夜雨聆风
夜雨聆风
AsterFire Flow 1.0 预览版发布!
2026 年 5 月 4 日,一场针对科研流水线底层逻辑的"升级"正式启动。星使智算重磅发布 AsterFire Flow 1.0 预览版——一个面向科研用户的 AI 驱动 DAG 工作流系统。
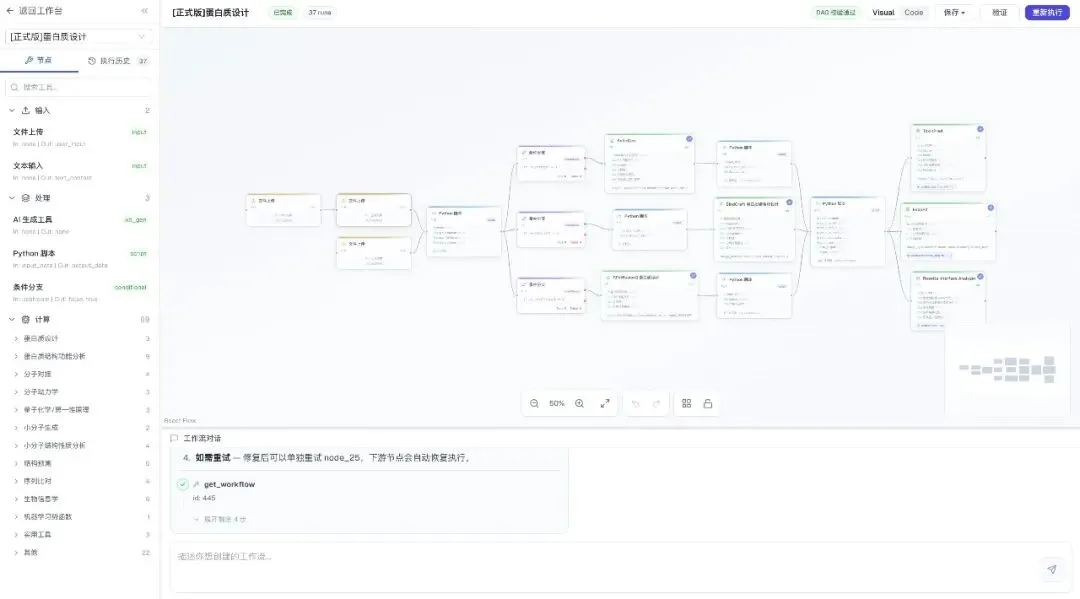
AsterFire Flow 完整画布:左侧 50+ 节点面板(按 12 个科学计算领域分类)、中央 DAG 编辑器、底部 Workflow Chat
这不是一个简单的 DAG 编辑器,而是一个能听懂人话、能记住每一步、能让同一份流水线在不同人手里跑出一致结果的科研工作流引擎。它标志着科研工作从枯燥的"一次性脚本",正式跨越到可复用、可分享、可溯源的资产。
PART01
痛点直击
从 final_v7.py 到 real_final_v99.py,科研自动化的尽头到底在哪?
写过科研代码的人,应该都见过这种文件名进化史——
analysis.py → analysis_v2.py → analysis_final.py
→ analysis_final_v7.py → analysis_real_final.py
→ analysis_real_final_v99_DONOTDELETE.py
每一次重命名背后,都是一次重跑、一次救火、一次"差点把上次的覆盖了"。科研代码越写越长,命名越改越离谱,但它的终极宿命——写完就扔。
对于科研工作者来说,最直接的痛点不是"算不动",而是:
🔍 流程难复现:同一份脚本,换了机器、换了同事、换了时间,跑不出来同样的结果;
🔍 批量难规模化:1000 个分子要批跑,写一段 for-loop 还行;要并行、要缓存、要错误重试,胶水脚本越写越长;
🔍 结果难溯源:跑出来的数字,半年后再看,不知道当初用了什么参数、什么版本的工具、什么输入;
🔍 流程难分享:把流水线给同事,对方先卡在环境上,再卡在文件路径上,最后卡在版本不一致;
🔍 工具难扩展:工具库里没你要的工具?申请提交、等开发同学打包、几天起步。
我们的实践:让 AI Agent 接管科学计算
作为 AI for Science 这条路上的探索者,我们已经做过不少实践——
ABACUS Agent:丢一句话 + 一个结构,AI 自动参考手册和科学家知识,完成 DOS、能带、甚至声子的计算和绘图;
SPONGE Agent:丢一段话 + 一个 PDB ID,AI 自动完成分子动力学的全过程模拟和分析。
这种纯智能体形态已经能解决很多场景——研究员不再需要写脚本、查手册、调命令行参数。
但科研需要的不只是聪明
科学计算的特点是精确性要求极高:轻则 rubbish in / rubbish out(输入差一点,输出全错),重则直接报错不让算。计算结果可靠、可复核,是科研论文最基本的要求。
可越往复杂场景走,纯智能体形态的边界越明显——当多流程、多软件被组合到一起、由 AI 全程调度时:
📌 参数容易串:从 SPONGE 切到 ABACUS、从 DOS 切到声子——每个软件的参数和约定都不一样,AI 一不留神就混;
📌 上下文长了就摆烂:让它跑 10 个同样的计算 + 分析?后几个可能就漏字段、串结果,甚至一本正经地胡说八道;
📌 黑箱化:你不知道它内部用了什么工具、什么参数,结果对不对全靠人审;
📌 改不动:流程跑错想精准修一步?要么从头跑,要么用更长的 prompt 哄它。
为了让 AI 不出错,提示词和知识库要把每个细节都描述清楚——但提示词一旦写到一定长度,又会触发 AI 上下文衰减、前后矛盾。这是一条没尽头的拉锯战。
科研需要的是可控的智能——既要 AI 的能动性,又要工程系统的可复现。
AsterFire Flow——把 AI 的灵活,与工程的可靠合二为一。
PART02
硬核实力
我们的实践:这不仅是 DAG 编辑器,是"科研工作流基础设施"
AsterFire Flow 之所以具有"开创性"意义,在于它不只是一个画 DAG 的工具——它构建了一套面向科研问题的工作流基础设施:能够理解科学语言、识别工具与数据、连接执行条件与原始证据,并将这些信息组织为可检索、可比较、可溯源的工作流资产网络。
1
节点底座:
覆盖科研全栈的工具节点
截至发布日,平台已经形成较为完整的节点底座:
📍 50+ 内置节点:从输入、控制、AI 生成,到全栈科学计算;
📍 12 个科学计算领域:蛋白质设计(3 类)、蛋白质结构功能分析(9 类)、分子对接(4 类)、分子动力学(3 类)、量子化学/第一性原理(3 类)、小分子生成(2 类)、小分子结构性质分析(4 类)、结构预测(5 类)、序列比对(4 类)、机器学习势函数(1 类)、实用工具(3 类)、其他(16 类);
📍 2 类控制流:Conditional / Script,让"如果 A 成则走 B 否则走 C 最后合流到 D"也能在 DAG 里搭得起来。
这是一个持续进化的工具库——不同于一次性打包的工具集,它通过 Kit-Gen 能持续接入最新的科学计算工具。
2
模板矩阵:
覆盖科研全栈的端到端工作流
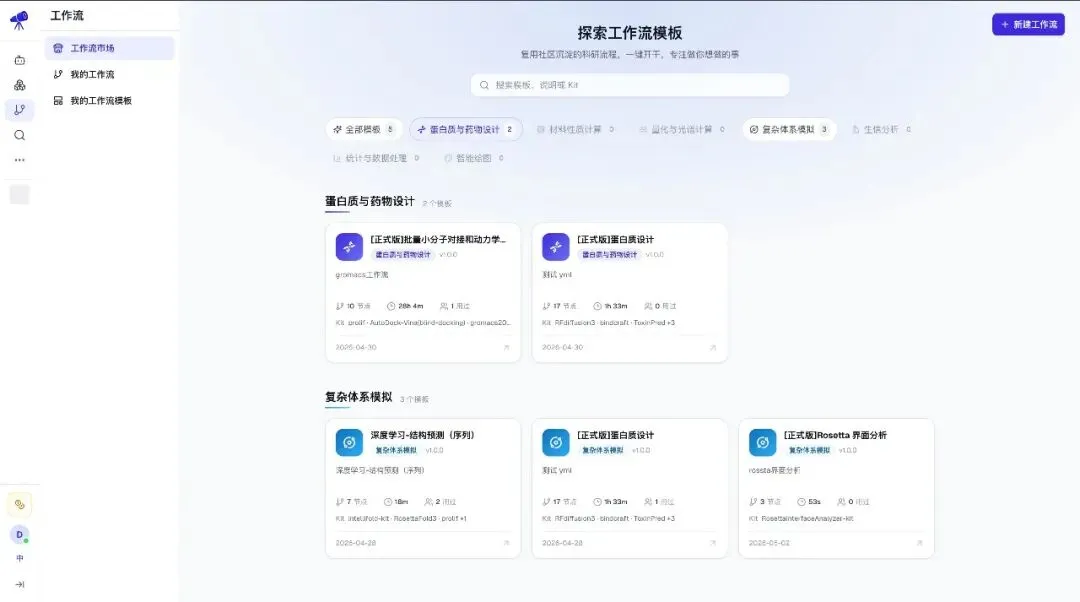
有节点不会组怎么办?AsterFire Flow 配套工作流模板,拿来即用!第一轮公开模板已经覆盖以下科研常见任务路径——
化学/分子模拟
蛋白设计 → 验证:从类 AF3 工具设计,到结合与互作分析(界面分析、动力学模拟、自由能分析),再到成药性质评估(热稳定性、毒性预测)——从设计到验证一气呵成;
电解液力场生成 + 模拟:ORCA → sobtop → GROMACS 三段式流水线;
分子对接 → 可视化分析 → GROMACS 动力学:从虚拟筛选到分子动力学完整链路;
MOF 滤膜体系力场生成 + 模拟:滤膜场景下的 ORCA → sobtop → GROMACS 全链路;
GO-小分子体系力场生成 + 模拟:石墨烯-小分子体系的力场打包流水线。
材料/第一性原理
MACE 全栈机器学习势工作流:采样 → ABACUS 单点 → MACE 训练 / 微调 → 下游应用(高通量吸附 / 过渡态 / 热导率 / 声子谱);
ABACUS 电子结构计算流程:MACE 预优化 → ABACUS 结构优化 → 能带 / DOS / 电荷分析。
光谱
一键光谱工作流:从结构到光谱预测的端到端路径。
生物信息
单细胞分析全流程:文献输入 → 质控 → 标准化 → 数据整合 → 降维聚类 → 分群 → 细胞类型定义 → 拟时间分析。
每一条都不是空架子——
它们来自真实科研课题,是科研者今天会做、明天还会重复做的事。
3
言出法随:一句话生成科研工作流
在科研场景中,最不愿意做的事就是搭流程图。AsterFire Flow 让 AI 接手这一步:
🔹 AI Planner:你描述需求,它在画布上长节点。它读得懂工具库里所有节点的 IO contract,连参数都帮你填好;
🔹 Kit-Gen:工具库里没你要的工具?AI 远程开机、写代码、装依赖、Docker 构建、SIF 转换、跑测试,沙盒测试 + 创建者确认 + 团队 review 后入库。
常见的科研流程——预测、分析、批跑、对比——大多数能一句话搭出来。
🔹 KIT-GEN 展望
下一步,Kit-Gen 会接入更强力的代码生成模型,把生成工具的复杂度再往上推;同时开放共建——每位研究者都能造自己趁手的模组,并把它贡献给所有人。一个 AI for Science 时代的工具库,应该由整个社区共建。
4
复现能力:
拒绝"跑一次就丢",每一步都有证据
在科研场景中,真正不可接受的,不是"算得慢",而是"跑出来的数字明年没人能复现"。
AsterFire Flow 要解决的,正是这一问题:让每一次运行都建立在可追溯、可核验的证据之上。
🔸 Provenance 溯源:每个节点的输入、输出、参数都会被记录,每一条结果都能反查到具体哪一步、用了什么参数;
🔸 Item-level 缓存:哪怕你后来改了流程,历史的那次运行——节点结构、参数、输出——都还在;改一个分子,只重跑那一个;
🔸 YAML 双向同步:画布与 YAML 进了 Git,就再也不会"一次性"。
AsterFire Flow vs 普通 AI Agent

PART03
场景革命
AsterFire Flow vs 传统脚本,使用门槛大幅降低
接下来,我们从三个真实科研场景,看 AsterFire Flow 如何重塑科研工作流。
📌 场景一
面对一篇论文里描述的实验流程
你该怎么开搭?
🔍 传统流程:翻论文找方法 → 找开源代码 → 装环境 → 试参数 → 改两遍发现 fork 版本和论文对不上 → 最后还要整理一份能给老板看的"流程图"。
📝 AsterFire Flow 体验:把论文方法描述粘进 Workflow Chat → AI Planner 直接出节点。
"用 ESMFold 预测这条蛋白结构,分析 binding pocket,生成报告。"
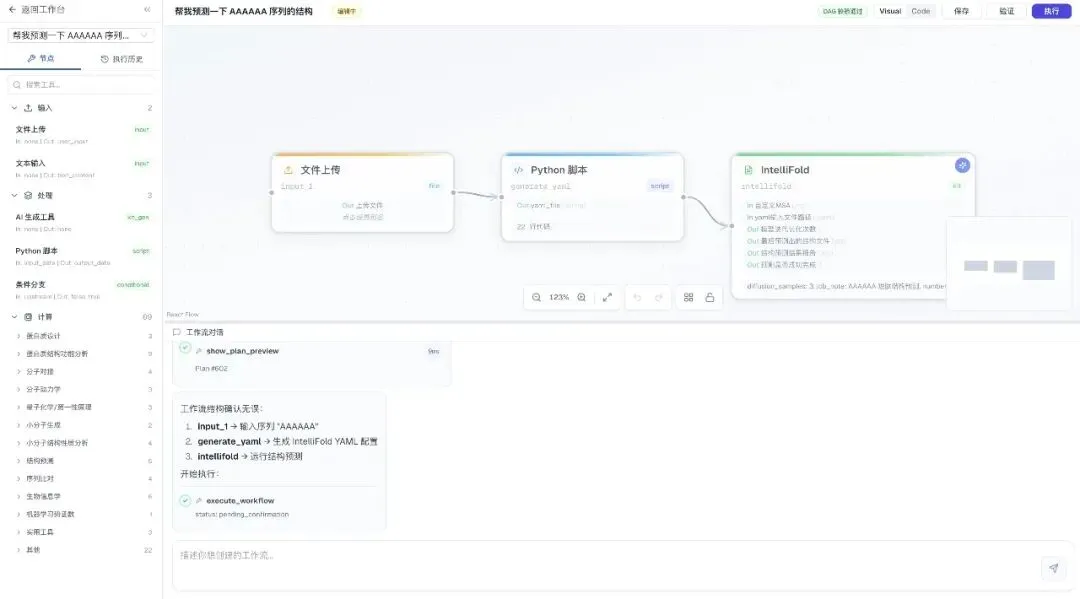
AI Planner 自动搭出的 DAG,可直接执行
🔖 能力体现:AI 一边解析、一边在画布上长节点,连参数都帮你填好。常见的预测、分析、批跑、对比类流程,大多数能一句话搭出来。
📌 场景二
1000 个分子批跑
跑到一半发现一条输入错了?
🔍 传统流程:把整段循环重新跑一遍——可能要等几个小时,浪费的是已经算对的 999 条。
📝 AsterFire Flow 体验:把"批处理"压成一个 Scatter 节点——pair / matrix 两种组合,item-level 缓存自动起效。改一个,只重跑那一个。
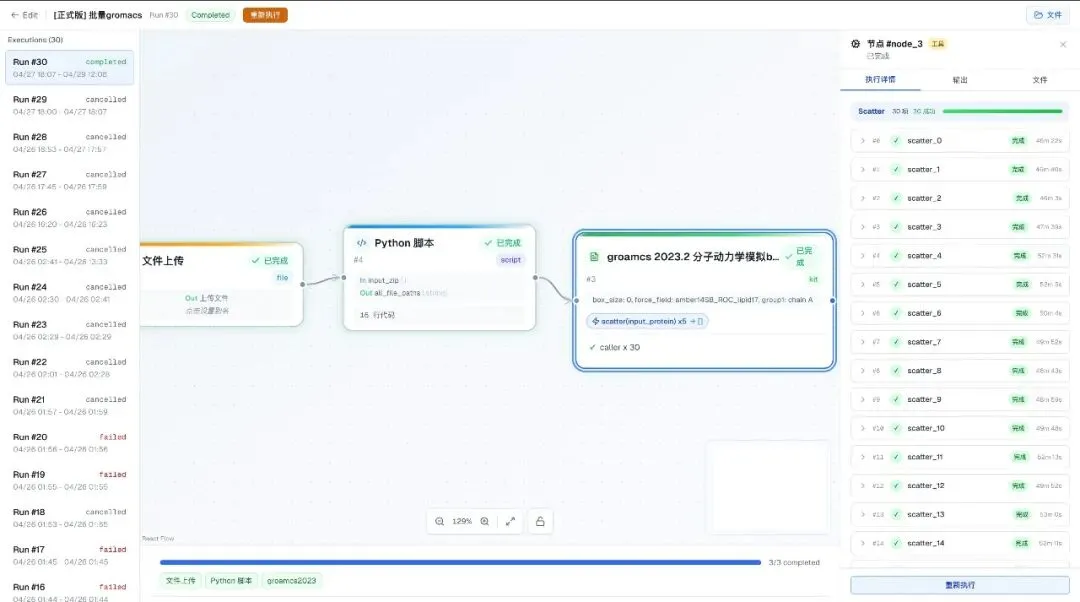
Scatter 节点把单步操作展开成 N 个并行任务,每个 item 独立缓存、独立溯源
🔖 能力体现:Scatter 让批处理第一次变成 workflow 的原生能力。每个 item 独立缓存、独立失败重试、独立溯源——而不是一段需要单独维护的胶水脚本。
📌 场景三
同事问你"上次那个流程能给我跑一遍吗"
你如何应对?
🔍 传统流程:
发 Python 文件 + README → 对方装不上环境 → 你远程帮装 → 对方跑出错 → 你们一起 debug 半天 → 终于发现是路径问题。
📝 AsterFire Flow 体验:
把这条工作流导出 YAML 发过去——对方拉取、导入、点执行。结果按同一配置复现。
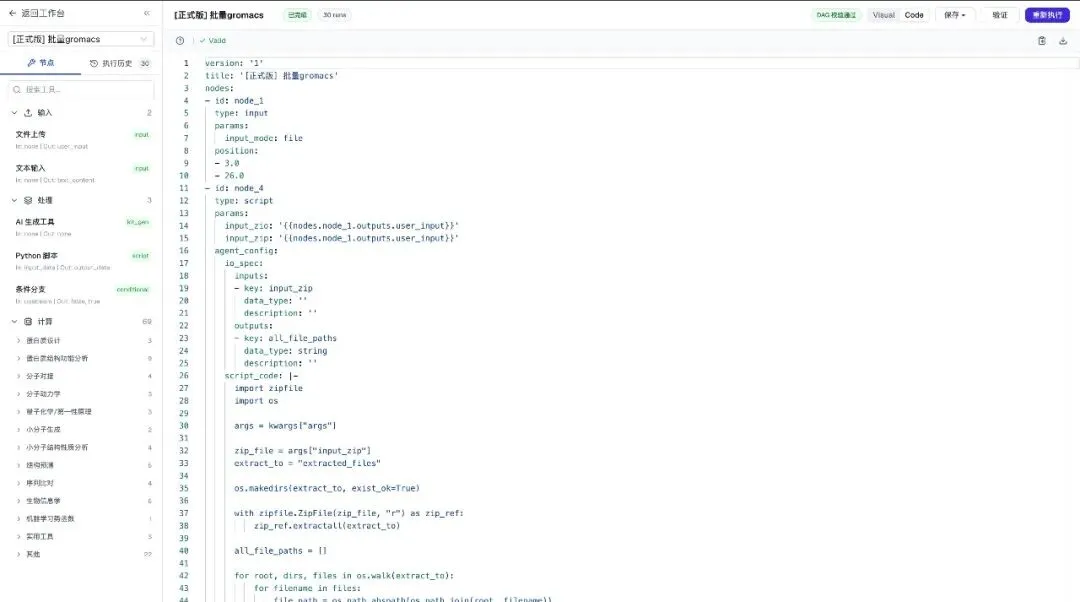
同一份工作流可在画布和 YAML 之间双向切换,研究员、工程同事、CI 三方共用
🔖 能力体现:画布与 YAML 双向同步——研究员在画布上拖节点,工程同事在 Git 里 review YAML,CI 用同一份定义跑回归。一份流水线进了 Git,就再也不会"一次性"。
PART04
技术壁垒
为什么它能做到“懂科研”?
AsterFire Flow 背后,是一套围绕"科研工作流可复用"目标设计的系统。它不只是把节点画成框框连起来,更要让节点之间、流程之间、人之间能互相理解。
1
IO Contract 体系:
让工具讲同一种"科研方言"
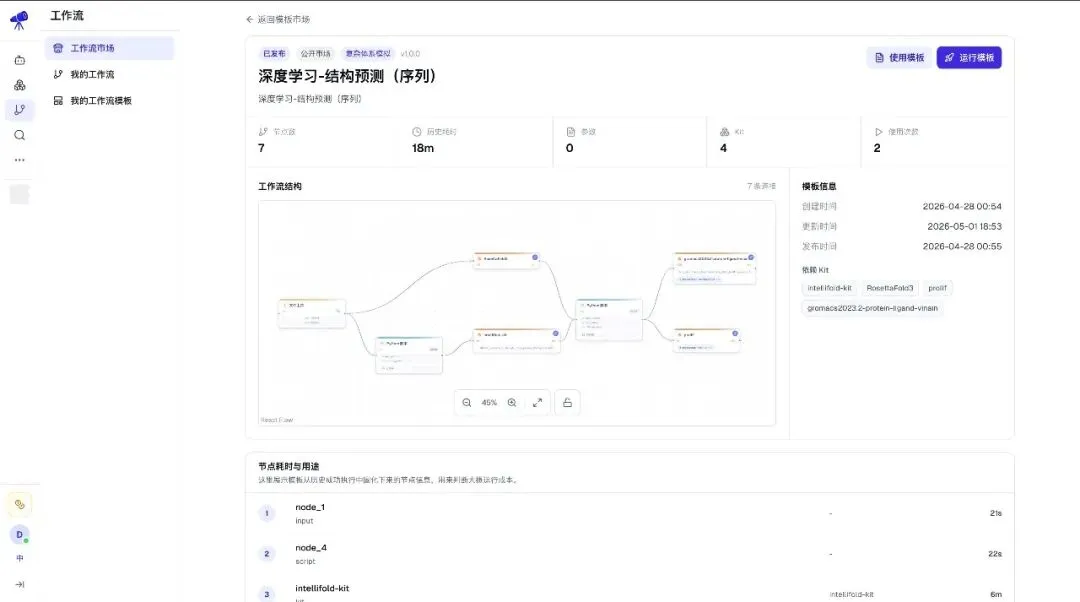
每个工作流都有结构化的元数据:节点数、Kit 依赖、历史耗时、版本
每个节点都有结构化的 IO 描述(input / output 的类型、格式、含义)。这件事看似简单,但它让 AI 能读懂"哪些节点能接哪些",让 Scatter 能自动展开文件目录,让 Lineage 能追溯每一份数据的去向。
2
AI Planner + Kit-Gen:
把"找工具"和"造工具"都接管
不是把 AI 当成"高级搜索",而是让 AI 成为工作流搭建的一等公民——能直接画图、改图、塞节点、造工具。
往下走,我们想让 AI 做更多——
🔹 看懂你画好的流程:帮你 review、提改进建议、给整体打个分;
🔹 看懂失败的运行:从日志和 Lineage 里定位哪一步挂了、为什么挂、怎么改。
3
运行记录 + 结果缓存:
每一次运行都进"可复现账本"
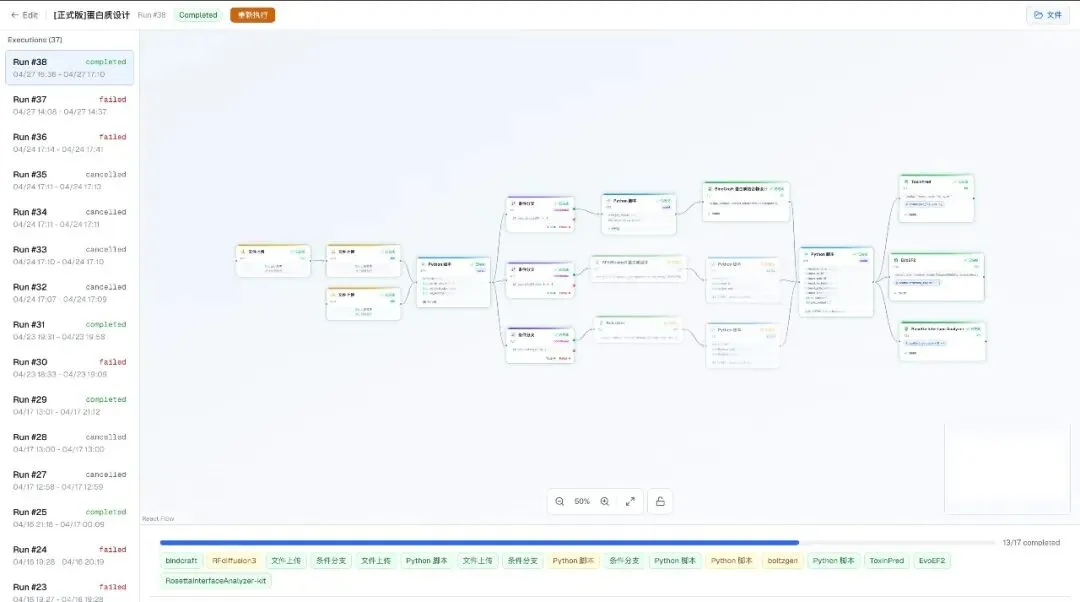
每次运行的输入、输出、参数都按 content-hash 索引,引用失效会自动提示
每次运行的所有输入、输出、参数都按 content-hash 索引。哪怕你后来把流程改了,历史的那次运行依然完整保留。任意结果都可以从运行记录中倒推回它的来源——这意味着你跑出来的数字,明年别人想复现,只要拿到 YAML + 运行记录,就能跑出一致的输出。
PART05
现在试用
邀请试用与 Roadmap
AsterFire Flow 1.0 预览版今天起开启邀请制内测。第一批名额给已有用户和深度合作方。
🔸 如果你是星使智算的已有用户
登录后台,左侧菜单的 Workflow 入口已开放。模板市场和端到端范例已经备好。
🔸 如果你是合作方 / 关注合规和私有部署
API 文档已上线,私有部署、定制工具库都可以聊。
正式 1.0 GA 预计在下个版本周期开放给所有用户。
AsterFire Flow 1.0 预览版的发布,不只是一次软件更新,更是 AI for Science 工作流资产化理念的一次落地。
它把科研人员从繁琐的环境管理、版本管理、参数管理中解放出来——让科学家回归科学的本质:思考与发现。
未来已来,我们和您共同面对。
产品官方入口:www.sidereus-ai.com
*点击阅读原文即可进入