 夜雨聆风
夜雨聆风每周有9亿人在使用ChatGPT,支撑其运转的系统正在成为核心基础设施。
要让AI变得更聪明,企业必须把成千上万块芯片连接在一起协同工作。而芯片之间的数据传输速度直接决定了整个系统的计算效率。
OpenAI联合AMD、博通、英特尔、微软和英伟达,通过开放计算项目正式发布了多路径可靠连接网络协议(Multipath Reliable Connection,MRC)。


MRC技术打破了传统网络设计的局限,通过多平面网络、数据包喷射和静态源路由技术,彻底解决了超大规模计算集群中的网络拥堵和设备故障停机难题,大幅降低了建设成本与能耗。
拆解超大单行道
训练前沿AI模型时,一个简单的计算步骤会产生数百万次的数据传输。
哪怕只有一个数据包迟到,整个训练任务都会受到波及,导致昂贵的计算芯片只能停下来原地等待。集群规模越大,网络拥堵、线路老化和设备故障引发的延迟就越频繁。
在以往的架构下,哪怕只是一根网线接触不良,都有可能导致整个训练任务彻底崩溃。
工程师必须让系统从上一个保存点重新启动,或者让整个网络停顿数十秒去重新计算数据传输路线。
大规模同步预训练要求所有芯片步调一致,工作负载就成了一个巨大的故障放大器,一点微小的波动都会带来极高的算力周期和时间成本。
为了应对Stargate(星际之门)级别超级计算机的建设需求,工程师必须从底层架构重新思考网络设计。
OpenAI的扩展团队与业界伙伴耗时两年开发出了MRC(Multipath Reliable Connection,多路径可靠连接)协议。
这项技术建立在RoCE(RDMA over Converged Ethernet,基于融合以太网的远程直接内存访问)标准的基础之上。
RoCE是一项由IBTA(InfiniBand Trade Association,InfiniBand贸易协会)制定的标准,专门用于加速图形处理器和中央处理器之间的直接内存读取。
MRC吸收了UEC(Ultra Ethernet Consortium,超级以太网联盟)开发的相关技术,并将其扩展到支持大规模计算网络。
构建高弹性的网络需要足够的物理冗余,保证部分线路断开时数据依然有路可走。
传统思路是将每个网络接口视作一条800Gb/s(每秒800吉比特)的超宽单行道。MRC选择将这条单行道拆分。一个接口可以连接到8个不同的交换机上,由此构建出8个独立的、平行运行的100Gb/s网络平面。
这种设计让计算集群的形态发生了巨大改变。一台原本只能连接64个800Gb/s端口的交换机,现在可以连接512个100Gb/s的端口。
在连接约13万块GPU时,新架构只需要两层交换机就能完成全互联配置,传统架构往往需要堆叠三到四层交换机。
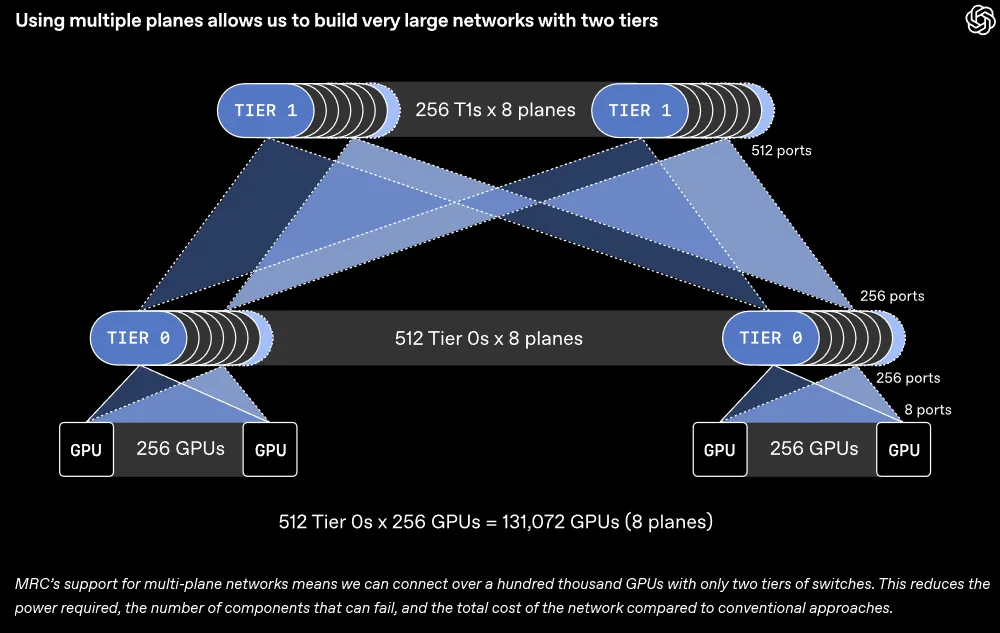
MRC对多平面网络的支持,意味着我们可以用两层交换机连接超过10万个GPU。与传统方法相比,这降低了所需的功率、可能发生故障的组件数量和网络的总成本。
层级的减少大幅削减了建设成本,降低了系统整体能耗,减少了潜在的硬件故障点。更多的数据流量可以留在底层交换机内部进行本地处理,传输效率得到了实质性的提升。
把数据当水洒出去
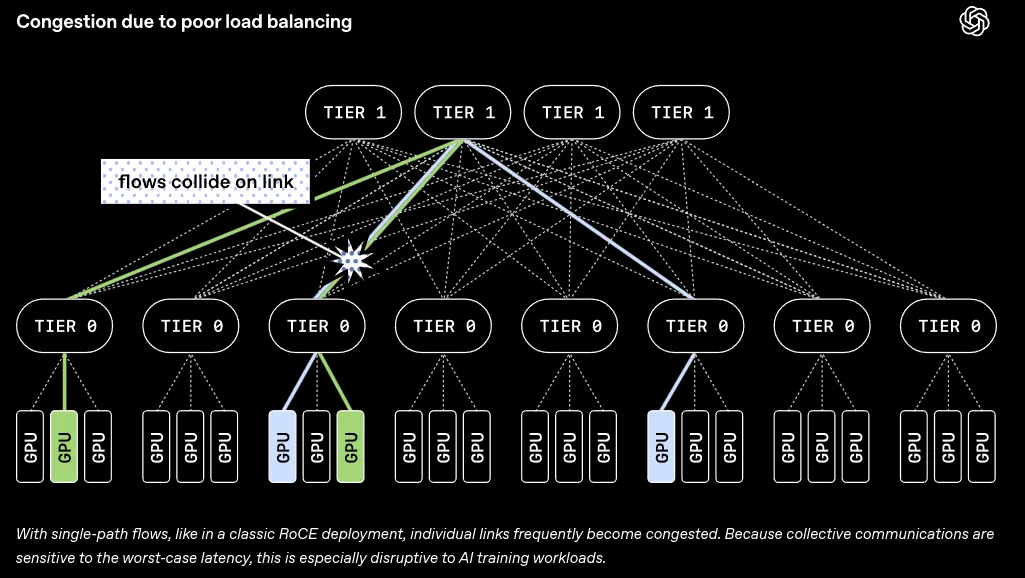
多平面网络提供了极其丰富的路径选择,想要充分利用这些路径并非易事。传统的AI训练网络协议要求单次数据传输必须沿着固定的一条路径前进,以确保数据包能够按照原本的顺序到达终点。
在拥有众多平面的大型网络中,死板的单路径规则会引发严重的后果。
不同的数据流很容易在同一条线路上发生碰撞,造成局部拥堵,其他空闲的平行网络平面却无事可做。单纯增加物理路径而不改变传输规则,系统的整体表现依然会非常糟糕。
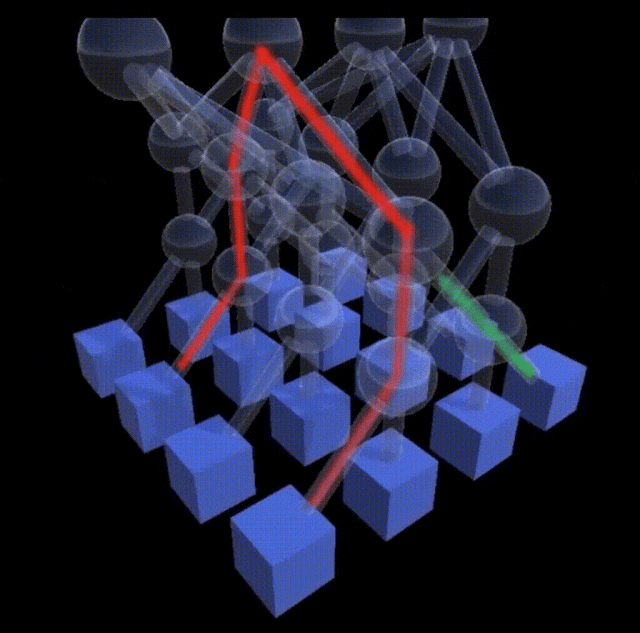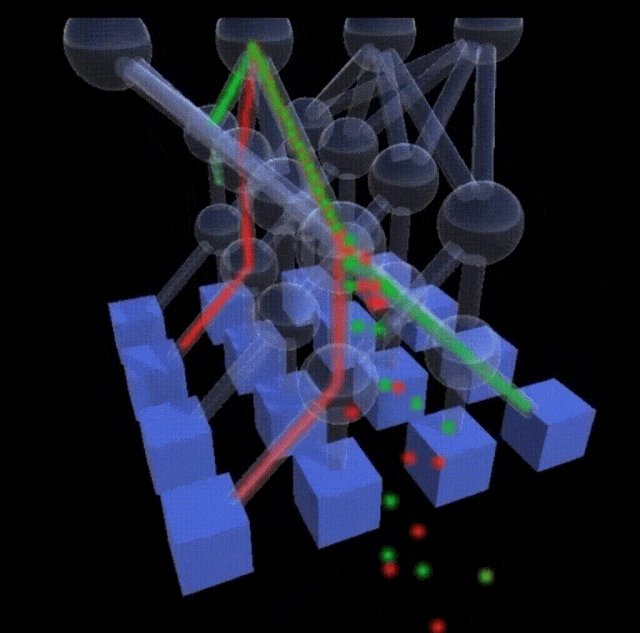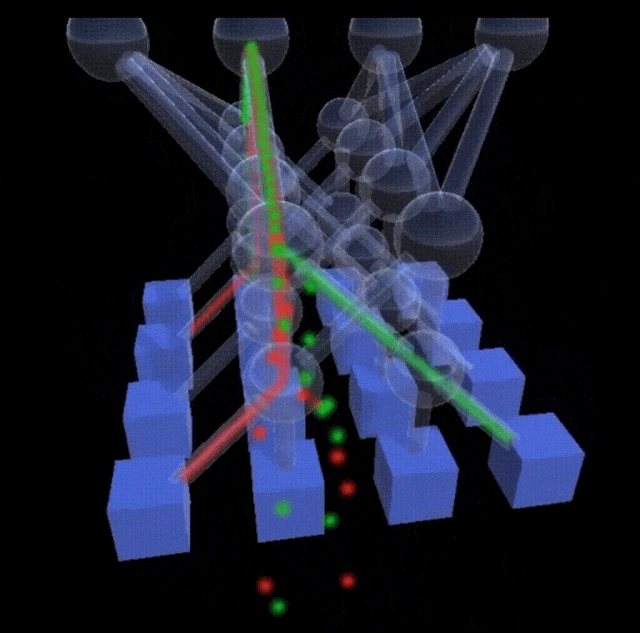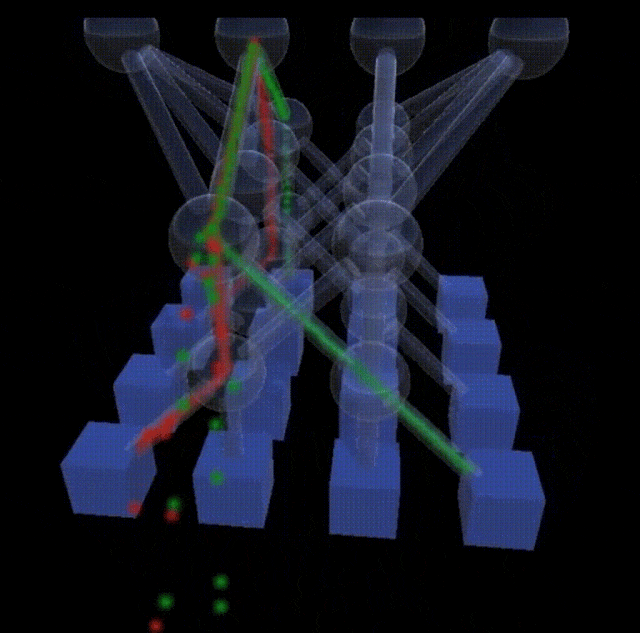
MRC彻底改变了数据传输的派发模式。系统不再给数据分配单一的固定通道,而是将一次传输任务拆散,像喷水壶一样将海量的数据包均匀地喷射到网络中的数百条路径和所有平面上。
这些数据包到达终点的顺序是完全错乱的。每一个MRC数据包内部都携带了最终的内存地址坐标。目的地接收端会在数据到达的瞬间,直接将它们安放到对应的内存位置上,完成拼图般的重组。
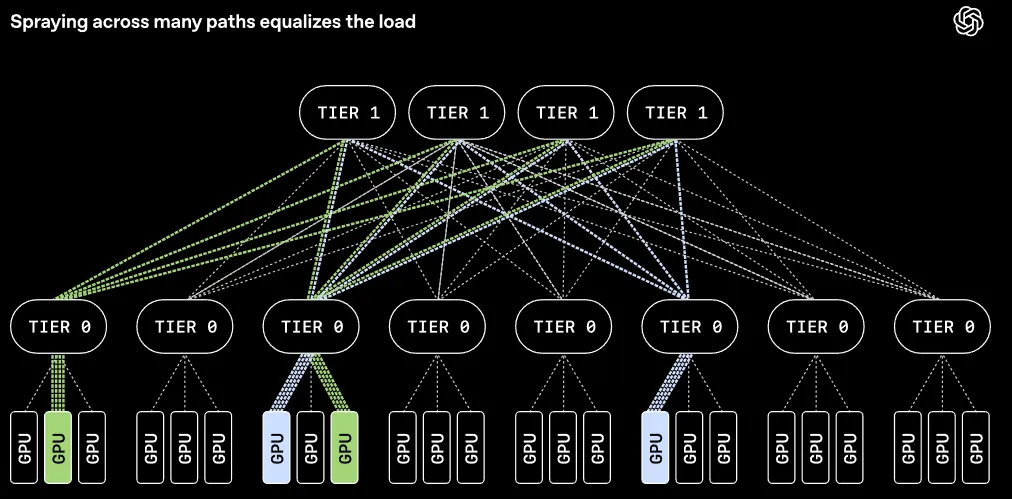
把流量摊薄到无数条路径上,网络内部的局部拥堵热点就不复存在了。所有的数据交互任务都能保持相近的处理时间,消除了拖慢同步训练的木桶短板。

每一个MRC连接都会在系统里保留一点状态记录。一旦协议察觉到某条路径的流速变慢,就会迅速将其替换为另一条畅通的路径,让整个网络的负载保持绝对的均衡。
遇到数据包丢失的情况,系统会采取最保守的安全策略,假定该路径上的某些硬件已经损坏,立即停止向该路径发送数据,并重新发送丢失的内容。被弃用的路径也不会被彻底遗忘,系统会定期发送探测包去检查故障是否已经修复,一旦确认恢复正常就会将其重新纳入传输队伍。
网络发生拥堵时接收端来不及处理数据,同样会造成丢包。
MRC引入了数据包修剪机制来应对这种状况。面临拥堵时,交换机会切掉数据包的核心有效载荷,只把表头信息发送给目的地,接收端看到表头后会直接发起明确的重传请求。
这种修剪动作有效避免了系统产生误判,防止协议把单纯的拥堵错误地当成物理硬件损坏。
让交换机停止思考
有了多平面拓扑、数据喷射、负载均衡和数据包修剪这些特性的配合,MRC连接能够在微秒级别内察觉并绕过网络故障。传统网络往往需要耗费几秒甚至几十秒的时间才能稳定下来并重新规划路线。
MRC在简化网络控制层面走得更远。
传统的交换机通常需要运行BGP(Border Gateway Protocol,边界网关协议)等动态路由协议。这类协议的作用是让交换机自己去计算可用的路径并绕开故障。
交换机本身是非常复杂的设备,里面运行着复杂的控制软件。当它们出现一些难以察觉的隐蔽故障时,工程师很难排查原因,网络连接也会随之频繁中断。
动态路由在MRC架构下失去了存在的必要。MRC采取了非常激进的做法,直接禁用了动态路由,转而使用SRv6(IPv6 Segment Routing,基于IPv6的段路由)技术。
利用SRv6,发送端可以直接决定每一个数据包在网络中应该走的具体路径。发送端把沿途每一台交换机的识别码按顺序嵌入到数据包的目的地址里。
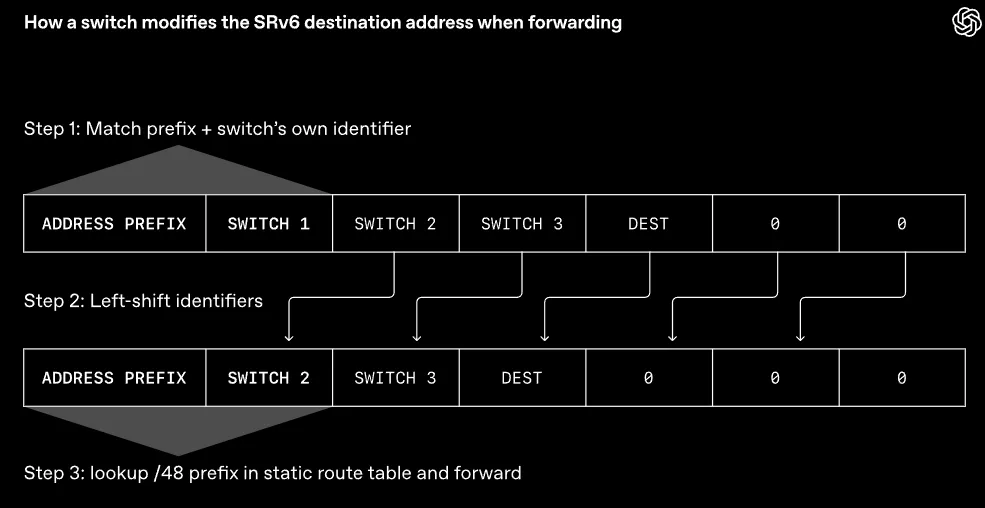
交换机在转发数据时,只需要核对数据包上有没有自己的识别码。核对无误后,交换机把自己的识别码抹掉,让下一台交换机的识别码显露出来。接着,交换机去查看一张静态路由表,把数据包扔向下一个目的地。
这张静态路由表在交换机初次开机部署时就已经配置完毕,此后再也不会发生变动。
交换机不需要再耗费算力去重新计算路线,只需要像一个毫无思想的流水线工人一样,机械地遵循静态规则进行转发。如果某条路径真的断了,发送端不再往这条路上喷射数据包即可。
这样的设计在实际生产环境中展现出了惊人的稳定性。在拥有数百万条网线的训练网络里,底层和上层交换机之间每分钟都会发生多次链路抖动。
MRC确保了这些抖动对同步预训练任务没有产生任何可测量的负面影响,工程师甚至不需要优先去维修那些不稳定的网线。
在近期一次前沿模型的训练过程中,运维团队重启了四台上层交换机。按照以往的经验,运维人员必须极其谨慎地协调时间,生怕打断训练任务。
有了MRC的庇护,运维团队无需跟负责训练的团队打任何招呼,直接在系统全速运转时完成了设备重启。线路维修也是如此,损坏的网线可以带电直接热修复。能用的线MRC自然会用,不能用的线它会自行绕开。
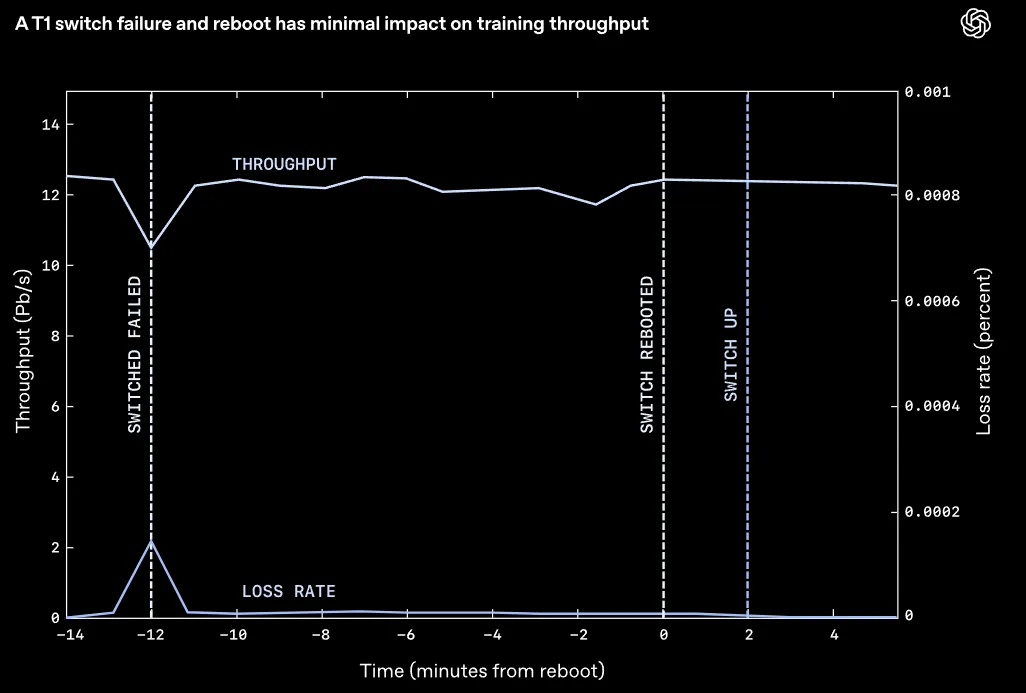
在训练运行期间捕获的真实数据显示,MRC对T1开关完全丢失的反应。训练工作暂时放缓,但很快恢复。
以往只要GPU网卡和底层交换机之间的连接断开,整个训练任务就会宣告失败。
现在,哪怕一张拥有8个端口的网卡坏掉了一个端口,系统最高传输速率仅仅下降八分之一。MRC会瞬间察觉到端口丢失,立刻重新计算路径绕开损坏的平面,同时通知网络里的其他节点不要再往这个损坏的平面发送数据。
多数掉线故障在一分钟内就能物理恢复,随后该平面会被无缝接纳回传输队伍中。系统速度的实际损耗,往往比物理硬件容量的损失要小得多。
开放标准与硬件落地
没有任何一家企业能独自解决AI领域的硬件挑战。
MRC协议目前已经部署在OpenAI最大的英伟达GB200超级计算机上,包括位于德克萨斯州阿比林市的OCI(Oracle Cloud Infrastructure,甲骨文云基础设施)站点,以及微软的Fairwater超级计算机中。
这项技术已经利用英伟达和博通的硬件成功训练了OpenAI多个模型。
AMD不仅联合主导了MRC规范的编写,还贡献了应对真实世界复杂环境的高级拥塞控制技术。
AMD已经在其实验集群中大规模部署并验证了这项技术。凭借Pensando Pollara 400 AI NIC(Network Interface Card,网络接口卡)的软硬件全可编程能力,AMD在MRC标准正式确立之前,就已经实现了改进版RoCEv2传输协议的早期验证。
目前AMD正将这项成熟的技术平滑过渡到下一代Vulcano 800G AI NIC网卡上。
AMD近期股价也翻了一番。
通过开放计算项目,MRC规范的细节已经向全世界公开。
全行业建立统一的关键基础设施标准,能够让计算系统跨越不同合作伙伴的生态壁垒。
网络正在成为消化硬件故障的减震器,保持计算资源的持续高产出,让通向通用AI的道路变得更加平稳。
参考资料:
https://openai.com/index/mrc-supercomputer-networking/
https://www.amd.com/en/blogs/2026/amd-advances-ai-networking-at-scale-with-mrc.html
https://www.opencompute.org/documents/ocp-mrc-1-0-pdf




