 夜雨聆风
夜雨聆风上个月,一个朋友跟我吐槽 Claude Code。
他说他卡在一个 bug 上,来回搞了十几轮,Agent 死活改不对。他的结论是:这东西还是不行,吹过了。
我问他:你半年前试过吗?
他说试过,更烂,当时连那个 bug 在哪都找不到。
我说:那再过半年呢?
他没接话。
这个沉默,就是我写这篇文章的原因。我把反复跟人讲的四件事凑成了一个判断框架,不是要说教,是真的觉得很多人卡在一些可以提前绕过的坑里。
大模型会越来越聪明
过去几年,大语言模型行业有一条被反复验证的规律:只要继续往里面投算力和数据,模型就会变得越来越聪明、越来越快、越来越便宜。
行业里管这个叫 scaling law(规模定律)。这个词不重要。每次你开始怀疑 AI 是不是到顶了、是不是吹过了,过半年,新模型出来,又打脸一次。
规律到目前为止从未失效。基准评分一直在涨,单次能处理的上下文从几十 K 涨到几百 K 甚至几 M,推理越来越深,速度越来越快,价格越来越低。
一个方向。能力持续增长。
这一条不是"第一章",是底座。后面三个反转之所以能成立,全是因为这台发动机还在转。
很多你今天觉得是"问题"的东西,本质上只是 scaling 还没走到那一步。context 不够大、推理太慢、价格太贵、工具调用太慢,这些不是原理性限制,是阶段性的。
反过来,很多今天你以为是"答案"的东西,把 Agent 当人管、什么复杂问题都丢给多 Agent 协作,本质上是你把阶段性方案当成了最终解。
好,底座说完了。聊三个反转。
反转一:你把 Agent 当编程工具。但它正在变成产品本身。
大多数人第一次用 Claude Code,直觉判断都一样:这是个超级好用的编程助手。我给需求,它写代码,我 review,我部署。Agent 是工具,软件是产品。一清二楚。
这个判断在两三年前完全正确。
但如果推理成本继续往下走,到一次调用只要几分钱、零点几秒,Agent 就没道理只待在开发环境里了。它会往前走一步,进入产品内部,变成产品运行逻辑的一部分。
不是在开发的时候帮你写代码。而是在产品上线以后,在用户看不见的地方,实时做决策、生成内容、调整策略。
我管这个叫智能体运行体。不是工具,而是产品内部持续运转的一部分。用户消费的不再是程序员提前写死的一段逻辑,而是运行体实时跑出来的结果。
举个离我们没那么远的例子。
你今天打开信息流产品刷推荐,推荐算法是人写的一段代码,跑在服务器上。很聪明,但它的聪明是"设计出来的"。工程师提前想好了要优化哪些指标,然后写死逻辑。
现在你想象一个版本:推荐不是固定算法生成的,而是一组 Agent 在实时理解你的阅读状态、当前的信息质量、话题的热度和深度,动态编排出来的。没有"提前写死"的逻辑,每次推荐都是一次即时决策。
那这个产品还是"一个 app"吗?它的核心逻辑,已经不是一段固定的代码了,而是一台持续运行的 Agent 引擎。
这不是科幻。Claude Code 本身如果被嵌到代码托管平台里,每次有人提 PR,Agent 自动 review、自动修明显的 bug、自动补测试,它就不是"一个命令行工具"了,它是"一个自动化的代码质量运行体"。OpenCode、Codex、OpenClaw,这些工具都在往同一个方向走。
还有一个信号,可能比这些产品案例更直接。
你想想你在 Claude Code 里面写的那些 skill 文件。你花了很多心思去写规则、定义边界、告诉 Agent 什么能做什么不能做。这些 skills 本质上是什么?是对模型目前能力不足的补丁。模型还不够懂你、不够稳定、不够可控,所以你要给它外挂一份说明书。
但模型会越来越聪明。那这些外挂的 skills 会发生什么?
它们会被内化。
就像提示词工程。两年前你要写一长串"你是一个专业的……""请一步一步思考……""请确保……",精心设计的 prompt 就是那时的 skill。今天大部分已经不需要了。模型自己就知道该怎么回答、该用什么格式、该注意什么边界。你精心设计的那套 prompt,变成了模型的一个默认开关。
skills 的命运也一样。今天你辛苦写的 skill 文件,迟早会被下一代模型内化成默认能力。不是因为 skills 写得不好,是因为模型不需要它们了。
而这正是 Agent 从"工具"变成"运行体"的另一个证据。工具需要说明书,运行体不需要。
所以第一个反转是:别只把 Agent 当工具。它正在变成产品内部的东西。
但等等
你说 Agent 在生产环境里不可控,谁敢把它嵌进产品?
你说得对。但这个顾虑的本质是什么?是现在的推理还不够便宜、不够快。如果每次 Agent 调用要三秒、花几毛钱,你当然不敢让它跑高频决策。但如果降到 0.3 秒、半分钱,"不可控"就不再是技术问题,是成本问题。
而成本,是 scaling 最确定会解决的方向。
反转二:你像管团队一样管 Agent。但 Agent 根本不是人。
第二个直觉也很有道理。
从 vibe coding 到 SWE-Agent,从 Cursor 到 Manus 到 Claude Code,人们很自然地做了一件事:既然 Agent 可以写代码、review 代码、跑测试、提建议,那不就是个虚拟开发团队吗?
于是项目管理、OKR、daily standup、code review 流程,全被套上去了。
这条路走通了。很快。但红利更快吃完了。
我见过一个团队的配置:三个 Agent 组成一个"开发小组",一个写代码,一个 review,一个当 PM 做协调。结果呢?三个 Agent 花了二十分钟互相确认需求、等待对方回应、反复调整方案。最后生产出来的代码,一个人用 Claude Code 十分钟就写完了。
看得我手心出汗。那二十分钟里 token 在烧,什么都没出来。
问题不出在"协作"这个方向上。问题在于,人类管理学的很多方法是为人设计的:人有内驱力、人的沟通天然带信息量、人的层级能加速决策。但 Agent 不具备这些东西。
Agent 的 memory 是有限的,干着干着就忘了上下文。Agent 的连续执行能力是有限的,工具链一长就容易断。Agent 的 function calling 接口是有限的,不是你想让它调什么就能调什么。
你把管人的方法套在一个不是人的东西上,不但不会提效,反而会放大它的每一个弱点。
X 和 Reddit 上能找到大量这种吐槽:Agent A 写了一段代码,Agent B review 的时候改了三行,Agent C 回来把 B 改的那三行又改了回去。然后它们三个开始互相解释。你坐在屏幕前,看着 token 在烧,什么都干不了。
"过度交流""七手八脚""随时停工",不是段子,是亲身经历。
所以第二个反转是:管理学套利这波红利,快吃完了。剩下的,是被管理流程拖累的 Agent,和淹没在沟通里的产出。
等一下
memory 太短、function calling 太慢、上下文容易丢。这些都是真的。
但它们是原理问题吗?
不是。一年前 context window(上下文窗口)几十 K,现在几百 K。一年前推理速度是现在的几分之一,价格是现在的几倍。这些全在变。
一年之后,很多今天让 Agent 协作卡壳的硬伤,可能已经不存在了。
真正的问题是:到那时候,你还在用管人的方法管 Agent,那你才是瓶颈。
反转三:你以为 Agent 能搞定一切复杂问题。但它最擅长的,反而是"简单干净但巨难"的那种。
这是我自己想清楚最晚的一条。
你用 Claude Code 解决了三天调不通的编译问题,让它写了一组你没耐心写的测试,让它重构了一个烂尾半年的模块。它全做到了。
于是你自然地觉得:这东西能搞定一切复杂问题。
但这里有一个区分很关键。"复杂"有两种,这两种看起来没区别,但其实是两件事。
第一种复杂:问题定义很简单,边界很清楚,但搜索空间巨大。
一道数学证明,要证什么明明白白。但证明路径可能有几万条,绝大多数是死胡同。一个编译器,输入输出是确定的,但实现方案有几万种排列。蛋白质结构预测,物理规则固定,但构型的组合是天文数字。
这类问题的难点在穷举、在探索、在一个干净答案藏在一百万个错误答案里面。这恰恰是 Agent 最擅长的:它不怕大,只怕乱。
第二种复杂:问题定义开放,边界模糊,系统高度耦合。
微信的一百种功能,不是"设计"出来的,是十几年里跟用户行为、商业需求、监管政策一点点磨出来的。
Facebook 的底层 infra,支付宝后面几百上千个基金和风控模型,这些系统是"长"出来的,不是"写"出来的。
每一个改动,都牵着一大堆你无法提前穷举的变量。
解决这类问题,Agent 不是不能参与,但它不能替代人。因为答案不在搜索空间里,答案在人与环境反复碰撞的那个过程里。
我给第一类问题起了个名字:定靶问题。它有三个条件:
第一,问题定义简单、干净、封闭。第二,解决方案的搜索空间巨大,可能有几百到几万种天马行空的方案,绝大多数是错的。第三,验证成本极低,验证的代价是设计代价的千分之一。
用人话说:答案可能藏在一百万个错误里,但你一眼就能认出哪个是对的。这就是 Agent 的甜点区。
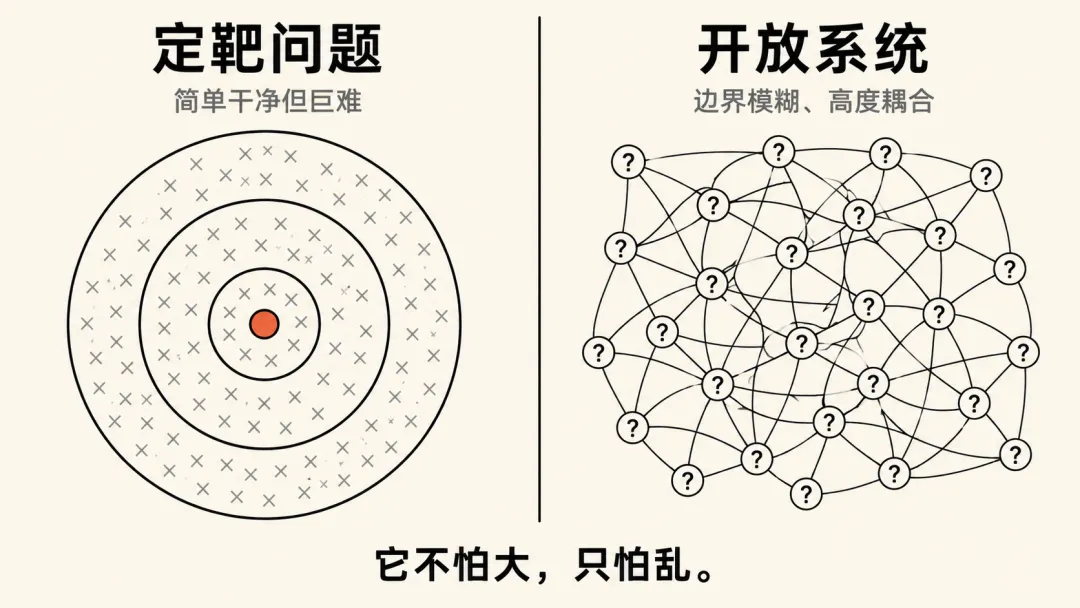
数学题,你解可能要一百步,验证只需要带回去算一步。编译器,设计可能要几万行,验证只需要两千个 test case 全覆盖。Lean 证明、电路模拟、游戏关卡测试、行为经济学仿真,全是这个类型。
反面呢?给微信加一个新功能、给支付宝调一个风控策略,你没办法把它们定义成一个"简单干净的问题",也没办法用一个标准化验证来判断"做好没有"。
所以第三个反转是:Agent 最擅长的不是最"乱"的问题,是最"干净但难"的问题。
但等等
那复杂开放问题 Agent 永远做不了?
也许吧,我也不确定。
我确定的是,今天做不到,不代表三年后做不到。
你想想上下文窗口从几十 K 涨到几 M 才用了多久。同一个增速再推三年,今天的"脏",可能就变成了明天的"干净"。
当 reasoning 足够长、context 足够大,脏问题会慢慢变干净。
但在那之前,先捡干净的做。在 scaling 把边界推过来之前,把定靶问题做到极致。
四条放在一起,其实就一件事
写到这里,回头看这四条,说实话,最开始我也不确定它们能不能串起来。
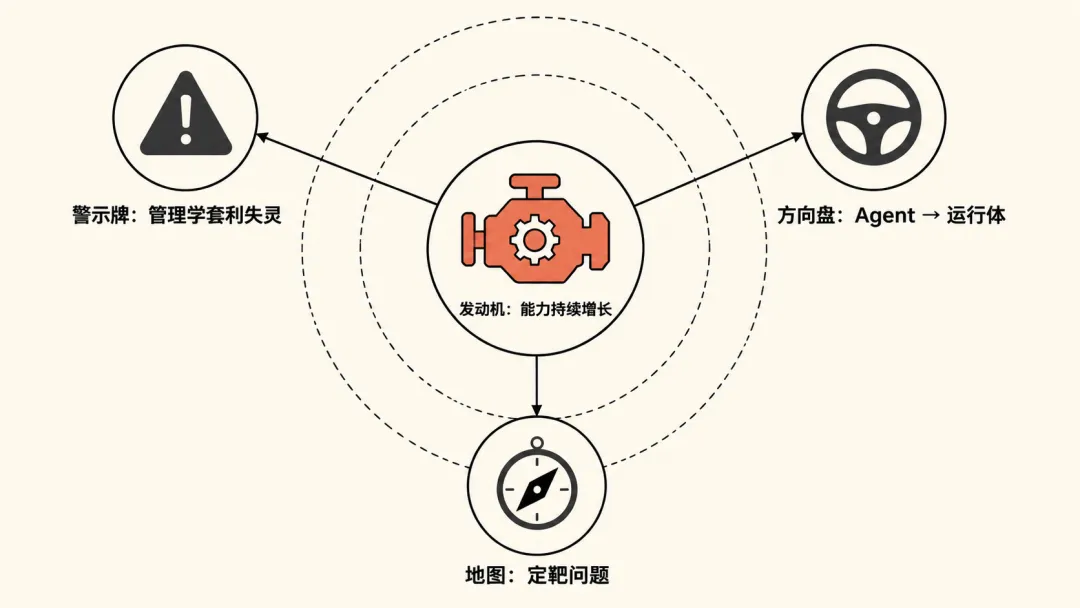
第一条,大模型能力持续增长。底座,决定你能跑多快。
第二条,管理学套利正在失灵。告诉你别再用管人的方法管 Agent 了,那条路快走到头了。
第三条,Agent 正在变成产品的运行体。告诉你该往哪跑:把 Agent 嵌进产品里,别只用完就丢。
第四条,定靶问题是当下的最优解。告诉你哪条路对、哪条路不对。
但我现在也不敢说这四条就是最终答案。每多试一个产品、多看一个团队的做法,里面的细节就会出来打脸一次。仅供参考,大家自行判断。
说实话,这些对你有什么用
下次有新的 AI 产品炸出来,你不用跟着兴奋,也不用跟着慌。只问一个问题:
"它现在不够好是因为 scaling 还不到,还是方向本身就错了?"
推理太慢?context 太小?价格太贵?等一等,这些都会变。
有人跟你说"我们把十个 Agent 组成一个公司,按阿米巴模式管理"?你大概率可以不用跟。
判断力在这个阶段,比信息量值钱。
半年前我第一次把这些观察放在一起,自己也不太确定。Agent 不是工具,也不是人。
它是一种还没有名字的存在形态。这句话现在听起来可能有点绕,但我猜三年后回头看,就像"软件正在吃掉世界"一样,会变成一个你不觉得需要解释的常识。
也许是我想多了。但那台发动机还在转,这一点是确定的。
