量/向量) - BMS场景:输入
[Batch, T, 3](电压、电流、温度),输出[Batch, 1](SOC值)
参数量计算:
- 单层Mamba:
P(aye) = 2d × dx + dx × d + dSd:模型维度(如256),dx:扩展维度(如2d),dS:SSM状态维度(如16-64)
- 典型配置(
d=256, N=12层):约 1.3M 参数 - 最小配置(
d=64, N=4层):约 50K 参数
计算复杂度与资源估算:
| 配置 | 参数量 | FLOPs/Token | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|
| d=64, N=4 | ~50K | ~0.1M | ~200KB | ~50KB | STM32F4 |
| d=128, N=6 | ~300K | ~0.5M | ~1.2MB | ~300KB | STM32H7 |
| d=256, N=12 | ~1.3M | ~2M | ~5.2MB | ~1.3MB | i.MX RT |
- 训练复杂度:
O(N × L × d2)(并行扫描实现) - 推理复杂度:
O(N × d2)每步(RNN模式,与序列长度无关) - 推理内存:
O(N × dS × d)— 仅需存储隐状态,与序列长度无关
嵌入式部署分析:
- ✅ 线性复杂度O(L),长序列友好
- ✅ 参数量可控(基础版约1-3M参数)
- ✅ 推理时可用RNN模式,内存恒定
- ⚠️ 需要自定义CUDA核或优化实现才能发挥性能
- ⚠️ 选择性机制增加计算分支,对MCU不友好
BMS适用性: ★★★★☆
- 适合捕捉电池长期依赖(如充放电循环间的记忆效应)
- 选择机制可学习关注关键状态变化点
开源情况:
- GitHub: https://github.com/state-spaces/mamba
- Stars: 15k+
- 许可证:Apache 2.0
2.1.2 MambaTS(时序专用版本)
创新点: 针对时间序列预测任务优化的Mamba变体
改进:
- 引入时间感知的选择机制
- 多尺度状态空间设计
- 通道混合策略优化
2.2 Transformer变体
2.2.1 iTransformer(ICLR 2024 Spotlight)
论文: iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
核心创新:
- 倒置Transformer架构: 传统Transformer将时间步作为token,变量作为特征;iTransformer将其倒置——将变量作为token,时间步作为特征维度
- 动机: 时序数据中,变量间关系(多变量相关性)比时间步间关系更重要且更稳定
架构对比:
| 传统Transformer | iTransformer |
|---|---|
| 输入: [B,T,V] | 输入: [B,V,T] (倒置!) |
| Time embedding | Var embedding |
| Self-attention (on time dim) | Self-attention (on var dim) |
| 复杂度O(T²) | 复杂度O(V²), V<<T |
核心架构图(来源:论文原文):
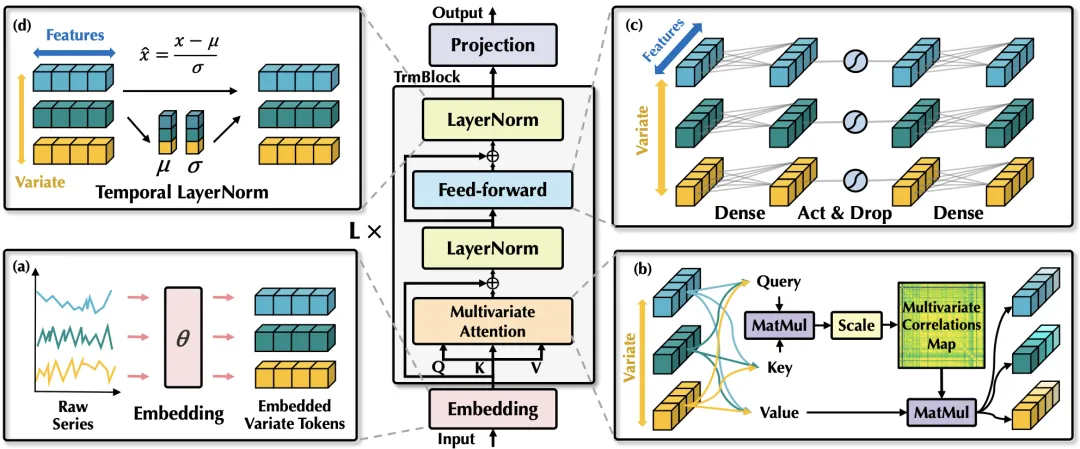 图:iTransformer倒置架构与传统Transformer对比(来源:arXiv:2310.06625, ICLR 2024 Spotlight)
图:iTransformer倒置架构与传统Transformer对比(来源:arXiv:2310.06625, ICLR 2024 Spotlight)
架构详解:
iTransformer的核心思想是"倒置"——将变量(通道)作为token,而非时间步。具体流程:
- 变量Token化:将输入
[B, T, V]转置为[B, V, T],每个变量(如电压、电流、温度)成为一个token,其特征维度为序列长度T - 变量嵌入:对每个变量token通过线性层映射到模型维度
d(ode) - 自注意力:在V个变量之间做注意力计算(V=3时仅需计算3×3的注意力矩阵)
- 前馈网络:对每个变量独立做FFN(包含expand→GELU→shrink)
- 重复N层后,通过线性头映射到预测空间
输入输出说明:
- 输入:
[Batch, LookbackLen, Vars]— 回看窗口长度×变量数 - 输出:
[Batch, PredLen, Vars]— 预测长度×变量数(支持多变量同时预测) - BMS场景:输入
[B, 512, 3](512步历史,3变量),输出[B, 1, 1](SOC值)或[B, 96, 3](多步多变量预测)
参数量计算:
- 单层参数:
P(aye) = 4d2(注意力QKV投影3d2+ 输出投影d2)+8d2(FFN,expand_ratio=4)=12d2 - 注意力部分复杂度:
O(V2 × d),当V=3时几乎可忽略 - 典型配置(
d=512, N=3层):约 9.4M 参数 - 轻量配置(
d=128, N=2层):约 0.4M 参数 - 最小配置(
d=64, N=2层):约 0.1M 参数
计算复杂度与资源估算:
| 配置 | 参数量 | FLOPs/样本 | 注意力开销 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|---|
| d=64, N=2 | ~100K | ~1.6M | V²×d=576 | ~400KB | ~100KB | STM32H7 |
| d=128, N=2 | ~400K | ~6.4M | V²×d=2.3K | ~1.6MB | ~400KB | ESP32-S3 |
| d=256, N=3 | ~2.4M | ~57.6M | V²×d=9.2K | ~9.6MB | ~2.4MB | i.MX RT |
- 关键优势:注意力复杂度为
O(V2 × d)而非O(T2 × d),当V=3时注意力计算几乎为零开销 - 推理内存:
O(N × V × d)— 与序列长度T无关
嵌入式部署分析:
- ✅ 注意力复杂度从O(T²)降到O(V²),V通常很小(电池数据:电压/电流/温度=3)
- ✅ 可利用标准Transformer优化方案(FlashAttention等)
- ✅ 模型结构简洁,易于量化
- ⚠️ 对极长序列仍需优化
BMS适用性: ★★★★★
- 完美匹配电池多变量输入(电压、电流、温度)
- 变量间注意力可学习电池内部电化学耦合关系
- 已有成功应用于电池SOC估计的研究
开源情况:
- GitHub: https://github.com/thuml/iTransformer
- Stars: 5k+
- 集成于Time-Series-Library
2.2.2 PatchTST(ICLR 2023)
论文: A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
核心创新:
- Patching机制: 将时间序列分割成patches(类似ViT的图像patch),每个patch作为Transformer的一个token
- 通道独立(Channel Independence): 每个变量独立处理,通过共享参数降低参数量
架构:
输入序列: [Batch, Vars, Time]
↓
Patching: 每个变量分割为N个patch
↓
Patch embedding + positional encoding
↓
Transformer Encoder × L
↓
Flatten + Linear → 预测输出
核心架构图(来源:论文原文):
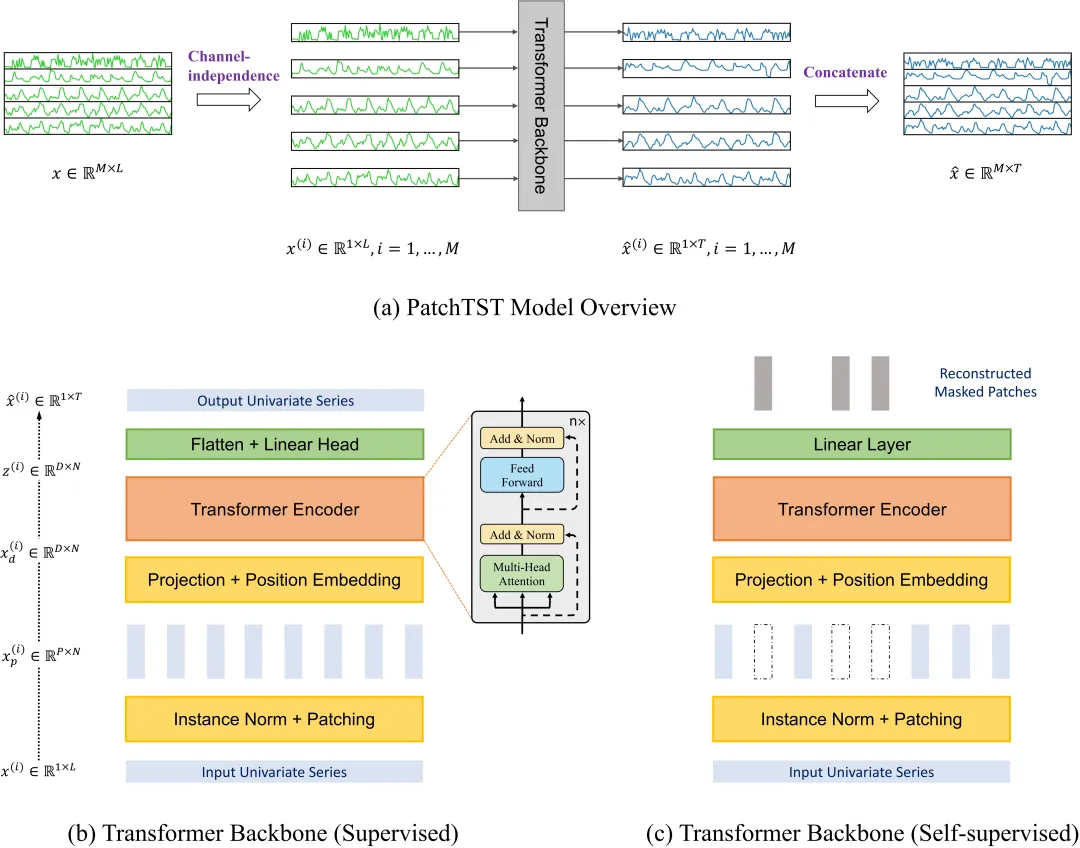 图:PatchTST的Patching机制与通道独立设计(来源:arXiv:2211.14730, ICLR 2023)
图:PatchTST的Patching机制与通道独立设计(来源:arXiv:2211.14730, ICLR 2023)
架构详解:
PatchTST借鉴了Vision Transformer(ViT)的patch思想,将其应用于时间序列:
- 通道独立:将多变量输入拆分为V个独立的单变量序列,每个变量共享同一套模型参数
- Patching:将长度为T的序列分割为若干个不重叠的patch,每个patch长度为P,步长为S(通常S=P)
- 序列长度T被分割为
N(atche) = ⌊ T/P ⌋个patch - 每个patch通过线性层映射为
d(ode)维的token embedding
- 序列长度T被分割为
- 位置编码:为每个patch添加可学习的位置编码
- Transformer编码器:标准的多头自注意力 + FFN,在
N(atche)个token上做注意力 - 预测头:Flatten所有token → 线性层 → 预测输出
输入输出说明:
- 输入:
[Batch, Vars, SeqLen]— 变量数×序列长度 - 输出:
[Batch, Vars, PredLen]— 每个变量独立预测 - BMS场景:输入
[B, 3, 512],patch_size=16 → 32个token → 输出[B, 3, 96]
参数量计算:
- Patch embedding:
P × d(ode)(每个patch线性映射) - 单层Transformer:
12d2(同标准Transformer) - 注意力复杂度:
O(N(atche)2 × d)— patching将序列长度从T降到T/P - 典型配置(
d=128, N=3, P=16, T=512):32个token,约 0.6M 参数 - 轻量配置(
d=64, N=2, P=16, T=512):32个token,约 100K 参数
计算复杂度与资源估算:
| 配置 | 参数量 | Token数 | FLOPs/样本 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|---|
| d=64, N=2, P=16 | ~100K | 32 | ~2M | ~400KB | ~100KB | STM32H7 |
| d=128, N=3, P=16 | ~600K | 32 | ~12M | ~2.4MB | ~600KB | ESP32-S3 |
| d=256, N=3, P=32 | ~2.4M | 16 | ~48M | ~9.6MB | ~2.4MB | i.MX RT |
- 关键优势:Patching使注意力从
O(T2)降到O((T/P)2),P=16时降低256倍 - 通道独立:参数不随变量数V增长,V=3和V=100参数量相同
嵌入式部署分析:
- ✅ 通道独立大幅降低参数量
- ✅ Patching减少序列长度,降低注意力开销
- ✅ 结构简单,易于部署
- ⚠️ 需要选择合适的patch size
BMS适用性: ★★★★☆
- Patching适合电池数据的周期性特征
- 通道独立可能损失变量间耦合信息
2.2.3 TimesNet(ICLR 2023)
论文: TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
核心创新:
- 时间二维变分建模: 将1D时间序列转换为2D张量,同时捕捉周期内(intraperiod)和周期间(interperiod)变化
- 多周期分解: 使用FFT分析找到主要周期,对每个周期分别建模
架构:
输入序列
↓
快速傅里叶变换(FFT) → 识别主要周期
↓
将1D序列reshape为2D: [周期数, 周期长度]
↓
2D卷积(inception block)
↓
Flatten + 融合多周期信息
↓
输出
核心架构图(来源:论文原文):
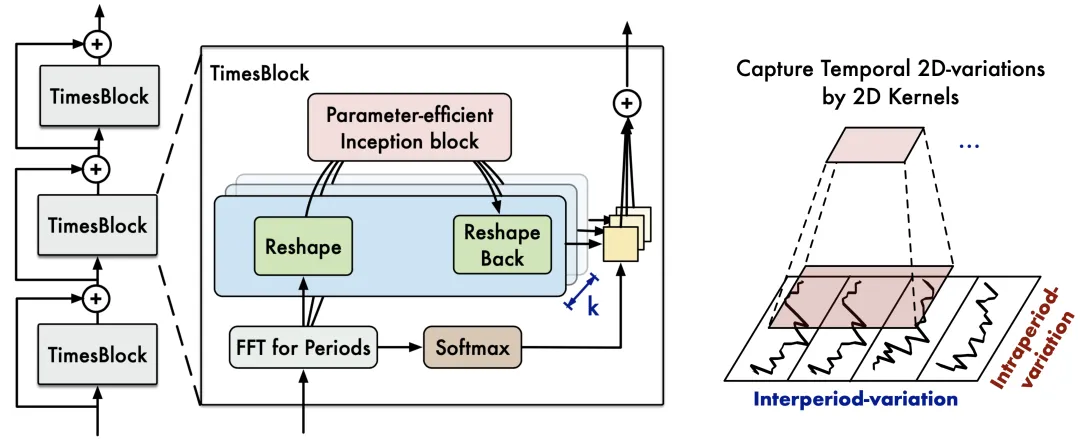 图:TimesNet的TimesBlock——1D时序到2D张量变换与Inception卷积(来源:论文原文 ICLR 2023)
图:TimesNet的TimesBlock——1D时序到2D张量变换与Inception卷积(来源:论文原文 ICLR 2023)
架构详解:
TimesNet的核心创新是将1D时间序列转换为2D张量,利用2D卷积同时捕捉时序的周期内和周期间变化:
- FFT周期提取:对输入序列做快速傅里叶变换,选取振幅最大的
k个频率分量,对应k个周期p1, p2, ..., pk - 1D→2D变换:对每个周期
pi,将长度为T的1D序列reshape为2D张量[T/p_i, p_i]- 行维度:周期重复次数(周期间变化)
- 列维度:单个周期内的变化(周期内变化)
- Inception 2D卷积:对每个2D张量使用多尺度2D卷积(kernel 1×k, 3×3, 5×5, 7×7)提取特征
- 2D→1D还原:将2D特征图Flatten回1D
- 自适应聚合:对
k个周期的特征通过平均池化或注意力加权融合 - 堆叠N个TimesBlock + 最终预测头
输入输出说明:
- 输入:
[Batch, SeqLen, Vars]— 序列长度×变量数 - 输出:
[Batch, PredLen, Vars]— 预测长度×变量数 - BMS场景:输入
[B, 512, 3],FFT提取top-3周期 → 3路并行2D卷积 → 输出[B, 96, 3]
参数量计算:
- 单层TimesBlock:Inception模块参数约
Cu × (C() × (1+9+25+49))(四种kernel) - 典型配置(
d=64, N=3, k=3):约 0.3M 参数 - 轻量配置(
d=32, N=2, k=1):约 30K 参数
计算复杂度与资源估算:
| 配置 | 参数量 | FFT开销 | FLOPs/样本 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|---|
| d=32, N=2, k=1 | ~30K | O(TlogT) | ~0.5M | ~120KB | ~30KB | STM32F4 |
| d=64, N=3, k=3 | ~300K | O(TlogT) | ~5M | ~1.2MB | ~300KB | STM32H7 |
| d=128, N=3, k=3 | ~1.2M | O(TlogT) | ~20M | ~4.8MB | ~1.2MB | ESP32-S3 |
- FFT开销:
O(T log T),T=512时约4600次复数乘法,对MCU有一定负担 - 2D卷积:可利用CMSIS-NN的2D卷积优化,硬件友好
- 多周期并行:k个周期可串行处理以节省内存,或并行处理以提升速度
嵌入式部署分析:
- ✅ 基于CNN,推理效率高
- ✅ 2D卷积可利用现有优化库(CMSIS-NN)
- ⚠️ FFT运算增加计算开销
- ⚠️ 多周期处理增加内存占用
BMS适用性: ★★★☆☆
- 适合有明显周期性的电池使用场景
- FFT对嵌入式设备有一定挑战
2.3 CNN-based模型
2.3.1 ModernTCN(2024)
核心创新:
- 纯CNN架构,但引入现代设计(大核卷积、门控机制、残差连接)
- 匹配或超越Transformer性能,但计算效率更高
架构特点:
- 大核因果卷积(kernel size=7-31)
- 门控时间卷积单元
- 通道混合MLP
核心架构图(来源:论文原文):
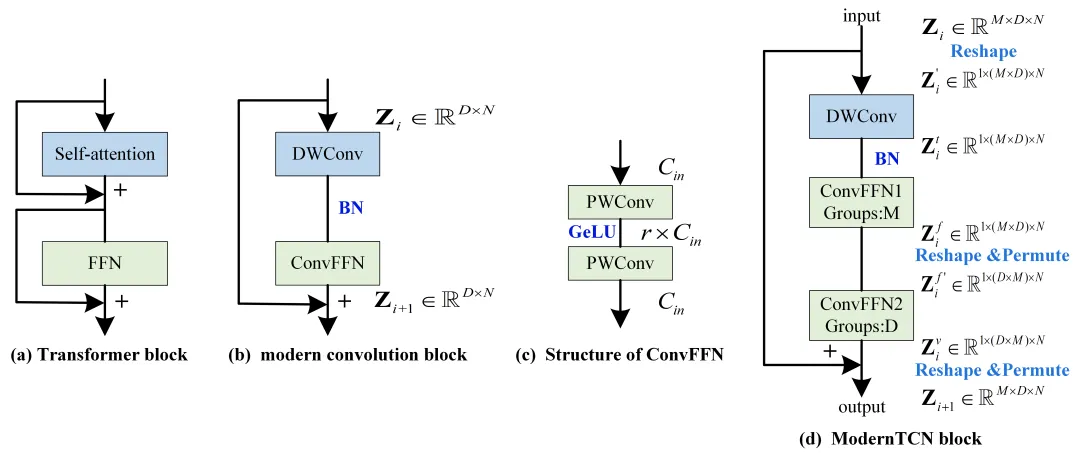 图:ModernTCN Block设计——大核因果卷积+门控激活(来源:ICLR 2024)
图:ModernTCN Block设计——大核因果卷积+门控激活(来源:ICLR 2024)
架构详解:
ModernTCN证明了纯CNN架构可以在时序预测中匹配甚至超越Transformer,其核心设计:
- 大核因果深度可分离卷积:
- 使用深度可分离卷积(Depthwise Separable Conv)降低参数量
- 因果卷积确保不泄露未来信息(padding只在左侧)
- 大核(kernel=7~31)扩大感受野,替代深层堆叠
- 通过"大核分解"(large-kernel decomposition)将大核拆为多个小核的级联,保持效率
- 门控激活:
- 将卷积输出分为两路:一路经过激活函数(GELU/SiLU),一路不经过
- 通过Sigmoid门控:
out = σ(Wg * x) ⊙ GELU(Wf * x) - 类似LSTM门的机制,但纯卷积实现,无循环依赖
- 通道混合MLP:expand→GELU→shrink,跨通道信息交互
- 残差连接:每个Block的输入直接加到输出上
输入输出说明:
- 输入:
[Batch, SeqLen, Vars]— 序列长度×变量数 - 输出:
[Batch, PredLen, Vars]— 预测长度×变量数 - BMS场景:输入
[B, 512, 3],输出[B, 1, 1](SOC)或[B, 96, 3](多变量预测)
参数量计算:
- • 单层ModernTCN Block: - 深度可分离大核卷积:
C() × K + C() × Cu(K为kernel size) - • 单层ModernTCN Block: - 门控线性层:
C() × Cu - • 单层ModernTCN Block: - 通道混合MLP:
C × 4C + 4C × C = 8C2 - 典型配置(
d=64, N=4, K=21):约 0.5M 参数 - 轻量配置(
d=32, N=3, K=7):约 60K 参数
计算复杂度与资源估算:
| 配置 | 参数量 | FLOPs/样本 | 感受野 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|---|
| d=32, N=3, K=7 | ~60K | ~1M | 21 | ~240KB | ~60KB | STM32F4 |
| d=64, N=4, K=21 | ~500K | ~8M | 85 | ~2MB | ~500KB | STM32H7 |
| d=128, N=4, K=31 | ~2M | ~32M | 125 | ~8MB | ~2MB | ESP32-S3 |
- 纯卷积优势:无注意力机制,推理延迟确定性,适合实时系统
- 深度可分离卷积:参数量和计算量均为标准卷积的
1/C()分之一 - 量化友好:卷积层INT8量化损失极小(<0.5%精度下降)
嵌入式部署分析:
- ✅ 纯CNN,推理速度快
- ✅ 无注意力机制,内存占用低
- ✅ 支持并行计算
- ✅ 易于量化和部署
BMS适用性: ★★★★☆
- 适合实时性要求高的BMS应用
2.3.2 DLinear / NLinear(AAAI 2023)
论文: Are Transformers Effective for Time Series Forecasting?
核心发现:
- 简单的线性模型(单层线性层)在很多时序任务上优于复杂Transformer
- 质疑复杂架构的必要性
架构:
DLinear: 分解趋势+季节性的两个线性层
NLinear: 归一化 + 单层线性
核心架构图(来源:论文原文):
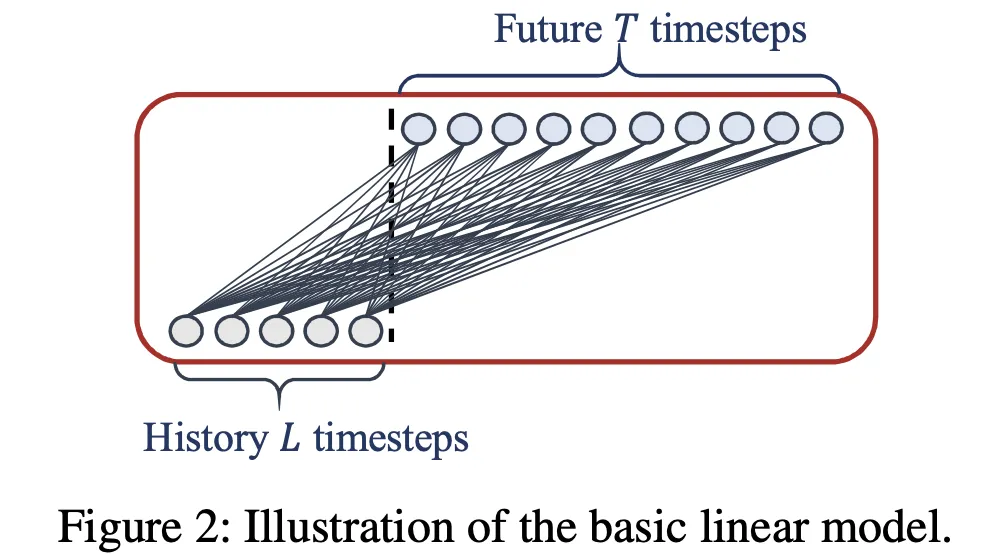 图:LTSF-Linear家族架构——DLinear与NLinear(来源:arXiv:2205.13504, AAAI 2023)
图:LTSF-Linear家族架构——DLinear与NLinear(来源:arXiv:2205.13504, AAAI 2023)
架构详解:
DLinear的极简设计是其最大特点,论文发现简单线性层在很多时序基准上超越了复杂Transformer:
- 移动平均分解:将输入序列分解为趋势(Trend)和季节性(Seasonal)两部分
- 趋势分量:通过平均池化(kernel=k)得到平滑的低频趋势
- 季节性分量:原序列减去趋势分量,得到高频残差
- 双路线性映射:
- 趋势路径:
Linear(T, P)— 将长度为T的趋势映射为长度为P的预测趋势 - 季节性路径:
Linear(T, P)— 将长度为T的季节性映射为长度为P的预测季节性
- 趋势路径:
- 相加输出:两路预测直接相加得到最终预测
NLinear变体更简单:先对输入做LayerNorm,再过一个Linear(T, P),无分解步骤。
输入输出说明:
- 输入:
[Batch, SeqLen, Vars]— 序列长度×变量数 - 输出:
[Batch, PredLen, Vars]— 预测长度×变量数 - BMS场景:输入
[B, 512, 3],输出[B, 96, 3](直接端到端映射)
参数量计算:
- DLinear:
P(ota) = 2 × V × T × P(两个线性层,每个V × T × P)V=3,T=512,P=96 时:2 × 3 × 512 × 96 =295K 参数V=3,T=96,P=24 时:2 × 3 × 96 × 24 =13.8K 参数
- NLinear:
P(ota) = V × T × P(仅一个线性层) - 注意:参数量与序列长度T和预测长度P线性相关,T越大参数越多
计算复杂度与资源估算:
| 配置 | 参数量 | FLOPs/样本 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|
| T=96, P=24, V=3 | ~14K | ~0.1M | ~56KB | ~14KB | STM32F4 |
| T=512, P=96, V=3 | ~295K | ~1.5M | ~1.2MB | ~295KB | STM32H7 |
| T=512, P=96, V=7 | ~689K | ~3.5M | ~2.8MB | ~689KB | ESP32-S3 |
- 极致轻量:无非线性激活函数,纯矩阵乘法
- 推理速度:单次矩阵乘法,微秒级延迟
- 局限性:线性模型无法捕捉非线性动态,对复杂BMS场景可能不足
嵌入式部署分析:
- ✅ 极简架构,参数量极小(<100K)
- ✅ 推理速度极快
- ✅ 内存占用极低
- ⚠️ 表达能力有限,复杂任务可能不足
BMS适用性: ★★★☆☆
- 可作为轻量级baseline或与其他模型结合
2.4 新兴架构
2.4.1 KAN(Kolmogorov-Arnold Networks)
论文: KAN: Kolmogorov-Arnold Networks (2024)
核心创新:
- 基于Kolmogorov-Arnold表示定理
- 用可学习的单变量函数替代MLP的固定激活函数
- 网络边上有可学习的非线性函数(B-spline),节点上是简单求和
架构对比:
| MLP | KAN |
|---|---|
| 激活函数在节点内(固定) | 激活函数在边上(可学习B-spline) |
| 参数量: O(n²) | 参数量: O(n)×网格点数(更少) |
核心架构图(来源:论文原文):
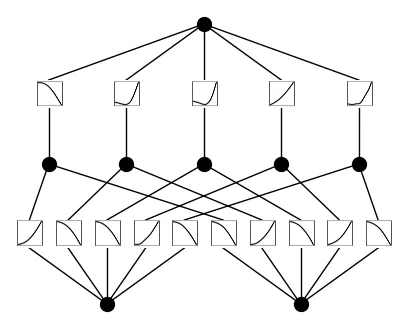 图:KAN与MLP架构对比——边上的可学习函数替代节点中的固定激活(来源:论文原文 arXiv:2404.19756)
图:KAN与MLP架构对比——边上的可学习函数替代节点中的固定激活(来源:论文原文 arXiv:2404.19756)
架构详解:
KAN基于Kolmogorov-Arnold表示定理:任何多元连续函数都可以表示为单变量函数的复合。与传统MLP的根本区别在于:
- MLP模式:节点(神经元)内有固定的激活函数(ReLU、GELU等),边上有固定的权重
- 计算:
y = W2 · σ(W1 · x)
- 计算:
- KAN模式:节点上只有简单的求和运算(Σ),边上有可学习的单变量函数
φ(x)- 计算:
y = Σj φ,(Σi φ(,i,)(xi))
- 计算:
- 边的可学习函数:使用B-spline(B样条)参数化,每个函数由一组控制点定义
φ(x) = spline(x) + SiLU(w · x + b)(样条 + 残差线性项)- 网格点数G控制精度,通常G=5
输入输出说明:
- 输入:
[Batch, InputDim]— 任意维度特征向量(非时序原生,需先做特征提取) - 输出:
[Batch, OutputDim]— 任意维度输出 - BMS场景:需先用TCN/LSTM提取时序特征,再接KAN做最终回归。输入为提取后的特征向量
[B, d],输出[B, 1](SOC值)
参数量计算:
- 单层KAN(输入维度
n(),输出维度nu,网格点数G):P(aye) = n() × nu × (G + 2)(每个边一个B-spline + 残差项)
- 2层KAN(
n()=3, n(idde)=8, nu=1, G=5):P = 3 × 8 × 7 + 8 × 1 × 7 =224 参数
- 对比同规模MLP(
3 × 8 + 8 × 1 =32 参数,但表达能力弱于KAN)
计算复杂度与资源估算:
| 配置 | 参数量 | B-spline求值次数 | 内存(FP32) | 嵌入式挑战 |
|---|---|---|---|---|
| 3→8→1, G=5 | ~224 | ~224 | ~1KB | B-spline查表 |
| 3→16→8→1, G=5 | ~1.4K | ~1.4K | ~6KB | 中等 |
| 3→32→16→1, G=8 | ~6.7K | ~6.7K | ~27KB | 较高 |
- B-spline计算:每个边的函数求值需要
O(G)次基函数计算,无法用标准矩阵乘法加速 - 嵌入式适配:可将B-spline预计算为查找表(LUT),用插值代替实时计算
- 当前状态:工具链不成熟,无TFLite/ONNX原生支持,需自定义算子
嵌入式部署分析:
- ⚠️ 新兴架构,部署工具链不成熟
- ⚠️ B-spline计算对嵌入式设备挑战较大
- ✅ 理论上更少的参数达到同等表达能力
BMS适用性: ★★☆☆☆
- 理论上有潜力,但工程化尚早
2.4.2 RWKV / FRWKV
核心创新:
- 结合RNN和Transformer优点
- 线性注意力机制,O(1)推理内存
- 支持并行训练
FRWKV(时序版本):
- 频域线性注意力
- 适合长期时间序列预测
嵌入式部署分析:
- ✅ 线性复杂度
- ✅ 恒定推理内存
- ✅ 已有嵌入式部署案例
核心架构图(来源:论文原文):
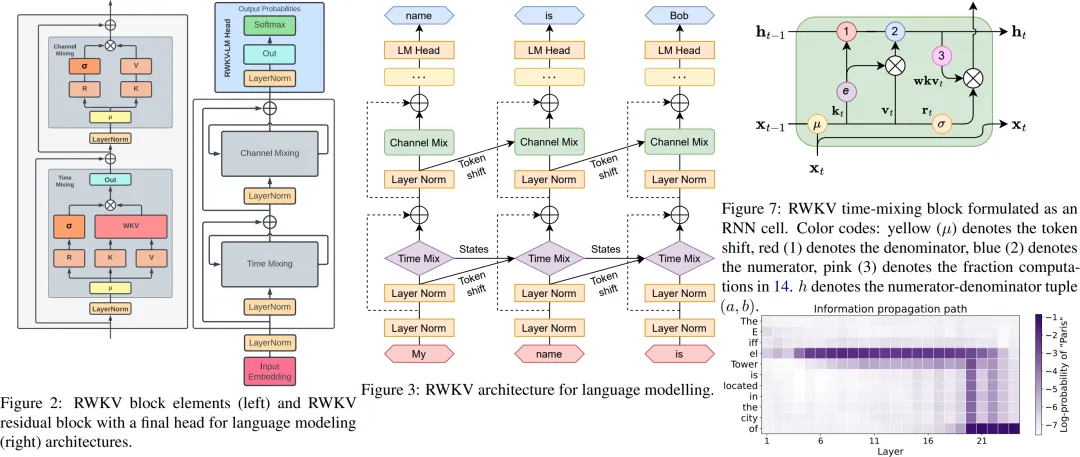 图:RWKV线性注意力机制与Multi-Head Attention对比(来源:论文原文 arXiv:2305.13048)
图:RWKV线性注意力机制与Multi-Head Attention对比(来源:论文原文 arXiv:2305.13048)
架构详解:
RWKV(Receptance Weighted Key Value)是一种将RNN和Transformer统一的架构,训练时并行,推理时串行且内存恒定:
- Time-mixing(时间混合)层:
- 对输入token做时间维度的混合(类似自注意力,但用线性递推替代)
- • 包含三个门控分量: - R(Receptance):接收门,控制当前token接受多少新信息 vs 保留多少历史信息。
rt = σ(Wr · xt) - • 包含三个门控分量: - K(Key):键向量,与衰减系数结合形成注意力权重。
kt = Wk · xt - • 包含三个门控分量: - V(Value):值向量,被加权聚合后输出。
vt = Wv · xt - 核心递推:
wt = w- · e() + kt · vt,ot = rt · (wt / (wt + ε)) - 衰减参数
δ控制历史信息的遗忘速度(可学习或固定)
- Channel-mixing(通道混合)层:
- 类似Time-mixing但在特征维度上做混合
- 包含R、K两个门控分量,用Shift操作替代部分线性层
- 交替堆叠:Time-mixing → Channel-mixing → Time-mixing → ... × N层
输入输出说明:
- 输入:
[Batch, SeqLen, Dim]— 序列长度×特征维度 - 输出:
[Batch, SeqLen, Dim]— 同形状输出(序列到序列) - BMS场景:输入
[B, T, 3](电压、电流、温度),输出[B, 1](SOC值,取最后一步或加线性头)
参数量计算:
- • 单层RWKV Block: - Time-mixing:
4d2(R、K、V、O四个线性映射)+d(衰减参数) - • 单层RWKV Block: - Channel-mixing:
2d × 4d + 4d × d = 12d2(expand_ratio=4) - • 单层RWKV Block: - 单层总计:约
16d2 - 典型配置(
d=512, N=6):约 25M 参数 - 轻量配置(
d=128, N=4):约 1M 参数 - 最小配置(
d=64, N=3):约 200K 参数
计算复杂度与资源估算:
| 配置 | 参数量 | FLOPs/Token | 推理内存 | 内存(FP32) | 内存(INT8) | 适用平台 |
|---|---|---|---|---|---|---|
| d=64, N=3 | ~200K | ~0.4M | O(d²)=4KB | ~800KB | ~200KB | STM32H7 |
| d=128, N=4 | ~1M | ~1.6M | O(d²)=16KB | ~4MB | ~1MB | ESP32-S3 |
| d=256, N=4 | ~4M | ~6.4M | O(d²)=64KB | ~16MB | ~4MB | i.MX RT |
- 训练复杂度:
O(L × d2)(可并行,类似Transformer) - 推理复杂度:
O(d2)每步(RNN模式,与序列长度无关) - 推理内存:
O(d2)— 仅需存储KV状态矩阵,与序列长度无关 - 关键优势:训练并行 + 推理O(1)内存 + 线性复杂度,是Transformer和RNN的最佳折中
嵌入式部署分析:
- ✅ 线性复杂度
- ✅ 恒定推理内存
- ✅ 已有嵌入式部署案例
三、BMS专用模型与方案
3.1 SOC实时估计
3.1.1 LSTM + AEKF 混合方案(最成熟)
论文: State-of-charge estimation of Lithium-ion battery: Joint long short-term memory network and adaptive extended Kalman filter online estimation algorithm
作者: Zhao, Lai 等(中国科学院电工研究所)
发表: Energy, 2020
论文链接:https://doi.org/10.1016/j.energy.2020.118265
论文简介:
该论文提出LSTM-RNN与自适应扩展卡尔曼滤波器(AEKF)的混合架构,是BMS领域SOC估计方向的高引用代表工作。LSTM负责捕捉电池电压、电流、温度等时序数据的非线性映射关系,AEKF负责在线修正估计误差,提高动态工况下的鲁棒性。这种"深度学习+传统滤波"的混合思路在工程实践中被广泛采用。
模型架构:
输入序列 [V, I, T]
↓
┌─────────────┐
│ LSTM-RNN │ → 初始SOC估计值
│ (预训练) │
└──────┬──────┘
↓
┌─────────────┐
│ AEKF │ → 修正后SOC估计值
│ (在线修正) │
└─────────────┘
输入输出说明:
- 输入:
[Batch, SeqLen, 3]— 电池端电压V、工作电流I、表面温度T的时序序列(滑动窗口) - 输出:
[Batch, 1]— SOC值(0~100%连续值)
嵌入式部署分析:
- ✅ LSTM部分可用CMSIS-NN的LSTM算子直接部署
- ⚠️ AEKF部分需手写C代码实现(矩阵运算可用CMSIS-DSP)
- ✅ 整体参数量可控(LSTM约200K参数)
典型性能:
- 估计精度:MAE < 2%,RMSE < 3%
- 参数量:优化后可控制在100K-500K
- 推理延迟:STM32F4上<10ms
3.1.2 CNN-BiLSTM 混合架构(RUL预测)
论文: Remaining useful life prediction of lithium-ion battery based on CNN-Bi-LSTM network
作者: Yuan Peng, Gao Yajing
发表: Electric Power Automation Equipment(电力自动化设备), 2021, Vol.41, No.10
论文链接:https://www.epae.cn/dlzdhsb/ch/reader/view_abstract.aspx?file_no=202110028
论文简介:
该论文提出CNN-BiLSTM混合网络用于锂电池剩余使用寿命(RUL)预测。CNN层从电池容量退化序列中提取局部特征,BiLSTM(双向LSTM)捕获容量退化序列的前后向时间依赖关系。与TCN-LSTM思路一致:卷积模块提取时序特征,循环模块建模长期依赖。
模型架构:
容量退化序列 / 健康因子(HF)
↓
┌─────────────┐
│ CNN │ → 局部特征提取
│ (1D卷积) │
└──────┬──────┘
↓
┌─────────────┐
│ BiLSTM │ → 前后向时间依赖建模
│ (双向LSTM) │
└──────┬──────┘
↓
┌─────────────┐
│ 全连接层 │ → RUL预测值
└─────────────┘
输入输出说明:
- 输入:
[Batch, CycleLen, Features]— 电池历史循环的容量衰减序列、健康因子等时序特征 - 输出:
[Batch, 1]— RUL预测值(剩余循环次数)
嵌入式部署分析:
- ✅ CNN部分可用CMSIS-NN卷积算子
- ⚠️ BiLSTM需改为单向LSTM以降低计算量(精度损失约1-2%)
- ✅ 适合离线分析场景(非实时)
3.2 电池滞回建模
3.2.1 物理信息神经网络(PINN)方案
论文: Physics-informed neural network for lithium-ion battery degradation stable modeling and prognosis
作者: Fujin Wang 等
发表: Nature Communications, 2024
论文链接:https://doi.org/10.1038/s41467-024-48779-z
论文简介:
该论文发表在Nature Communications上,将电池电化学物理方程(包括OCV-SOC关系、滞回特性等)作为物理约束嵌入神经网络的损失函数中。物理约束帮助网络学习到符合电化学规律的滞回特性,避免纯数据驱动方法可能产生的非物理解。代表了"物理+数据"混合建模的前沿方向。
模型架构:
电池运行数据 [I, V, T, Cycle]
↓
┌─────────────┐
│ 神经网络 │ ←── 物理约束(电化学方程)
│ (MLP/LSTM) │ 嵌入损失函数
└──────┬──────┘
↓
┌─────────────┐
│ 多任务输出 │ → SOH估计 + RUL预测
└─────────────┘
输入输出说明:
- 输入:
[Batch, SeqLen, 4]— 电流、电压、温度、循环次数 - 输出:
[Batch, 2]— SOH(健康状态)+ RUL(剩余寿命)
嵌入式部署分析:
- ⚠️ 物理约束部分需在训练时实现,推理时仅运行前向网络
- ✅ 推理阶段为标准MLP/LSTM,部署难度中等
- ⚠️ 多任务输出增加模型复杂度
滞回建模挑战:
- 电池充放电存在滞回效应(同一SOC对应不同OCV)
- 滞回与电流历史、温度、老化程度相关
- 纯数据驱动方法需要大量数据覆盖各种工况
- 物理约束可有效减少数据需求
3.3 静置电压(OCV)预测
3.3.1 基于DNN的部分充电数据OCV估计
论文: Deep neural network-enabled battery open-circuit voltage estimation based on partial charging data
作者: Ziyou Zhou, Yonggang Liu, Chenghui Zhang, Wei Shen, Rui Xiong(北京理工大学)
发表: Journal of Energy Chemistry, 2024, Vol.90
论文链接:https://doi.org/10.1016/j.jechem.2024.03.035
论文简介:
该论文提出基于深度神经网络的电池OCV估计方法,核心创新点是仅需部分充电数据(而非完整充电过程)即可估计电池的完整OCV曲线。使用深度全连接网络(DNN/MLP)学习从部分充电数据到完整OCV曲线的映射关系,解决了实际应用中难以获得充分静置时间来测量OCV的难题。
模型架构:
部分充电数据 [V_partial, I_partial, T]
↓
┌─────────────┐
│ DNN/MLP │ → 完整OCV曲线估计
│ (多层全连接) │
└─────────────┘
输入输出说明:
- 输入:
[Batch, Features]— 部分充电过程的电压、电流、温度数据(非时序,为提取的特征向量) - 输出:
[Batch, OCV_Points]— 完整OCV曲线(多个SOC点对应的OCV值)
嵌入式部署分析:
- ✅ 纯MLP架构,部署极其简单
- ✅ 可用CMSIS-NN全连接层直接实现
- ✅ 推理速度快,适合在线校准场景
- ✅ 参数量小(<50K),适合低端MCU
创新方向:
- 结合物理知识:RC等效电路约束
- 多时间尺度:不同静置时长的联合建模
- 端到端:直接从原始充电曲线预测OCV
3.4 BMS专用模型总结
| 方向 | 代表论文 | 网络结构 | 输入 | 输出 | 嵌入式难度 |
|---|---|---|---|---|---|
| SOC估计 | Zhao et al. (2020) | LSTM + AEKF | V, I, T时序 | SOC | ★★★☆☆ |
| RUL预测 | Yuan et al. (2021) | CNN-BiLSTM | 容量退化序列 | RUL | ★★★☆☆ |
| 滞回建模 | Wang et al. (2024) | PINN | I, V, T, 循环数 | SOH, RUL | ★★★★☆ |
| OCV预测 | Zhou et al. (2024) | DNN/MLP | 部分充电特征 | OCV曲线 | ★☆☆☆☆ |
四、推荐方案总结
4.1 按应用场景推荐
SOC实时估计(高实时性)
推荐模型: ModernTCN 或 优化后的GRU
- 理由: 纯CNN/GRU推理速度快,适合kHz级采样
- 参数量目标: <500K
- 预期精度: MAE < 3%
滞回建模(高精度)
推荐模型: iTransformer
- 理由: 变量间注意力机制可学习电流-电压耦合
- 参数量目标: 1-2M
- 预期精度: 电压预测RMSE < 10mV
静置OCV预测(低频次)
推荐模型: PatchTST 或 TCN
- 理由: 可处理较长历史序列,计算量可控
- 参数量目标: <1M
- 预期精度: OCV预测误差 < 5mV
4.2 综合推荐
| 排名 | 模型 | 综合评分 | 主要优势 | 主要劣势 |
|---|---|---|---|---|
| 1 | iTransformer | ★★★★★ | 变量间建模强,嵌入式友好 | 对极长序列需优化 |
| 2 | ModernTCN | ★★★★☆ | 纯CNN高效,易部署 | 长程依赖稍弱 |
| 3 | PatchTST | ★★★★☆ | 结构简洁,通道独立 | 可能损失变量耦合 |
| 4 | MambaTS | ★★★☆☆ | 线性复杂度,长序列友好 | 部署工具链不成熟 |
| 5 | DLinear | ★★★☆☆ | 极简,资源占用极低 | 表达能力有限 |
五、开源资源汇总
5.1 模型库
| 项目 | 链接 | Stars | 说明 |
|---|---|---|---|
| Time-Series-Library | https://github.com/thuml/Time-Series-Library | 8k+ | 清华开源,包含iTransformer、PatchTST等 |
| tsai | https://github.com/timeseriesAI/tsai | 4k+ | fastai风格的时序库 |
| sktime | https://github.com/sktime/sktime | 8k+ | scikit-learn兼容的时序库 |
| Mamba | https://github.com/state-spaces/mamba | 15k+ | 官方Mamba实现 |
5.2 BMS专用资源
| 类型 | 资源 | 说明 |
|---|---|---|
| 数据集 | NASA Battery Dataset | 公开电池老化数据 |
| 数据集 | Oxford Battery Degradation Dataset | 多工况测试数据 |
| 工具 | MATBAT | 电池建模工具箱 |
5.3 部署工具
| 工具 | 说明 |
|---|---|
| TensorFlow Lite Micro | 嵌入式推理框架 |
| CMSIS-NN | ARM优化神经网络库 |
| NNoM | 单片机高层推理库 |
| emlearn | 嵌入式机器学习库 |
六、实施建议
6.1 开发路线
阶段一:Baseline建立(1-2周)
- 使用DLinear建立简单baseline
- 验证数据流程和评估指标
- 在目标硬件上测试部署流程
阶段二:模型选型与优化(2-4周)
- 对比iTransformer、PatchTST、ModernTCN
- 针对电池数据进行迁移学习
- 量化压缩至目标大小
阶段三:部署优化(2-3周)
- 使用CMSIS-NN或TFLM部署
- 性能 profiling 和优化
- 长时间稳定性测试
6.2 关键注意事项
- 数据质量: 电池数据需要精确的同步(电压/电流/温度)
- 标定策略: 深度学习模型需要定期用OCV法标定
- 安全边界: AI估计结果需要与保守的物理约束结合
- 温度补偿: 确保模型在不同温度下泛化
七、参考文献
- Liu, Y., et al. (2024). iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. ICLR 2024.
- Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces.
- Gu, A., & Dao, T. (2024). Mamba-2: State Space Duality. ICML 2024.
- Nie, Y., et al. (2023). A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. ICLR 2023.
- Wu, H., et al. (2023). TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis. ICLR 2023.
- Liu, S., et al. (2024). A hybrid deep learning model based on parallel TCN-LSTM architecture for battery RUL prediction.
- Liu, Z., et al. (2024). KAN: Kolmogorov-Arnold Networks.
报告完成
