夜雨聆风
夜雨聆风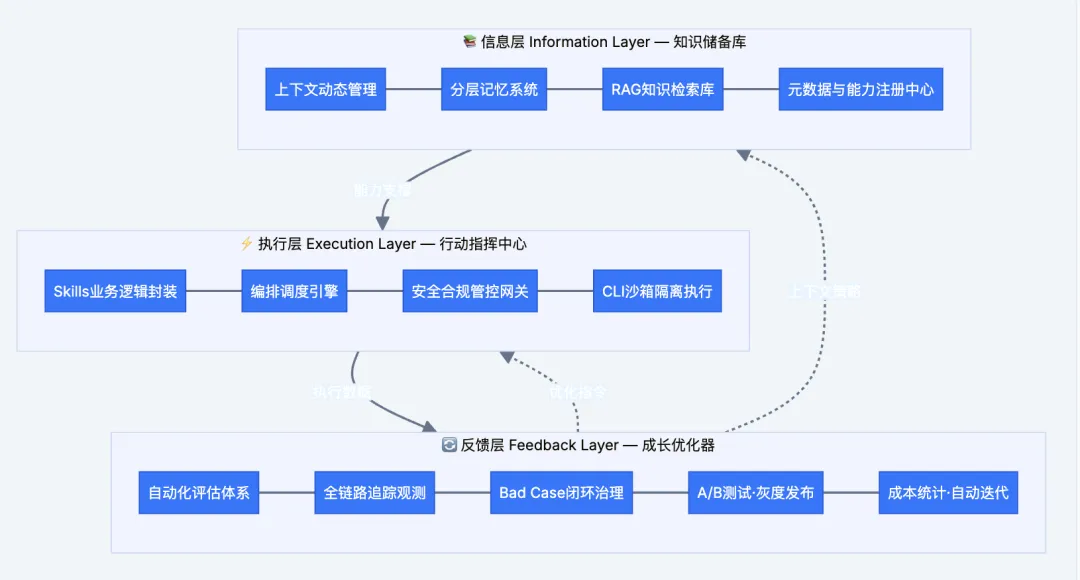
这次版本更新,主要解决了以下AI知识库的痛点:
持久化用户记忆
技能自主学习
GEPA Prompt 优化
接下来我就展开和大家聊聊具体的功能实现细节。
先和大家聊聊什么是 JitKnow AI 知识库
JitKnow 是一款面向个人与企业的 AI 知识管理与协作平台,融合了结构化文档编辑、多格式智能解析、RAG 增强检索和 AI 多智能体工作流。产品支持个人版和企业版两条产品线,通过开放 API 允许第三方系统集成。
企业文化 企业产品相关问题 企业培训手册 企业知识库 人事任命/薪酬/组织部门等信息
更多介绍可以参考我往前的文章:
JitKnow AI知识库V2.2.0发布:打造文档驱动的“企业AI大脑”
JitKnow V2.0.0发布:开放API+数据分析重构知识管理边界
JitKnow知识库 V1.5.0 发布:企业控制台 + 自定义模型上线!
下面和大家分享一下这期我们设计的功能点。
Phase 1: 上线持久化用户记忆功能
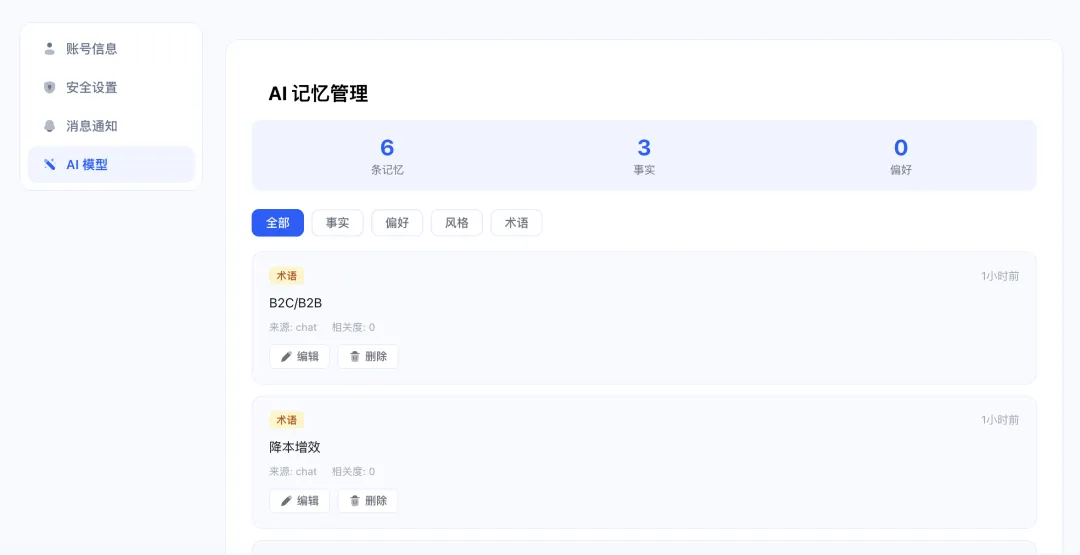
解决的问题:
之前我们的AI知识库记忆实现方案,使用了滚动窗口 + LLM 摘要,会出现跨 session 完全遗忘用户写作风格、术语偏好、文档模式等问题,同时用户每次新对话都从零开始,无法积累个性化知识。
最近我们研究借鉴了 Hermes Agent 的思想, 设计了一套机制:
Hermes 的
MEMORY.md+USER.md持久化文件 + FTS5 全文搜索我们用 PostgreSQL 替代 SQLite FTS5,但核心思想一致:跨 session 积累、自动评估、结构化存储
Hermes 的 "periodic push mechanism" → 我们的
pruneMemories()评估哪些记忆值得保留
具体的技术架构原理如下:
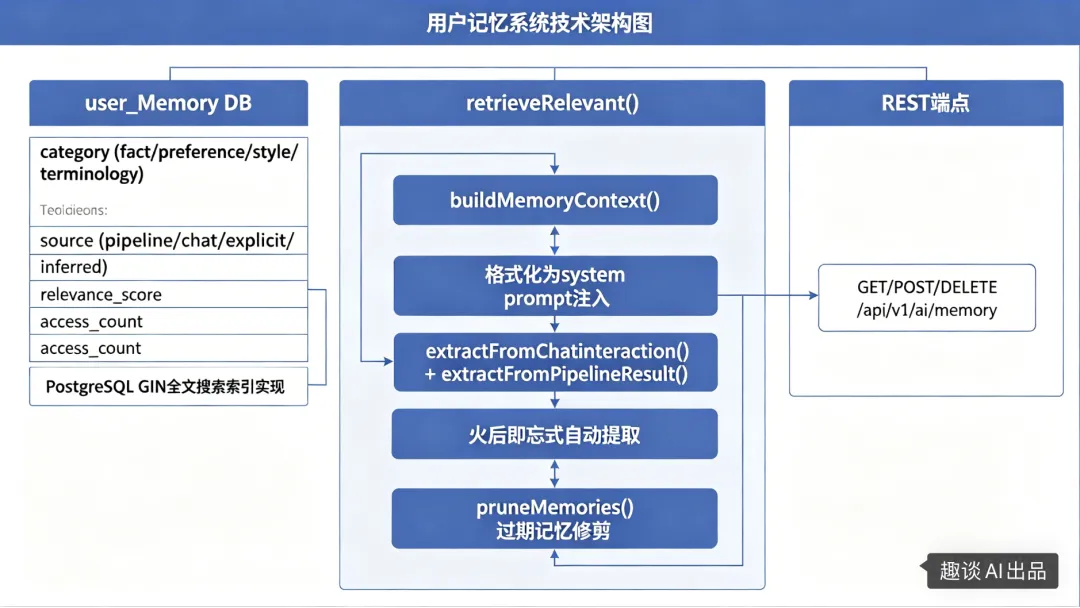
通过这种方式设计,可以保证在可控的上下文和tokens消耗下,能有一个稳定+持久的AI记忆,最终效果就是:JitKnow的用户用得越多,AI助手越懂你。
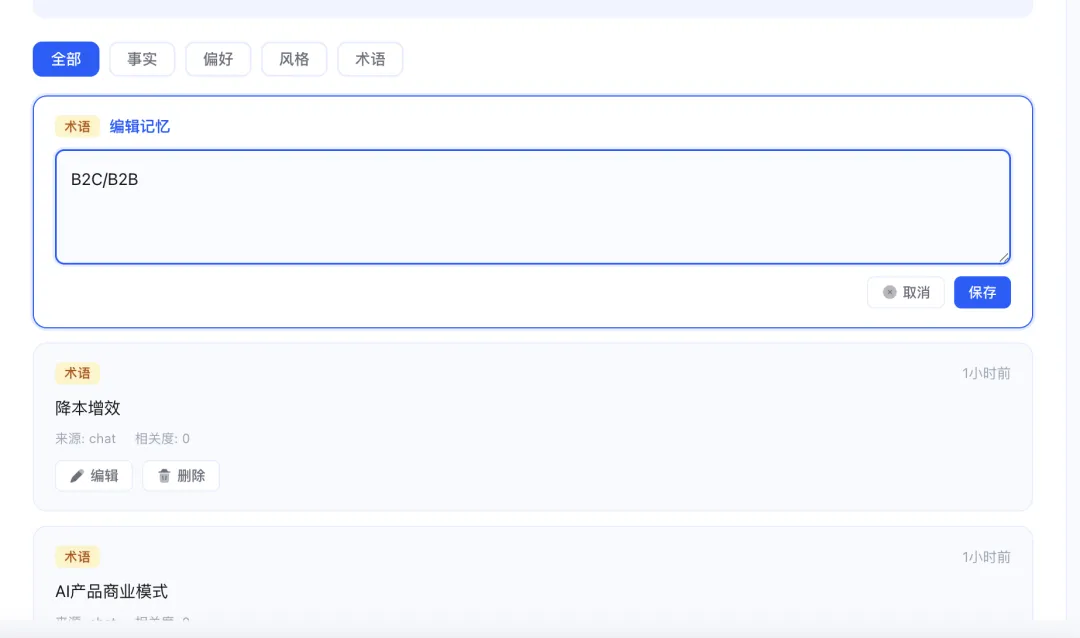
同时我们还开放了记忆编辑能力,可以修正AI的记忆,让它朝着我们期望的方向“成长”:
Phase 2: 技能自动学习
解决的问题:
之前我们在办公Agent模块,内置的技能完全由我们手动编写,添加新文档类型需要开发者介入,同时高质量 pipeline 运行的经验无法自动沉淀为可复用的技能。
这里我们借鉴 Hermes Agent 的如下思想:
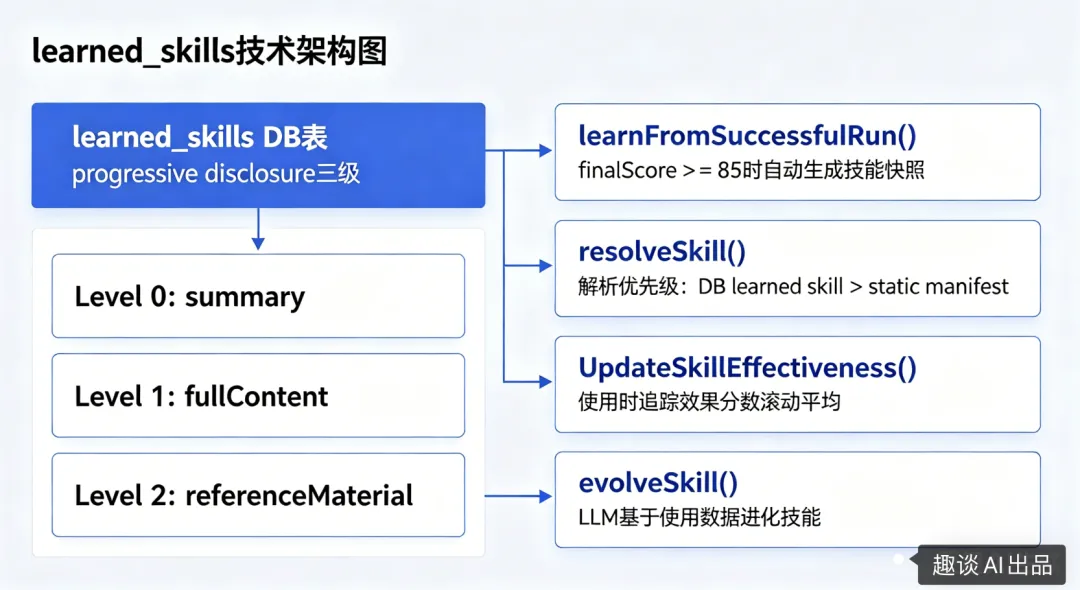
Hermes 的 agentskills.io 标准渐进式披露:Level 0 概览 → Level 1 完整 → Level 2 深度参考
Hermes 的 "auto-generate skill files from complex tasks" → 我们的
learnFromSuccessfulRun()技能优先级 learned > static → Hermes 的 "improve over time while retaining safety net"
实现了一套机制,来实现AI Agent能自主学习,具体的架构设计如下:
大家可以参考一下,也可以直接体验我们 JitKnow AI知识库:
Phase 3: GEPA Prompt 优化
解决的问题:
之前我们的AI助手模块,没有从 pipeline 输出质量到 prompt 质量的反馈回路。Prompt 完全静态,无法根据实际效果自我改进。
我们也借鉴了 Hermes Agent 的设计思路:
Hermes 的 "periodic push mechanism" 定期评估上下文窗口占用,动态压缩
我们用 token-budget 替代固定轮次,本质上就是 Hermes 的 "evaluate what's worth keeping" 思想
Handoff framing 对应 Hermes 的 "memory-context fence",防止 LLM 将背景信息误认为用户指令
具体的实现方案如下:

总结
对AI不了解的朋友可能看到这里还是不太懂这次更新的功能到底有什么用,我用大白话总结为两个核心痛点的优化:
第一点:
我们之前的 AI 写作助手,用户每次对话都是从零开始,prompt 全靠手写,所以我们加入了持久记忆、技能自学习、Prompt 自动优化、工具协议,来保证AI写作能连续的,带有记忆的来为我们文档创作服务。
第二点:
在第一步实现之后,上线后发现还有三大问题需要优化:上下文溢出、错误无法恢复、安全漏洞。所以我们又加了压缩隔离、错误分类、注入检测、冻结快照。
这个过程给我们团队最大的收获是:从 Hermes Agent 学到了:AI 系统的核心挑战不是功能,而是 工程安全"。
最后补充一嘴
感谢每一位陪伴 JitKnow 成长的老用户,后续我们会继续倾听大家的声音,迭代出更贴合需求的功能。