 夜雨聆风
夜雨聆风我是王练,一个爱折腾工具的工程师。在这里,让 AI 从概念变成你手里的工具。
上回那篇文章里,我们把几件该做的事做了:
Hermes Agent 装好了。
女娲 Skill 装好了。
王小波的风格也蒸馏出来了。
但那都是半吊子。为什么?因为还得手动复制粘贴。飞书和公众号之间,中间隔着一道人工的墙。
这不好。照我看,人活着就该让机器替我们干这些枯燥的活儿。我们自己呢,去想些有趣的事。
所以这一篇,我把九步全写出来。走完这九步,你只需执行一条命令,剩下的事,全部自动完成。剩下的时间,你可以去读书、去散步、去想明白些道理。
九步是这样的:
• 编写 .env 配置(飞书 App ID/Secret、微信 App ID/Secret)
• 脚本获取飞书文档 token
• 调用飞书 API 读取文档 blocks
• 提取结构化文本(标题、正文、列表、代码块),保存为临时文件
• 加载 wang-xiaobo-perspective skill,逐段改写风格
• 保存改写后文本
• 读取改写后文本,生成微信 HTML 排版
• 下载飞书图片 → 上传到微信素材库 → 替换链接
• 创建微信公众号草稿,返回草稿链接
所谓"一键发布",就是这个意思。不是说你真就按了一个键——是你敲了一行命令,然后你就可以走开了。
第一部分:功能说明
上篇我们做的那个东西,说它能"飞书→公众号",其实得靠手工复制粘贴。而且只处理纯文本——遇到图片、列表、代码块,排版就乱成一团。那叫半成品。
半成品不是不能用,但总觉得差点意思。这道理很明白——你总不能指望一个不认识 Block(块)的程序去读懂一篇飞书文档。
因为飞书文档的真实结构是 Block。每一段是一个 block。每一张图是一个 block。每一个列表项也是一个 block。只有读懂了 block,才能把原始结构原封不动地搬到公众号去。
还有一件事。公众号 API 不接受 Markdown 图片链接。你必须先把图片上传到微信素材库,再把链接换成素材库的 URL。这件事不做,图片就没了。图片没了,文章就像人没了眼睛——能走,但不好看。
前置条件
• 已经完成第1篇:0基础打造AI写作助手:从安装Hermes到加载“女娲”Skill
• 飞书账号已注册
• 微信公众号已开通
本篇完成后,你会得到一个可独立运行的 Skill。
第二部分:完整步骤(共9步)
步骤1:编写 .env 配置
敏感信息不能硬编码。这是常识。你总不能在代码里明文写上你的密码,然后说"反正没人看"。这就跟你把钥匙藏在门垫底下一样——不是没人找得到,是找的人懒得弯腰。
我们把所有敏感信息放在一个 .env 文件里。在项目目录下创建它:
• 配置内容如下:

# 飞书凭证FEISHU_APP_ID=你的APP_IDFEISHU_APP_SECRET=你的APP_SECRET# 微信公众号凭证WECHAT_APPID=你的公众号APPIDWECHAT_APPSECRET=你的公众号SECRET# 公众号名称WECHAT_ACCOUNT_NAME=公众号名称# 作者署名WECHAT_AUTHOR=作者署名
就这么简单。四个变量,一个公众号名字,一个署名。
步骤2:获取飞书文档 token
飞书文档的 URL 长这样:
https://xxxx.feishu.cn/docx/D0cxbF9dkoT6bqxHcqRcFjNunAf
其中
D0cxbF9dkoT6bqxHcqRcFjNunAf
就是 document_id,也叫文档 token。写一个函数,从 URL 里把它揪出来:
def extract_feishu_doc_token(url: str) -> str:"""从飞书文档链接中提取文档 token"""# 支持格式:# https://xxx.feishu.cn/docx/xxxxx# https://xxx.feishu.cn/docx/xxxxx?xxx=yyy# https://xxx.feishu.cn/doc/xxxxxmatch = re.search(r'/docx/([a-zA-Z0-9]+)', url)if not match:match = re.search(r'/doc/([a-zA-Z0-9]+)', url)if not match:print(f"无法提取飞书文档 token: {url}")print(f" 请确认链接格式为: https://xxx.feishu.cn/docx/xxxxx")sys.exit(1)token = match.group(1)print(f"文档 token: {token}")return token
这函数的道理很明白:找到 /docx/ 后面的那一串字符,就是它了。找不到?那就是链接格式不对,退出。
步骤3:调用飞书 API 读取文档 blocks
飞书文档的内容以 Block 为单位存储,而 block 是树形结构,需要递归获取。这里是核心部分:
def read_feishu_doc_blocks(doc_token: str, feishu_token: str) -> dict: """ 读取飞书文档 blocks,返回结构化的文档内容 返回数据结构: { "raw_content": str, # 纯文本内容(raw_content API) "blocks": list, # 所有 blocks(blocks API) "headings": list, # 标题块 [{block_id, level, text}] "image_tokens": list, # 图片 token 列表 "code_blocks": list, # 代码块内容列表 "callouts": list, # Callout 高亮块 "quote_blocks": list, # 引用块 "bullet_items": list, # 无序列表项 "ordered_items": list, # 有序列表项 "highlighted_texts": dict, # 高亮文本 {text: color} "bold_texts": set, # 加粗文本集合 } """
为什么要返回这么多东西?
因为一篇飞书文档不是只有文字。有标题,有图片,有代码,有高亮,有列表。你得把它们都认出来,才能在公众号里把它们放回原位。
步骤4:提取结构化文本,保存为临时文件
飞书 block 有多种类型:
1=标题
2=正文
12=无序列表
13=有序列表
14=代码块
27=图片
我们解析完之后,需要把文字部分提取出来,供后续改写使用。
# 保存文档数据到临时文件,供后续步骤使用output_path = "/tmp/feishu_doc_data.json"# 将 set 转换为 list 以便 JSON 序列化serializable_data = {k: (list(v) if isinstance(v, set) else v) for k, v in doc_data.items()}with open(output_path, 'w', encoding='utf-8') as f:json.dump(serializable_data, f, ensure_ascii=False, indent=2)print(f"\n✅ 文档数据已保存到: {output_path}")print("\n🎉 步骤 1 完成!飞书文档 blocks 读取成功。")print("下一步:王小波风格改写")
步骤5:加载 wang-xiaobo-perspective skill,逐段改写风格
这一步,是让整个流程有意思的关键。前面那些步骤,都是枯燥的机械活。但这一步,是风格的事。
流程是这样的:
飞书文档链接 ↓① 读取飞书文档(blocks API)→ 保存 workspace/raw_content.json + workspace/task.json ↓② Agent 加载 wang-xiaobo-perspective skill,逐段改写风格 ↓③ 改写结果保存为 workspace/rewritten_content.json,更新 task.json status ↓④ 脚本读取改写内容 → 生成微信 HTML → 上传配图 → 创建草稿 ↓返回草稿链接这个操作 SOP 已经固化在新 Skill 的 SKILL.md 里了。后续改写,就按这个流程走。不用每次重新发明轮子。
步骤6:保存改写后文本
改写后的内容保存到 rewritten_content.json。状态流转是这样的:
extract → status: "extracted" (raw_content.json 已生成)改写 → status: "rewriting" (Agent 在改写)改写完成 → status: "rewritten" (rewritten_content.json 已生成)publish → status: "published" (微信草稿已创建)
四个状态,清清楚楚。每一步该做什么,下一步该做什么,都在里面了。
步骤7:读取改写后文本,生成微信 HTML 排版
微信公众号 API 只接受 HTML 格式,不接受 Markdown。所以得把改写后的 JSON 转换成适合手机阅读的 HTML。这里给出核心代码的开头:
def generate_html_content(raw_content, image_urls, title, intro="", code_blocks=None, callouts=None, highlighted_texts=None, bold_texts=None, callout_content_lines=None, quote_blocks=None, quote_content_lines=None, headings=None, bullet_items=None, ordered_items=None, wechat_account_name="水滴新途"): """生成带 HTML 排版的文章内容""" if code_blocks is None: code_blocks = [] if callouts is None: callouts = [] if highlighted_texts is None: highlighted_texts = {} if bold_texts is None: bold_texts = set() if callout_content_lines is None: callout_content_lines = set() if quote_blocks is None: quote_blocks = [] if quote_content_lines is None: quote_content_lines = set() if bullet_items is None: bullet_items = [] if ordered_items is None: ordered_items = [] # 构建 heading 映射 heading_map = {h['text']: h['level'] for h in headings} if headings else {} # 构建代码块映射 code_block_map = {} for code in code_blocks: first_line = code.split('\n')[0].strip() if first_line: code_block_map[first_line] = code lines = raw_content.splitlines() if lines and lines[0].strip() == title: lines = lines[1:] if lines and '我是王练' in lines[0]: lines = lines[1:] image_iter = iter(image_urls) formatted_content = "" list_items = [] in_list = False code_lines = [] in_code = False code_block_mode = False
后面的代码很长,但道理不复杂:一行一行读,识别出标题、正文、列表、代码块、图片,然后给每种类型套上对应的 HTML 标签。
步骤8:下载飞书图片 → 上传到微信素材库 → 替换链接
这是最复杂的一步。但也是最不能跳过的一步。没有图片的文章,就像没有配料的菜——能吃,但没意思。
8.1 从飞书文档中获取图片下载链接
飞书 API 提供了获取图片的接口。我们要做的是:从已有的 blocks.json 中提取所有 image_token,然后调用获取下载 URL。
def download_and_convert_image(source, output_path):"""下载图片"""if source.startswith('http'):resp = requests.get(source)with open(output_path, 'wb') as f:f.write(resp.content)else:import shutilshutil.copy(source, output_path)return output_path
8.2 上传到公众号素材库
用前面下载到的图片,上传到公众号素材库,然后替换原文中的链接:
def upload_to_wechat_material(image_path, wechat_token, is_permanent=True):"""上传图片到微信素材库"""if is_permanent:url = f"https://api.weixin.qq.com/cgi-bin/material/add_material?access_token={wechat_token}&type=image"else:url = f"https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token={wechat_token}"with open(image_path, 'rb') as f:resp = requests.post(url, files={'media': (os.path.basename(image_path), f, 'image/jpeg')})data = resp.json()if is_permanent:return data.get('media_id')else:return data.get('url')
步骤9:创建微信公众号草稿,返回草稿链接
最后一步。把排好版的 HTML 内容、标题、摘要、封面图,一起打包发给微信 API:
def create_draft(title, author, digest, content, cover_media_id, wechat_token):"""创建草稿"""url = f"https://api.weixin.qq.com/cgi-bin/draft/add?access_token={wechat_token}"payload = {"articles": [{"title": title,"author": author,"digest": digest,"content": content,"thumb_media_id": cover_media_id,"show_cover_pic": 1}]}payload_str = json.dumps(payload, ensure_ascii=False)headers = {"Content-Type": "application/json; charset=utf-8"}resp = requests.post(url, data=payload_str.encode('utf-8'), headers=headers)return resp.json()
完成后的Skill目录长这样。
到这里,整个九步流程就跑通了。最终脚本的完整代码在 Skill 目录里,你可以直接拿去用。
第三部分:总结
走完这九步,我们当前可以做什么了?
• 一键处理:把任意飞书文档转换为公众号草稿
• 保留结构:标题、列表、代码块都会正确呈现在公众号文章中
• 风格改写:王小波的调调被注入每一段文字
• 图片保留:飞书图片会被自动下载并上传到微信素材库
九步看起来不少。但过程中每一步都可以交给 Hermes 完成,并且只需要配置一次。之后,一句话就能完成改写和发布,就像这样:
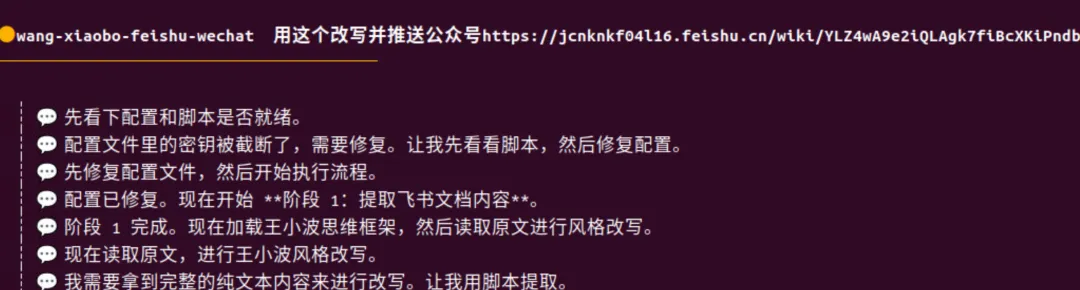
这就是 AI 自动化应该有的样子。
不是替我们思考,是替我们干那些重复的、枯燥的、本该机器干的活儿。省下来的时间,我们可以去想明白些道理,遇见些有趣的事。
下一篇,我们让王小波更强大、更自动化。
📬 互动话题
你有哪些需要AI自动化的工作流吗?
欢迎在评论区留言!👇
- End -
作者:王练 | 公众号:水滴新途
