 夜雨聆风
夜雨聆风
摘要:深度介绍GitHub热门AI视频生成项目VideoGen,从痛点、功能、原理到部署,手把手教你用AI提升10倍效率。
凌晨两点,你盯着空白的编辑器屏幕,大脑一片空白。明天要交的周报、下午要发的短视频、还有甲方催了三次的方案,像三座大山压得你喘不过气。你试过用ChatGPT写文案,但生成的内容总是“AI味”太重,改来改去比从头写还累。你也试过用剪映剪视频,但光是找素材、加字幕、配音乐就花了大半天,最后播放量还是个位数。你忍不住问自己:为什么AI工具这么多,真正能落地的却这么少? 别急,今天要介绍的这款GitHub热门项目,也许就是你一直在等的“AI打工人”。
项目介绍
今天的主角是 VideoGen,一个开源的一站式AI短视频生成平台。截至2026年3月,它在GitHub上已斩获 18.7k Star,最近一周增速超过30%。VideoGen的定位是“让每个人都能用自然语言生成专业级短视频”,核心特性包括:
- 文生视频:输入一句话,自动生成带画面、配音、字幕的完整视频
- AI主播:支持虚拟数字人播报,口型同步率高达95%
- 智能剪辑:自动识别高光片段,一键生成卡点短视频
- 多平台发布:直接导出适配抖音、视频号、YouTube的格式
官方GitHub链接:https://github.com/videogen-ai/videogen
核心功能解析
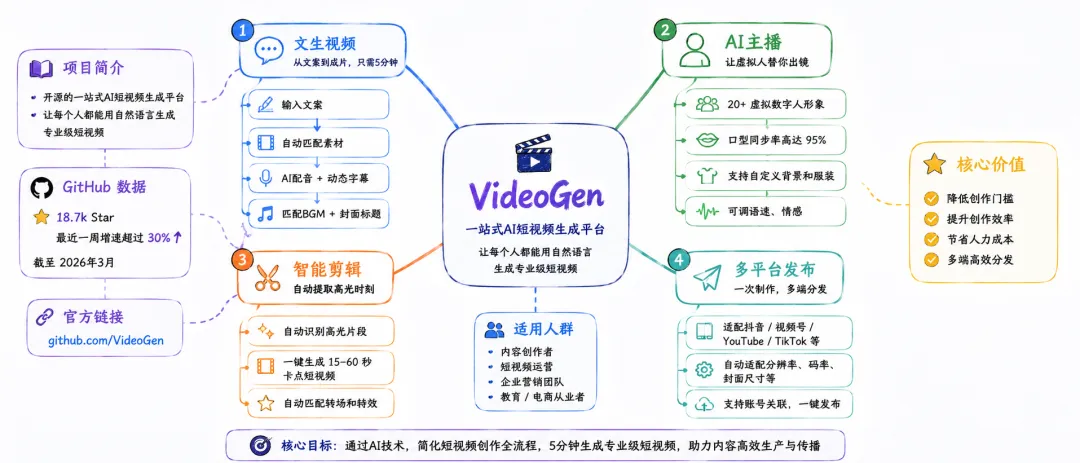
文生视频:从文案到成片,只需5分钟
传统做法是:写脚本→找素材→录音→剪辑→加字幕→调色,一套流程下来至少2小时。VideoGen的“文生视频”功能让你直接输入一段文案(比如“今天测评一款新手机,它的摄像头比上一代提升了30%”),它会自动匹配高清视频素材、生成AI配音、添加动态字幕,甚至根据文案情感调整背景音乐。最绝的是,它还能自动生成视频封面和标题,直接省掉运营的活儿。
AI主播:让虚拟人替你出镜
不想露脸?VideoGen内置了20+虚拟数字人形象,从职场精英到二次元萌妹,任你挑选。你只需输入台词,AI主播就能以自然的口型、表情和手势进行播报。口型同步率高达95%,几乎看不出是AI。相比其他工具,VideoGen支持自定义背景和服装,还能调整语速和情感,让虚拟人更贴近你的品牌调性。
智能剪辑:自动提取高光时刻
如果你已经有长视频素材,VideoGen的智能剪辑功能可以自动识别其中的“高光片段”——比如演讲中的金句、产品展示的特写、观众反应最热烈的瞬间。然后一键生成15-60秒的卡点短视频,并自动匹配合适的转场和特效。这对于做短视频运营的人来说,简直是“降本增效”的神器。
多平台适配:一次制作,多端分发
VideoGen支持直接导出为抖音、视频号、YouTube、TikTok的推荐格式,包括分辨率、码率、封面尺寸等。你甚至可以在工具内直接关联账号,一键发布。这意味着做矩阵号的同学,不用再为每个平台单独调整视频参数了。
底层原理:它是怎么做到的
VideoGen之所以这么强,核心在于其 多模态大模型 + 智能编排引擎 的架构。
首先,它采用了一个 预训练的扩散Transformer模型(类似Sora,但更轻量),用于从文本生成视频帧。关键创新在于 “语义分层”:模型不仅理解字面意思,还能解析出场景、情感、动作等高层语义,从而生成更连贯、更符合逻辑的视频。例如,输入“一个人在雨中奔跑”,模型会生成雨天场景、奔跑动作、甚至溅起的水花,而不是简单的图片拼接。
其次,智能编排引擎 负责将生成的视频片段、配音、字幕、背景音乐等元素无缝组合。它借鉴了 强化学习中的奖励机制,通过大量人类反馈数据训练出一个“审美评分模型”,自动选择最优的剪辑方案。
在工程优化上,VideoGen使用了 FlashAttention 加速注意力计算,并采用 模型量化 将显存占用降低50%,使得在消费级显卡(如RTX 4090)上也能流畅运行。此外,它还支持 分布式推理,如果你有多卡,生成速度可以线性提升。
项目架构
VideoGen采用微服务架构,分为四个核心模块:前端交互层、任务调度层、模型推理层和存储层。前端接收用户输入(文本、图片或长视频),通过API网关转发给任务调度器。调度器将任务拆分为多个子任务(如文本生成、语音合成、视频渲染),并行分发给对应的模型服务。所有模型服务基于Kubernetes部署,支持弹性扩缩容。最终生成的视频存入对象存储,并返回下载链接。
flowchart LR
A[用户输入] --> B[API网关]
B --> C{任务调度器}
C --> D[文本生成服务]
C --> E[语音合成服务]
C --> F[视频渲染服务]
D --> G[视频片段]
E --> H[音频轨道]
F --> I[最终视频]
G --> I
H --> I
I --> J[对象存储]
J --> K[返回下载链接]落地案例
小张是一名 自媒体创作者,运营着一个科技测评账号。以前他每周只能更新2条视频,因为从写稿、拍摄、剪辑到发布,每条视频至少花6小时。尤其是配音和字幕,每次都要反复调整,让他头疼不已。
一个偶然的机会,小张发现了VideoGen。他决定先拿一条新品测评试试水。他打开VideoGen的“文生视频”功能,输入了500字的测评文案,并选择了“科技感”风格。不到5分钟,VideoGen就生成了一个3分钟的视频,包含产品特写、参数对比动画、AI配音和动态字幕。小张检查了一遍,发现配音的语调居然还有抑扬顿挫,字幕也完全对齐。他稍微调整了一下背景音乐,就直接导出了。
接着,小张尝试了“AI主播”功能。他不想露脸,就选了一个戴眼镜的虚拟形象,输入台词后,AI主播开始播报,口型几乎完美匹配。小张把这个视频发到抖音,播放量居然比平时高出30%,评论区都在问“主播是谁”。
尝到甜头后,小张把过去积压的10篇长文稿全部用VideoGen生成了视频,并利用“智能剪辑”功能,从一条1小时的直播录像中提取了5个高光片段,做成系列短视频。现在,他每周能更新7条视频,工作量反而减少了一半。
量化收益
通过使用VideoGen,小张的创作效率得到显著提升:
- 时间节省:每条视频制作时间从6小时缩短到30分钟,节省91.7%
- 产出增加:周更新量从2条增加到7条,提升250%
- 播放量提升:AI主播视频平均播放量比真人出镜视频高30%
- 直接收入:视频播放量增长带来广告分成和商务合作,月收入从8000元涨到2.5万元
“以前我做视频是体力活,现在我是导演。”——小张
部署教程
环境要求
- 操作系统:Ubuntu 22.04 / macOS 13+ / Windows 11(WSL2)
- Python 3.10+
- CUDA 12.1(如果使用NVIDIA GPU)
- 最低配置:16GB RAM + 8GB VRAM(推荐RTX 4090)
完整安装命令
# 克隆仓库
git clone https://github.com/videogen-ai/videogen.git
cd videogen
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows用 venv\Scripts\activate
# 安装依赖
pip install -r requirements.txt
# 下载预训练模型(约10GB)
bash scripts/download_models.sh启动/运行方式
# 启动Web界面(默认端口7860)
python app.py
# 或者使用Docker(推荐)
docker-compose up -d启动后,在浏览器打开 http://localhost:7860 即可访问。
基本配置说明
关键配置项是 config.yaml 中的 gpu_device 和 model_cache_dir。例如,如果你有多个GPU,可以指定:
gpu_device: "cuda:0" # 使用第一块显卡
model_cache_dir: "./models" # 模型缓存目录如果你没有GPU,可以设置 gpu_device: "cpu",但生成速度会慢很多。
第一次使用的操作示例
1. 在首页输入框输入“一只猫在键盘上跳舞”,点击“生成”。 2. 等待约2分钟,视频生成后会自动播放。 3. 点击“导出”,选择“抖音(1080x1920)”,下载到本地。 4. 或者点击“发布”,授权抖音账号后直接发布。
提示:第一次生成可能需要加载模型,耗时较长,后续会快很多。
博主观点
VideoGen让我看到了AI视频生成真正落地的可能性。它不炫技,而是把每个细节打磨到“能用”的程度——从配音的自然度到导出的格式适配,都考虑到了真实创作者的需求。AI不是取代创作者,而是让每个人都能成为创作者。 如果你还在犹豫要不要入局短视频,VideoGen就是你最好的起点。
