 夜雨聆风
夜雨聆风大家好。
最近这段时间,我一直在折腾一件事:
能不能把一篇论文 PDF,直接变成一套可以拿去组会汇报的 PPT?
不是那种把 PDF 截图塞进幻灯片,也不是套一个很丑的模板,更不是只能看、不能改的图片版 PPT。
我想要的是:
• 能读论文、读 Figure、读截图和资料 • 能自动规划每一页 PPT 的内容 • 能生成比较像样的医学学术汇报风格 • 能保留原文里的 Figure、图表、影像和截图 • 最后还能导出文字可编辑的 PPTX
所以这次,我把这个工作流整理成了一个github开源项目:
yixueAIganhuo-PPT
一句话介绍就是:
一个把论文、PDF、Figure、截图、报告和自备资料自动制作成高质量 PPT,并进一步重建为可编辑 PPTX 的 AI PPT skill。
先看一个真实例子
下面这个案例,是把一篇 PMID 38133501 的原文 PDF 输入给 yixueAIganhuo-PPT 后,最终得到的可编辑 PPTX 效果。
大家可以左右滑动看完整页面效果。
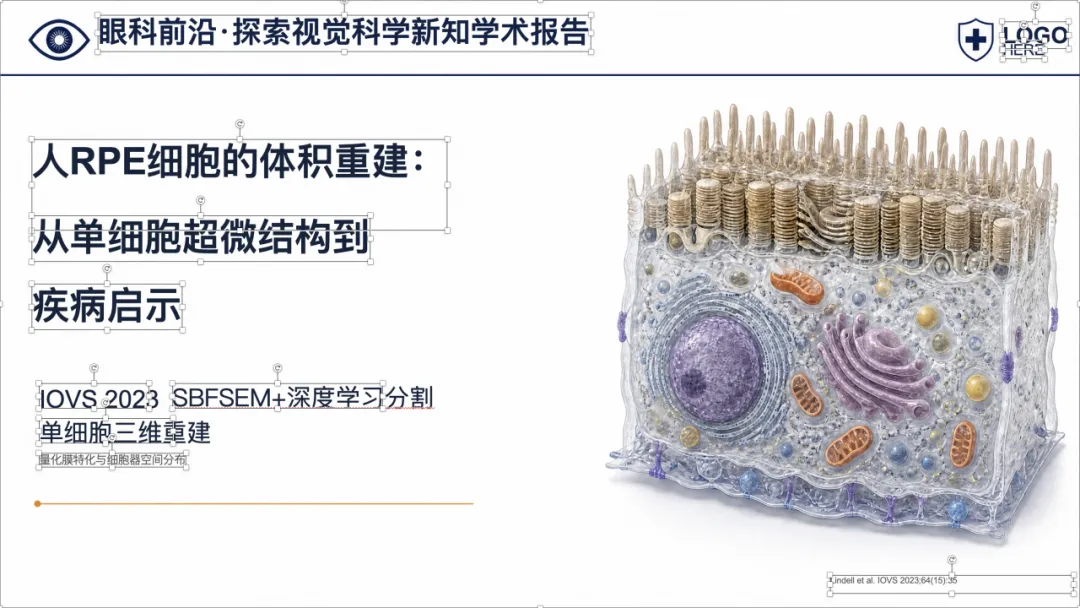
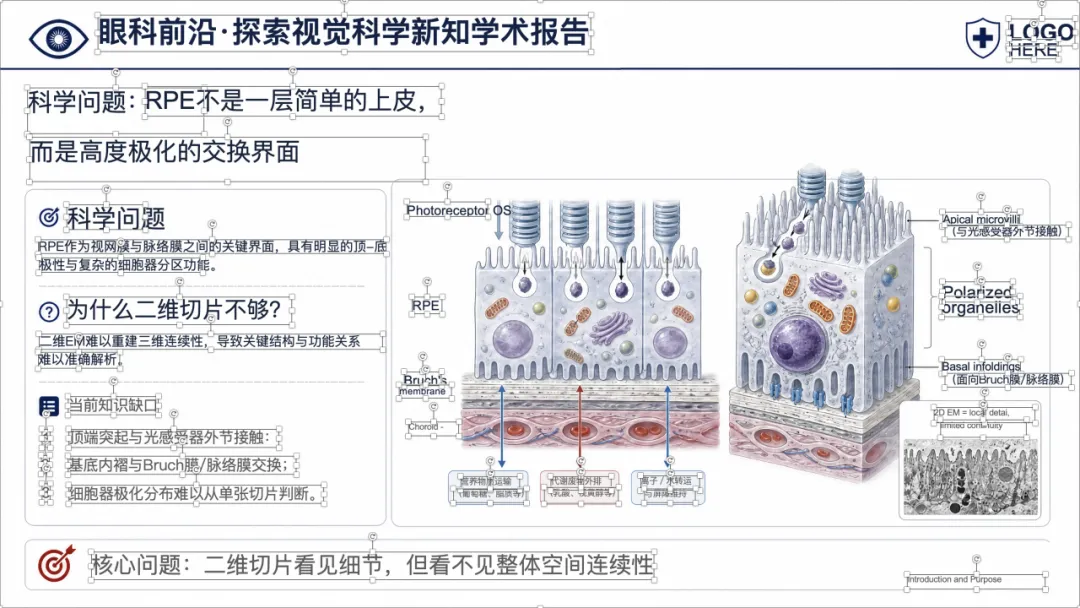
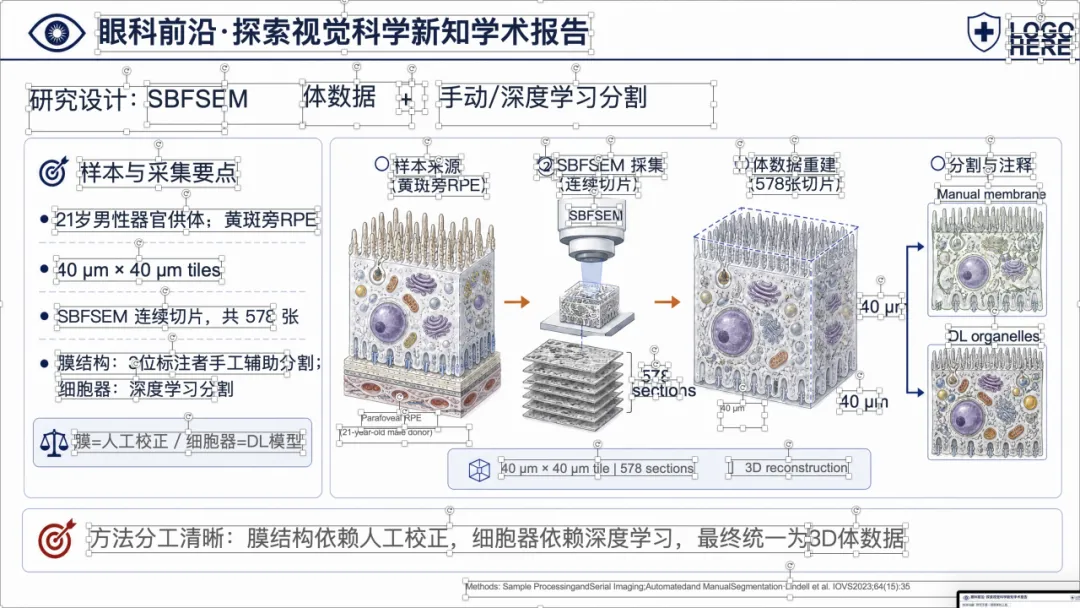
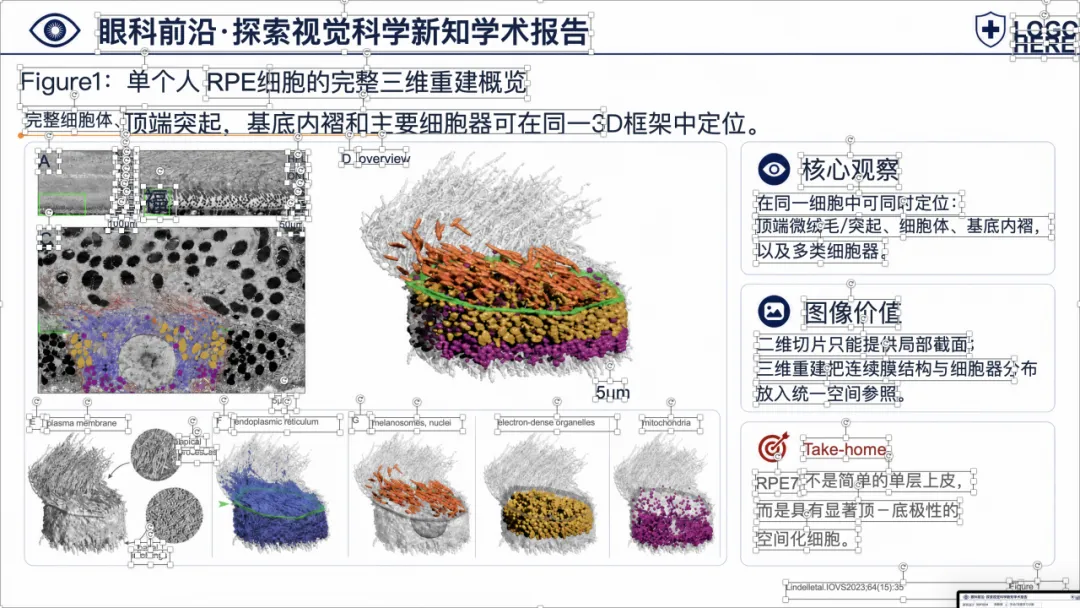
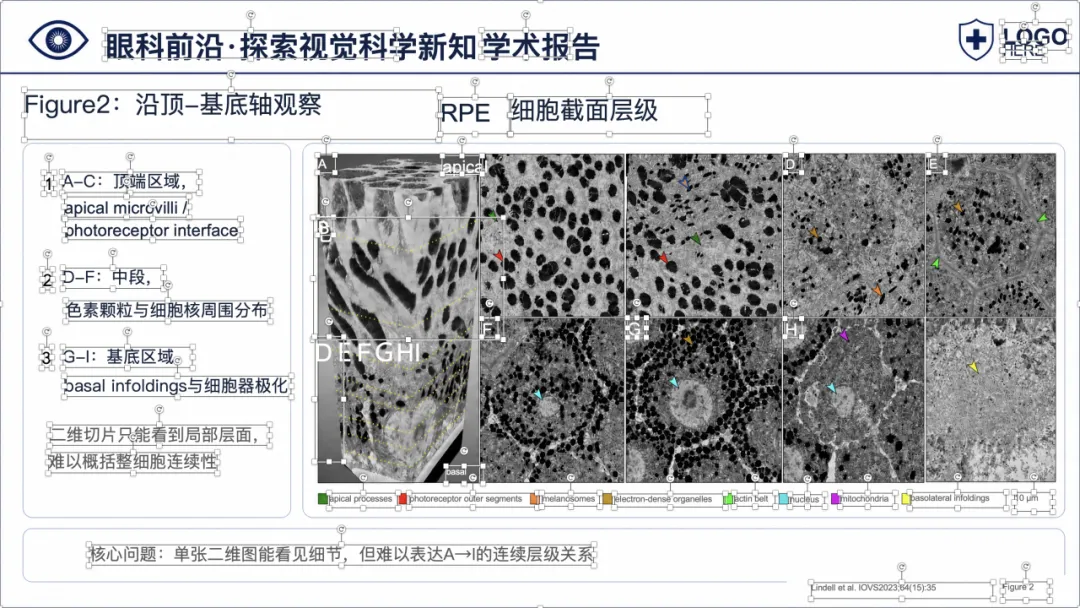
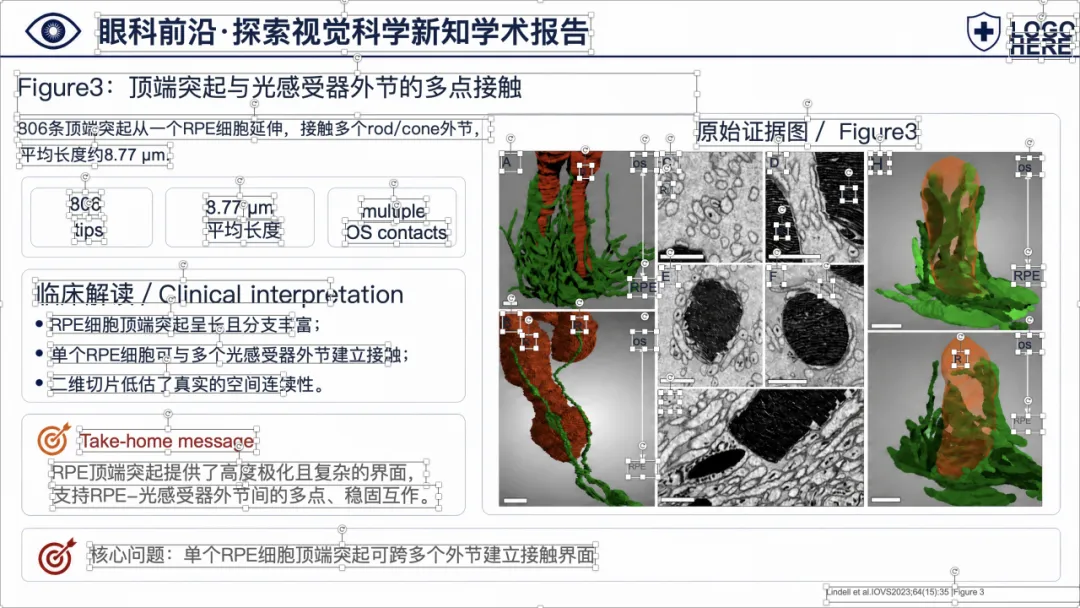
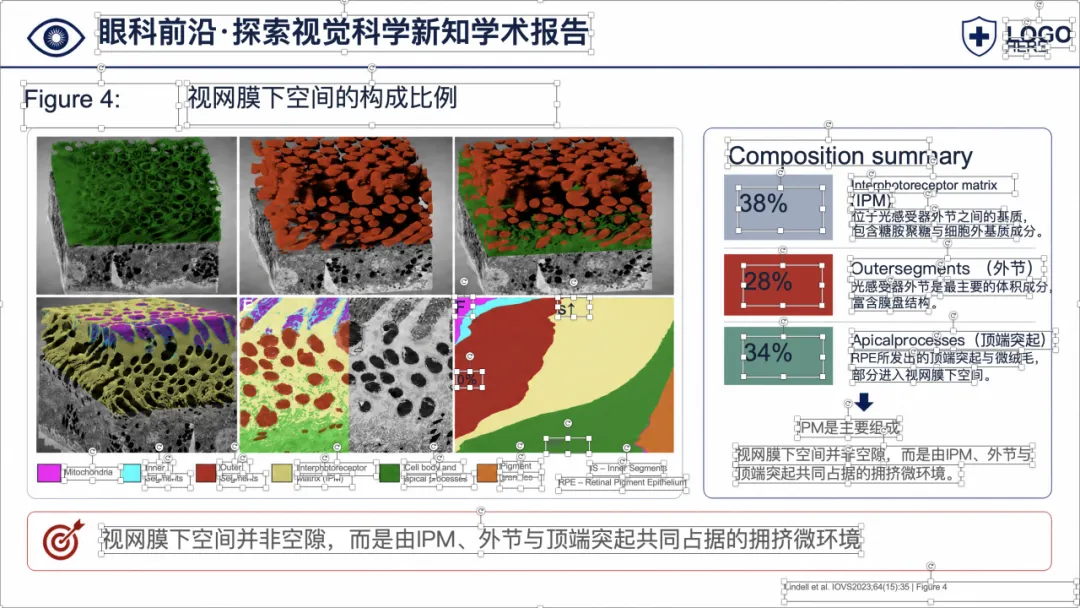
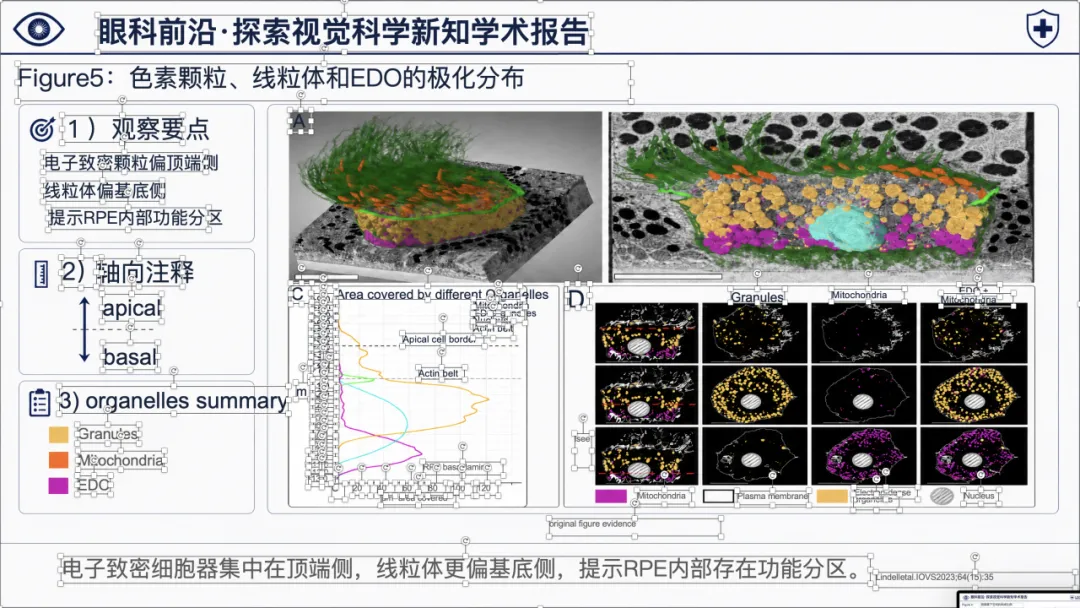
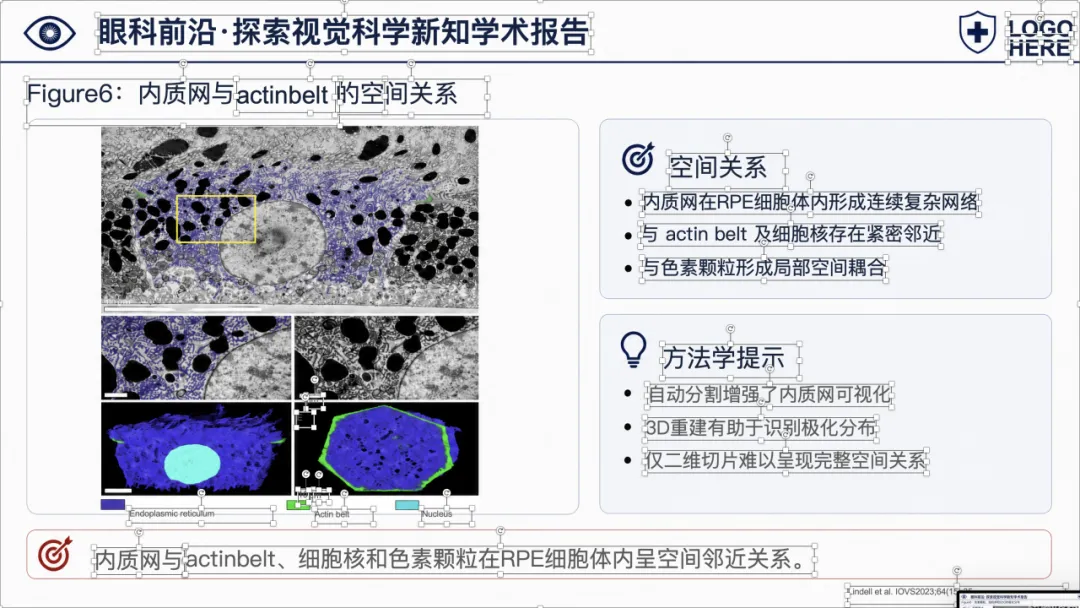
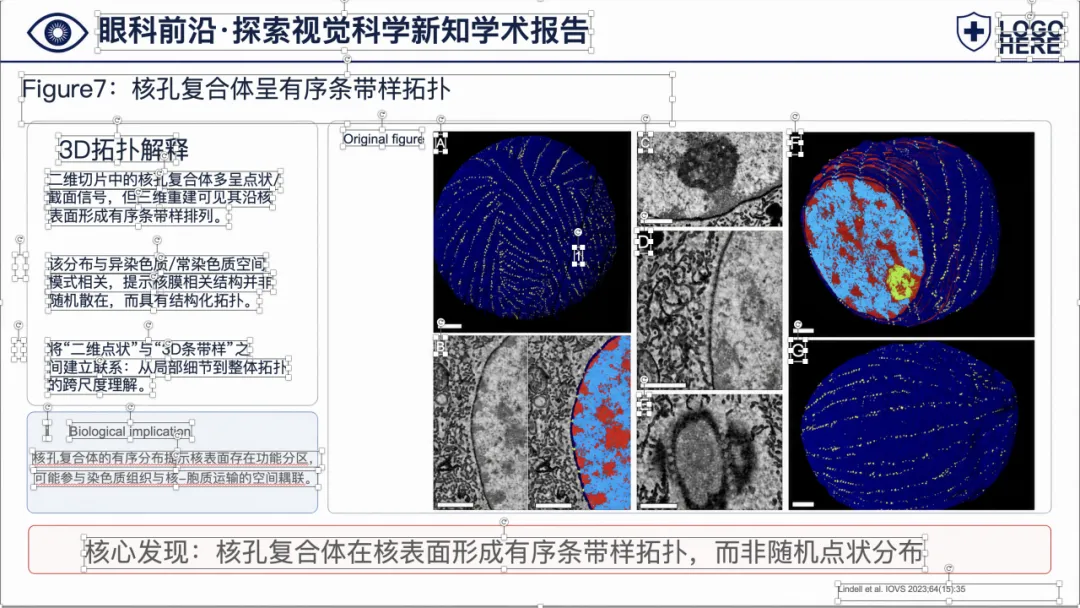
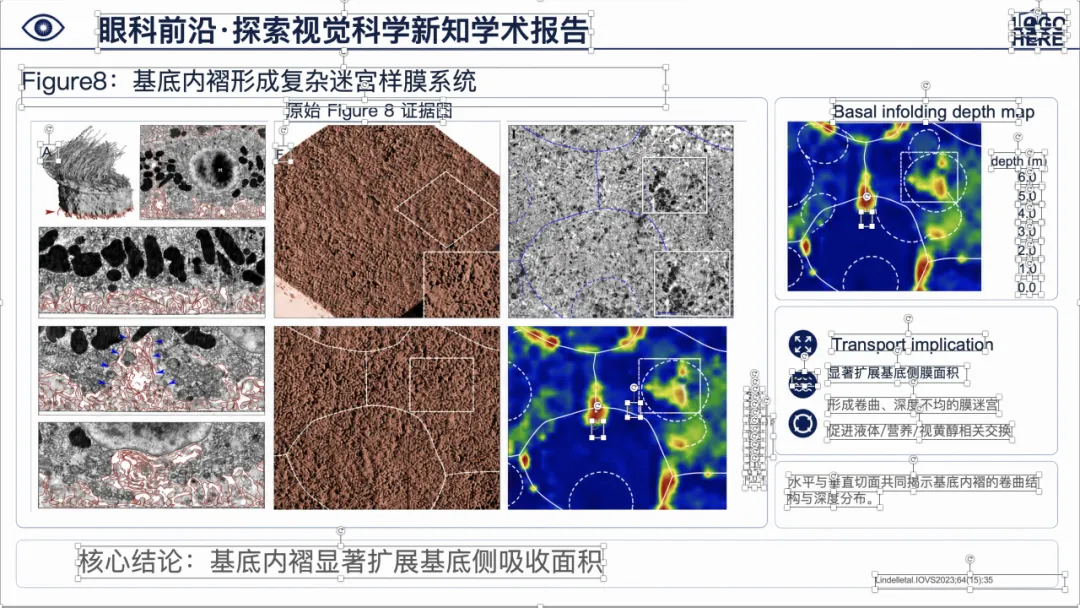
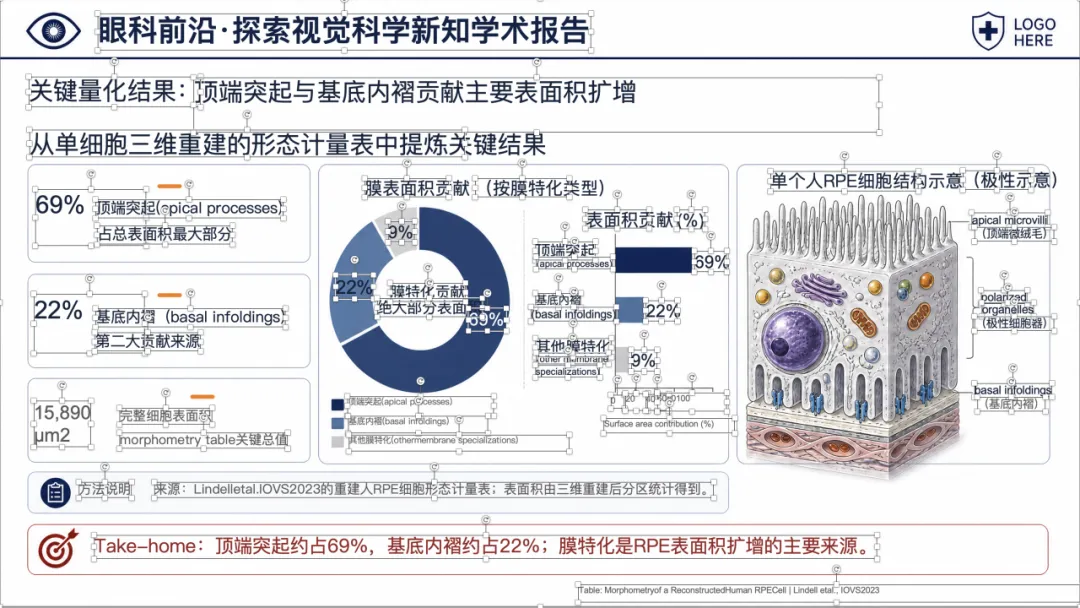
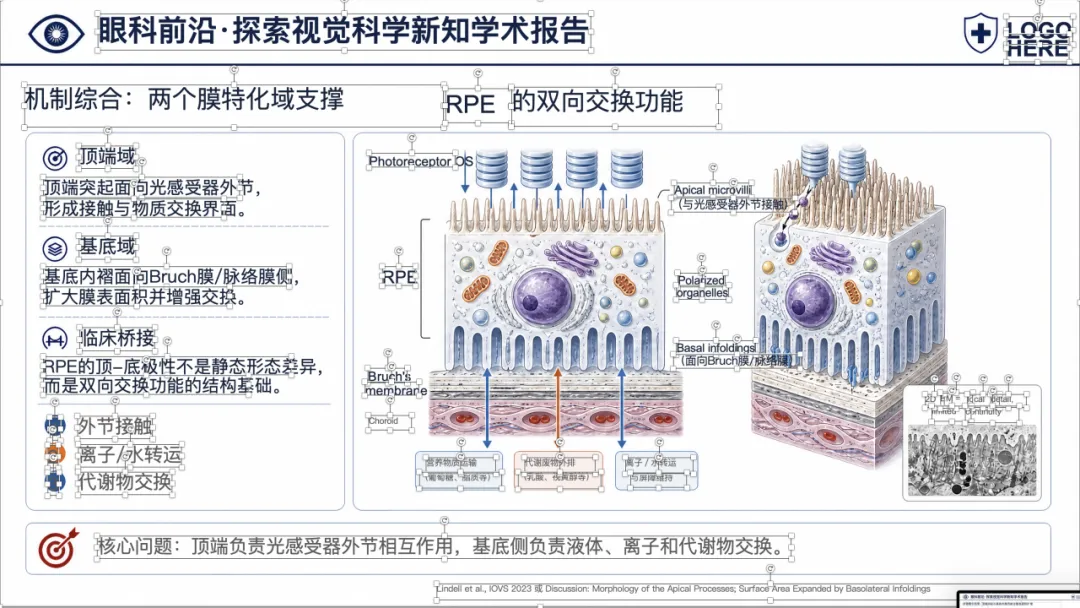
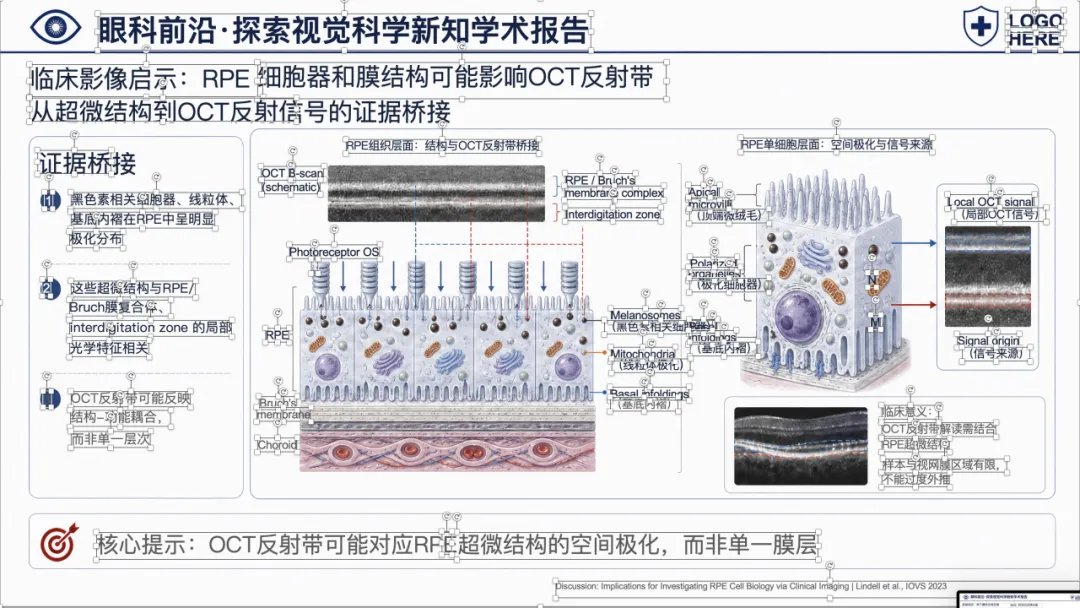
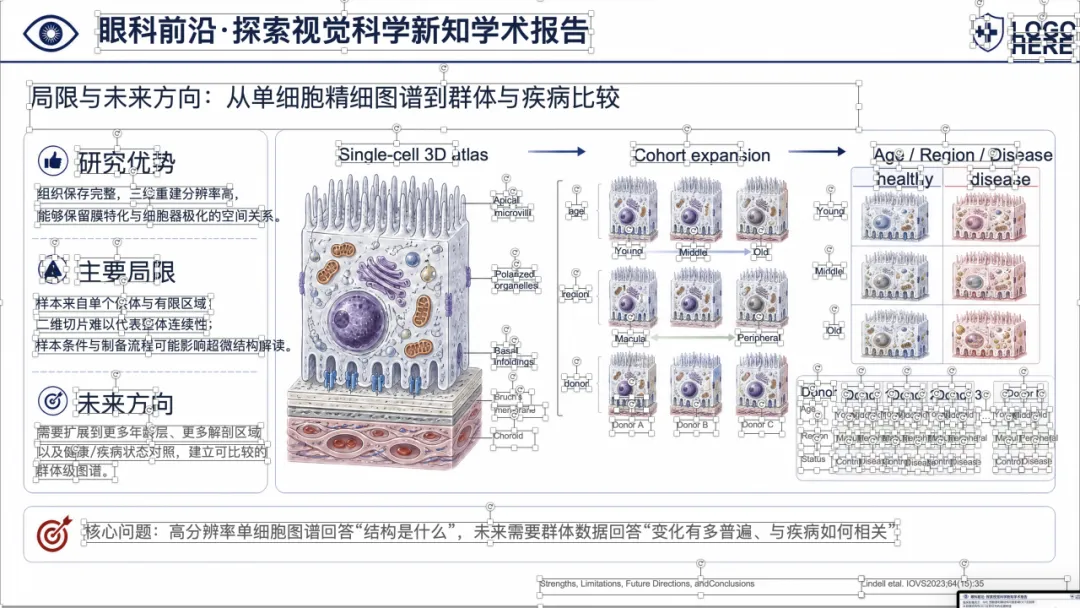
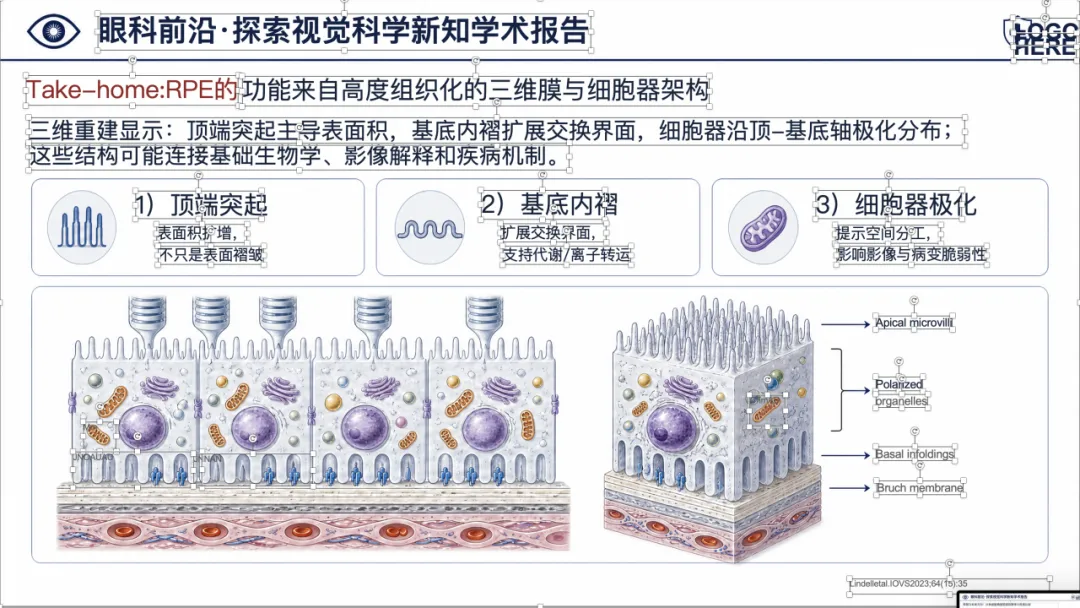
可以看到,整体样式已经比较接近正式的医学学术汇报 PPT,不是简单把论文截图塞进去。
更重要的是,这些页面里的文字也都尽量重建成了 PowerPoint 文本框,后面还可以继续编辑。
流程示例和原理
为了说明它是怎么从论文 PDF 走到最终可编辑 PPTX 的,这里放一张完整流程示例图。
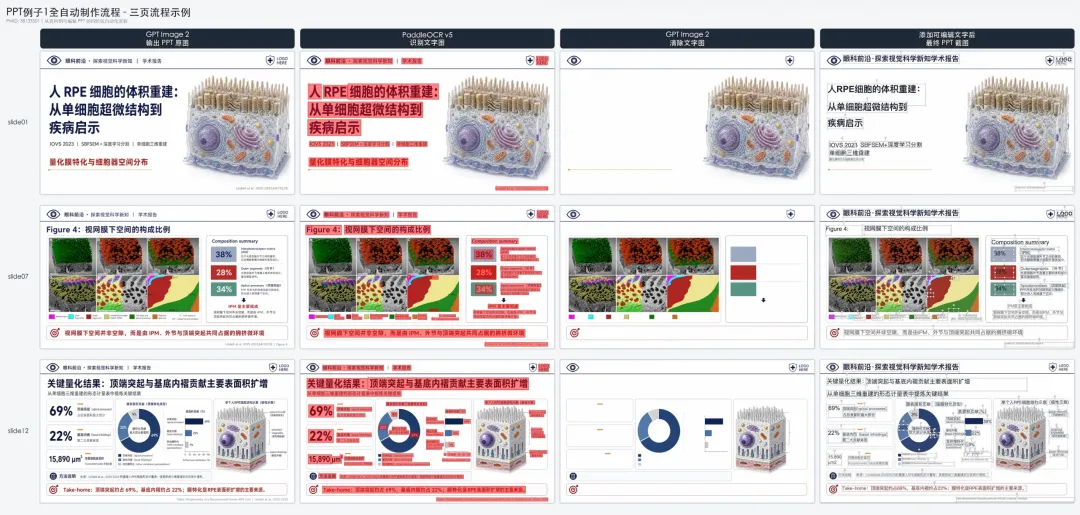
每一行从左到右分别是:
• GPT Image 2 生成的 PPT 原图 • PaddleOCR v5 识别文字 • GPT Image 2 清除原图中的文字背景 • 叠加可编辑文字层后的最终 PPT
也就是说,这个项目不是单纯“生成一张 PPT 图片”,而是多走了一步:
把图片型 PPT,尽量重建成可以继续编辑的 PPTX。
整个流程可以简单理解为:
资料理解 -> PPT 页面规划 -> GPT Image 2 生成图片型 PPT -> PaddleOCR v5 识别文字 -> GPT Image 2 清除文字背景 -> 添加可编辑文字层 -> 生成 editable PPTX项目里的原理图如下:
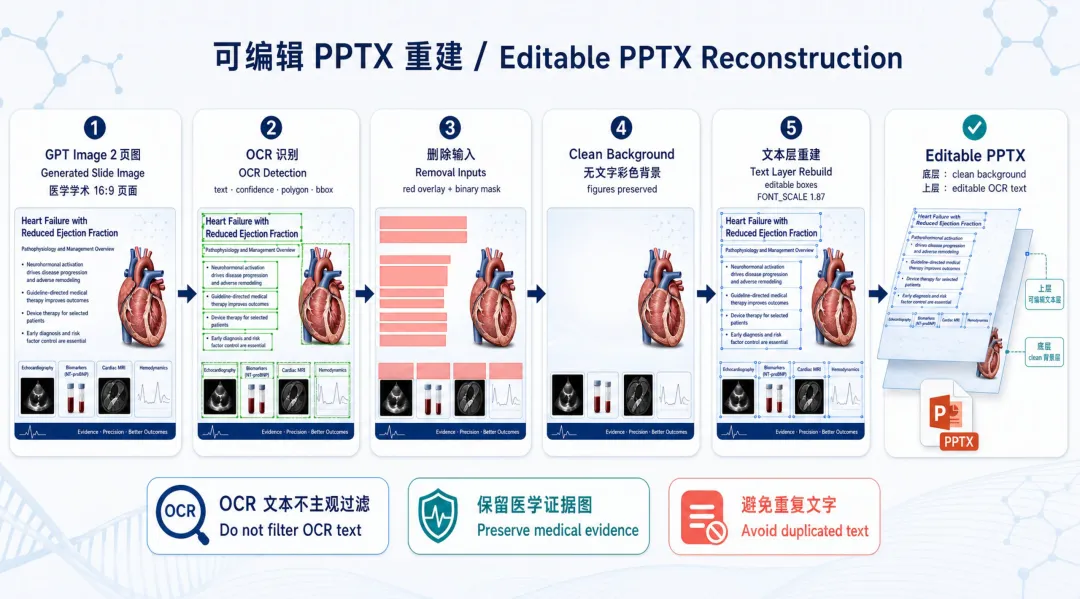
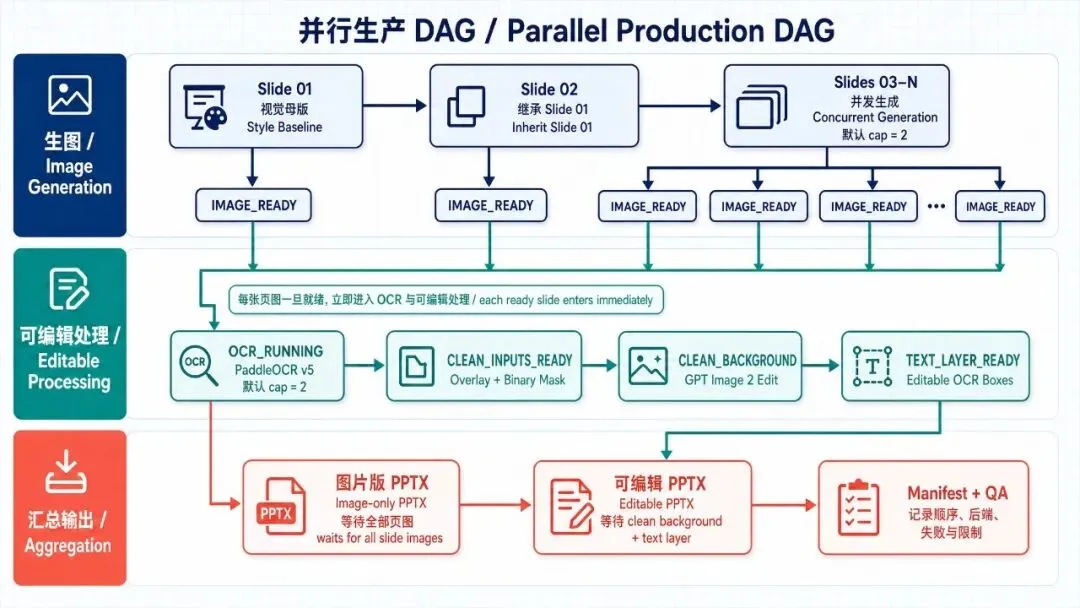
从功能上看,这个项目主要做了这几件事:
• 自动读取论文 PDF、Figure、截图和自备资料,规划 PPT 页面结构 • 用 GPT Image 2 生成 16:9 的图片型 PPT 页面 • 用 PaddleOCR v5 识别页面文字和位置 • 用 GPT Image 2 清除原图里的文字背景 • 把 OCR 识别出的文字重新放回 PowerPoint,生成可编辑文字层 • 原始 Figure、图表、影像和截图尽量按原始比例嵌入,不主动拉伸变形 • 可生成带演讲稿备注的 PPTX,方便后续准备汇报 • 支持本地 CLIProxyAPI、OpenRouter / OpenAI 兼容接口等 GPT Image 2 后端 • 支持本地 PaddleOCR v5,也支持 PaddleOCR API 方式
它适合哪些场景?
我自己最看重的是下面几个场景:
1. 论文精读汇报
比如 journal club、文献精读、课题组组会。输入论文 PDF,让它先帮你整理出一版可以讲的 PPT 初稿。
2. 课程资料整理
课程 PDF、讲义、截图、实验材料,也可以整理成教学或培训用 PPT。
3. 病例、报告和截图汇总
有些临床或科研汇报,不是完整论文,而是多份截图、检查结果、图表、文字说明混在一起。这类材料也可以先交给它整理成汇报框架。
4. 图片型 PPT 转可编辑 PPTX
如果你已经有了一套图片型 PPT,或者每页都是截图,也可以只走后半段流程,把“只能看”的 PPT 尽量转成“还能改文字”的 PPTX。
怎么使用?
这个项目本质上是一个给 Codex、Claude Code 或其他支持 skills 的 agent 使用的 skill。
安装时,可以直接把下面这段话复制给 agent:
请帮我安装 yixueAIganhuo-PPT skill。仓库地址:https://github.com/snowmanzhuang/yixueAIganhuo-PPT.git请保存到你当前可用的 skills 目录中,并且只拉取 skill 运行所需文件:SKILL.mdscripts/references/examples/requirements.txt不要下载 docs、README 展示图、示例 PDF 和示例 PPTX。安装好之后,使用时可以这样说:
请调用 yixueAIganhuo-PPT skill,把我提供的论文 PDF 做成文字可编辑的中文汇报 PPTX。也可以这样:
请调用 yixueAIganhuo-PPT skill,把这些课程资料和截图整理成一个适合课堂讲解的 PPTX。如果只想把已有图片型 PPT 转成可编辑版本,可以这样:
请调用 yixueAIganhuo-PPT skill,我已经有图片型 PPTX / 每页截图,只需要帮我转成可编辑 PPTX。如果你暂时不想跑 OCR,也可以只生成图片版:
请调用 yixueAIganhuo-PPT skill,只生成图片型 PPTX,不需要转成可编辑 PPTX。使用前一定要注意
这个项目不是点一下就百分百完美出片的“一键神器”。
第一次使用时,我建议务必先小规模测试:
• 先做 3-5 页,不要一上来跑 20 页以上 • 先确认 GPT Image 2 后端能正常生成 16:9 图片 • 先确认 PaddleOCR v5 或 OCR API 能正常返回文字坐标 • 网络不稳定或 API 限流时,先把并发调低 • 最终可编辑 PPTX 里的文字位置、字号、换行,仍然可能需要手动微调
尤其是可编辑 PPTX 这一步,本质上是把 OCR 坐标重建成 PowerPoint 文本框,不可能做到每个字都和原图完全重合。
我的目标不是替代你最后的人工检查,而是把最耗时间的 70%-80% 先自动跑出来。
API 和环境怎么选?
图像生成这块,推荐优先使用支持 GPT Image 2 的后端。
如果你是OpenAI订阅会员,并且能稳定使用 GPT Image 2,建议通过本地搭建 CLIProxyAPI来反代api调用GPT Image 2,这样可以不额外增加任何费用(详情请看 https://github.com/router-for-me/CLIProxyAPI)。
如果没有CLIProxyAPI,也可以使用 OpenRouter 或 OpenAI API 这类方式,但费用和稳定性要自己评估。
OCR 这块,如果电脑配置不错,推荐本地部署 PaddleOCR v5。电脑配置一般或者不想折腾本地部署的话,也可以走 PaddleOCR API。 (详情请看 https://github.com/snowmanzhuang/yixueAIganhuo-PPT/blob/main/docs/setup/paddleocr.zh.md)
第一次配置会稍微麻烦一点,尤其是 PaddleOCR 的本地环境、模型下载和 Python 路径。但只要第一次跑通,后面就会顺很多。
再放 3 个例子
大家同样可以左右滑动查看每个案例的完整页面效果。
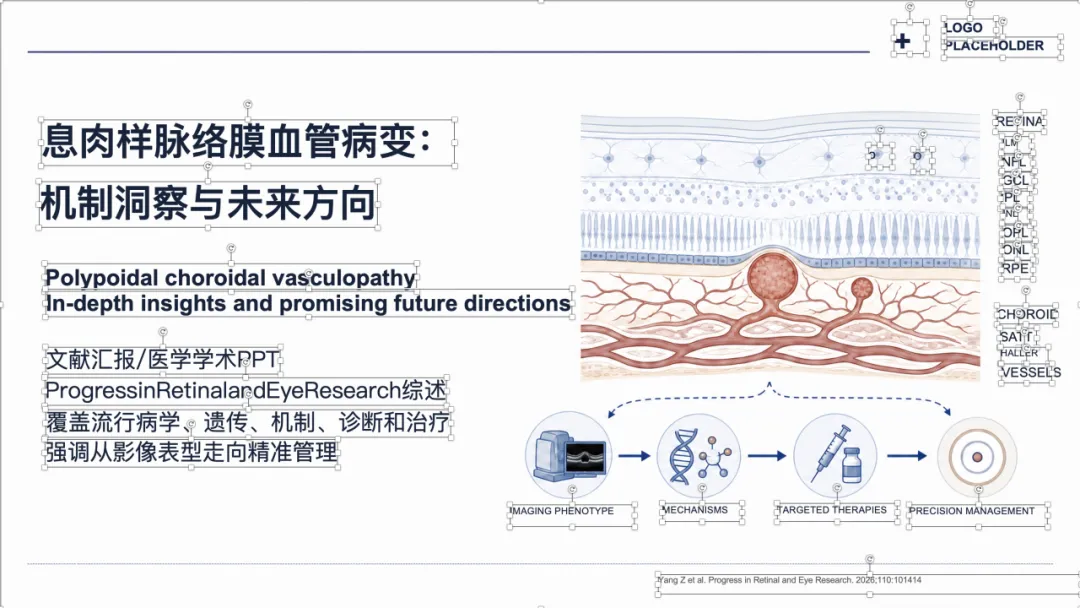
例子 2:PMID 41232598 最终可编辑 PPT 效果
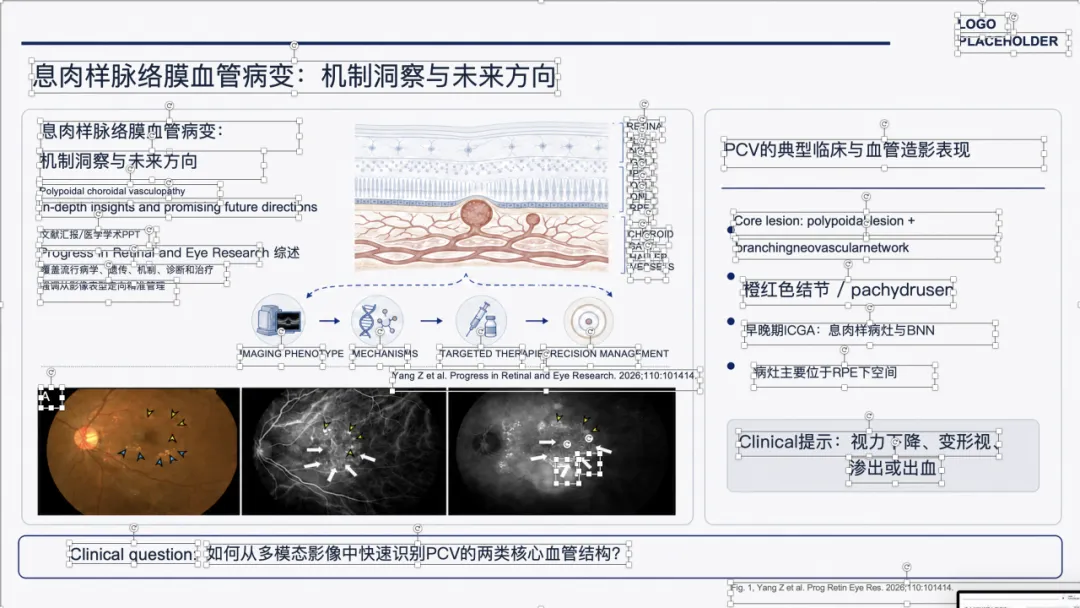
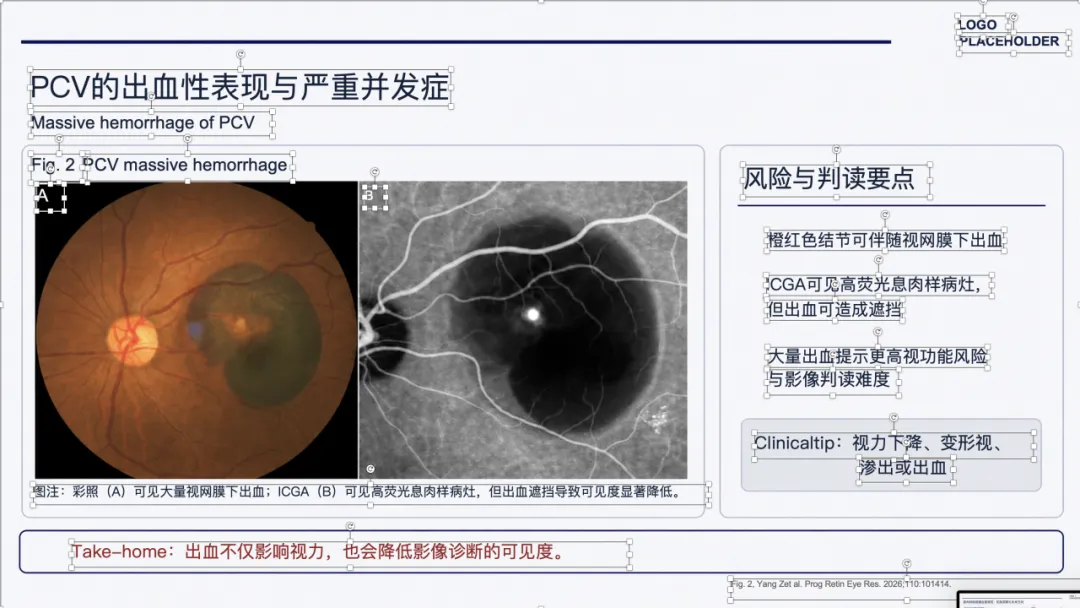
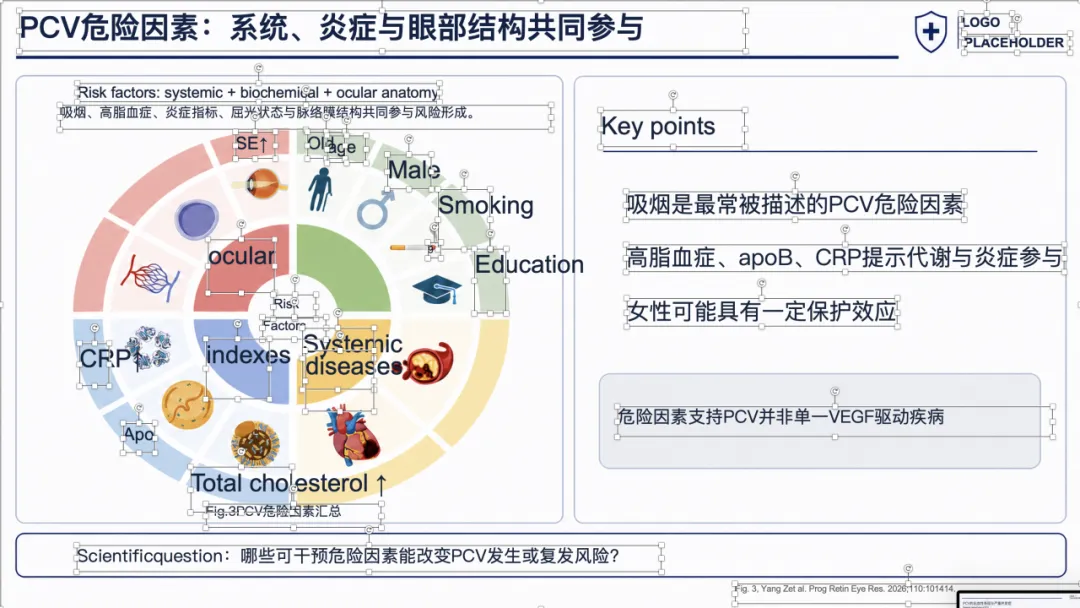
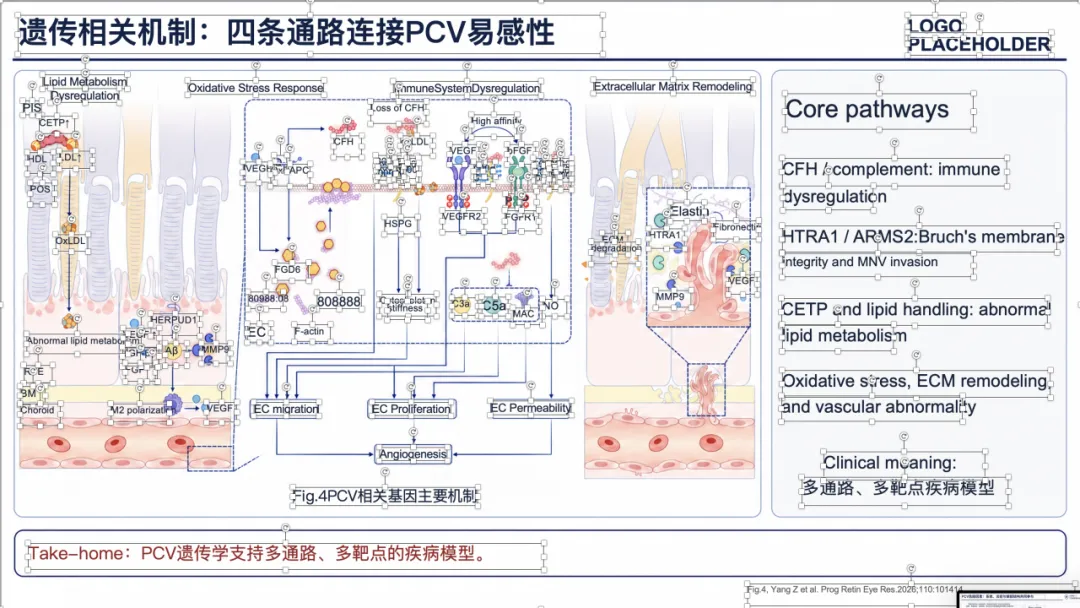
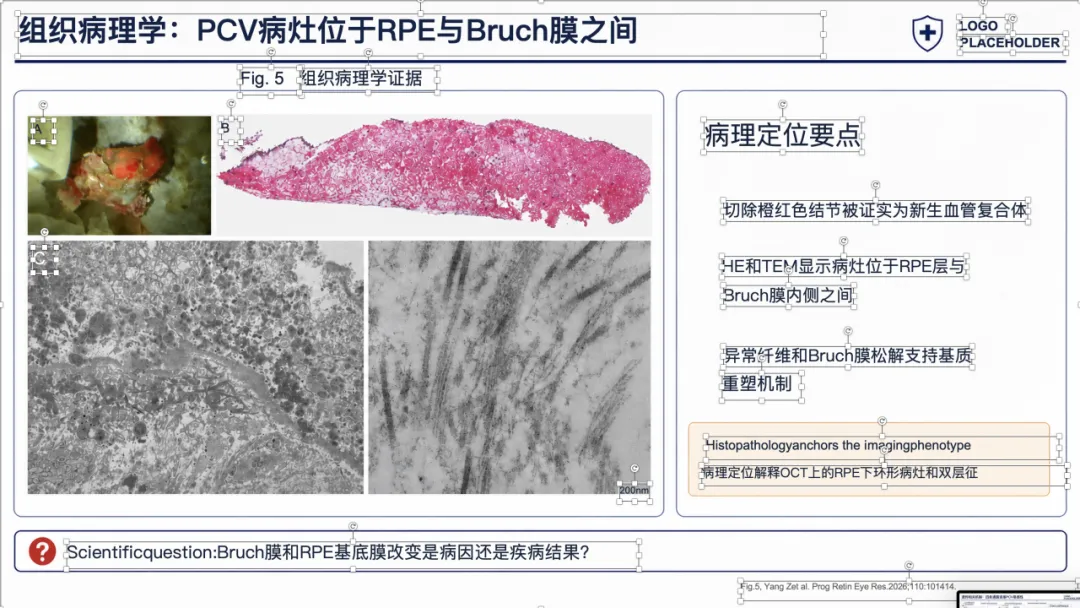
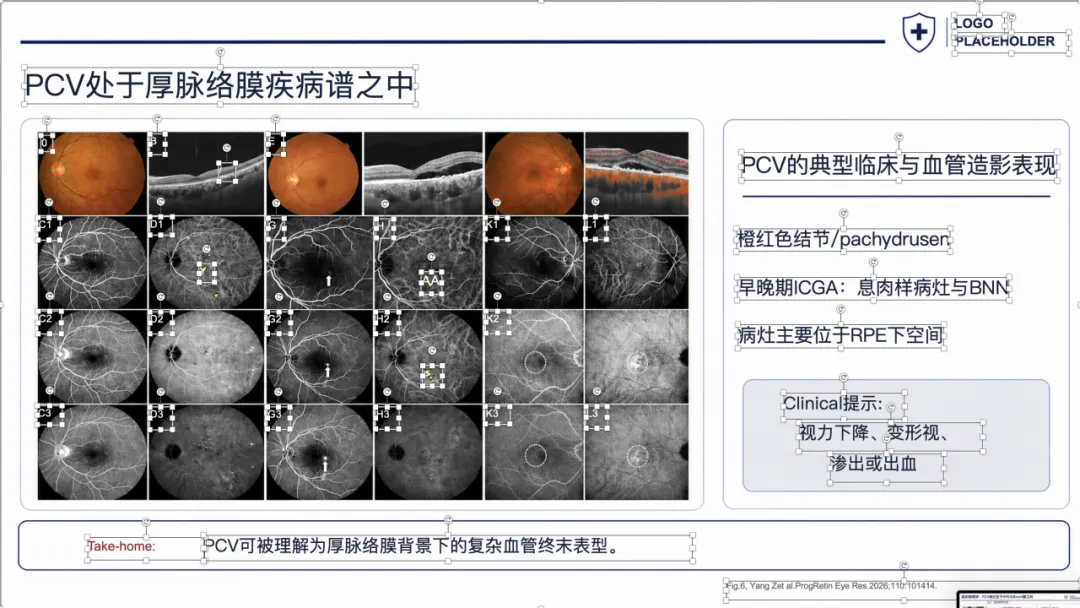
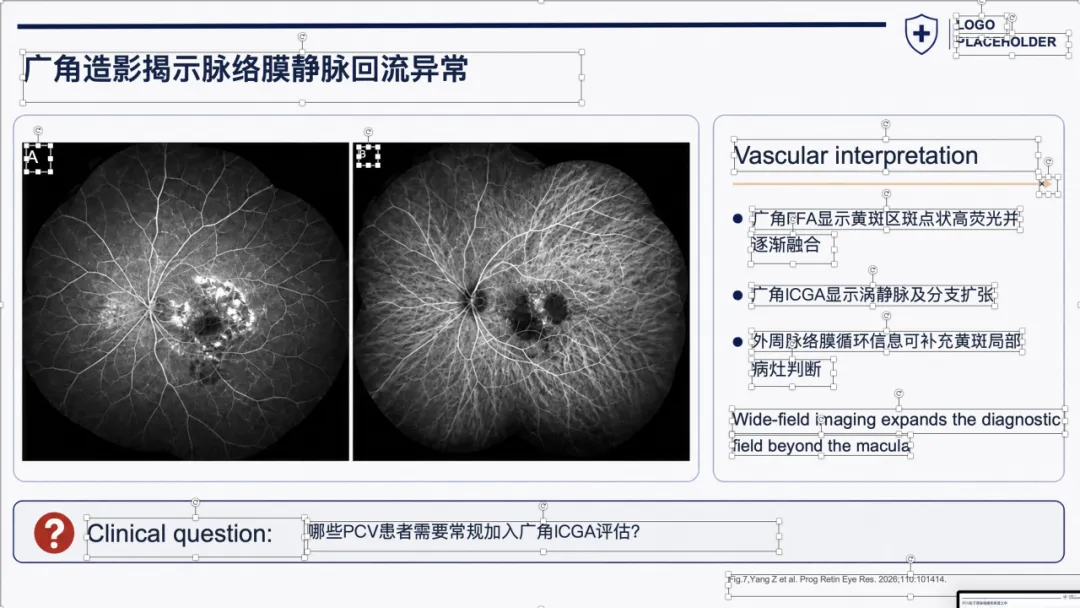
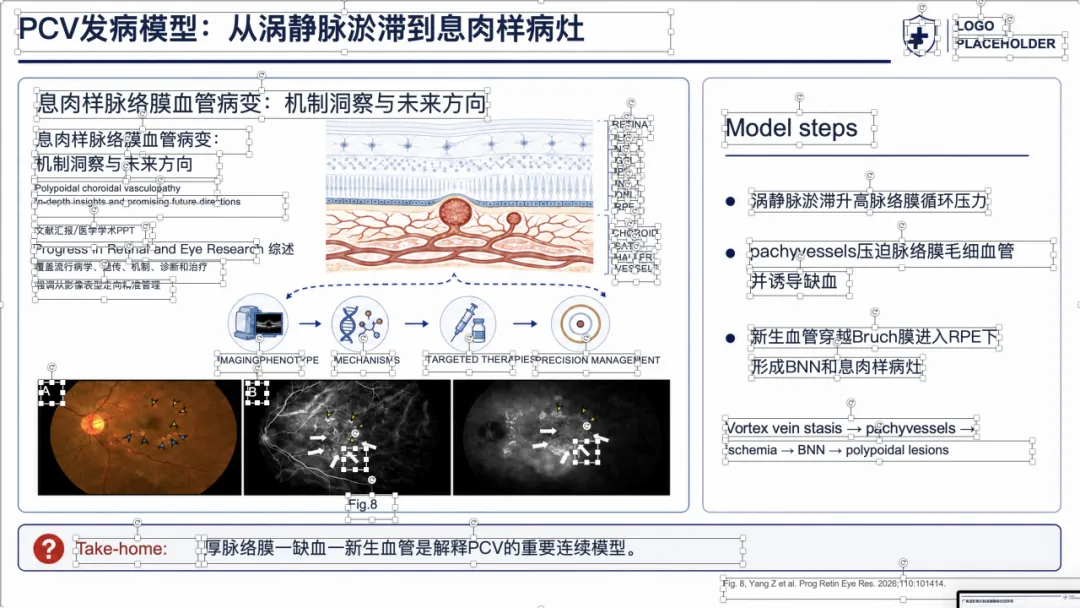
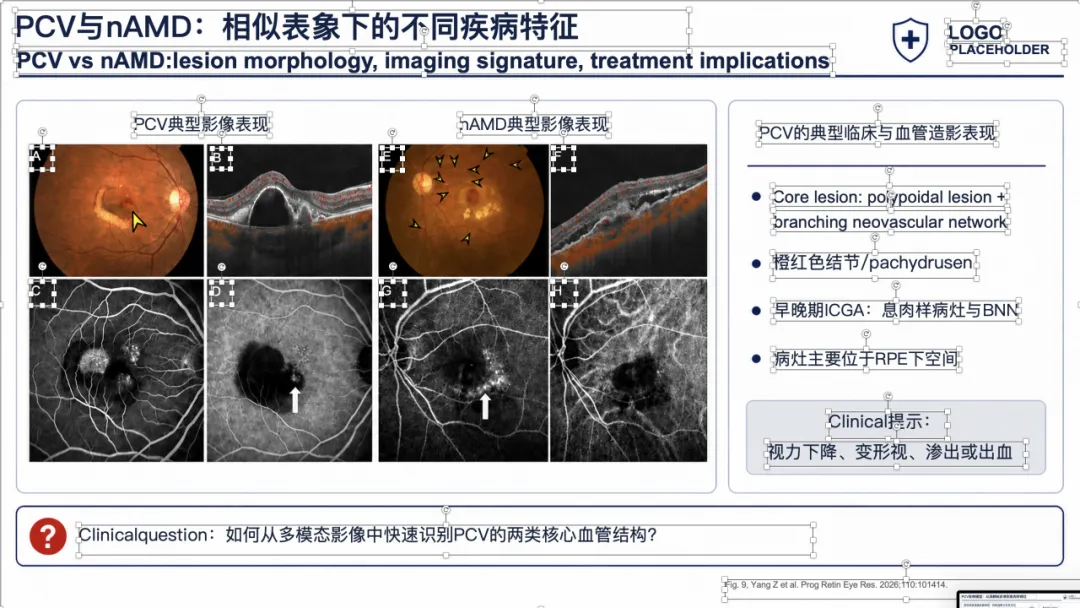
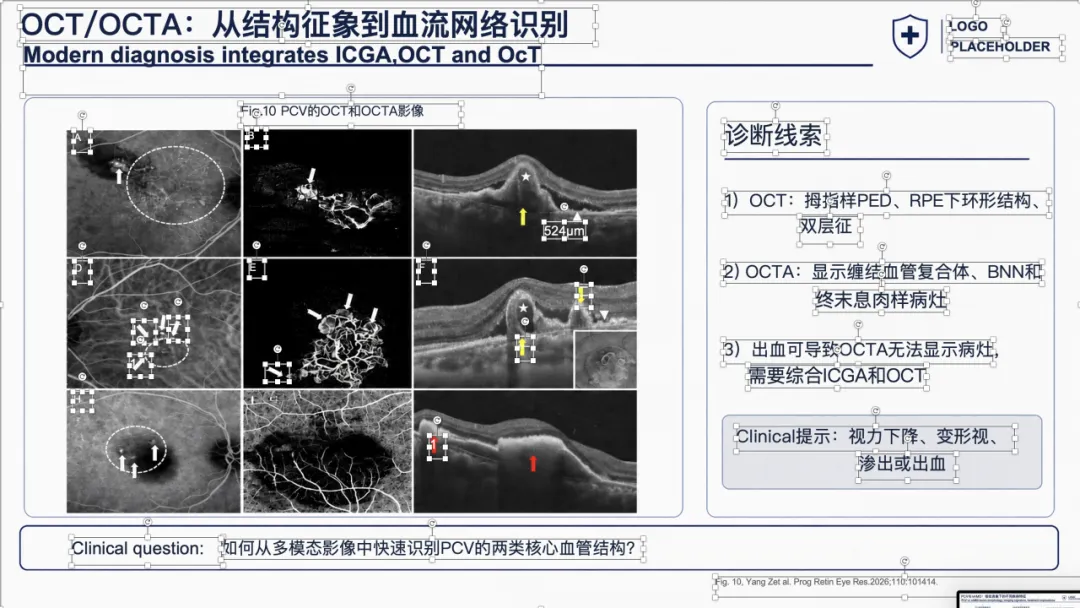
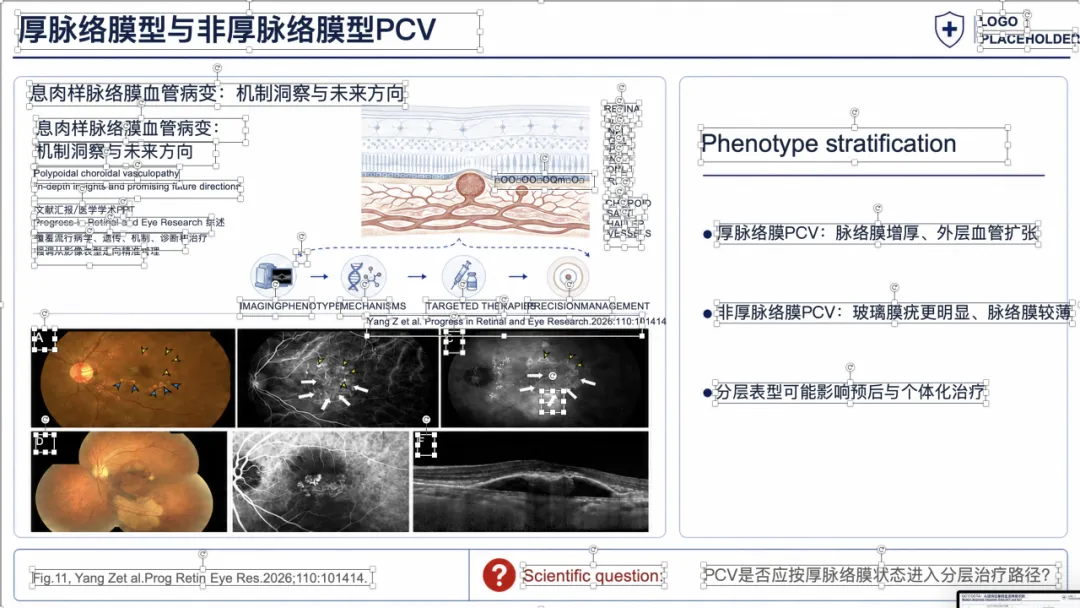
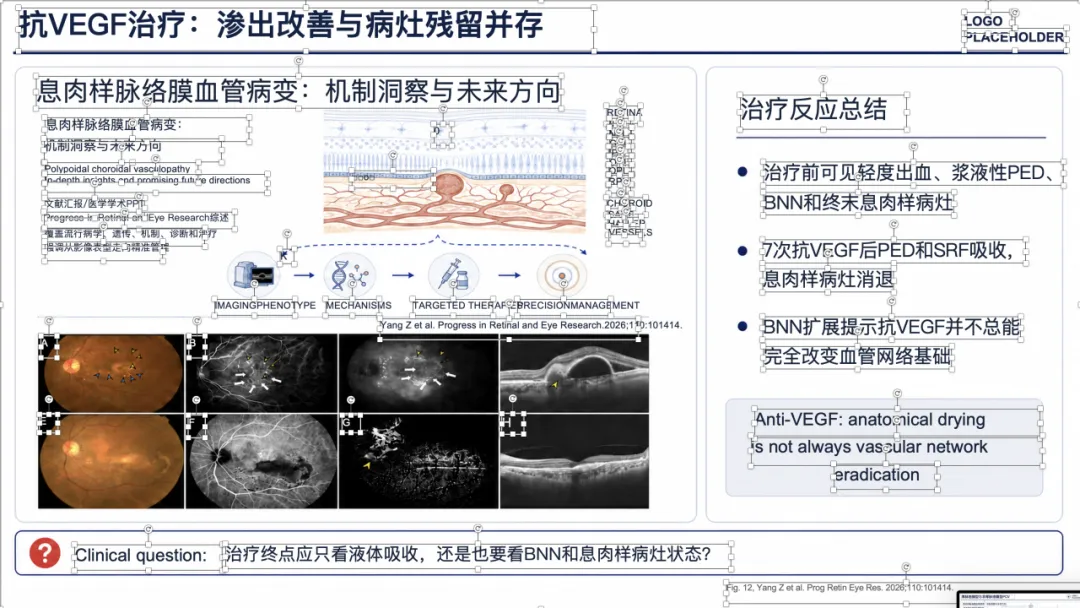
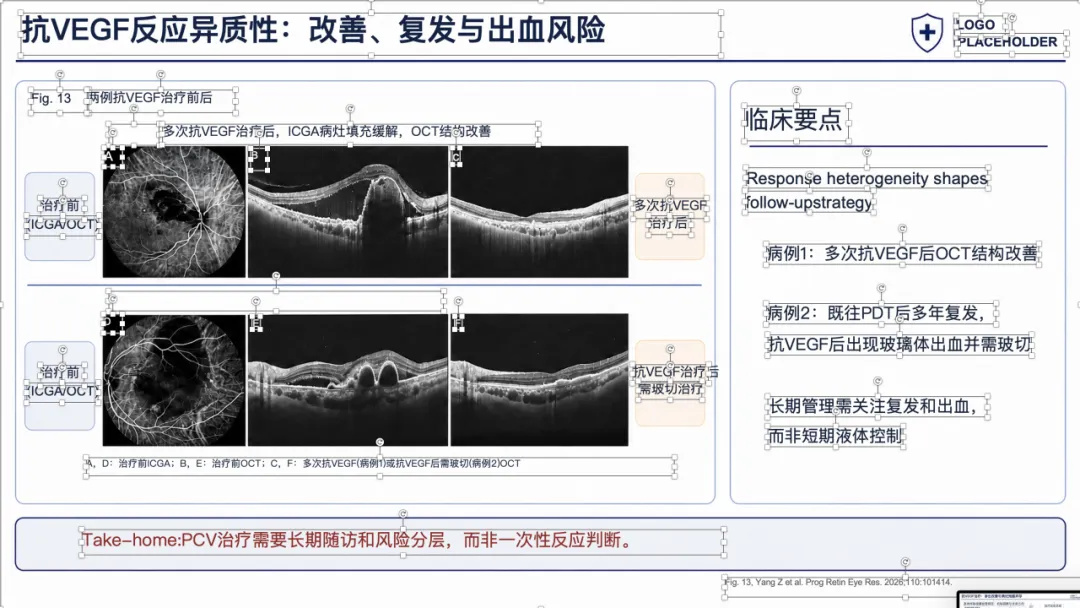
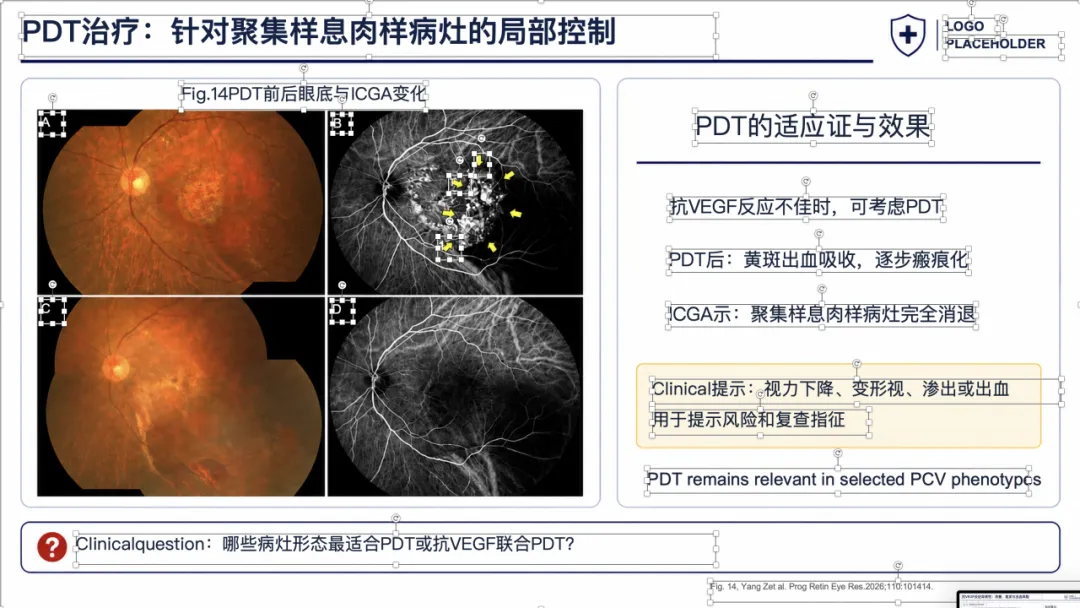
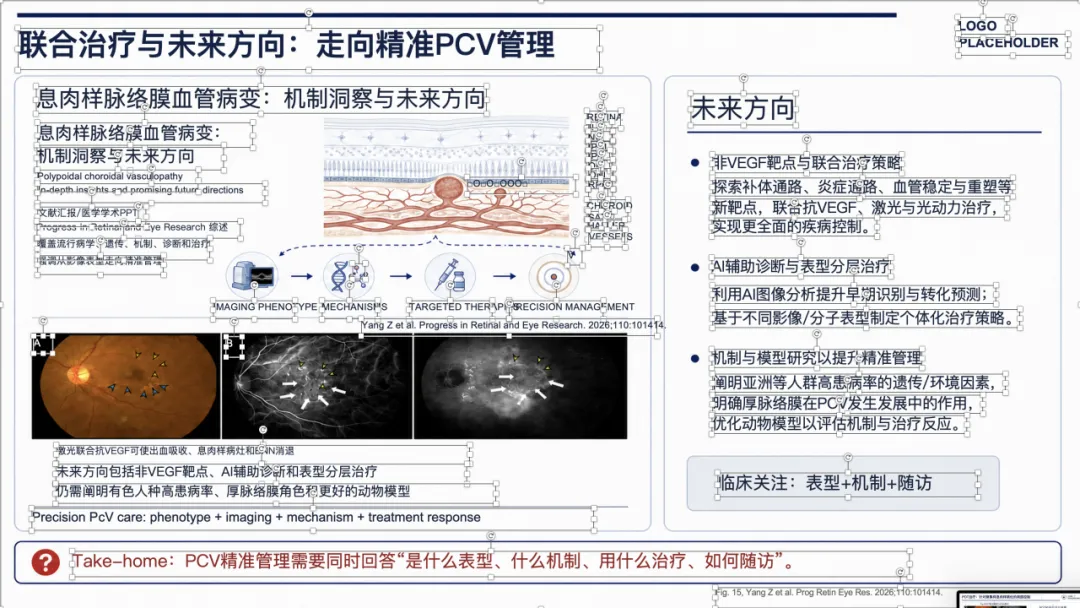
例子 3:PMID 41167457 最终可编辑 PPT 效果

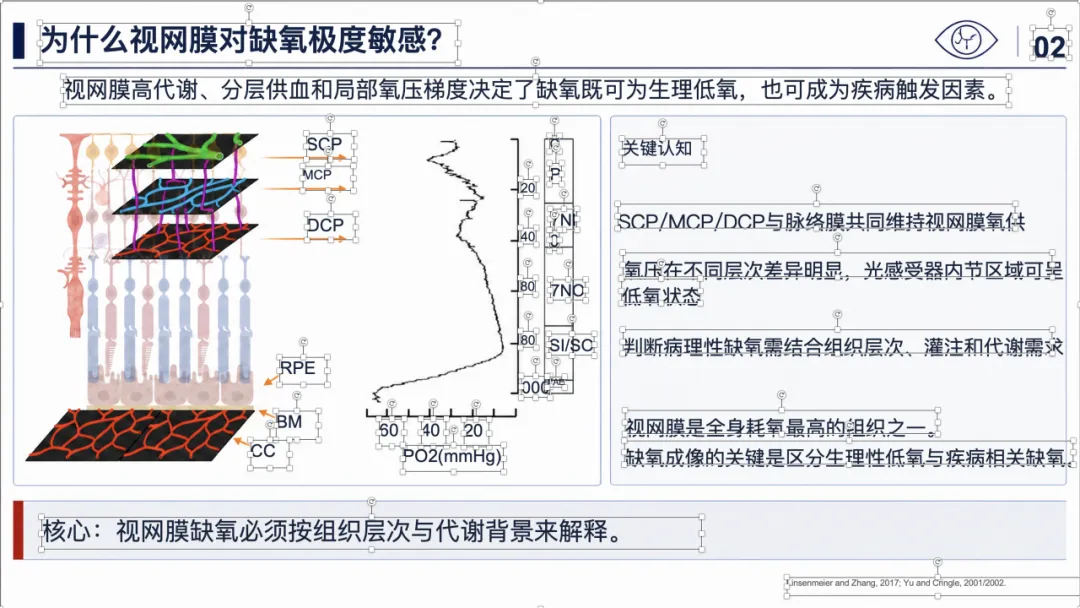
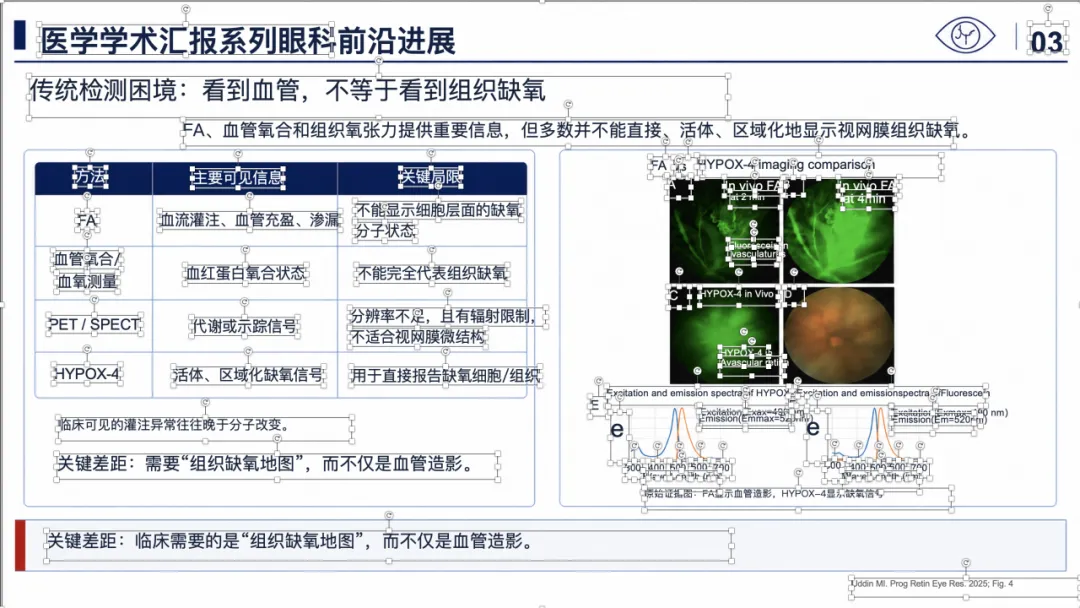
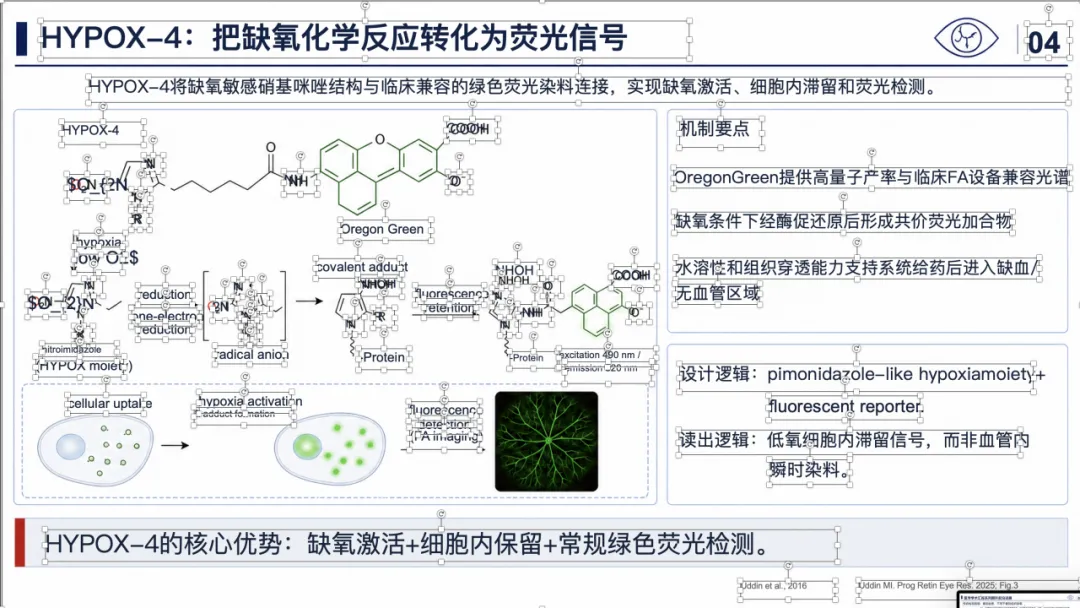
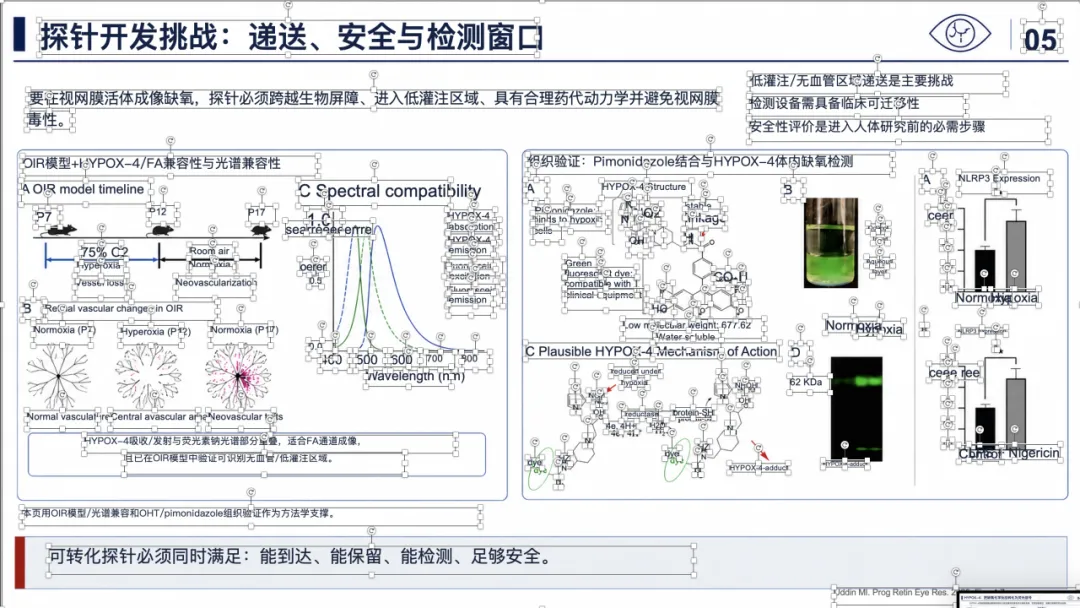
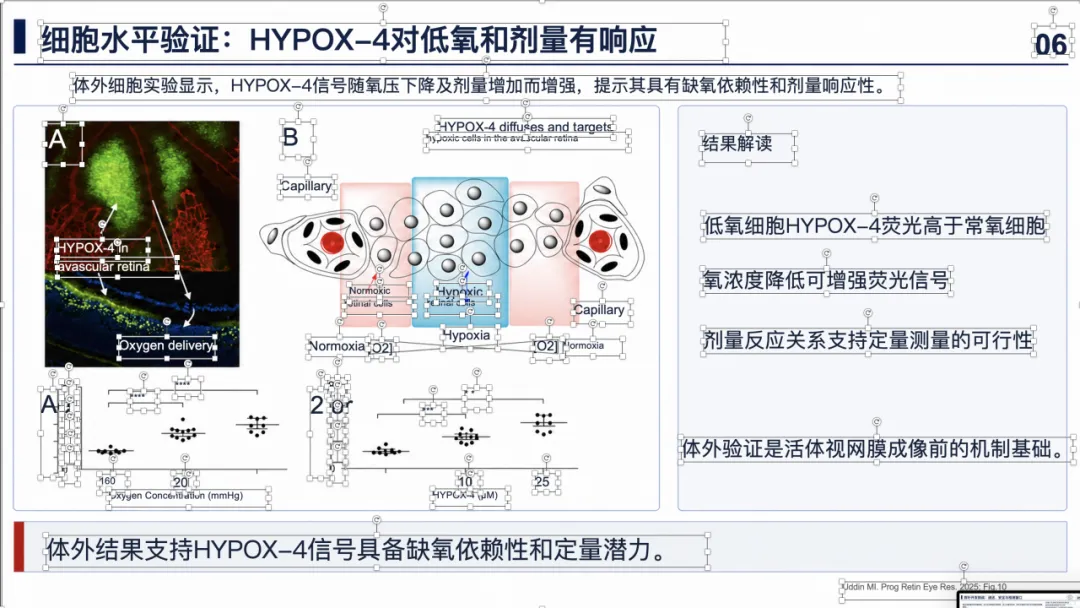
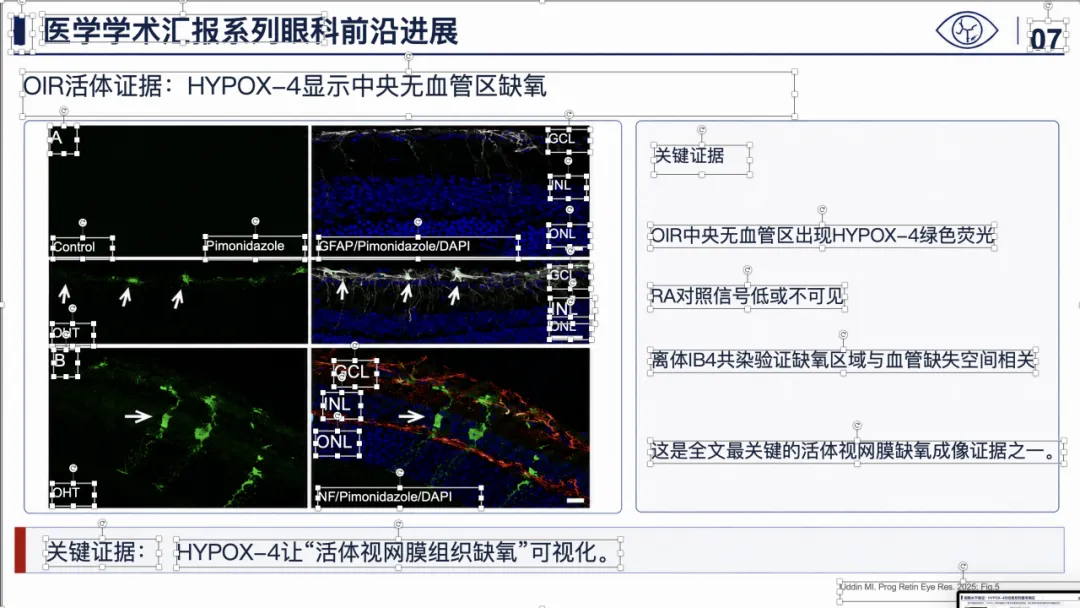
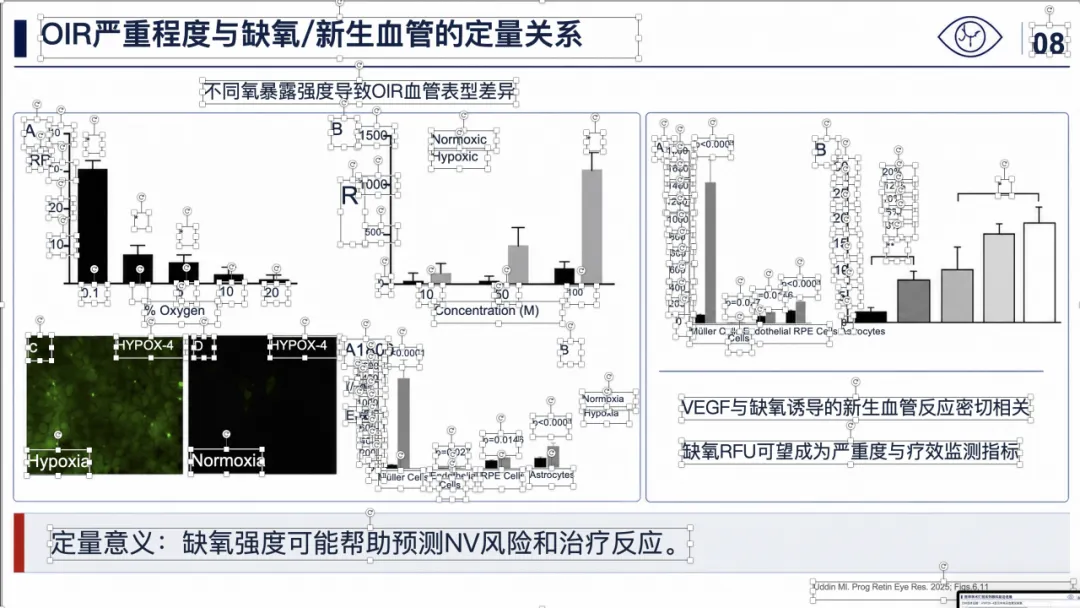
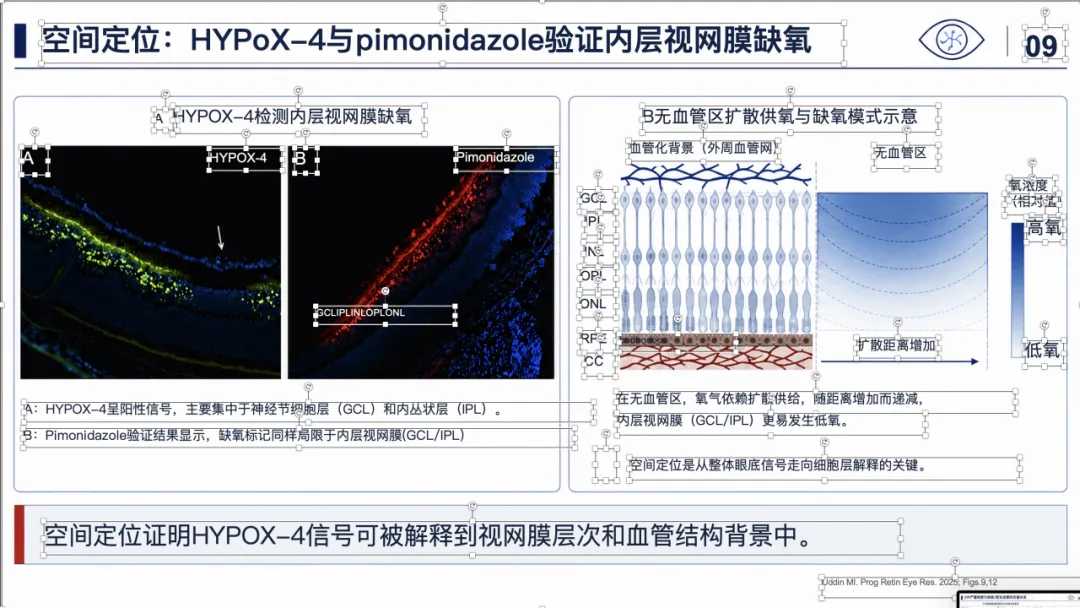
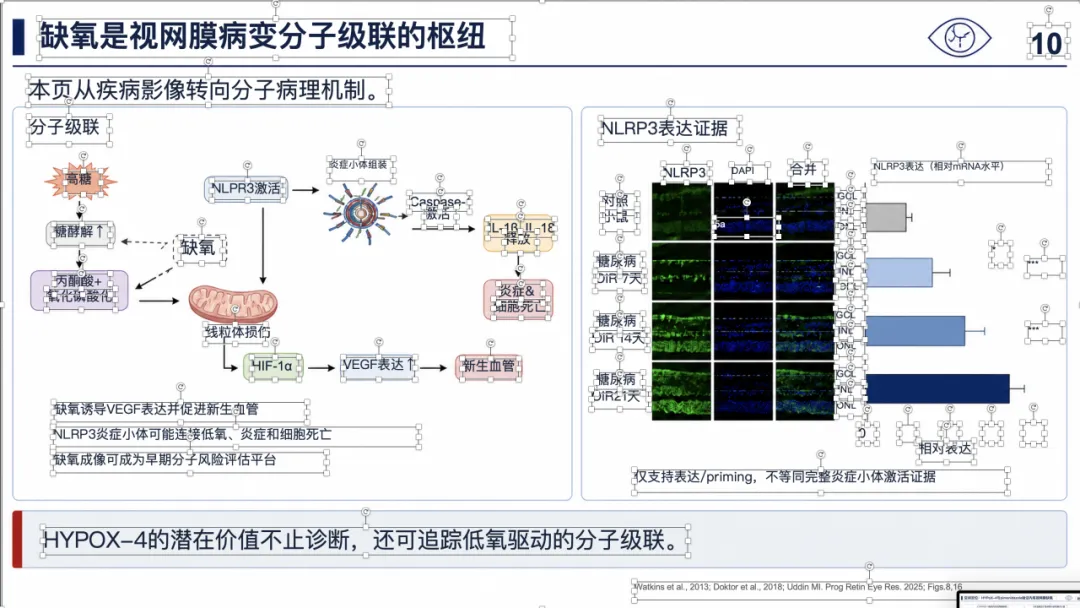
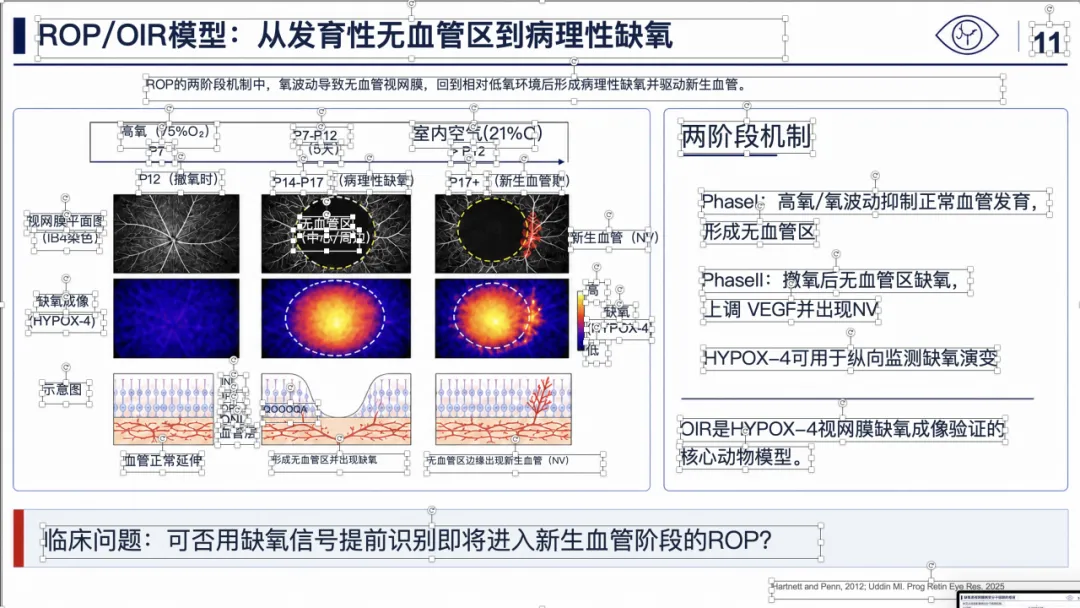
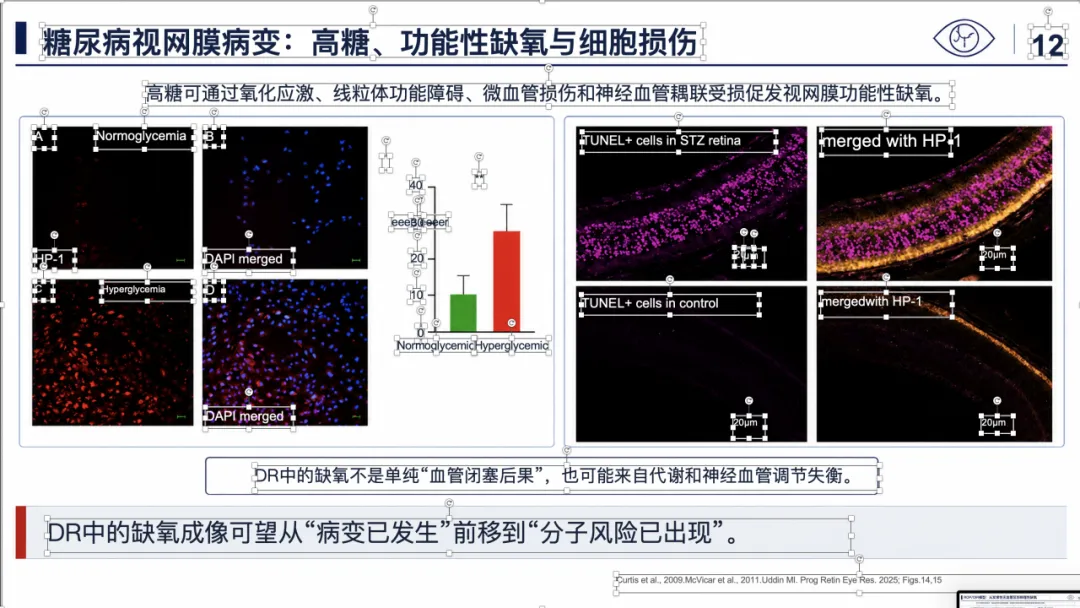
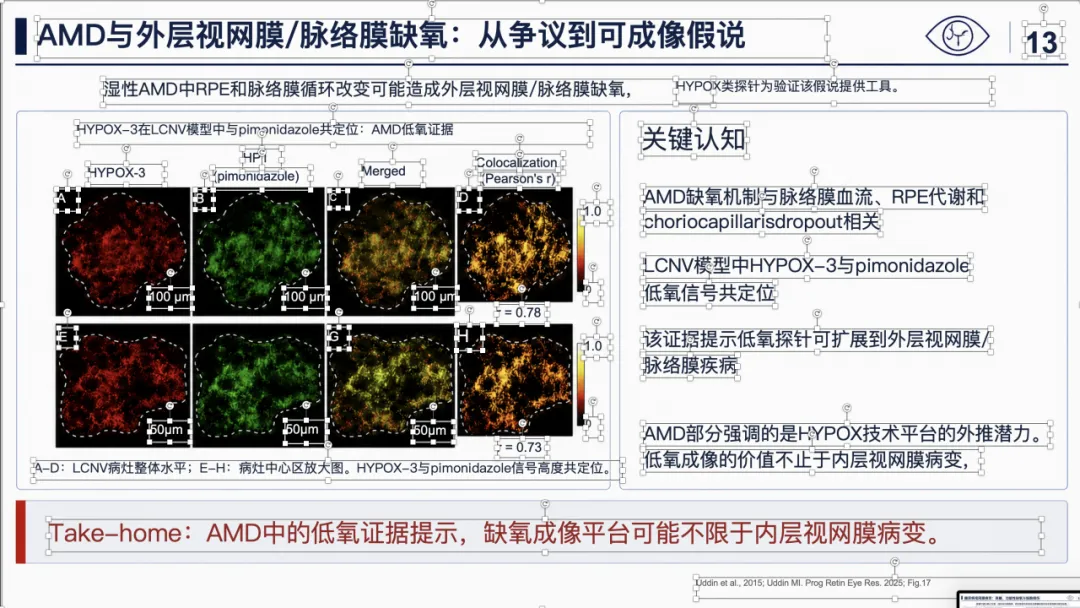
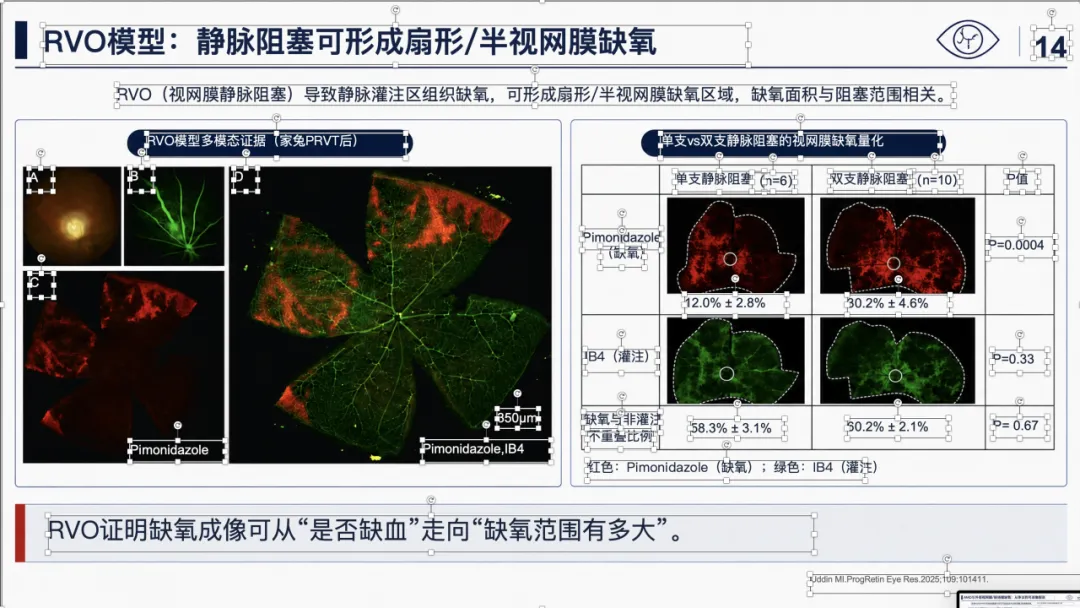
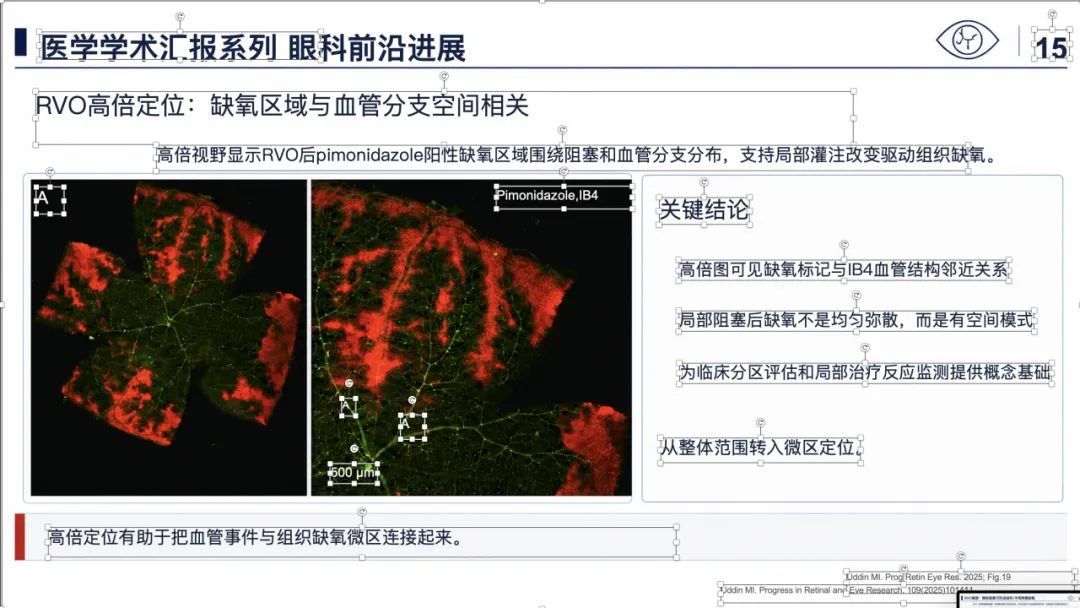
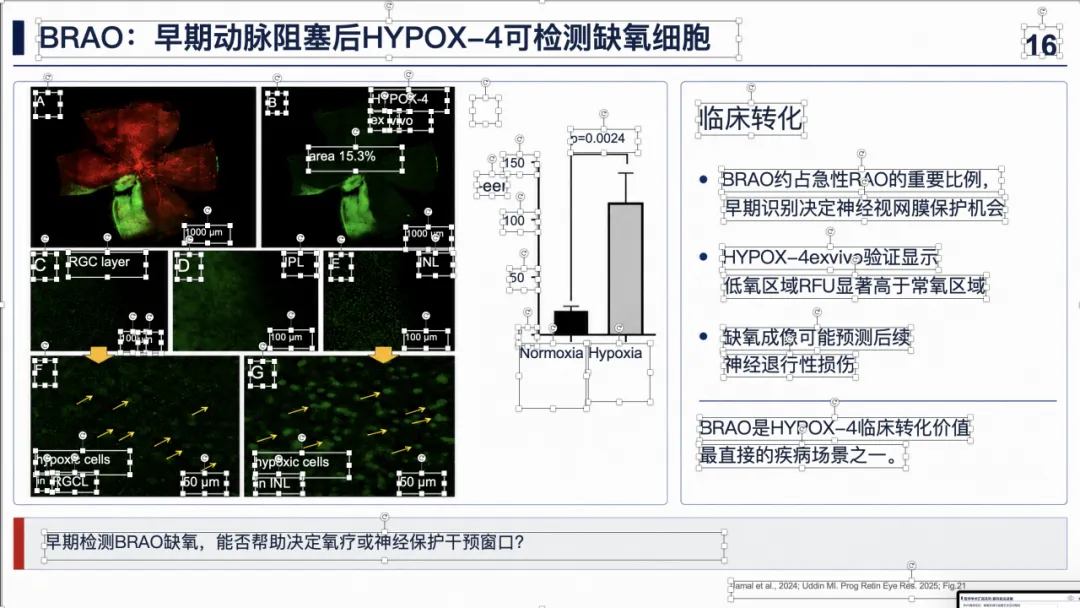
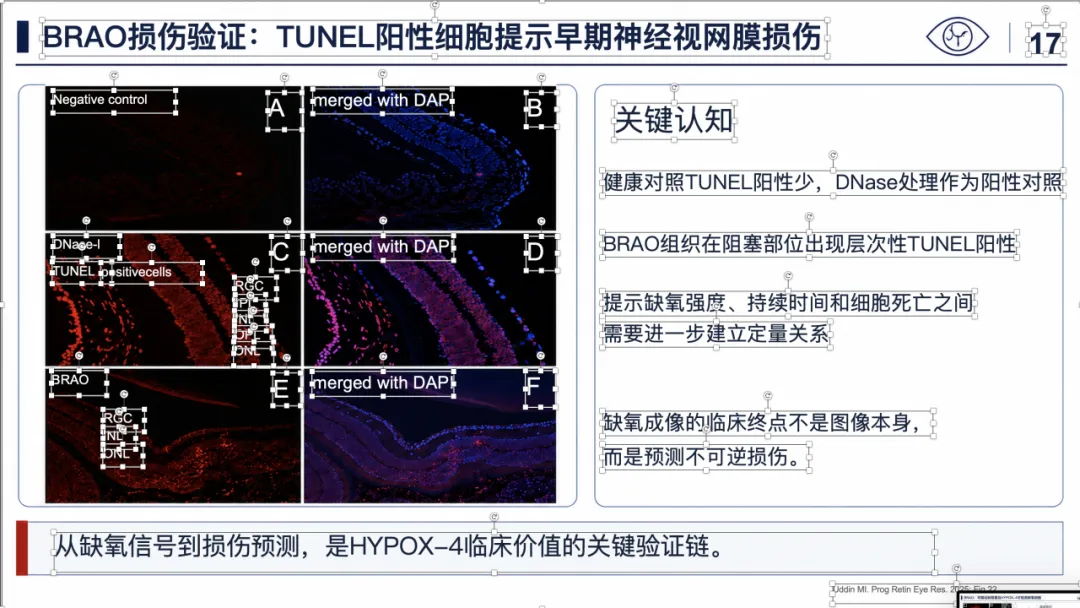
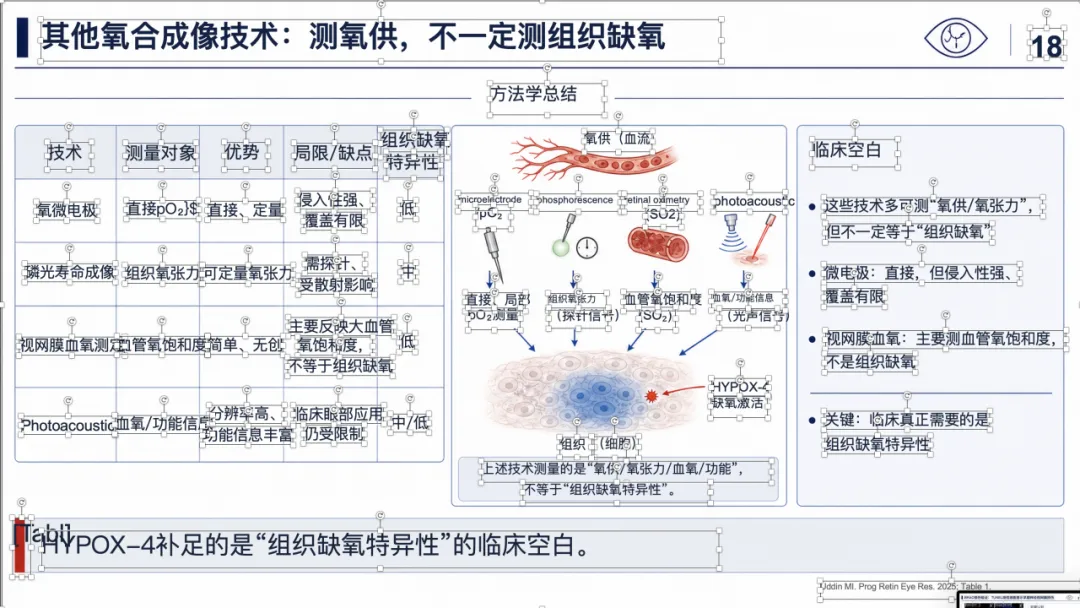
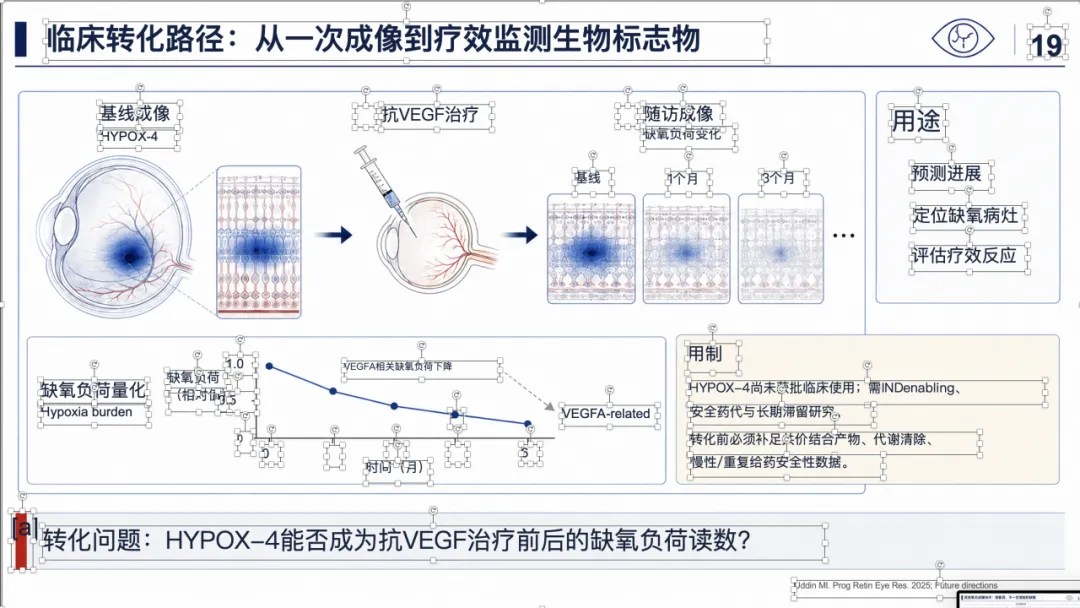
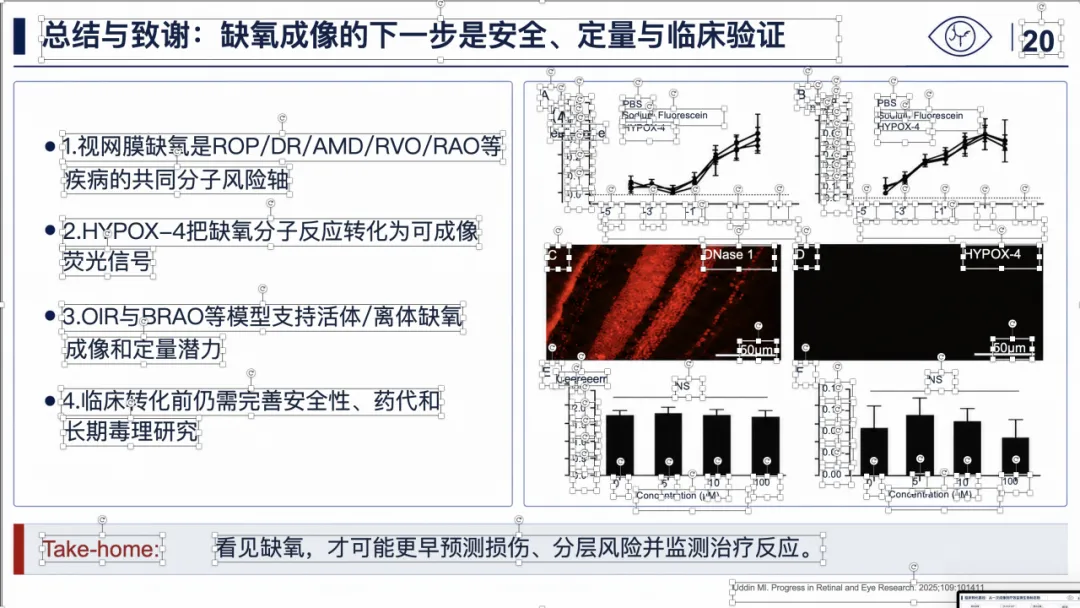
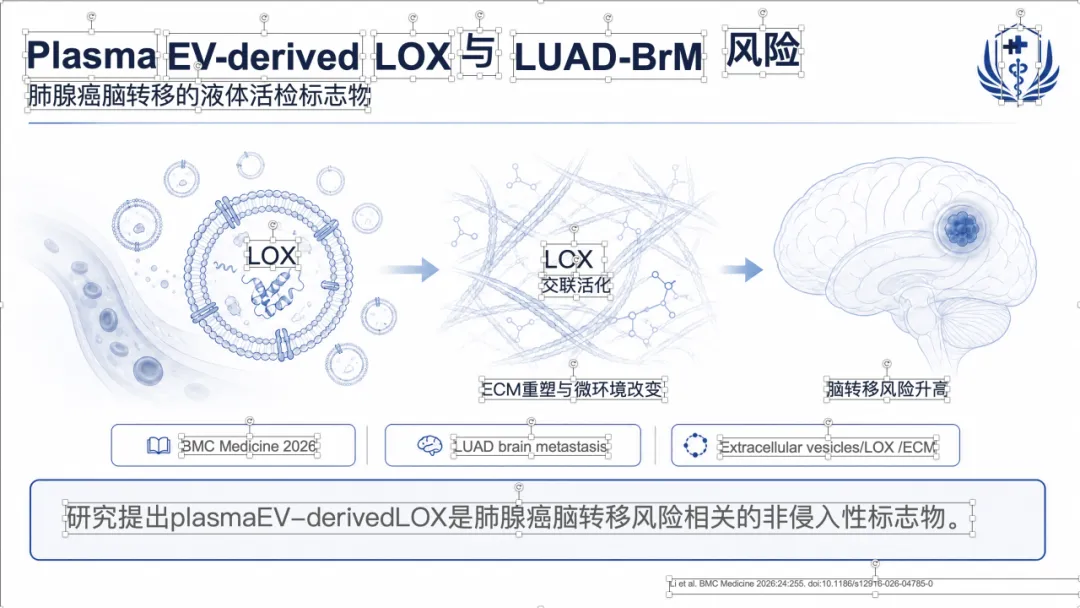
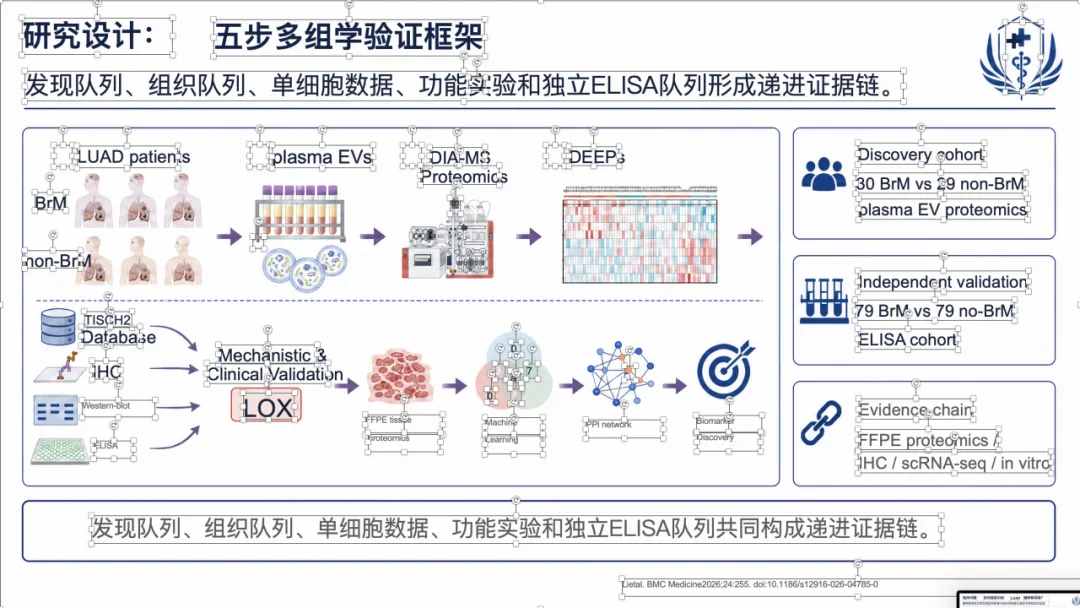
例子 4:PMID 41814259 最终可编辑 PPT 效果

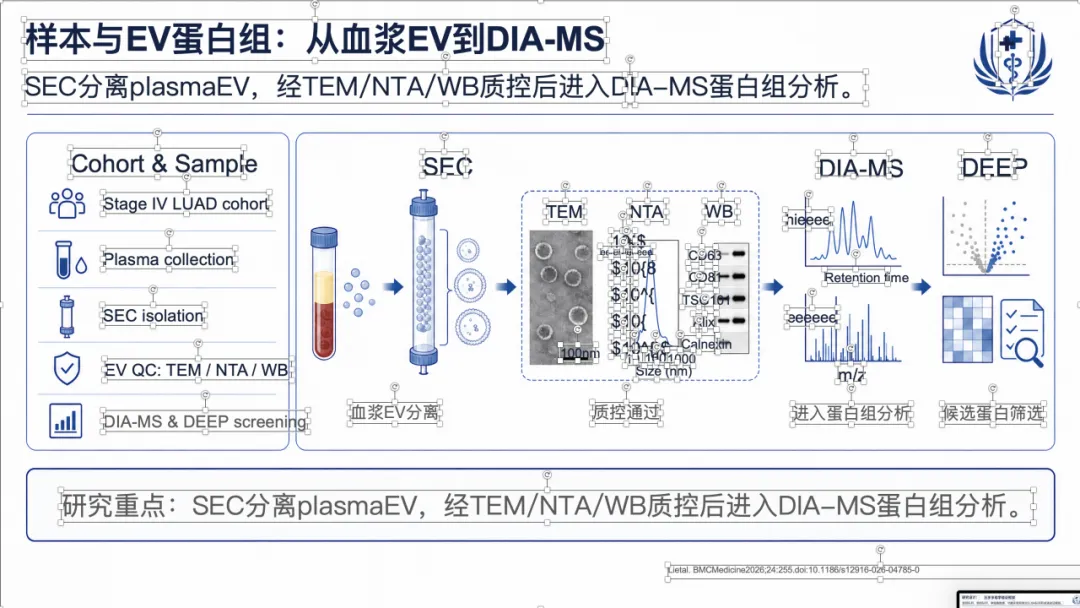
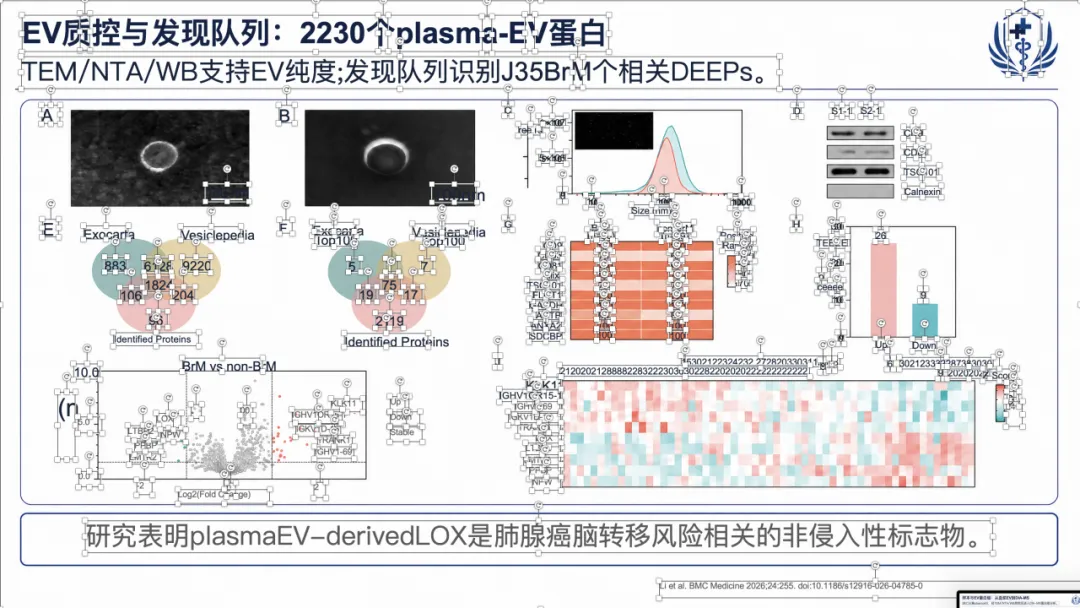

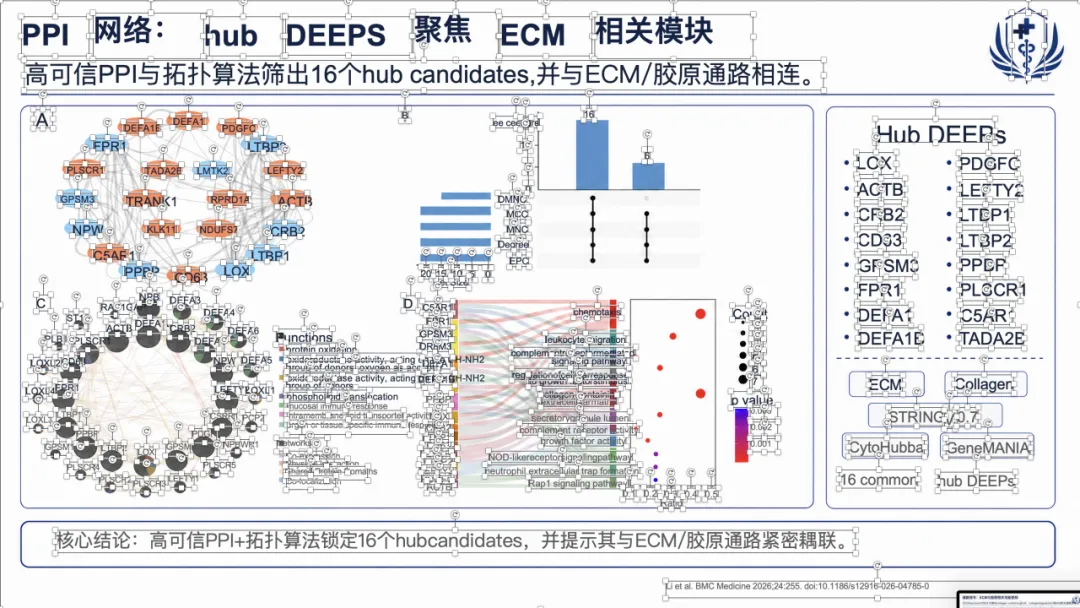
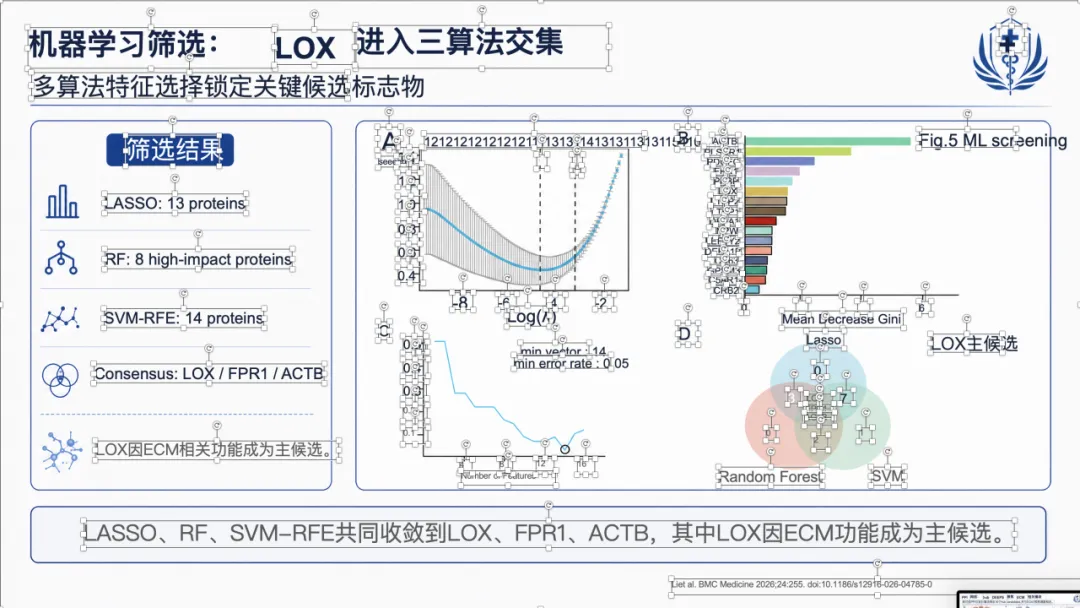
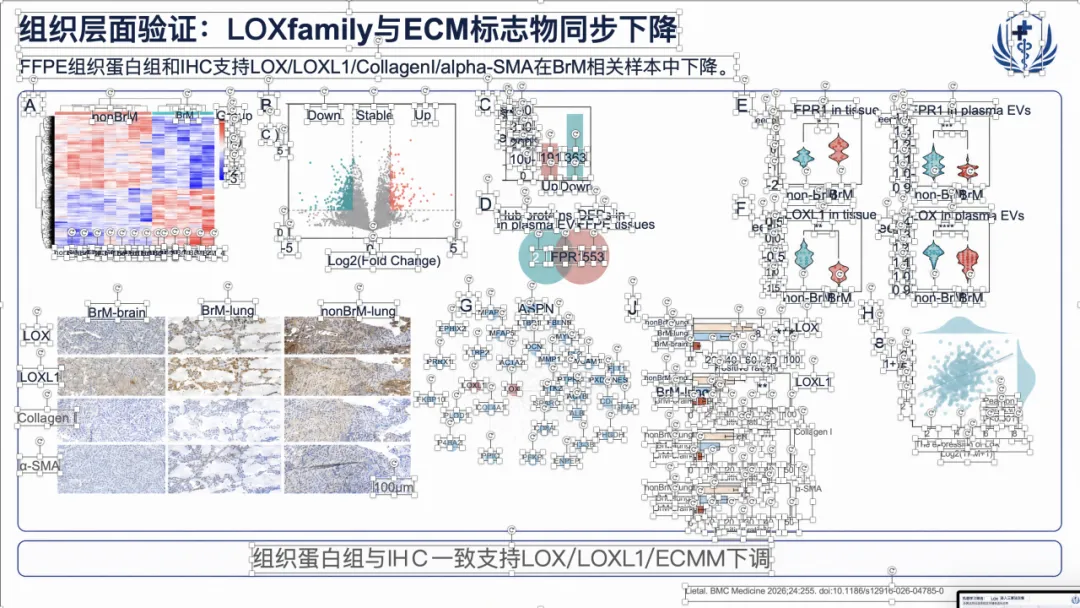
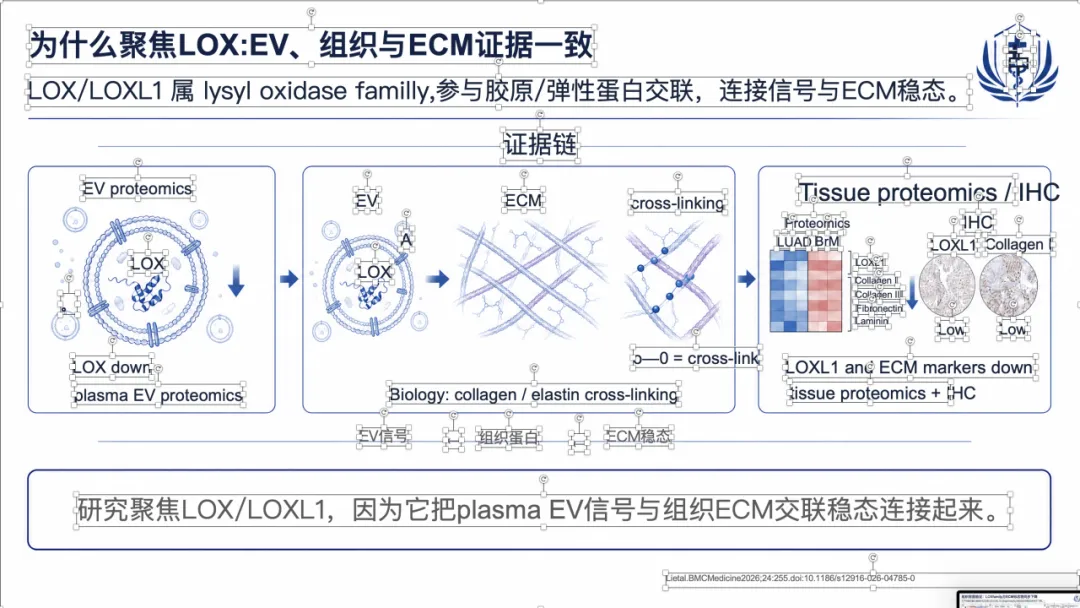
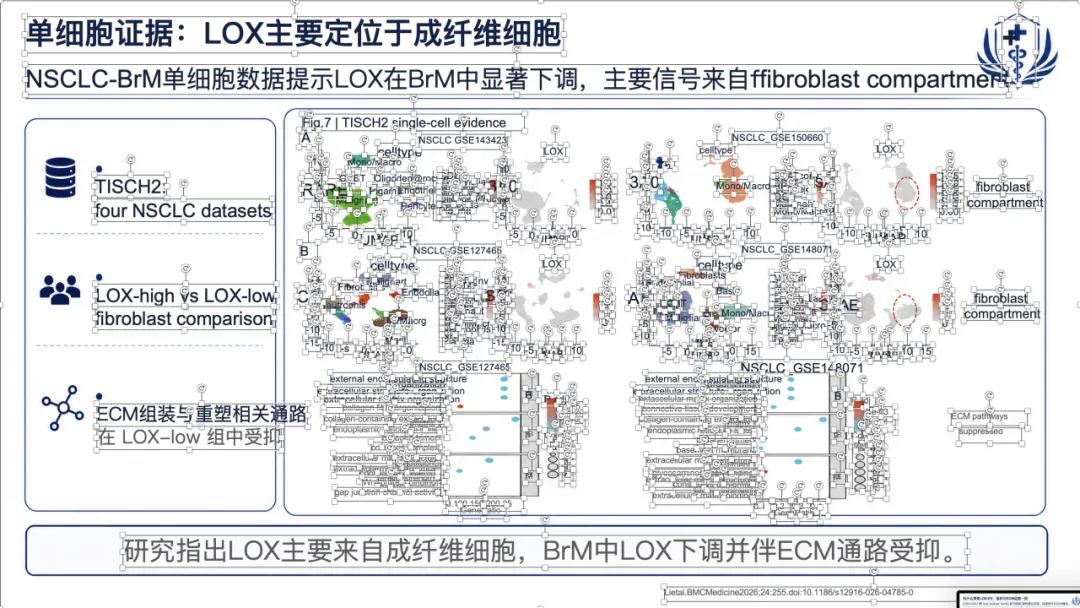
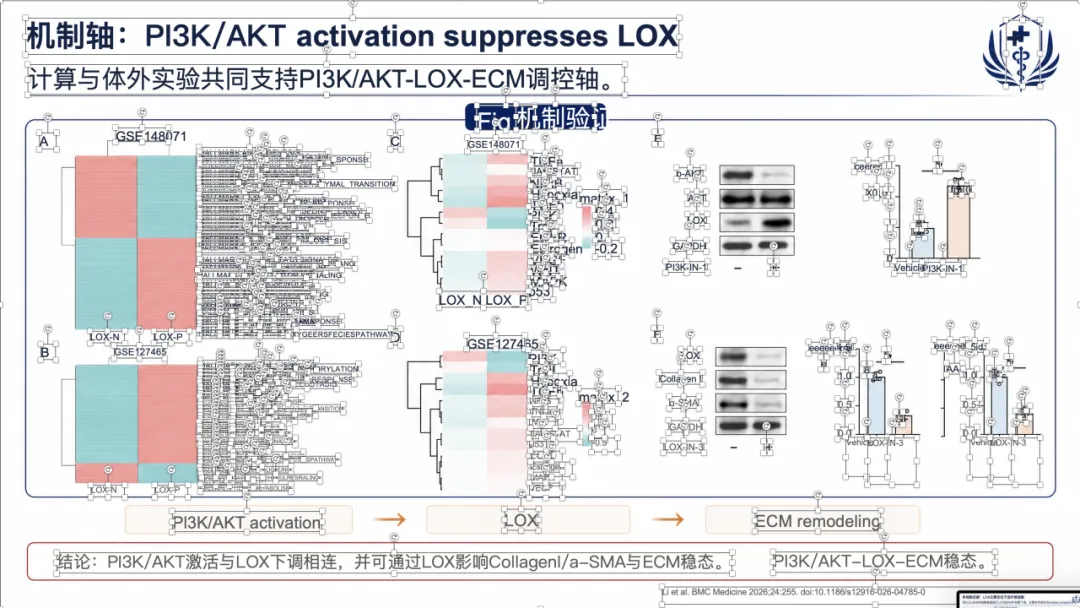
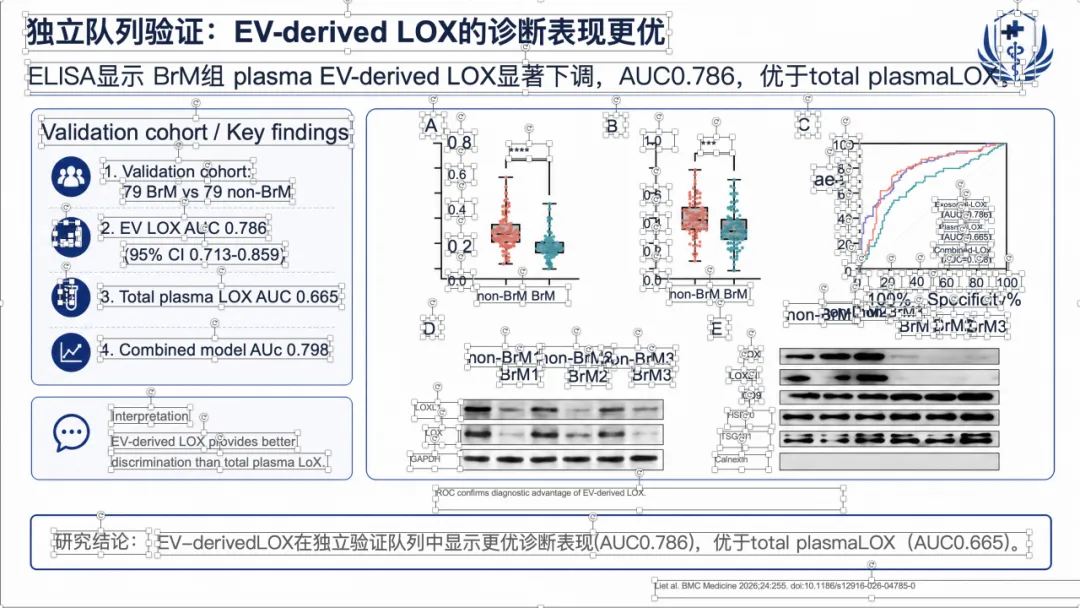
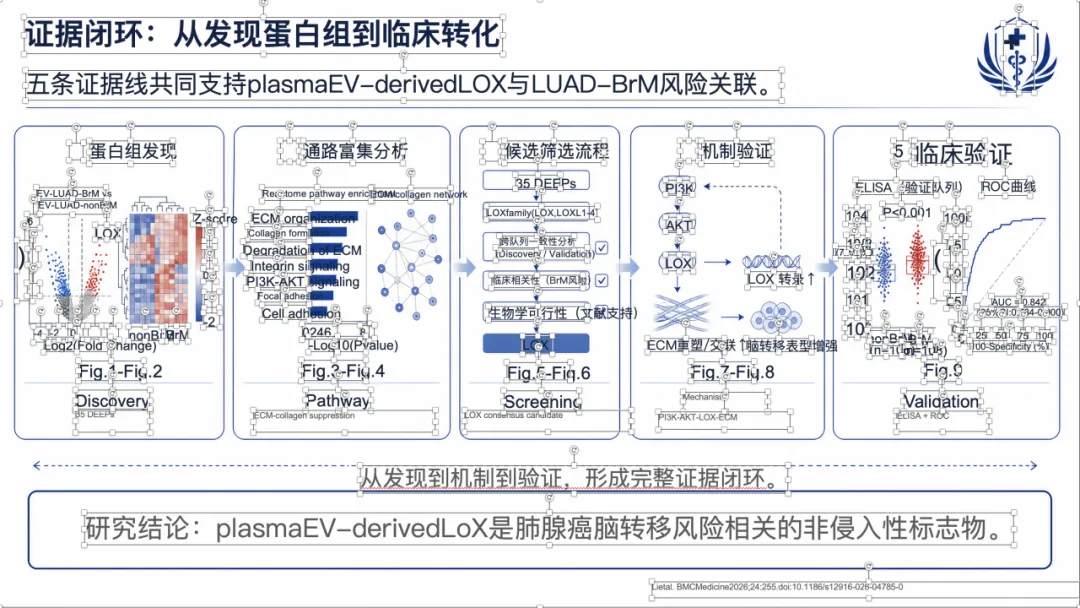
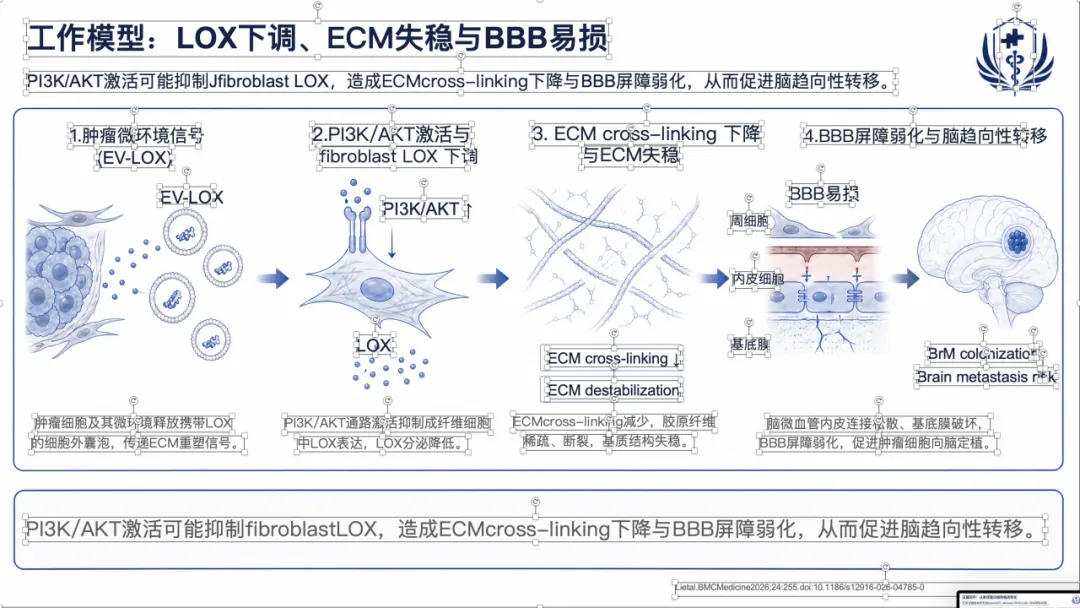
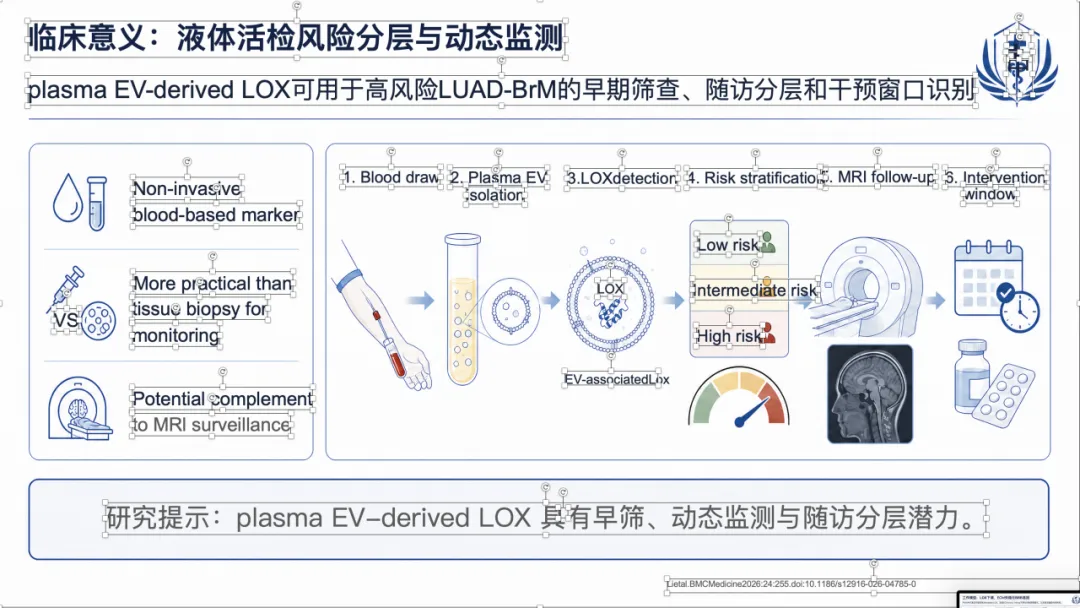
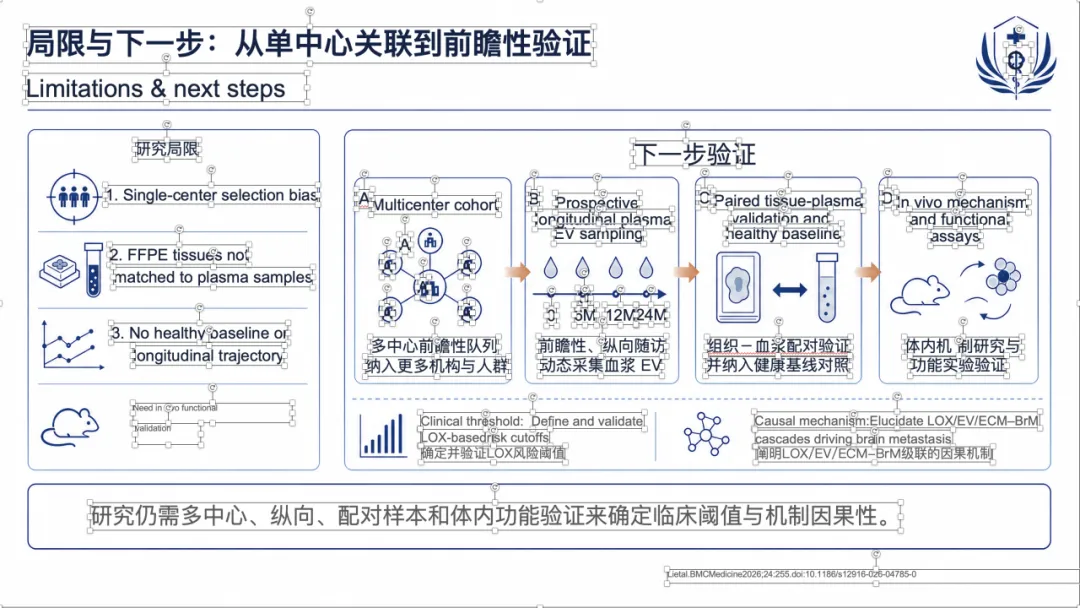
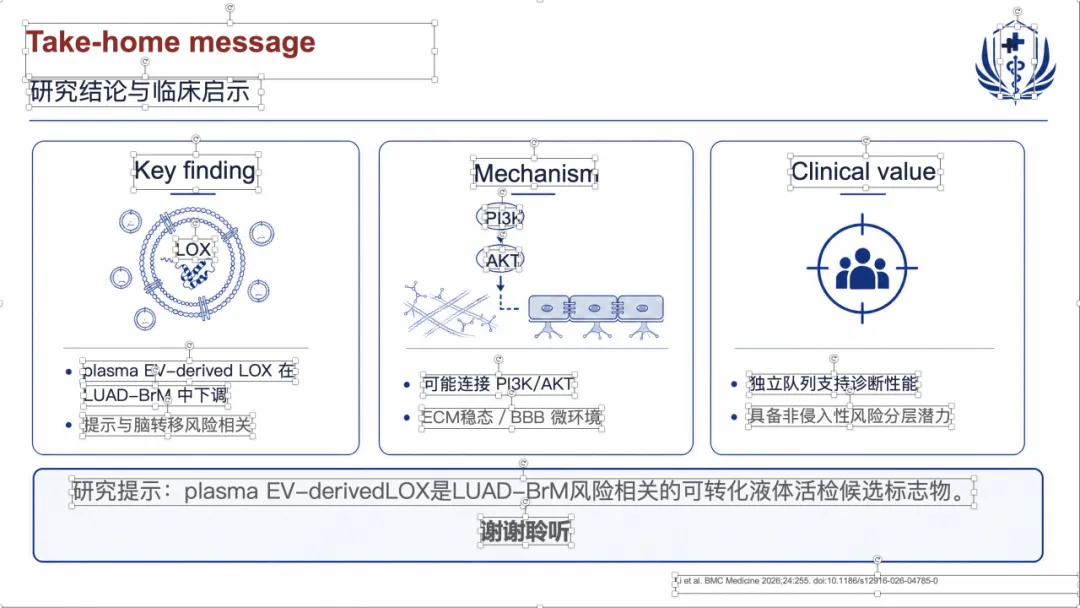
如果想看完整示例,可以直接去项目里的 docs/gallery.zh.md。
最后
项目已经开源,GitHub 地址是:https://github.com/snowmanzhuang/yixueAIganhuo-PPT
这个项目不是为了证明 AI 可以完全替代人做 PPT。
至少在医学科研汇报里,内容判断、证据取舍、逻辑串联和最后审稿,仍然需要人来把关。
但如果 AI 能先帮我们把论文读一遍,把 Figure 整理好,把页面初稿排出来,再把文字尽量重建成可编辑 PPTX,那已经能省掉很多重复劳动了。
创作不易,觉得有用欢迎点赞、在看、分享。
如果想要加入交流群,也可在后台回复关键词:交流群。
也欢迎大家点击查看往期推文:
用传统AI分析数据要2个小时,用Skill只花了3分钟,我当场破防了
文献推送工作流:AI自动筛选、总结并推送任何个性化医学领域的最新进展
告别AI“废话文学”:BRTRE框架与7款提示词优化工具深度实测(附赠写作全流程提示词)
如何8分钟完成高质量医学综述?首款支持限定参考文献分区/因子的AI综述工具免费使用
