 夜雨聆风
夜雨聆风本文作者为康奈尔大学 Peter McMahon 教授,他在学术休假期间为其所处的 Unconventional AI 公司撰写了这篇博客。放眼全球,致力于研究非传统(新型)计算范式的团队,其核心使命高度一致:实现 AI 算力与能效的数量级提升。
McMahon团队的研究重点在于探索物理神经网络在提升 AI 能效与计算速度方面的潜力。物理神经网络通过直接利用可训练的物理系统进行 AI 推理,试图充分发挥物理学固有的自然计算特性,同时大幅简化硬件物理层与算法/应用层之间的大量计算机抽象层次,从而显著提升效率与速度。其团队于 2022 年在Nature期刊上发表的论文,通过实验证明:即使在存在模拟噪声和模型缺陷的条件下,仍然可以使用反向传播算法训练深度物理神经网络。这一发现为直接借助物理系统带来实际应用效益提供了重要契机。
笔者持续关注 McMahon 团队的研究进展,该团队也关注我们在模拟计算方向的工作,并曾邀请我的学生左濮深就高精度模拟计算开展线上交流。

——孙仲(北京大学)
Unconventional AI 的愿景是:在数据中心应用场景下,面向生成式 AI(GenAI)推理任务,相比在传统先进 AI 硬件上运行的最先进 AI 模型,实现 1000 倍的能效优势。我们采取的方法是:从零开始协同设计 AI 模型与其运行的硬件,让两者共同演进,使硬件尽可能逼近当前 CMOS 技术的物理极限,同时使运行其上的 AI 模型能够最优地匹配硬件的性能特征。
在这篇博客中,我们将阐释实现该 1000 倍优势所面临的两大挑战,并介绍我们为应对这些挑战所采取的技术路线。尽管新型 AI 模型与新型硬件的开发同等重要,本文仍将重点聚焦于硬件层面的考量,同时也会指出硬件设计与 AI 模型设计之间的相互作用如何为能效提升带来新的机遇。
基线是什么?
我们对比的基线是:在传统先进硬件(如 GPU 或 TPU)上运行最先进的AI 模型,产生相同质量输出所需的端到端系统能耗成本。我们优化的指标是:每 Token 焦耳数(适用于 GenAI 文本)或每图像焦耳数(适用于 GenAI 图像),且在相同输出质量下进行等质比较。我们同时也将延迟、吞吐量、芯片面积和价格作为次级但重要的考量指标。
我们并不关注 TOPS(每秒万亿次操作)或 TOPS/W这类算术指标——这些指标并非最终决定因素,且极易导致“苹果比橙子”式的无效比较。
当前能效的最先进水平如何? ML.ENERGY 排行榜中,每Token 焦耳数和每图像焦耳数的取值范围极大。这种差异部分源于生成的 Token 和图像的质量不同(而质量又受模型架构、参数数量、训练方法、数据集等因素控制)。不过,为给出代表性数据:最大规模的模型在文本生成上约为10 焦耳/Token,图像生成则超过10,000 焦耳/图像。
现代系统能够达到的吞吐量约为每用户每秒 1000 Token(即无批处理场景),采用 8-GPU 系统,最大功耗约 14 kW1。
我们还需要瞄准未来的趋势:对我们而言,有意义的基线不是 2026 年的最先进水平,而是我们预估到约 2030 年,传统方法可能达到的水平。
挑战1:数据移动
推理的能耗成本主要并非来自计算(算术运算),而是来自数据存储/访问与移动。Horowitz 早在 2014 年就指出了在硬件加速器中考虑存储器访问能耗的重要性,强调了算术运算与片上/片外存储器访问之间能耗量级的巨大差距。谷歌于 2021 年更新的 CMOS(7 nm)数据显示了同样的差距:8 位整数乘法与从片外高带宽存储器(HBM)读取 8 位操作数之间的能耗差异超过 1000 倍。
然而,自 2014 年以来,情况在另一个关键维度上变得更加严峻:模型规模已从数百万参数增长到超过 1 万亿参数,活跃参数超过 1000 亿。这意味着模型已经大到无法放入单个芯片的片上存储器中。因此,现代推理加速器(如 B200 GPU 或 TPU v8i)中,存储器访问成本往往最大:主要是片外 HBM 访问,而非片上 SRAM 访问。
模型无法装入片上存储器这一事实,构成了提升能效的核心挑战。据估计,在当前 GenAI 推理数据中心中,片外存储器(HBM)消耗了 GPU 超过 20% 的功耗。如果不能降低片外存储器的能耗成本,就不可能实现超过 10 倍的能效提升(参见下文挑战2)。
通过一些粗略估算,可以帮助建立对存储器问题的直观认识。假设你在一个具有1000 亿(10¹¹)个活跃参数的 AI 模型上进行推理。每 Token 能耗会是多少呢?
仅计算算术运算:假设每个参数进行一次8 位整数乘法100B × 0.07 pJ = 0.007 焦耳/Token
将整个模型存储在SRAM 中,且仅计算 SRAM 读取参数的能耗100B × 2 pJ(每 8 位)= 0.2焦耳/Token2
将模型存储在片外HBM 中,且仅计算 HBM 读取参数的能耗100B × 39 pJ(每 8 位)= 3.9焦耳/Token3
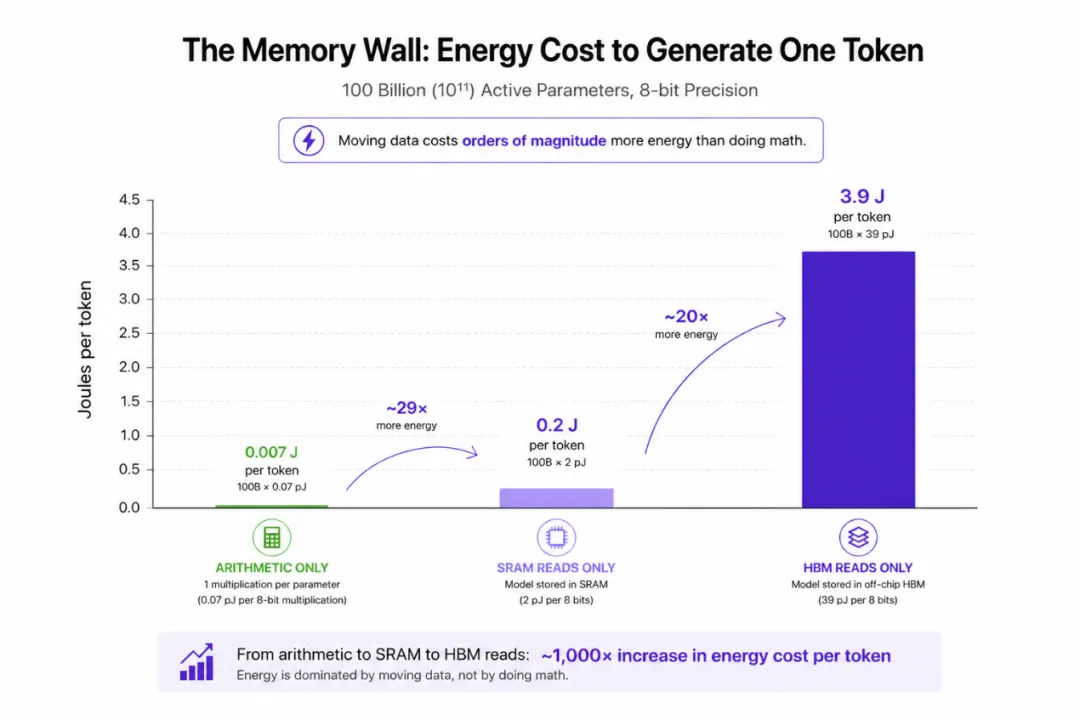
从这些粗略估算可以看出,要实现1000 倍的优势,必须解决存储器问题。仅从片外存储器转向片上存储器是不够的:从片外 HBM 转向片上 SRAM,在极理想条件下最多提供10 倍的优势(而对于 Transformer 模型,实测的每 Token 焦耳数收益约为1.5 倍)。
上述计算未考虑KV 缓存。对于长上下文长度(如 32k),KV 缓存可能需要读取约 50 GB 的数据,与我们假设的模型参数读取量(100 GB)相当。因此,仅 KV 缓存的片外 HBM 读取就可能贡献约2 焦耳/Token。对于更长的上下文长度(如 1M),KV 缓存可能超过 1 TB,需要多个GPU 才能存储,仅读取 KV 缓存就需约100焦耳/Token。
如果我们保持乘累加(MAC)算术运算的能耗不变,同时消除所有来自存储器的能耗,我们很可能立即获得约1000 倍的能效优势。这从另一个角度说明:实现1000 倍优势的关键在于存储器,而非单个算术运算的效率。
挑战2:阿姆达尔定律
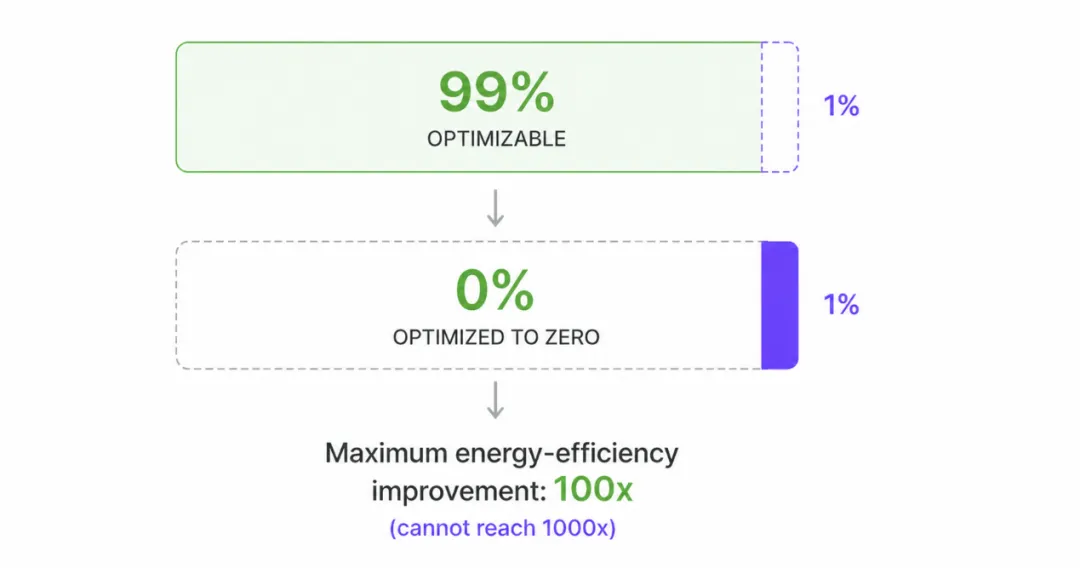
在能效语境下,阿姆达尔定律指出:通过降低系统某部分的能耗所能获得的系统级改进,受限于该部分原本在总能耗预算中的占比。这构成了实现 1000 倍改进的重大障碍,因为它意味着:即使你对系统大部分组件做了巨大改进,那些在原始能耗中占比很小的部分也可能阻止你实现目标。
例如,假设你专注于改进系统中某部分的能效——这部分在优化前占系统总能耗的 99%。即使你将这部分能耗降至零,所能实现的最大系统级改进也仅为 100 倍。
在设计 AI 推理硬件时,阿姆达尔定律带来的挑战反复出现。例如:
仅解决占能耗 99% 的核心部分,而将占 1% 的开销任务留待优化,无法达成目标。
仅解决计算的能耗,而忽略数据的能耗,同样无法达成目标。
针对Transformer 模型,仅消除线性层的能耗而不处理注意力层的能耗,也无法达成目标。
在Unconventional AI,我们的理念是从头开始并发设计硬件及其上运行的 AI 模型,这有助于避免那些运行现有模型时难以降低能耗的“微小”成本项——这些成本项原本可能阻碍1000 倍优势的实现。
需要解决哪些开放问题?
挑战1 与挑战2 共同意味着:我们必须:
1.减小模型规模(例如,利用硬件中的动态特性,从而高效复用参数),和/或
2.降低存储器成本,和/或
3.最小化数据移动(例如,尽可能将存储与计算保持在同一局部区域)。
我们需要足够高密度的存储器,以便将整个模型放入片上存储器或靠近芯片的 3D 集成存储器中。我们需要局部性,使得存储在存储器中的数据在芯片上物理接近的位置被使用。假设在 2D 集成芯片之间或单个芯片全宽度上传输数据的能耗为 2.4 pJ/字节,那么对于一个 1000 亿参数的模型,仅数据通信就将消耗超过0.2 焦耳/Token。这一数值足以使能效提升被限制在约 10 倍以内,无法超越当前最先进水平。
挑战2 意味着:我们必须优化系统的几乎全部组件才能达到 1000 倍,并且任何开销都不能超过原始能耗的0.1%。
如何实现 1000 倍优势?
以下是我们可采用的一些技术路线。每条路线都可以走到极致,也可以只走一部分。例如:不必将硬件完全定制为某种计算,但比当前 GPU 做更多的定制化。
1.针对特定 AI 模型架构或模型架构类别的定制:设计硬件架构以匹配AI 模型的架构,从而最小化数据移动。例如,数据流架构可以在 CMOS 中采用空间布局,使神经元激活值传递到神经网络下一层的距离最短,从而降低能耗。
2.针对特定 AI 模型的定制(硬连线参数):比将硬件精确映射到目标 AI 模型架构更极端的做法是,通过将模型参数硬连线到芯片中,定制为该模型的某个具体训练实例。这是 Taalas 公司以及一些学术论文所倡导的方法。
3.参数效率:通过用更少的参数和更多的计算进行权衡,减少所需的总存储容量。传统机器学习社区中关于深度均衡模型和递归模型的工作对此进行了探索。在电子电路中实现的物理动态系统可以自然地吸收这些方法的思想,在某些情况下,用连续时间物理系统实现它们甚至更为自然。
4.稀疏性:稀疏递归系统可以达到与稠密前馈网络相当的精度。工程化的电子动态系统如果具有稀疏性,其功耗可以更低。
5.利用动态特性避免注意力机制:注意力机制以及推理中 KV 缓存的加载,是Transformer 在 GPU 上实现的主要瓶颈,对于任何实现注意力机制的非传统硬件加速器可能也是如此。状态空间模型(如Mamba)已证明,无需注意力机制也能获得高质量的 Token。这些方法和思想可以应用于实现神经网络的新型硬件。
6.允许与当前神经网络非数学同构(即作为物理神经网络的 CMOS 电路实现):AI 和神经网络并不需要精确的矩阵-向量乘法;它们需要的是具有表达能力的参数化输入-输出关系。不要强行让电路精确实现矩阵-向量乘法,而是允许它们以最自然、最节能的方式运行。这一理念同时适用于模拟和数字电路。例如,已有研究探索了耦合振荡器(模拟)和训练好的查找表(数字)作为神经网络。
CMOS电路作为物理神经网络需要具备哪些理想特性?
表达能力强:能够表示许多复杂的非线性函数。
参数丰富:拥有大量可训练参数(可编程或硬连线)。
难以被模拟替代:如果一个电路用当前数字处理器进行模拟所需的能耗低于其物理运行所需的能耗,那么它就不是一个有前景的候选方案。我们需要的电路像风洞一样:物理运行比数字模拟更便宜。
可通过梯度下降训练:我们必须能够学习到使电路产生期望行为的参数。如果希望使用在数字计算机上运行的反向传播进行训练,电路需要有一个足够精确的行为模型。
使用模拟电路:在低精度计算方面,模拟电路相比数字电路具有潜在的能耗优势。我们可以在能获得收益的地方使用模拟电路,其余地方使用数字电路。
容忍噪声:不要过度设计电路以达到过高的信噪比——这通常以能耗为代价。如果在训练过程中考虑了噪声,神经网络可以容忍一定程度的噪声。
最终,要实现 1000 倍的能效优势,我们可能不会依赖单一技术路线贡献全部优势。相反,我们可能通过工程实现10 个 2 倍或3 个 10 倍的因素,累加出 1000 倍的优势。
1这提供了另一个数据点,与约 10 焦耳/Token 的估计一致。
2这是一个乐观估计,因为它假设使用 1 MB(而非更大)的 SRAM,并且计算结果可以在本地使用,即无需额外的数据移动能耗。
3一个重要说明:传统实现(如 GPU)试图通过多次重用从片外存储器读取的值来分摊片外存储器读取成本,例如一次处理一批查询而不是单个查询。这里计算的是零重用极端情况下的数值。
