 夜雨聆风
夜雨聆风如果你认真听完 MIT 这门课《How to AI (Almost) Anything》的第二讲,你会发现一件有点反直觉的事:
AI 的核心,不是模型,而是数据。
很多人一上来就刷模型、刷架构、刷论文,但在 Paul Liang 教授看来,这几乎是本末倒置。
他说:你能不能把 AI 做好,80% 取决于你有没有真正理解你的数据。
如果数据没搞清楚,再强的模型也只是“空中楼阁”。
这门课的第二讲就是回答这个问题,“到底什么叫理解数据?”

一、数据的第一性原理:模态
先从一个看起来“学术”,但其实极其基础的概念开始:模态(Modality)。
简单说,模态就是——信息被表达或被感知的方式。
对人类来说,是视觉、听觉、触觉;对 AI 来说,是图像、文本、语音、传感器、图结构……
这听起来像是分类问题,但它背后真正重要的是:
不同模态,本质上是完全不同的数据世界。
你不能用处理图像的方法去处理文本,也不能用处理语音的方式去处理图结构。这不是模型能力的问题,而是数据结构本身不同。
1. 视觉:连续、结构化、高信息密度
图像是最直观的模态。每个像素,本质是一个三维向量(RGB)。
这个设计并不是“技术最优”,而是人类视觉最优——因为我们的视锥细胞正好对红、绿、蓝敏感。
这带来一个很重要的认知:
我们训练视觉模型,本质是在模拟人类的视觉系统。
这在自动驾驶、安防识别里没问题,但如果是红外、CT、深度图——RGB就不再适用。
视觉数据的几个关键特征:
• 2D网格结构(空间关系强) • 连续值(可微、适合梯度优化) • 信息密度极高(冗余也多)
2. 语言:离散符号 + 强上下文依赖
语言完全不同。它不是物理信号,而是人类发明的符号系统。
最经典的表示方法——词袋模型(BoW),把文本变成一个高维稀疏向量。但它有一个致命问题:
它完全丢掉了“顺序”。
“人咬狗”和“狗咬人”,在词袋里是一样的。
这也是为什么后来演进出:
• N-gram(局部顺序) • Word2Vec / GloVe(语义空间) • Transformer(全局上下文)
本质上,都是在弥补一个问题:
语言的核心,不是词,而是关系。
3. 听觉:时间信号 + 频域结构
语音是物理信号——空气振动 → 电信号 → 数字化。
这里有一个很经典的设计:20ms 时间窗口
原因是:
• 太短 → 只有振荡,看不到语音结构 • 太长 → 混合多个音素,丢失时间信息
20ms,刚好捕捉一个音素。
再通过频谱图(Spectrogram)转换:
语音 → 一张“带结构的二维信号”
具体来说:
• 横轴是时间(音频在流动) • 纵轴是频率(不同音高) • 颜色/亮度表示能量强弱
这时候,你会发现一件很关键的事,语音不再只是“波形”,而是变成了一种有“局部结构”的二维数据。
比如某些频率带会持续一段时间(形成“横向纹理”);某些声音会在瞬间爆发(形成“竖向边界”);音素之间会形成稳定的模式块。这些模式,其实和图像里的“边缘”“纹理”“形状”非常类似。
也正因为如此,我们可以用处理图像的方式,去捕捉语音里的局部模式。
而卷积神经网络(CNN)擅长的就是在局部区域里,提取稳定、可复用的特征。
所以,语音任务中使用 CNN,就是因为频谱图具备了和图像类似的“局部结构规律”。
4. 传感器:系统“内感知”
和视觉不同,传感器不是“看世界”,而是 看自己。
比如力矩、电机转速、位置速度等。
典型形式是时间序列:T × N 的矩阵(时间 × 维度)
它的关键特征:
• 无空间结构 • 强时间依赖 • 通常与视觉/语言结合(多模态)
5. 表格:工业世界的主战场
如果你做过业务,一定知道:
绝大多数真实数据,是通过表格呈现的。
比如医疗、金融、用户数据。
特点:
• 特征异构(连续 + 离散 + 类别) • 结构清晰 • 噪声复杂
有意思的是:
在表格数据上,传统模型(XGBoost)往往比深度学习更强。
原因就是表格关系复杂,但不具备强结构,树模型反而更适配。
6. 图:关系即一切
图数据的核心不是“点”,而是 连接关系。
应用场景:
• 社交网络 • 推荐系统 • 分子结构
图神经网络(GNN)的核心思想就是:你是谁,取决于你和谁在一起。
7. 集合:无序世界
有一类数据很特殊:没有顺序。 比如点云(自动驾驶激光雷达)等。
它们关键约束是: Permutation Invariance(置换不变性)
顺序变了,结果不能变。这类问题催生了像 DeepSets 这样的结构。
二、真正的理解:模态特征谱
认识模态只是第一步,更关键的是:你如何系统地理解它?
课程给了一个非常有用的工具:Modality Profile(模态特征谱)
可以把任何数据,从6个维度拆开看:
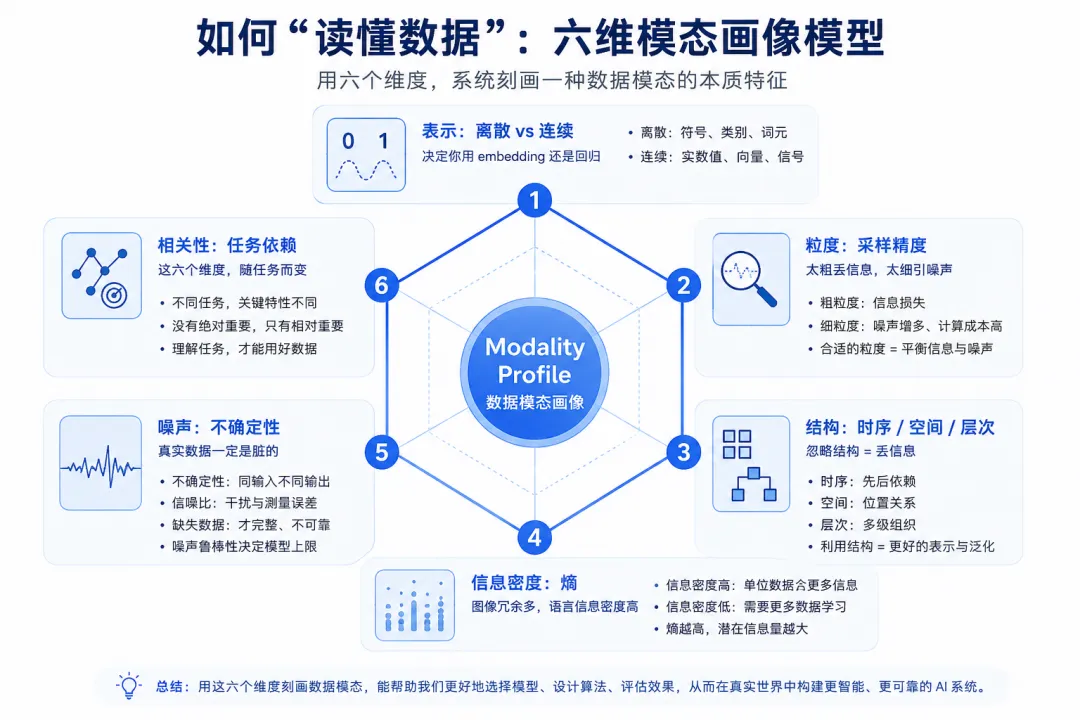
没有“通用最重要特征”,只有“对当前任务最重要的特征”
这里其实有一个非常关键的认知跃迁:
数据没有“客观重要性”,只有“任务相关性”。
三、模型只是学习范式的选择
理解数据之后,才轮到模型。课程把学习方法分为四大类:
1. 监督学习:从答案中学
最常见:x → y
问题在于:你假设训练数据 ≈ 未来数据
一旦分布变了(distribution shift),模型就会崩。
2. 无监督学习:从结构中学
没有标签,只学习数据分布:
• 聚类 • 降维 • embedding • diffusion(生成模型)
本质是:理解“什么是这个世界的结构”
3. 强化学习:从反馈中学
没有标准答案,只有奖励:
• 做得好 → +1 • 做得差 → -1
典型应用:ChatGPT 的 RLHF。
它的关键作用不是“更聪明”,而是更符合人类期望。
4. 更现实的组合
真实世界里,很少只用一种范式:
• 多模态学习(视觉+语言) • 多任务学习 • 主动学习 • 人在回路(Human-in-the-loop)
本质是:让学习过程更接近真实世界。
四、真正的核心问题:泛化
这是整节课最重要的一句话:我们真正想要的,不是训练效果,而是泛化能力。
1. 两个经典错误
欠拟合(Underfitting)
模型太弱,什么都学不会
过拟合(Overfitting)
模型太强,把噪声也学进去了
但更隐蔽的问题是:
测试集 ≠ 真实世界
如果你的测试环境和真实环境不一致:
• 实验室 → 户外 • 美国数据 → 中国应用
结果一定会崩。
2. 泛化的本质
不是“记住数据”,而是:
应对没见过的情况。
五、最后的落地方法:How To Data(五步法)
课程最后给了一个极其实用的方法论:
当你拿到一份新数据,按这5步来:

而很多人会反过来做:先选模型,再看数据。
这就是为什么项目总是越做越乱。
结语:你以为你在做模型,其实你在做数据
这一讲最值得记住的,不是某个技术点,而是一个判断:
AI 的上限,从来不是模型决定的,而是数据决定的。
模型只是放大器,你输入什么数据,它就放大什么。
如果数据是混乱的、带偏的、片面的——
模型只会把这些问题,更高效地放大出来。
所以真正的分水岭不是:你会不会用 Transformer,而是你有没有能力“读懂数据”。
Tip
专注于 AI 智能体实践与技术演进深度思考。主理人拥有资深技术背景与心理学视角,致力于通过真实实验(2025年更新361篇实操记录)探索 LLM、RAG 与 Agentic Workflow 的落地边界。

