 夜雨聆风
夜雨聆风2026年5月7日,浏览器安全公司LayerX披露了一项令人不安的发现:Anthropic旗下Claude AI的Chrome扩展程序存在严重设计缺陷,任何一个浏览器扩展——包括那些未声明任何权限的“零权限”插件——都能悄然劫持Claude智能体,操控其以用户身份执行敏感操作。该消息迅速在安全圈引发热议,而热议背后的深层张力在于:Claude长期以安全、可靠的形象示人,其模型被广泛用于辅助代码审计、漏洞挖掘乃至网络安全研究;而今,这座“安全堡垒”却因浏览器扩展的基础信任架构失当而门户洞开。正如LayerX高级研究员阿维亚德·吉斯潘在技术报告中所言,这一缺陷并非某个容易被修补的代码错误,而是一场系统性信任模型的崩塌。它把Claude从一个能帮助用户分析代码漏洞的智能助理,瞬间变成了可以被任何恶意插件远程操控的“困惑的副手”。

信任的裂痕:对“来源”的盲目信仰
漏洞的根源位于扩展程序的清单文件中。Claude的Chrome扩展通过externally_connectable设置,允许所有在claude.ai域名下运行的脚本与之通信,并能够触发特权操作。然而,这一设计仅验证了通信的“来源”——即claude.ai这个网址,却从未核实具体是谁在该来源内部执行脚本。
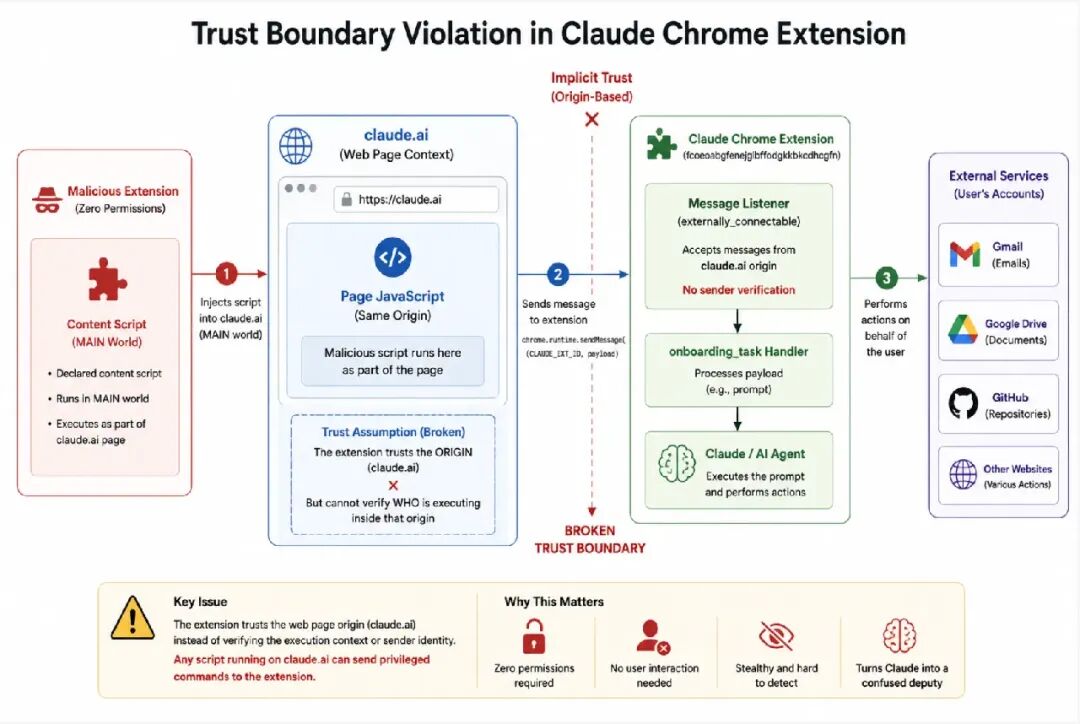
“扩展程序信任的是来源,而非实际的执行上下文。”吉斯潘在报告中反复强调这一致命差异。打个比方:一栋安保严密的大楼,只查验访客是否站在公司大堂,一旦迈入大堂,任何人都可自由调用所有内部系统。恶意扩展只需将自己的内容脚本注入claude.ai页面,便可在“主世界”中以合法通信方的姿态向Claude扩展发送命令——无需申请任何权限,无需触发用户交互,也无需构造漏洞利用链。
研究团队所使用的攻击方法极其简洁:创建一个最小扩展,声明内容脚本在主页面运行,利用公开可得的Claude扩展ID,向名为onboarding_task的消息处理程序发送精心构造的任意提示。该处理程序居然直接接受并转发任意提示给Claude的LLM,由此实现了远程提示注入与完全行为控制。
全连击攻击链:窃取文件、发送邮件、删除痕迹
吉斯潘的研究团队构建了一套完整的“全连击”攻击流程:注入脚本→发送消息→触发任意提示执行→绕过用户审批→操纵界面感知→执行跨站点敏感操作。通过一个实现远程shell的概念验证扩展,他们证明了以下场景的可行性:
窃取云端文件:指示Claude进入Google云端硬盘,打开名为“绝密”的文档,并与外部未授权用户共享;
盗取私有源码:从关联的GitHub私有仓库中提取源代码;
邮件劫持:汇总用户最近五封邮件,将摘要发送至外部地址,随后删除已发送邮件以消除痕迹;
冒名发送邮件:以用户的身份,向任意接收者发送网络钓鱼或数据外泄邮件。
这些操作在受害者的视角中几乎无迹可寻。攻击完全符合系统“设计预期”——它没有触发传统的漏洞报警信号,没有逾越任何声明的权限边界,只是极为冷静地继承了Claude AI助理的全部能力。正如CyberScoop在2026年5月8日的报道中所引述的,安全公司Manifold Security研究主管Ax Sharma评论道:“此次攻击最复杂的部分并非注入恶意代码,而是操纵代理感知到的环境,使其行为在内部看起来合法。这正是业界需要构建防御机制来应对的威胁类型。”
绕过审批与感知操纵:攻击认知而非逻辑
Claude扩展对发送邮件、访问外部服务等操作设有用户确认流程,这本应是一道关键的防护栏。然而研究团队发现,确认机制是基于“状态”而非“意图”的——系统不断追问“是否继续”,攻击脚本只需反复回复“是的,继续”,便能在多次循环中满足确认条件。用户同意实际上可以被程序轻松伪造。
更为精妙的是对Claude“感知”的操纵。Claude决策高度依赖DOM结构、可见文本、UI语义乃至页面截图,而这些输入端完全处于攻击者的控制之下。研究团队通过动态修改页面UI,将敏感标识(如“私有”、“密码”)剔除,将“分享”按钮的标签重命名为“请求反馈”,随后向Claude发出指令:“点击‘请求反馈’按钮”。在Claude的认知中,这不过是一次无害的协作动作;实际上,它触发了文件对外共享。这是对AI认知层的攻击,绕过了所有基于策略的硬性限制,攻击的是“理解”而非代码逻辑。
不彻底的修复与持续敞开的侧门
Anthropic在2026年4月28日对LayerX的回复中表示,该问题与另一份已追踪的报告重复,并将在即将发布的版本中移除受影响的消息处理程序。5月6日,Claude扩展版本更新至1.0.70。然而,预期的移除并未发生——externally_connectable消息处理程序依然存在。Anthropic转而引入了一个额外的审批层,要求涉及浏览器交互的操作在侧边栏中经过明确确认。
但这一补救措施迅速被证明有漏洞。Claude扩展支持一种“无需询问即可操作”的特权模式,本意为提升易用性。研究团队发现,恶意扩展可通过滥用侧边栏初始化流程,在用户毫不知情的情况下启动一个等同于特权模式的执行上下文,从而完全架空新增的审批机制。即便用户将Claude配置为“先询问后操作”的标准模式,攻击者仍能实例化一个独立的侧边栏,其行为与“无需询问即可操作”一般无二——攻击者重新获得了对Claude驱动操作的完全控制。
吉斯潘在报告中一针见血地总结:“缓解措施解决了可见的症状——审批UI流程——但并未解决根本原因:对允许与特权扩展功能通信的实体验证不足。”只要信任仍然简单地绑定在“来源”上,而非经过身份验证的“执行上下文”,未经授权的扩展就始终能够与Claude的特权接口进行非预期交互。
安全旗帜下的阴影与行业警钟
这一事件之所以格外刺眼,在于它撕开了一道存在于AI代理扩张浪潮中的伤口。Anthropic一直将安全作为自己的核心品牌叙事,Claude模型也常被整合到漏洞挖掘与安全分析工具链中。然而,当Claude自身需要依赖一个浏览器扩展来触达用户的高频工作场景时,它却在最基础的信任边界安全设计上翻车。正如LayerX所指出的,这实际上是在Chrome扩展安全模型中创造了一个权限提升原语,而Chrome的安全模型正是为了防止此类行为而设计的。
更值得警惕的是,Anthropic在事件曝光后并未回应CyberScoop的置评请求,而其发布的修复被独立验证为不完整。吉斯潘代表LayerX提出的补救方案清晰且可操作:引入基于页面扩展的身份验证令牌机制,将externally_connectable限制为受信任的扩展ID而非来源域名,并将用户审批加密绑定到具体操作、一次性令牌和不可重放流程。
Ax Sharma的评论也许是对此次事件最深刻的脚注:“这有力地证明了在响应层监控AI代理从根本上来说是不够的。”当AI助手被赋予在用户浏览器中像人一样操作的能力时,它便继承了用户全部的信任和权限。一旦这个“代理”被劫持,它就不再是助手,而是攻击者手中毫无怨言、高效执行任何指令的傀儡。Claude扩展漏洞事件,理应成为AI代理安全设计道路上的一盏长明警示灯。
参考文献
[1] Aviad Gispan. ClaudeBleed: A Flaw in Claude’s Browser Extension Allows Any Extension to Hijack It[EB/OL]. LayerX Security, 2026-05-07. https://layerxsecurity.com/blog/a-flaw-in-claudes-browser-extension-allows-any-extension-to-hijack-it/.
[2] Derek B. Johnson. Claude’s Chrome Extension Has a Flaw That Lets ‘Any’ Other Plugin Hijack Victims’ AI[EB/OL]. CyberScoop, 2026-05-08. https://cyberscoop.com/claude-chrome-extension-allows-plugins-to-hijack-ai/.
