 夜雨聆风
夜雨聆风做 AI 技术越往后越明白:
只会调 Python API、搭应用 demo,永远停在表层; 想进 AI Infra、做大模型推理、冲击大厂核心岗,必须啃到底层内核。
但现实学习很尴尬: 入门教程太浅,只教调用,不讲实现; 工业源码又太深,llama.cpp、vLLM 上万行代码,各种优化揉在一起,新手根本抓不住主线,越看越懵。
所以这次我们训练营新开一个纯落地、偏底层、重工程的实战项目:mini-llama.cpp。它不是调包,不是封装,而是用纯 C++ 代码实现一个完整的 LLaMA-style 推理内核,并提供一个类似 Ollama 的终端聊天程序。
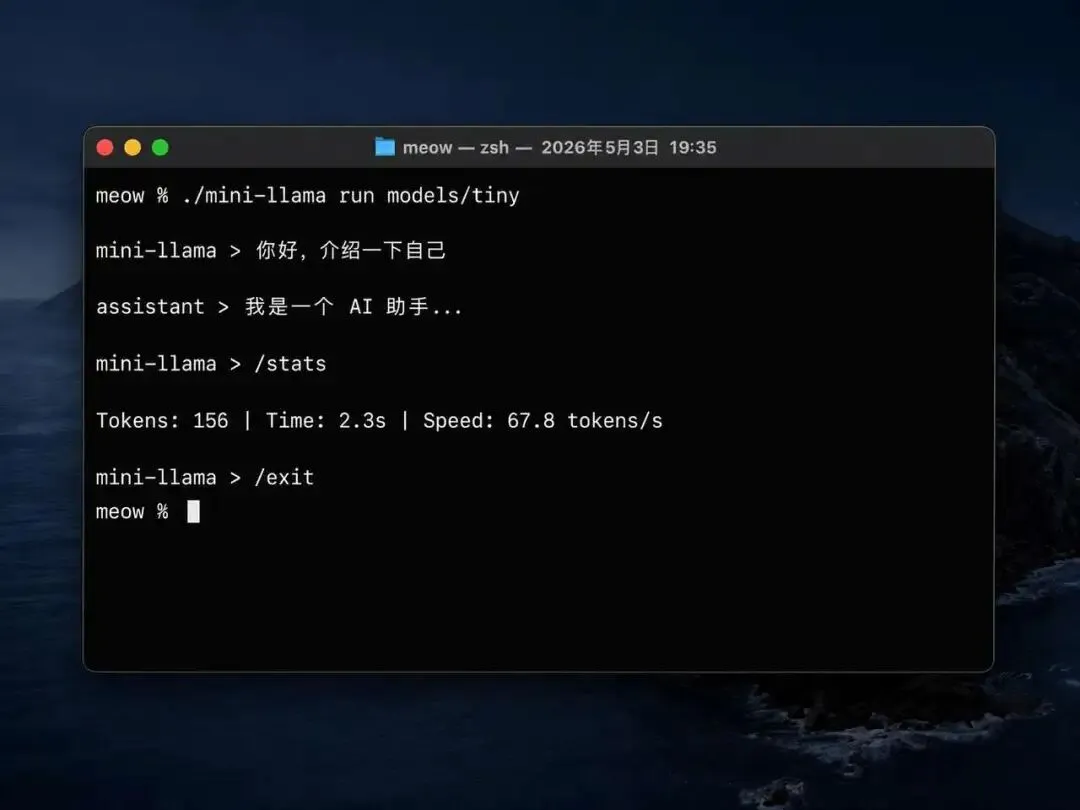
完成这个项目后,你能自信地说:"我从零实现过一个 LLM 推理引擎,能跑、能聊、能调试。"
为什么要做这个项目?
AI Infra 是 2026 年最热的方向
OpenAI、Anthropic、Google 都在疯狂优化推理性能 vLLM、llama.cpp、TensorRT-LLM 是行业标准工具 大厂 AI Infra 岗位需求暴涨,薪资远超传统后端
但市面上的学习资源有两个问题:
要么太浅:只讲 Python 调 API,碰不到 C++ 推理内核 要么太深:直接啃 llama.cpp 上万行代码,看不懂主线 mini-llama.cpp 填补了这个空白
✅ 用一个可运行、可调试、可理解的 C++ 项目
✅ 把 LLM 推理的核心链路讲清楚
✅ 提供类似 Ollama 的终端聊天体验
✅ 对标工业级项目(llama.cpp、vLLM)
项目完整形态
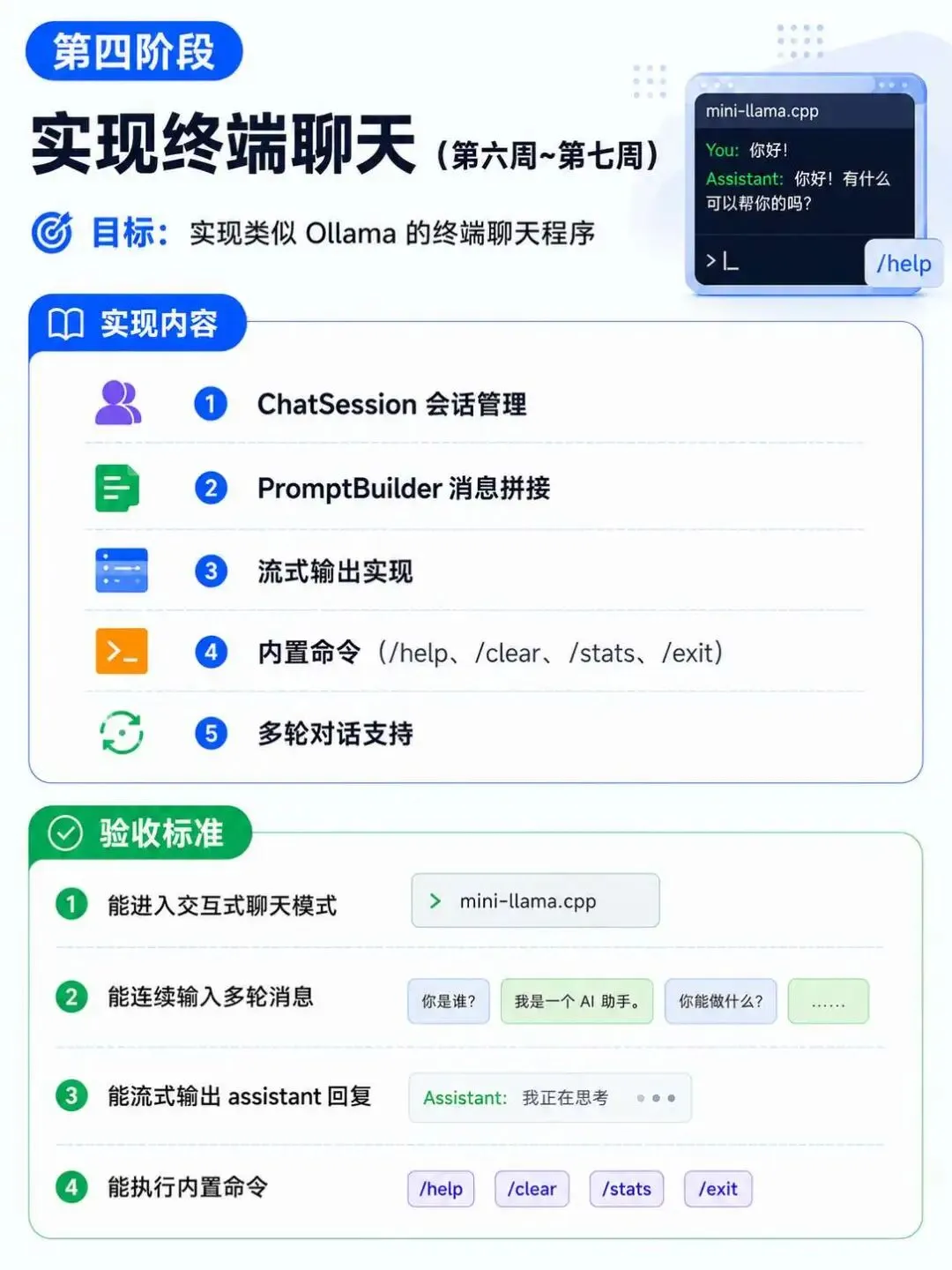
1. 推理内核
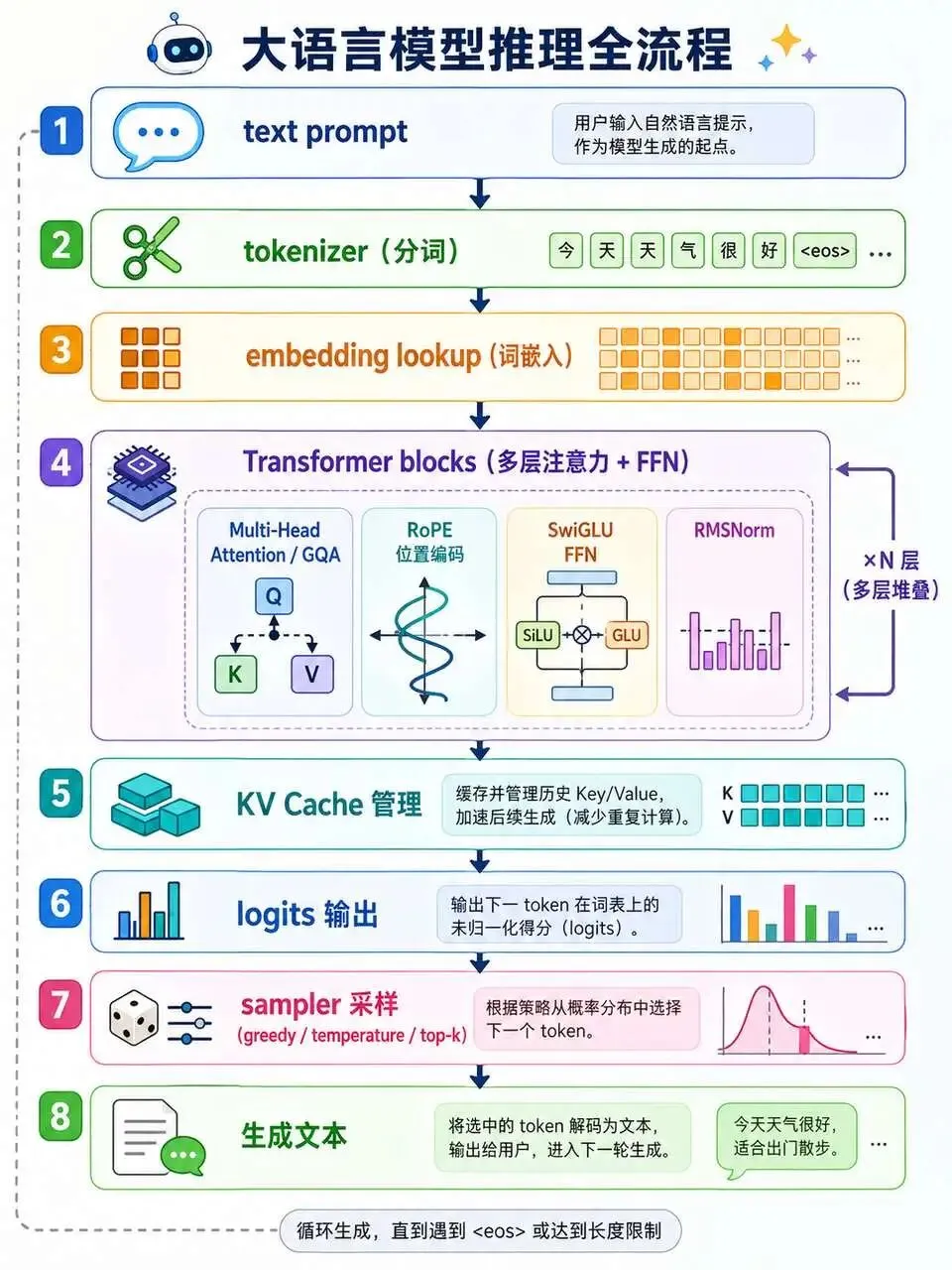
完整实现 LLaMA-style Transformer 推理链路:
2. 终端聊天程序
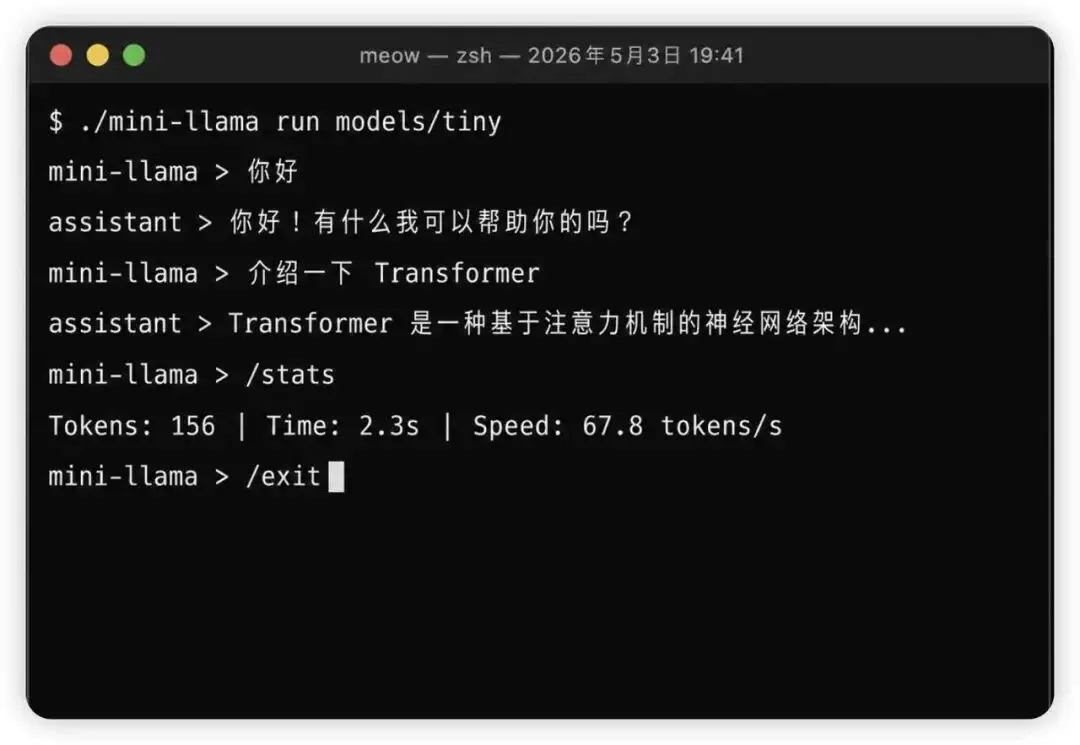
类似 Ollama 的使用体验
多轮对话,自动维护上下文 流式输出(逐字显示,像真实聊天) 内置命令:/help、/clear、/stats、/exit 会话管理(system prompt + user + assistant)
3. 完整的工程实践
✅ 模块化设计(Runtime / API / Chat / Model / Tensor / Ops)
✅ Python reference 数值对齐(误差 < 1e-4)
✅ 完整的单元测试和回归测试
✅ AddressSanitizer 内存检查
✅ 详细的文档(设计文档 + 实现文档 + llama.cpp 映射)
你能学到什么技术?
1. AI Infra 核心知识
Transformer 推理链路
Embedding lookup:token 如何转换为向量 Multi-Head Attention:注意力机制的完整实现 Grouped-Query Attention (GQA):现代 LLM 的标配优化 RoPE (Rotary Position Embedding):位置编码的工业实现 SwiGLU FFN:LLaMA 系列的前馈网络 RMSNorm:比 LayerNorm 更高效的归一化
KV Cache 管理
为什么需要 KV Cache?如何加速推理? 4D 张量存储结构设计 Prefill 和 Decode 两阶段协作 上下文窗口管理策略
采样策略
Greedy sampling:最简单的贪心采样 Temperature sampling:控制生成的随机性 Top-k sampling:工业级采样策略 可复现的随机数生成
推理引擎架构
模型加载器设计 推理上下文管理 状态机设计(prefill → decode loop) 流式输出实现 会话管理(多轮对话)
2. C++ 工程能力
现代 C++ 特性
RAII 资源管理 智能指针(std::unique_ptr, std::shared_ptr) 移动语义(move semantics) std::vector 高效使用 std::optional 错误处理 C++17/20 新特性
系统编程
内存布局与对齐 二进制文件 I/O 性能分析与优化 多线程编程(扩展阶段)
工程实践
CMake 构建系统 单元测试(Google Test) 回归测试设计 AddressSanitizer 内存检查 代码组织与模块化
3. 数值计算与算子实现
基础算子
Matrix Multiplication (matmul):推理的性能瓶颈 Softmax:注意力权重归一化 RMSNorm:高效的归一化算子 SiLU (Swish):激活函数 RoPE:旋转位置编码
张量操作
多维张量设计(1D/2D/3D/4D) 张量形状推导 内存连续性保证 算子融合思路
4. 工业对标能力
与 llama.cpp 的映射
MiniLlamaModel ↔ llama_model MiniLlamaContext ↔ llama_context forward_token() ↔ llama_decode() MiniSampler ↔ llama_sampler ChatSession ↔ llama.cpp examples 的会话逻辑
与 vLLM 的架构对比
理解 PagedAttention 的设计思路 理解 continuous batching 的价值 理解 prefix caching 的实现
你能提升什么能力?
1. 从 0 到 1 做 AI Infra 项目的能力
这不是一个"调包侠"项目。你会:
自己设计张量结构 自己实现核心算子 自己管理 KV Cache 自己验证数值正确性 自己实现终端聊天程序 自己优化性能瓶颈 完成后,你能自信地说:"我从零实现过一个 LLM 推理引擎,能跑、能聊、能调试。"
2. 读懂工业级 AI Infra 代码的能力
mini-llama.cpp 是通往 llama.cpp、vLLM、TensorRT-LLM 的桥梁。 做完这个项目后,你再去看 llama.cpp 的源码,会发现:
llama_decode() 不再是黑盒 KV Cache 的设计一目了然 算子调度的逻辑清晰可见 性能优化的方向有迹可循
3. AI Infra 面试的硬实力
这个项目能让你在面试中回答: 基础问题
"讲讲 Transformer 的推理流程" "KV Cache 是什么?为什么需要它?" "Attention 的计算复杂度是多少?" "RoPE 和传统位置编码有什么区别?" "Prefill 和 Decode 阶段有什么区别?" 进阶问题 "如何优化 matmul 性能?" "GQA 相比 MHA 有什么优势?" "如何设计一个推理引擎的内存管理?" "如何实现流式输出?" "如何管理多轮对话的上下文?" 项目深挖 "你的项目中最大的技术挑战是什么?" "如何验证推理结果的正确性?" "如果要支持量化,你会怎么设计?" "如果要支持 GPU,你会从哪里入手?" "如何实现类似 Ollama 的终端聊天体验?"
4. 简历上的硬核项目
简历上可以这样写: mini-llama.cpp:从零构建 LLM 推理引擎
用纯 C++ 实现了完整的 LLaMA-style Transformer 推理引擎 实现了 Multi-Head Attention、GQA、RoPE、SwiGLU、RMSNorm 等核心算子 设计并实现了 KV Cache 管理机制,支持 prefill 和 decode 两阶段推理 实现了 greedy、temperature、top-k 三种采样策略 实现了类似 Ollama 的终端聊天程序,支持多轮对话、流式输出、会话管理 通过 Python reference 验证数值正确性,误差控制在 1e-4 以内 编写了完整的单元测试和回归测试,通过 AddressSanitizer 内存检查 性能优化:[如果你做了优化,可以写具体数据]
面试官会问什么?
"为什么选择从零实现而不是用现成的库?"
答:为了深入理解 LLM 推理的核心机制,掌握 AI Infra 的底层原理
"你的项目和 llama.cpp 有什么区别?"
答:llama.cpp 是工业级引擎,支持量化、多后端、分布式;我的项目是教学型内核,聚焦核心推理链路的可读性和可理解性,并提供了类似 Ollama 的终端聊天体验
"如何实现流式输出?"
答:每生成一个 token,立即 decode 并输出到 stdout,flush 缓冲区,用户就能看到逐字显示的效果
"如何管理多轮对话的上下文?"
答:用 ChatSession 保存消息历史,PromptBuilder 把多轮消息拼成模型输入,KV Cache 保存历史的 K/V,新一轮只需要 prefill 新的 user message
适合什么人?
适合人群
校招生
想进 AI Infra 方向的 想做 LLM 推理/训练的 想进大厂 AI 团队的 简历上缺硬核项目的
社招
想转 AI Infra 方向的 想提升 C++ 系统编程能力的 想理解 LLM 推理原理的 想在简历上加一个有分量的项目的 前置要求 必须掌握 C++ 基础(指针、引用、类、STL) 基本的线性代数(矩阵乘法、向量运算) 基本的 Python(用于验证) 最好了解 Transformer 的基本概念(不了解也可以边做边学) CMake 基础(不了解也可以边做边学) 不需要 不需要深度学习背景 不需要 GPU 编程经验 不需要数学推导能力
能找到什么工作?
直接对口的岗位
AI Infra 工程师
LLM 推理引擎开发 模型部署与优化 推理性能优化 量化与加速
AI 系统工程师
AI 框架开发 算子优化 模型编译 异构计算
后端开发(AI 方向)
LLM API 服务 模型服务化 推理集群管理 AI 中台开发
薪资水平(2026 年参考)
校招(应届生)
普通后端:20-30w AI Infra:25-40w 头部大厂 AI:30-50w
社招(1-3 年)
普通后端:25-40w AI Infra:30-50w 头部大厂 AI:40-70w 为什么 AI Infra 薪资高? 人才稀缺:同时懂 C++、懂 AI、懂系统的人不多 业务价值大:推理性能直接影响成本和用户体验 技术壁垒高:需要系统编程、数值计算、性能优化多方面能力
学习路径


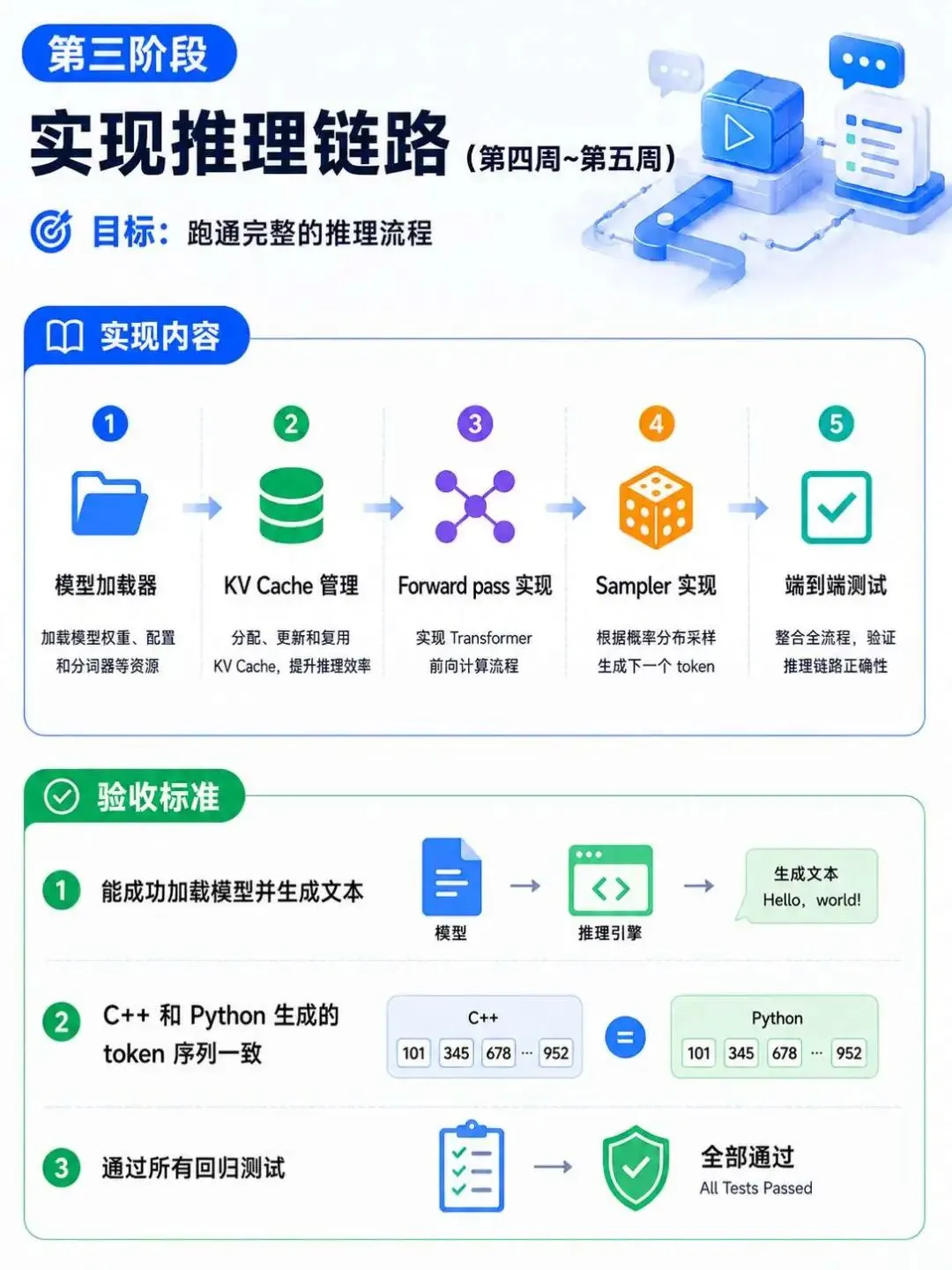
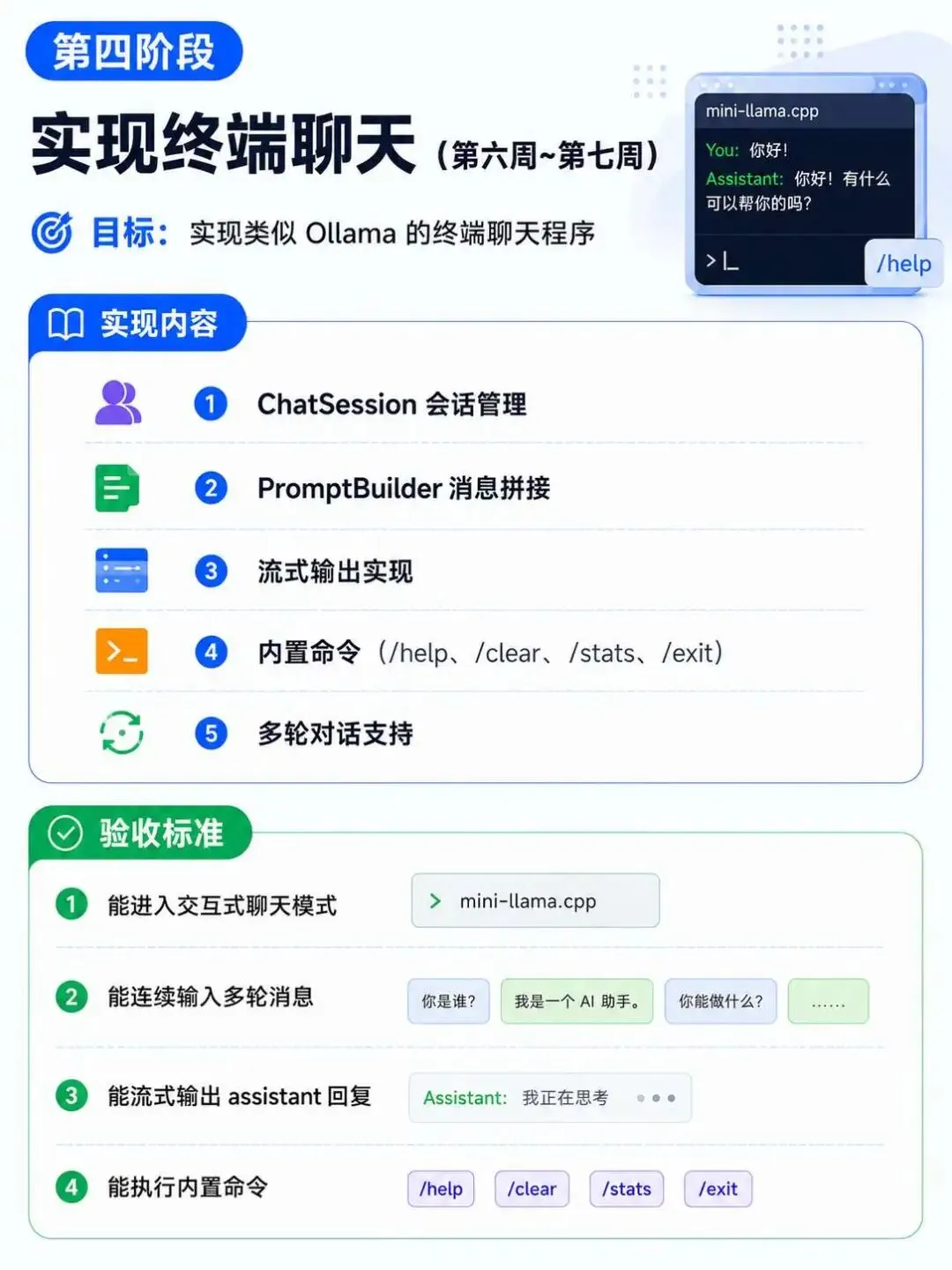

项目亮点

项目成果展示
完成这个项目后,你会有:
可运行的终端聊天程序
完整的文档
设计文档:架构设计、模块划分 实现文档:核心算法、数据结构 测试文档:测试策略、验证方法 性能文档:性能分析、优化方案 llama.cpp 映射文档:与工业项目的对应关系
扎实的理解
能讲清楚 LLM 推理的完整流程 能解释每个模块的设计思路 能分析性能瓶颈和优化方向 能对比工业级项目的差异 能实现类似 Ollama 的终端聊天体验
面试的底气
简历上有一个硬核项目 面试时能深入讲解技术细节 能回答 AI Infra 相关的问题 能展示系统编程能力 能展示从 0 到 1 做项目的能力
为什么选择这个项目?

训练营支持
在希加加 C++ AI Infra 训练营,你会得到:
1v1 导师指导
领航导师全程跟进 专项导师深度答疑 每周代码 review 随时解答问题
完整学习计划
根据你的基础定制学习路径 每天的学习任务和验收标准 机器人每日提醒和监督
项目全程支持
从设计到实现全程指导 遇到问题随时答疑 代码 review 提升质量 性能优化建议
面试准备
简历优化(突出项目亮点) 模拟面试(1v1 大厂面试官) 面经复盘(针对性提升) 面试题库(AI Infra 方向)
常见问题
Q: 我没有深度学习背景,能做这个项目吗?
A: 可以。这个项目不需要深度学习背景,需要的是 C++ 编程能力和基本的线性代数。Transformer 的原理可以边做边学。
Q: 这个项目和 llama.cpp 有什么区别?
A: llama.cpp 是工业级推理引擎,支持量化、多后端、分布式,代码上万行。mini-llama.cpp 是教学型内核,聚焦核心推理链路,代码约 2000 行,优先可读性,并提供了类似 Ollama 的终端聊天体验。
Q: 做完这个项目能直接找到 AI Infra 的工作吗?
A: 这个项目是敲门砖,能让你的简历通过筛选,能让你在面试中有话可说。但找工作还需要:扎实的 C++ 基础、算法能力、系统设计能力、面试技巧等。训练营会全方位帮你提升。
Q: 项目需要 GPU 吗?
A: 不需要。主线是 CPU-only 的,普通笔记本就能跑。如果你想做 GPU 加速的扩展,可以在完成主线后再做。
Q: 需要多长时间完成?
A: 根据你的基础和投入时间:
有 C++ 基础 + 每天 4-6 小时:6-8 周 C++ 基础一般 + 每天 4-6 小时:8-10 周 需要补 C++ 基础:10-12 周
Q: 完成后能加到简历上吗?
A: 当然可以。这是你从 0 到 1 完成的项目,代码是你自己写的,理解是你自己的。面试时能讲清楚技术细节,就是你的硬实力。
Q: 和 Ollama 有什么区别?
A: Ollama 是成熟的产品,支持多种模型、量化、GPU 加速等。mini-llama.cpp 是教学型项目,聚焦核心推理链路的可读性和可理解性,提供类似的终端聊天体验,但功能更简单。
立即开始
如果你想:
进入 AI Infra 方向 深入理解 LLM 推理原理 提升 C++ 系统编程能力 在简历上加一个硬核项目 拿到大厂 AI 团队的 offer 加入希加加 C++ AI Infra 训练营,从 mini-llama.cpp 开始你的 AI Infra 之路。
联系我们
服务内容:
1v1 导师指导、代码 review、模拟面试、简历优化、学习监督
导师团队:
程序喵:大厂 C++ 技术专家,《C++20 高级编程》《C++23 高级编程》译者 程序厨:前腾讯高级后端工程师,GitHub 10000+ star 开源作者 拓跋阿秀:前字节跳动全栈工程师,现外企团队 leader 其他多位大厂导师
↓下方评论区,立即加入,开启你的 AI Infra 之路!
