 夜雨聆风
夜雨聆风前两天有位读者抛来一个问题,说他正在规划一个AI动画短片项目,想让我帮他看看方案靠不靠谱。
他设想的管线长这样:
小说原文 → DeepSeek V4 转剧本 → 提炼角色/场景/道具提示词 → 生成分镜 → GPT Image 2 逐帧生图 → 即梦 SD2 图生视频 → 拼接出片
乍一看挺完整——文本、图像、视频三个环节都有对应的工具,管线逻辑也通顺。但逐环节推敲下来,每一步都有值得深挖的细节。这些细节恰恰是"从想法到落地"之间最容易踩的坑。
把我们的讨论过程整理出来,供正在规划类似项目的朋友参考。
一条AI动画管线,到底该怎么搭?
开箱即用的幻觉:为什么"看起来通"不等于"跑得通"
这位读者能画出这条管线,说明他对AI工具链有基本认知——知道LLM做文本、扩散模型做图像、视频模型做动画,各司其职。但实际项目中,管线图和可运行的代码之间,隔着一层对每个环节"真实约束条件"的理解。
我把他的方案拆成四个环节,逐一分析。
环节一:LLM转剧本 + 提炼提示词
结论:完全可行,这是整条管线最没有风险的一环。
当前主流的LLM(无论是DeepSeek V4、GPT-4还是Claude)在处理文本结构化和格式转换上的能力已经非常成熟。关键是要设计好system prompt的输出格式约束:
场景1:森林小屋(夜)镜头:中景 俯拍人物:张三(惊恐)动作:推开窗户查看动静画面描述:月光透过树梢洒在木屋门前...生成提示:anime style, dark forest cabin, night, moonlight, cinematic lighting只要输出格式固定,后续的脚本解析、提示词提取、分帧调度都可以自动化。这一步的核心工作是prompt engineering,不需要纠结模型选型——手头有什么模型就用什么。
环节二:GPT Image 2 生图
结论:可行,但有一个绕不过去的坑——角色一致性。
这是整条管线里最容易被低估的问题。GPT Image 2 作为文生图模型,单张出图质量没有问题,但当你需要同一个角色出现在场景1和场景20时,问题就来了。
第一次生图:黑长发红瞳少女,站在森林里 第二次生图:同样描述,发色偏棕、瞳色变紫、脸型也变了
分镜连不起来,故事就没有连贯性。这不是GPT Image 2独有的问题,所有文生图模型都有这个特性——它对"黑长发红瞳少女"这个描述的理解,每次采样都是独立的。
解决方案有几种:
方案A:固定seed + 统一外貌模板。在每张图的生成请求中固定seed值,同时在prompt中嵌入统一的角色外貌段落("xxx角色:黑色长发、红色瞳孔、身高165cm、穿白色连衣裙"),尽量减少随机漂移。
方案B:放弃全量生图,改用"底图+局部重绘"。先出一张标准角色定妆照,每次场景变化时用这张图做img2img基础,只重绘背景和姿势。
方案C:上本地SD + ControlNet + IPAdapter。如果你对角色一致性的要求是"完全不变",那就得回到本地部署路线,用IPAdapter锁死角色特征。这是效果最好的方案,代价是你得有一块24GB显存的GPU。

环节三:ComfyUI 但不用本地模型?
结论:这是讨论中最需要纠正的认知——ComfyUI的价值在于本地推理。
读者一开始的计划是"安装ComfyUI,但不用本地模型,全部走API"。我当时给的反馈很直接:ComfyUI的核心优势是本地Stable Diffusion的节点化推理——Checkpoint加载、LoRA融合、ControlNet姿态控制、IPAdapter特征锁定、AnimateDiff动画生成,这些都是本地GPU才能干的事。
如果你所有图像都走云端API,ComfyUI就只是一个空壳画布。与其架一个空壳,不如直接写Python脚本:
defgenerate_frame(scene_desc, character_prompt, seed=42): payload = {"model": "gpt-image-2","prompt": f"{character_prompt}, {scene_desc}","n": 1,"seed": seed,"resolution": "1k" }return call_alami_api(payload)一个脚本 + 一个API Key,比架ComfyUI轻量十倍。那什么时候该上ComfyUI?当你需要ControlNet锁姿态、IPAdapter锁角色、LoRA调画风的时候——这些操作目前只有本地SD生态能原生支持。
环节四:即梦 SD2 API 图生视频
结论:方向对,但接口不是你想要就能拿到。
字节跳动的即梦(Seedance 2.0)在AI图生视频领域表现确实亮眼——角色一致性95%+、多模态参考、深度集成剪映生态。但问题在于:字节的API目前主要是企业合作渠道,不是公开注册就能调用的。
我给读者列了几个备选:
可灵Kling API:文档明确,按量付费,支持图生视频。月费$6.99起,中文理解最好,性价比之王。
阿里通义万相Wan API:国内可直接购买,支持图生视频和视频编辑,有免费商用版本。
Runway API:国际卡可付,精细控制最强(Motion Brush、镜头运动),$12-76/月。
策略很明确:先用最易拿到的API跑通demo管线,确认整条链路工作正常,再谈换更好的模型。
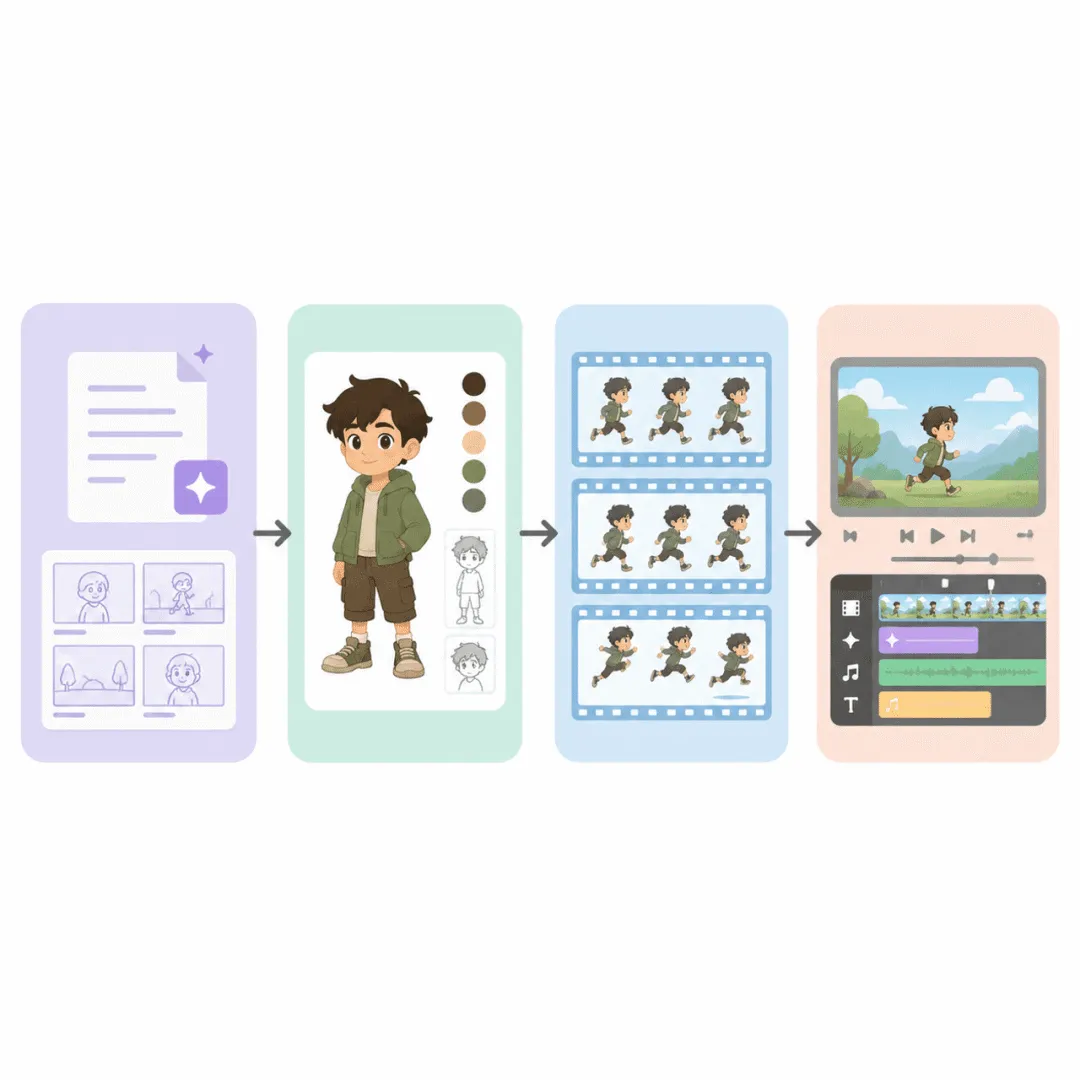
修正方案:一条更务实的管线
经过逐环节推敲,我们把原始方案修正为:
小说 → LLM转剧本+分镜 → Python编排脚本 → GPT Image 2 / 可灵API → 图生视频 → 剪映后期
几个关键改动:
去掉ComfyUI,换Python脚本。如果你的图全部走API,一个Python脚本就能完成调度、重试、存储、元数据管理。只有当你需要本地ControlNet锁姿态或IPAdapter锁角色时,才值得上ComfyUI。
API选型留退路。先确认即梦API能否拿到,拿不到直接换可灵或通义万相。核心原则:选管线最快跑通的方案,不是效果最好的方案。
角色一致性分阶段解决。第一期靠seed固定+统一prompt模板;第二期如果效果不够,再加本地IPAdapter。
这篇文章想说的方法论
写完这个案例,我想分享三句话:
第一,画管线图只是第一步,每个环节的"真实约束条件"才是方案设计的关键。角色一致性、API可获取性、本地vs云端的成本分界线——这些不亲手调过接口、不亲自跑过管线的人,很难预判。
第二,不要为了用工具而用工具。ComfyUI很好,但如果你不需要本地推理,它就是一个不必要的复杂度。选工具的逻辑应该是"我有这个需求→哪个方案满足→最轻量的是什么",而不是"这个工具很火→装一个→想办法塞进管线"。
第三,验证假设的成本越低越好。先用免费/低价API跑通demo,确认管线逻辑没问题,再决定是否上本地GPU。我的读者用半天时间跟我讨论,避免的可能是一周盲目搭建后的推倒重来。
你目前在做的AI项目卡在哪一步?是工具选型、角色一致性、还是API获取?评论区聊聊,说不定下一篇就聊你的方案。
