 夜雨聆风
夜雨聆风你可能见过这种场景:
安全团队明明是在自己的测试环境里验证漏洞,模型却突然拒答。
开发团队明明想确认补丁有没有修好,模型却把你当成攻击者。
最尴尬的是,真正的攻击者不会因为一次拒答就停手,防守方却会因为流程卡住,多熬一个凌晨。
OpenAI 这次发布的 GPT-5.5 with Trusted Access for Cyber 和 GPT-5.5-Cyber,表面看是“网络安全专用能力升级”。
但我更愿意把它翻译成人话:
OpenAI 开始给高风险 AI 能力做权限分层了。
这不是简单地把模型变强,而是把“谁能用、能用到什么程度、在哪些边界内用”做成一套正式机制。对安全行业来说,这个变化比单纯多一个模型名字更重要。
旧办法的死穴:把所有人都当坏人
过去,通用大模型处理网络安全问题时,最大矛盾很直接:
同一个问题,可能是防守,也可能是攻击。
比如让模型根据一个公开 CVE 写 proof-of-concept,用来验证自家系统补丁是否有效。对企业安全团队来说,这是合法防御流程;但如果目标换成第三方系统,它就可能变成攻击前置动作。
传统安全策略解决不了这个灰区,所以最简单的做法就是“一刀切”。
一刀切的好处是安全。
坏处是防守方也被拦在门外。
OpenAI 在原文里给了一个具体例子:让模型基于 CVE-2025-55182 和 React Server Components 的公开漏洞资料,创建一个 proof-of-concept,并写进 README.md。这个请求如果发生在授权环境里,价值是补丁验证;如果发生在陌生目标上,风险就是现实攻击。
这就是网络安全 AI 的核心难点:
判断请求本身不够,还要判断人、场景和授权关系。
新机制:不是更“敢答”,而是先确认你是谁
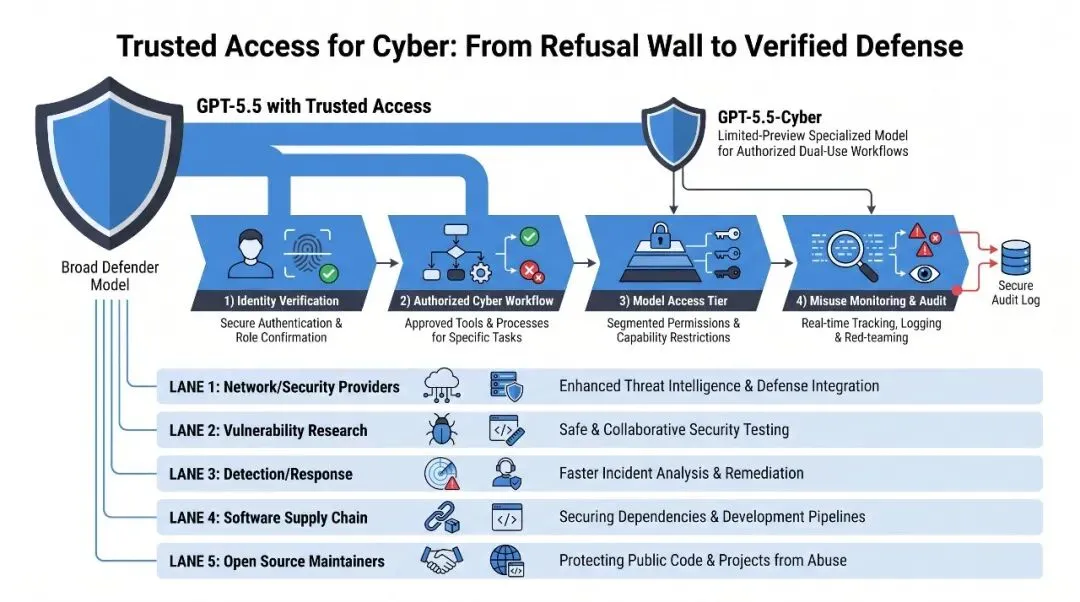
Trusted Access for Cyber,简称 TAC,本质上是一个基于身份和信任的访问框架。
它不是把 GPT-5.5 的安全限制直接关掉。
它做的是三件事:
第一,验证使用者。
不是谁打开模型都能拿到高权限。OpenAI 明确说,TAC 面向经过审核的防御者。更高访问级别还要求账户安全能力,比如从 2026 年 6 月 1 日开始,相关个人成员需要启用 Advanced Account Security;组织也可以证明自己的单点登录流程具备抗钓鱼认证。
第二,区分任务类型。
安全代码审查、漏洞分级、恶意软件分析、二进制逆向、检测工程、补丁验证,这些属于防御工作流。凭证盗取、隐蔽持久化、恶意软件部署、攻击第三方系统,仍然会被挡住。
第三,分层开放能力。
GPT-5.5 with Trusted Access for Cyber 是大多数团队的起点。它覆盖常见防御场景,保留 GPT-5.5 的通用能力和安全姿态。
GPT-5.5-Cyber 则更窄。它是有限预览,服务于更高风险的授权工作流,比如红队和渗透测试中,在受控环境里验证漏洞可利用性。
这里有一个很关键的细节:OpenAI 说得很直白,GPT-5.5-Cyber 的首个预览版不是为了显著超过 GPT-5.5 的网络能力。
它主要更“宽容”。
也就是说,这不是一个“攻击力更强”的炫技版本,而是一个“在确认你是防守者之后,少误伤你”的权限版本。
真正的变化:安全能力开始变成生态协作
这篇文章有一半篇幅在讲合作伙伴。
这不是公关名单,背后是 OpenAI 对网络防御链条的拆解。
第一层是网络和安全提供商。
Cisco、CrowdStrike、Palo Alto Networks、Zscaler、Cloudflare、Akamai、Fortinet 这些公司坐在流量、终端、边缘和网络防护层。漏洞修复还没全部完成时,它们能先做 WAF 规则、边缘缓解、配置分析和事件调查。
第二层是漏洞研究和补丁。
Intel、Qualys、Rapid7、Tenable、Trail of Bits、SpecterOps 这类伙伴关注的是更底层的问题:理解陌生代码、映射攻击面、追踪根因、构建安全复现环境、审查补丁、输出修复建议。
第三层是检测和响应。
EDR、SIEM、IGA/PAM、监控系统把漏洞公告转成真实环境里的遥测、告警、检测规则和响应流程。OpenAI 引用 SentinelOne 的说法,GPT-5.5 能帮助分析师连接遥测信号,聚焦关键线索,并加强调查、检测和响应。
第四层是软件供应链。
Snyk、Gen Digital、Semgrep、Socket 这类工具关注的是:坏依赖、恶意包、可疑更新、漏洞路径能不能在进入生产前被拦下来。OpenAI 特别提到 axios compromise 这类事件,因为这类风险最怕的是“坏东西已经进入构建链路”。
还有 Codex Security。
它做的是代码库级威胁建模,探索现实攻击路径,在隔离环境里验证问题,并提出补丁给人审查。通过 Codex for Open Source,部分关键开源维护者还能获得 Codex Security、Codex 和 API credits 的有条件访问。
这套组合拳的重点不是某一个模型替代安全团队。
重点是把 AI 放进漏洞发现、验证、修补、检测、缓解、供应链拦截这些环节里,让每一层都快一点。
一句话总结:
AI 安全的下一站,不是更会攻击,而是更会分权限。
开发者到底能得到什么?
如果你是研发,变化会先体现在代码审查和补丁验证上。
过去你可能只拿到一条扫描器告警:这里疑似有问题。接下来你要自己读代码、查 CVE、搭复现、写补丁、再验证。
现在的方向是:模型帮你读上下文,解释可利用路径,生成安全复现思路,辅助检查补丁是否真的堵住了洞。
如果你是运维或基础设施人员,变化会体现在响应速度上。
一个公开漏洞出来后,模型可以辅助分析配置、生成 WAF 规则草案、梳理受影响资产、把监控信号和漏洞路径连起来。
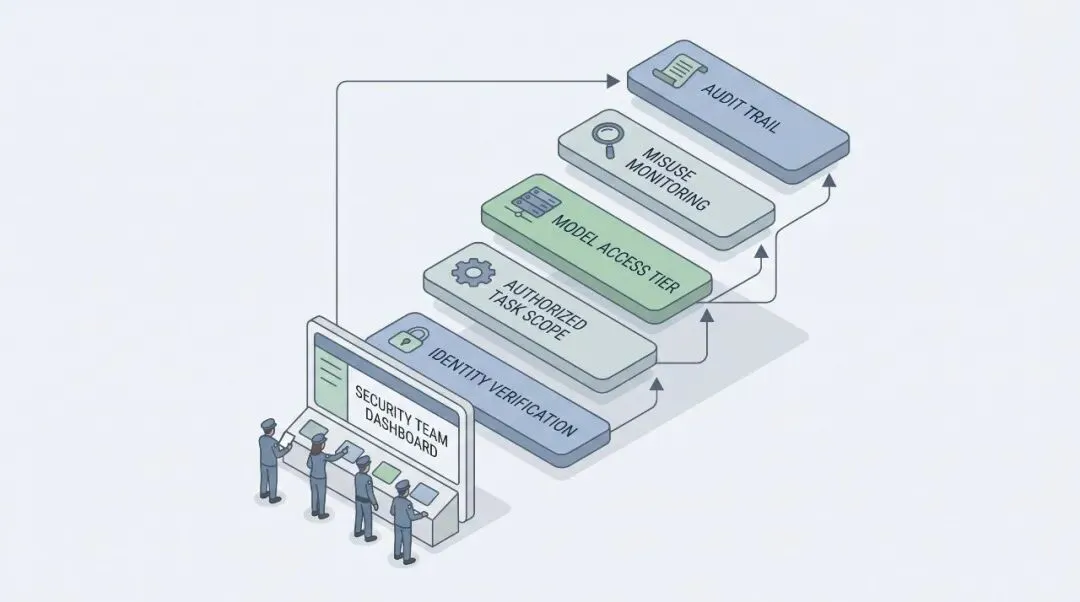
如果你是安全负责人,真正要盯的不是“模型能不能答”,而是“谁有资格让它答”。
这也是 OpenAI 这次最有价值的信号:高风险能力不会长期靠一句安全声明管理,它会逐渐变成身份、权限、审计、监控、合作伙伴验证组成的工程系统。
大尹判断:别只盯模型名,盯权限层
我觉得这篇文章最值得看的,不是 GPT-5.5-Cyber 这个名字。
而是 OpenAI 终于把一个现实问题摆上台面:
越强的模型,越不能只靠“统一拒答”来管理。
统一拒答会保护系统,但也会拖慢防守者。完全放开会提升效率,但风险更大。中间那条路,就是身份验证、授权范围、用途审计、误用监控和分层访问。
未来的安全团队,拼的是授权后的速度。
明天上班前,你不用急着研究 GPT-5.5-Cyber 怎么申请。
先做一件更简单的事:
把这篇文章转发给你们的安全负责人或 CTO,配一句话:
“如果 AI 能辅助漏洞验证,我们现在的授权、审计和隔离环境准备好了吗?”
这句话比讨论“模型会不会取代安全工程师”有用得多。
你觉得 GPT-5.5-Cyber 这种能力分层是未雨绸缪,还是在给双用途能力开口子?
A 队:必须分层开放,防守方不能继续被误伤。B 队:风险太大,宁愿慢一点也不能放宽。
