 夜雨聆风
夜雨聆风天天用 AI,它背后是怎么工作的吗?
现在很多人每天都在用 AI。
写文案、改简历、写代码、做总结、生成标题、分析资料、陪你聊天……
ChatGPT、Claude、Gemini、豆包、通义千问、Kimi、DeepSeek,这些名字大家可能都听过。
但问题是:
它们到底是什么?
为什么能听懂人话?
为什么能一边理解问题,一边生成答案?
它们嘴里经常提到的 LLM、Transformer、Token,又到底是什么意思?
今天不讲复杂公式,也不讲论文细节。
就用大白话,把这几个 AI 时代绕不开的概念讲清楚。
一、LLM:大语言模型,也就是 AI 的“大脑”

LLM,全称是:
Large Language Model,大语言模型。
简单理解:
LLM 就是一个通过海量文字训练出来的 AI 大脑。
它可以理解语言、生成内容、回答问题、写代码、做总结、改文案、翻译内容、分析资料。
现在用到的很多 AI 工具,背后基本都离不开大语言模型。
比如:
ChatGPT
Claude
Gemini
豆包
通义千问
Kimi
DeepSeek
它们都可以理解成不同公司推出的大语言模型产品,或者基于大模型能力开发出来的 AI 应用。
以前的程序,更像是“按规则办事”。
你告诉它点哪里、输入什么、执行什么命令,它就按固定流程跑。
但 LLM 不一样。
你可以直接用人话跟它交流:
“帮我写一篇公众号文章。”
“解释一下这段代码。”
“把这段话改得更吸引人。”
“根据这个报错告诉我怎么解决。”
“帮我总结这份资料。”
它能理解你的意思,然后生成对应结果。
所以,LLM 最厉害的地方不是“会聊天”,而是:
它把自然语言变成了一种新的操作方式。
以前你想让电脑帮你干活,需要学软件、学命令、学代码。
现在你只要把需求说清楚,AI 就能帮你完成一部分工作。
这也是为什么大模型会这么火。
因为它改变的不只是聊天,而是工作方式。
二、Transformer:大模型背后的核心架构

如果说 LLM 是大语言模型的大脑,那么 Transformer 就像是这个大脑的底层结构。
很多人听过 AI、大模型、ChatGPT、DeepSeek,但不一定知道它们背后绕不开一个关键词:
Transformer。
一句话理解:
Transformer 是现在很多大语言模型的底层架构。
它最早是在 2017 年那篇非常经典的论文《Attention Is All You Need》里被提出的。
这篇论文的名字翻译过来就是:
注意力机制就是你所需要的一切。
为什么它重要?
因为它改变了 AI 理解语言的方式。
以前的模型处理一句话,很多时候更像是一个字一个字、一步一步往下看。
但 Transformer 引入了一个非常关键的能力:
Attention,注意力机制。
它可以让模型在理解一句话的时候,快速判断哪些词更重要,哪些词之间有关联。
比如这句话:
“我把苹果手机放在桌子上,它没电了。”
这里的“它”指的是谁?
人类一看就知道,是“苹果手机”。
而注意力机制要做的事,就是让 AI 学会在上下文里找到这种关系。
它不是只看单个词,而是看词和词之间的联系。
这就是为什么大模型能理解上下文,能写文章,能总结内容,能翻译,能写代码,甚至能和你连续对话。
可以这样记:
LLM 是大语言模型。
Transformer 是很多大语言模型的底层架构。
Attention 是 Transformer 里的核心机制。
如果把大模型比作一辆智能汽车:
LLM 是整辆车。
Transformer 是发动机和控制系统。
Attention 是它判断路况、抓重点、做决策的能力。
三、Token:大模型眼里的“文字碎片”
再说一个经常听到的词:
Token。
天天用大模型的人,迟早都会遇到这个词。
比如:
“这个模型支持多少 token?”
“这次调用消耗了多少 token?”
“输出 token 太多了。”
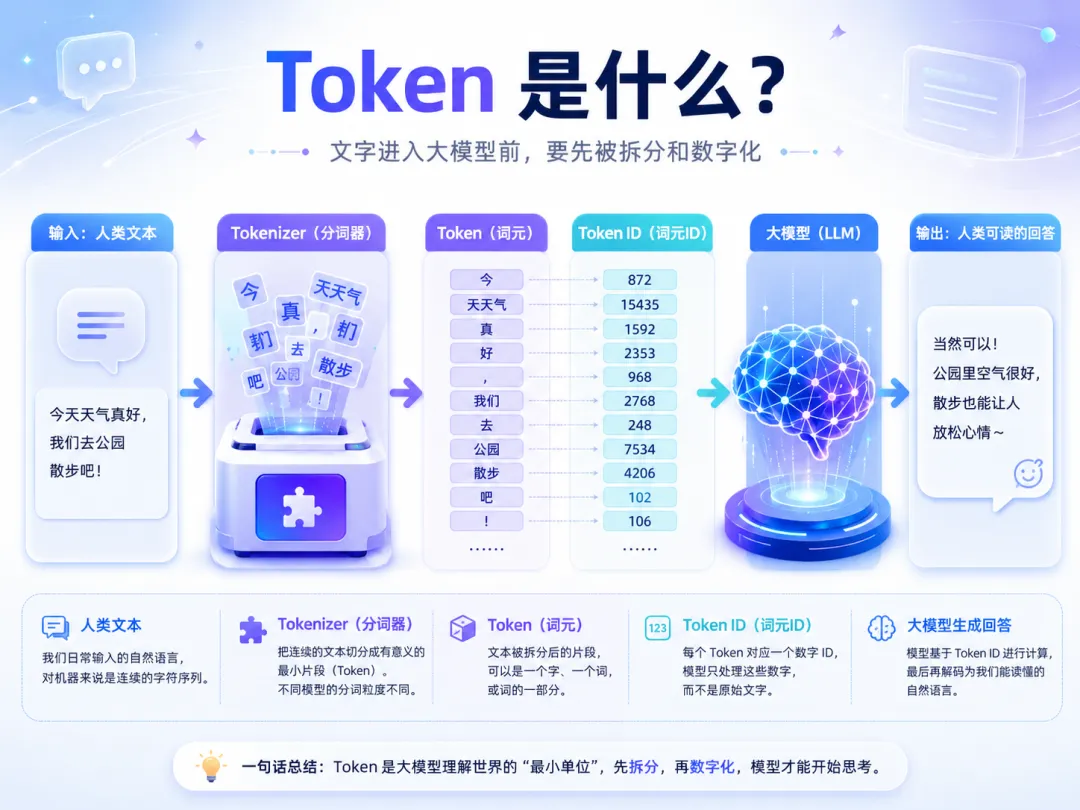
那 Token 到底是什么?
一句话理解:
Token 是大模型处理文本的基本单位。
你可以把它理解成:
大模型眼里的文字碎片。
但注意,Token 不一定等于一个字,也不一定等于一个词。
中文里,一个字可能是一个 Token。
英文里,一个单词可能会被拆成多个 Token。
有时候标点、空格、特殊符号也可能算 Token。
很多人以为:
“我输入一句话,大模型直接就看懂了。”
其实不是。
大模型本质上不是人。
它不是用人类的方式读文字。
更准确地说:
大模型本质上是一个非常庞大的数学函数。
它里面跑的是大量数学运算,真正能接受的是数字,输出的也是数字。
那问题来了:
人类输入的是文字,
大模型只认识数字,
中间谁来翻译?
答案就是:
Tokenizer。
Tokenizer 可以理解成大模型和人类之间的“翻译官”。
它主要做两件事:
编码 Encode:把文字变成数字。
解码 Decode:把数字变回文字。
比如你问大模型一句:
“什么是 Token?”
Tokenizer 会先把这句话拆成一个个小片段。
这些片段就叫 Token。
然后每个 Token 会被映射成一个数字编号。
这个数字编号叫:
Token ID。
所以你可以这样记:
Token 是文本片段。
Token ID 是文本片段对应的数字编号。
Tokenizer 负责文字和数字之间的转换。
大模型真正吃进去的,不是我们看到的文字,而是一串串 Token ID。
也就是一串数字。
接下来,大模型开始计算。
它会根据上下文、参数和概率,预测下一个最可能出现的 Token ID。
然后继续预测下一个。
再下一个。
再下一个。
你看到它一个字一个字往外“吐”,本质上就是:
模型在不断生成新的 Token ID。
最后,Tokenizer 再把这些 Token ID 解码成人类能看懂的文字。
这就是你最终看到的回答。
四、这三个概念之间是什么关系?
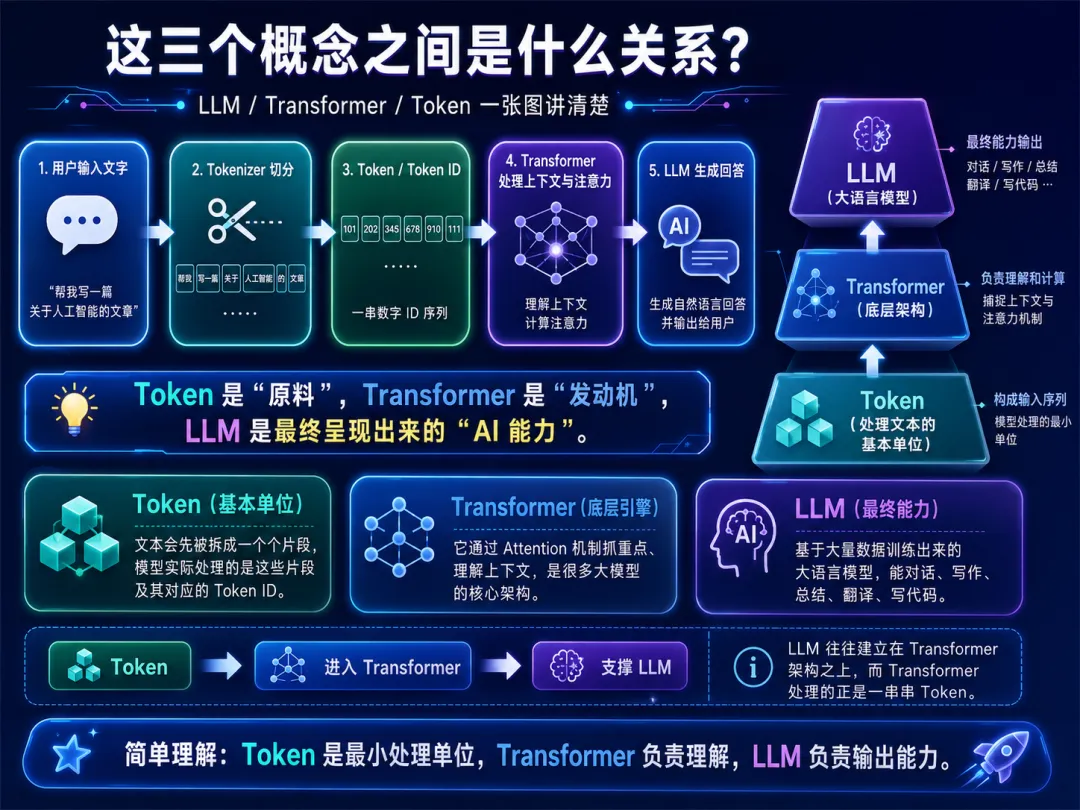
我们可以用一条简单链路串起来:
用户输入文字
↓
Tokenizer 把文字切成 Token
↓
Token 被转换成 Token ID
↓
Token ID 进入大模型计算
↓
基于 Transformer 架构进行理解和生成
↓
模型输出新的 Token ID
↓
Tokenizer 再把 Token ID 解码成文字
↓
用户看到 AI 的回答
也就是说:
Token 是大模型处理文字的基本颗粒。
Tokenizer 是文字和数字之间的翻译官。
Transformer 是大模型理解上下文、抓重点的底层架构。
LLM 是最终呈现出来的大语言模型能力。
这几个词听起来很技术,但用大白话理解,其实并不难。
五、为什么要懂这些?
因为未来 AI 会越来越多地进入工作和生活。
LLM 可以帮你:
写文案
做总结
改简历
翻译内容
整理资料
生成选题
学习新知识
对程序员来说,LLM 可以帮你:
解释代码
生成函数
排查 Bug
写接口
写测试
优化项目结构
对内容创作者来说,LLM 可以帮你:
找热点
写标题
做提纲
生成公众号文章
生成微博、小红书、短视频文案
但也要记住一点:
LLM 不是万能的。
它可能会一本正经地说错。
它可能不了解最新信息。
它可能生成看起来很对、实际不准确的内容。
所以正确用法不是完全相信它,而是:
让它帮你提高效率,但最后判断要靠自己。
你可以把 LLM 当成一个超级助手。
它很会整理,很会表达,很会生成,也很会联想。
但它需要你给它清楚的目标、背景和判断标准。
最后总结一下
如果你想理解 AI,大概先记住这几个词:
LLM:大语言模型,AI 工具背后的核心大脑。
Transformer:很多大模型的底层架构。
Attention:让模型抓重点、理解上下文的机制。
Token:大模型处理文本的基本单位。
Tokenizer:负责把文字和数字互相转换的翻译官。
以前我们使用电脑,需要学习软件、命令和代码。
现在,我们开始用自然语言指挥 AI 完成任务。
这才是大模型真正厉害的地方。
它改变的不只是聊天方式,而是人与机器协作的方式。
未来不会用 AI 的人,不一定会被 AI 直接取代。
但很可能会被更会用 AI 的人拉开差距。
所以,学 AI 不一定要一开始就研究复杂算法。
最实用的第一步,是先学会:
怎么向大模型提问。
怎么描述清楚需求。
怎么让 AI 帮自己完成任务。
