 夜雨聆风
夜雨聆风无需 Embedding,无需向量库,无需切分——开源项目TreeSearch 用树结构保留文档灵魂,毫秒级检索万级文档。
你是不是也被 RAG 切碎过?
用过 RAG 的人都知道这个痛点:
文档被机械地切成固定大小的 chunk,喂给向量数据库,检索出来的片段上下文断裂,拼不出完整语义。你问"第三章的实验方法是什么",它给你返回一坨没有章节归属的文字碎片。
传统 RAG 的致命缺陷,不在于检索不够快,而在于它根本不理解文档的结构。
一篇论文有章节层级,一份 API 文档有标题嵌套,一段代码有类和函数的从属关系——这些天然的结构,才是人类理解文档的钥匙,却在 chunk 切分的那一刻,全部丢失了。
TreeSearch,就是为了解决这个问题而生的。

TreeSearch 是什么?
TreeSearch是一个结构感知的文档检索库。它的核心理念极其简洁:
把文档解析成树,而不是切成块。
传统 RAG:文档 → 切成 chunks → 向量化 → 检索 → ❌ 上下文断裂
TreeSearch:文档 → 解析为树结构 → 结构化检索 → ✅ 保留完整语义
支持 Markdown、纯文本、代码文件(Python AST + 正则,Java/Go/JS/C++ 等)、HTML、XML、JSON、CSV、PDF、DOCX——几乎你能想到的文档格式,它都能解析成树。
然后呢?用 SQLite FTS5 做关键词匹配。没有向量,没有 Embedding 模型,没有 API Key,毫秒级出结果。
为什么它比传统 RAG 更好?
核心优势——五个"无需":无需向量嵌入、无需分块、无需向量数据库、无需 LLM 调用、无需等待。
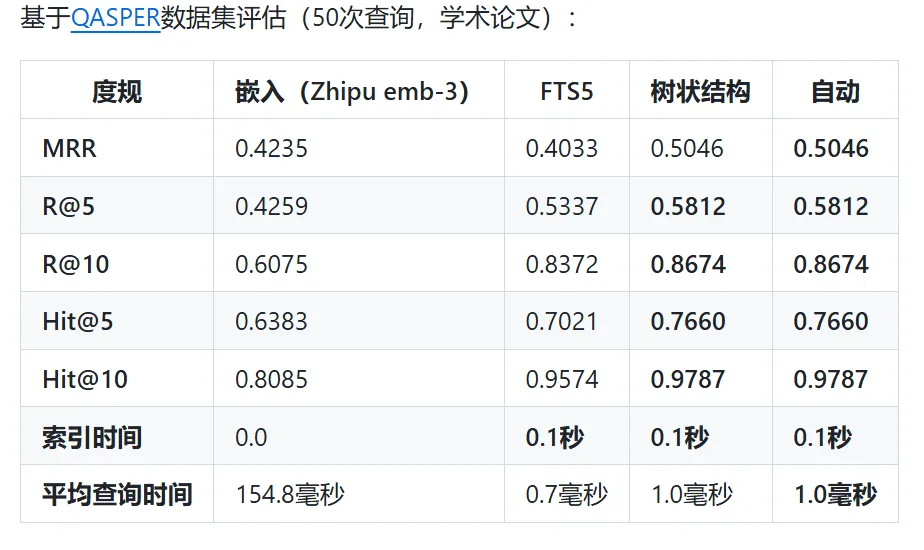
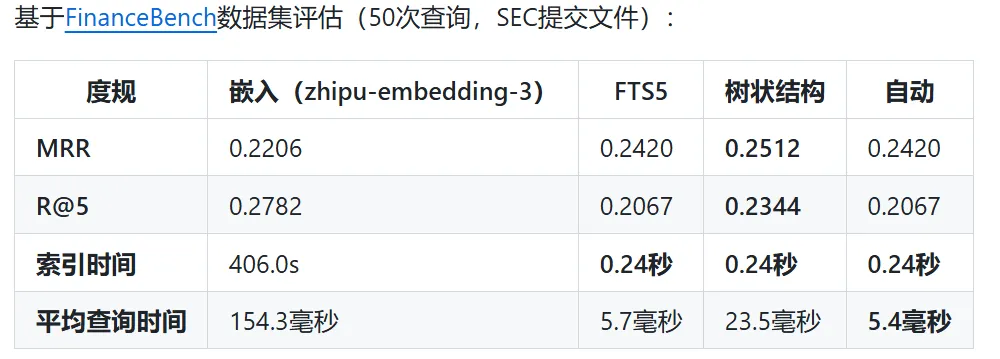
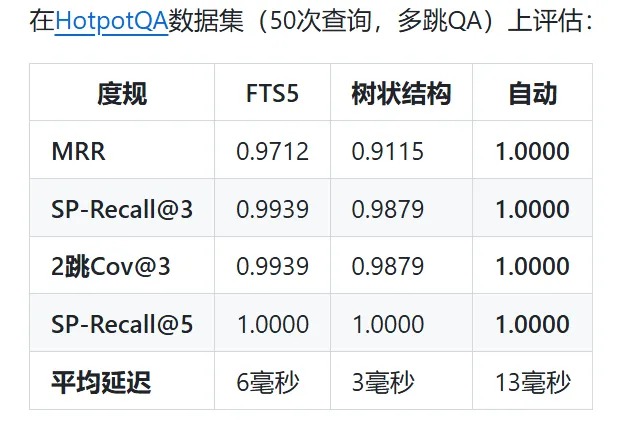
QASPER 基准 Tree 模式 MRR 0.50(+25% vs 纯 FTS5);CodeSearchNet Flat 模式 MRR 0.91。
三种检索模式,自动帮你选
Tree 模式——论文、长文档,锚点定位 + 树遍历找最优路径Flat 模式——代码搜索、关键词查询,纯 FTS5 倒排索引Auto 模式(默认)——智能选择,零配置
Auto 模式三层策略:类型映射 → 深度校验 → 比例阈值,不会出现"1 个 markdown 混在 50 个代码文件里就全走 tree"的问题。
三大核心场景
技术文档问答:100+ 份 API 文档、设计文档、RFC 毫秒检索,返回完整章节不是碎片
代码库语义搜索:AST 解析 + ripgrep 加速,搜索"登录相关"直接定位完整类和函数
学术论文检索:50 页论文自动定位到"3.2 Experimental Design"章节
安装超简单
pip install -U pytreesearch
treesearch "认证系统如何工作?" src/ docs/
macOS/Linux 也可以用 Rust CLI(不依赖 Python):
brew tap shibing624/tap && brew install treesearch
写在最后
TreeSearch 的价值不在于"更快"——虽然确实快——而在于它重新定义了文档检索的思路:不是把文档切碎后强行拼凑,而是尊重文档的天然结构,让检索结果本身就带有上下文。
https://github.com/shibing624/TreeSearch
