 夜雨聆风
夜雨聆风Office Open XML(缩写:Open XML、OpenXML或OOXML),是微软(Microsoft)开发的一种基于 XML以ZIP格式压缩的电子文件范式,用于支持文件、表格、备忘录、幻灯片等文件格式。
• 标准化:2006 年成为 ECMA 标准(ECMA-376),2008 年进一步成为国际标准(ISO/IEC 29500)。 • 替代旧格式:取代了早期 Office 使用的私有二进制格式( .doc、.xls、.ppt),使文档结构更加开放和透明。• 本质特征:OOXML 不是“新的独立压缩格式”,而是建立在 ZIP 容器和 OPC(Open Packaging Conventions,开放包装约定)之上的 XML 文档包。
一、哈希值与后缀名验证
修改文件后缀名不会改变文件内容本身。因此,同一个 OOXML 文件从
.docx/.xlsx/.pptx改名为.zip后,其哈希值应保持一致改后缀这一操作,改变的是操作系统或软件如何“解释”该文件,而不是文件本体的二进制内容
利用哈希值验证其原后缀标准与改为 .zip 用于查看二进制的对比

这也是为什么:
WordOOXML.docx和WordOOXML.zip,如果只是重命名而没有二次保存或重新打包,那么其 MD5、SHA1、SHA256 等哈希值应一致。
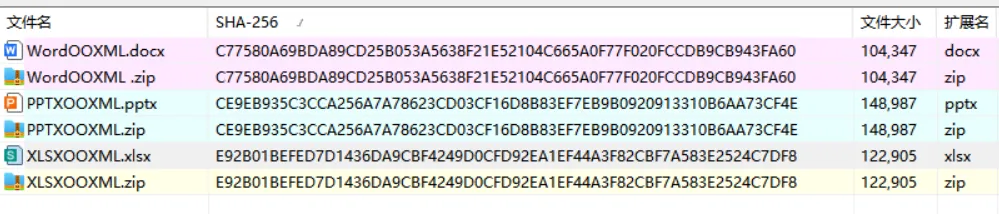
二、文件结构
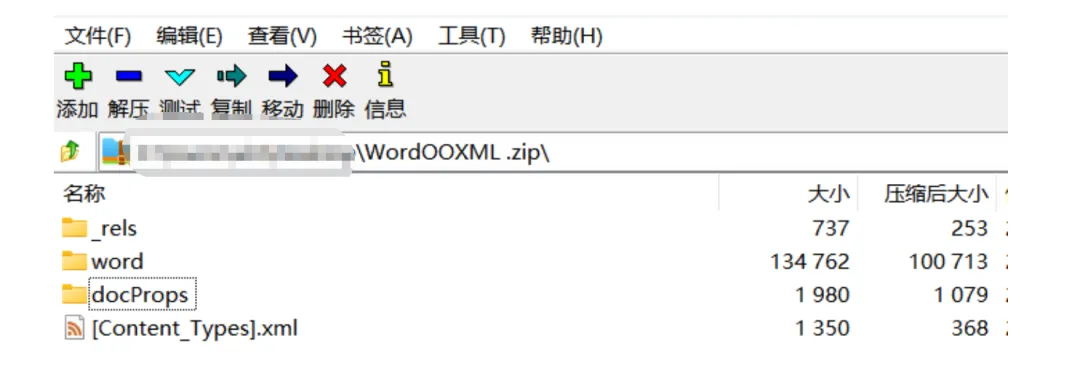
OOXML 文件本质上是一个 ZIP 压缩包。如果你将 .docx、.xlsx 或 .pptx 的后缀改为 .zip 并解压。
例如:docx文件后缀改为zip后会看到类似这样的内部结构:
document.docx
├── [Content_Types].xml ← 定义包内各部件的 MIME / Content-Type
├── _rels/ ← 关系文件,描述各部件之间的引用关系
│ └── .rels
├── word/ ← Word 文档主体内容
│ ├── document.xml ← 实际正文内容
│ ├── styles.xml ← 样式定义
│ ├── theme/
│ └── media/ ← 嵌入图片、音频、视频等资源
└── docProps/ ← 文档属性(作者、标题、创建时间等)对于不同 OOXML 子类型,主目录会有所变化:
• Word 文档: word/• Excel 工作簿: xl/• PowerPoint 演示文稿: ppt/
2.1 核心路径说明
[Content_Types].xml | |
_rels/.rels | |
docProps/ | core.xml、app.xml |
word/document.xml | |
xl/workbook.xml | |
ppt/presentation.xml |
2.2 结构层面的关键结论
• 仅凭文件扩展名不足以认定 OOXML • 仅凭 PK 03 04也不足以认定 OOXML的具体指向
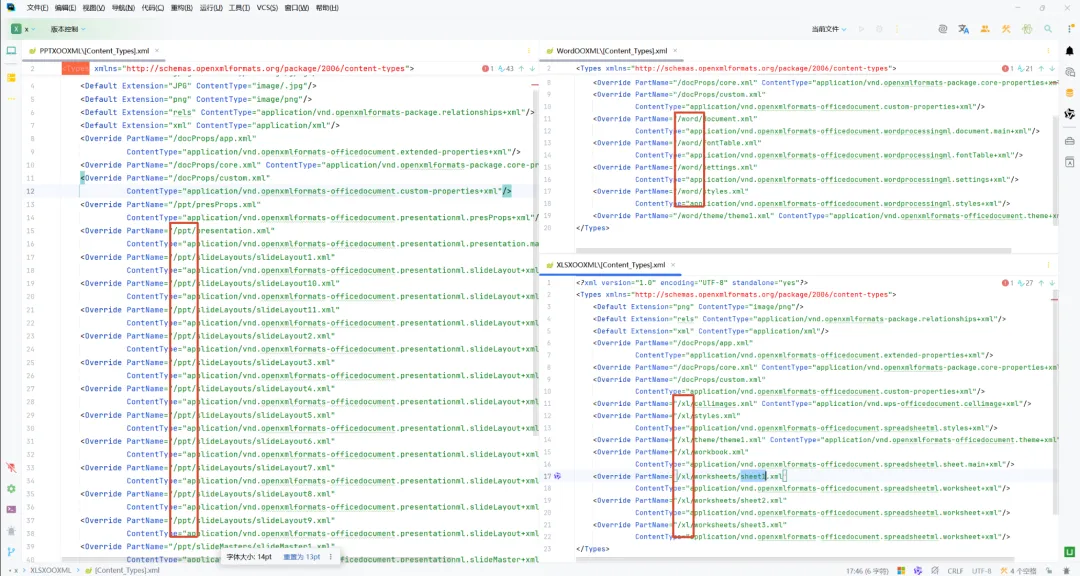
• [Content_Types].xml• _rels/.rels
word/、xl/、ppt/
三、Magic Bytes
3.1.zip
PKZIP 最初由 Phil Katz编写,PKZIP是一种文件归档计算机程序,以引入流行的 ZIP文件格式而闻名。
• .zip、.apk、.jar、.docx、.xlsx、.pptx、.odt、.epub、.xpi

| ZIP (.zip, .apk, .jar, .docx, .xlsx, .pptx) | ZIP 固定签名 | 50 4B 03 04 | PK.. | |
| ZIP (empty) | 50 4B 05 06 | PK.. | ||
| ZIP (spanned) | 是另一类 ZIP 记录标记 | 50 4B 07 08 | PK.. |
它们属于 ZIP 的不同结构位置,不是一段连续固定的起始魔术字节。

3.2 OOXML 魔术字节
普通未加密的 OOXML 文件(如 docx/xlsx/pptx)本质上是 ZIP 容器,因此:
• OOXML 的基础容器魔术字节也是 50 4B 03 04• 它没有像老式 DOC/XLS/PPT那样独立、稳定、唯一的专属固定文件头
换言之:
50 4B 03 04 可以说明该文件是 ZIP 或 ZIP-based container,但不能仅凭这一点就断定它一定是 OOXML
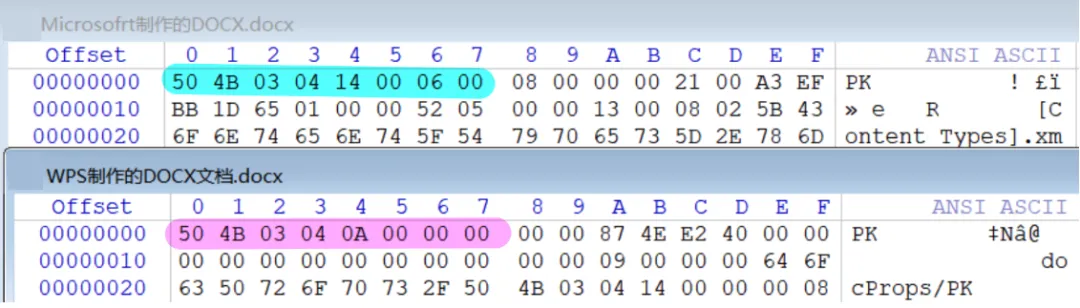
3.2.1 样本不同产生不同
参考链接:The structure of a PKZip file
50 4B 03 04 14 00 06 00 |
50 4B 03 04 0A 00 00 00 |
50 4B 03 04 14 00 01 00 |
这些字段会随着:
• 压缩器实现差异、是否加密、压缩选项 • 是否使用 data descriptor • 生成器不同(Microsoft Office、LibreOffice、WPS、第三方库、Python创建)而发生变化
3.2.2 为什么不能只靠文件头判断 OOXML
因为以下格式也都可能以 50 4B 03 04 开头:
• .zip、.apk、.jar、.docx、.xlsx、.pptx、.odt、.epub、.xpi• 以及其他任意 ZIP-based 容器
因此:
• PK 03 04只能说明“这是 ZIP 家族或 ZIP-based 容器”• 不能单独证明该文件是 OOXML
四、OOXML 的依据
4.1 步骤
(1)要认定某 ZIP-based 文件是 OOXML,应进一步检查:
• [Content_Types].xml• _rels/.rels• docProps/• word/、xl/、ppt/
(2)推荐的识别优先级如下:
1. 看文件头是否为 50 4B 03 042. 列出 ZIP 内部条目 3. 检查是否存在 [Content_Types].xml4. 检查是否存在 _rels/.rels5. 根据主部件判断类型: • word/document.xml• xl/workbook.xml• ppt/presentation.xml6. 解析 [Content_Types].xml进行最终确认

4.2 OOXML 常见类型与主部件
OOXML Format Family -- ISO/IEC 29500 and ECMA 376
docxdocm / dotx / dotm | word/ | word/document.xml |
xlsxxlsm / xltx / xltm / xlam | xl/ | xl/workbook.xml |
pptxpptm/potx/potm/ppsx/ppsm/ppam/sldx/ sldm | ppt/ | ppt/presentation.xml |

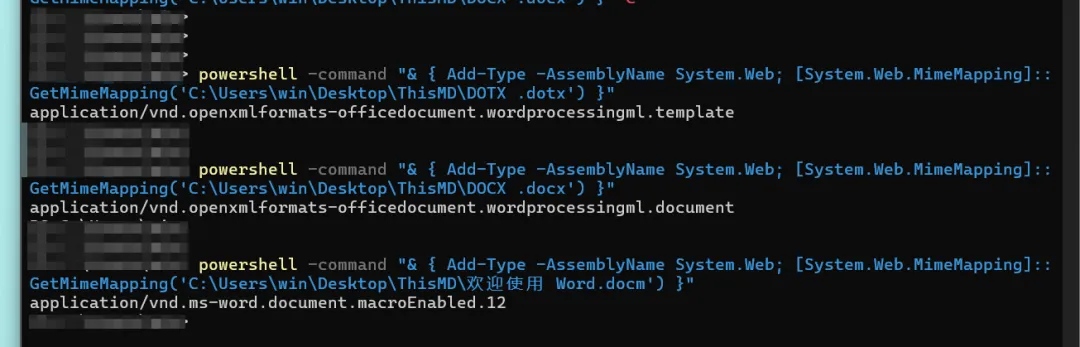
4.3 认识MIME
MIME(Multipurpose Internet Mail Extensions)是一种用于描述消息内容类型的标准,用以标识文档、文件或字节流的性质与格式。
MIME 消息可以包含文本、图像、音频、视频以及其他应用程序特定的数据。
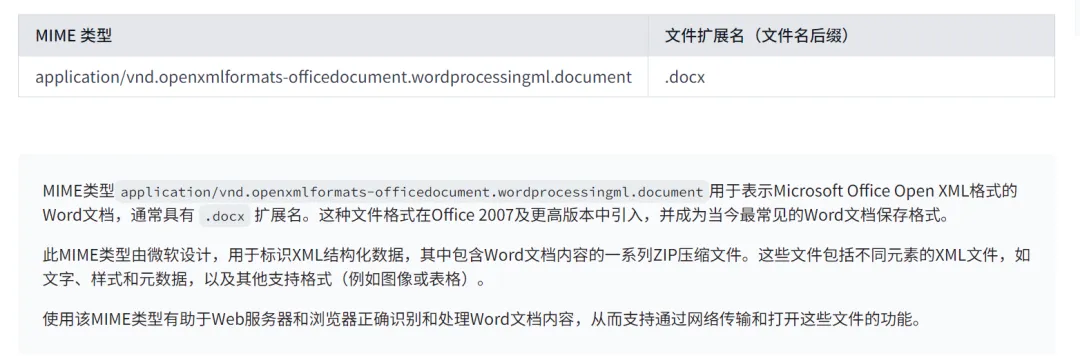
浏览器通常依据 MIME 类型(而非文件扩展名)来决定如何处理 URL,因此 Web 服务器在响应头中设置正确的 MIME 类型至关重要。一旦配置有误,浏览器可能无法正确解析文件内容,导致网站功能异常,下载的文件也会被错误处理。
import os
import mimetypes
import zipfile
import xml.etree.ElementTree as ET
from typing importList, Tuple
defget_file_mime_info(file_path: str) -> Tuple[str, str, str]:
"""
获取文件的 MIME 信息
"""
file_name = os.path.basename(file_path)
_, ext = os.path.splitext(file_name)
ifnot ext:
ext = ""
mime_type, _ = mimetypes.guess_type(file_path)
if mime_type isNone:
mime_type = "application/octet-stream"
return (file_name, ext, mime_type)
defget_ooxml_content_type(file_path: str) -> str:
"""
从 OOXML 文件中提取主文档部件的 ContentType
"""
ooxml_extensions = ('.docx', '.docm', '.dotx', '.dotm',
'.xlsx', '.xlsm', '.xltx', '.xltm', '.xlam',
'.pptx', '.pptm', '.potx', '.potm', '.ppsx', '.ppsm', '.ppam', '.sldx', '.sldm')
_, ext = os.path.splitext(file_path)
if ext.lower() notin ooxml_extensions:
return"非OOXML文件"
try:
with zipfile.ZipFile(file_path, 'r') as zf:
if'[Content_Types].xml'notin zf.namelist():
return"无Content_Types.xml"
with zf.open('[Content_Types].xml') as f:
tree = ET.parse(f)
root = tree.getroot()
# 定义命名空间
ns = {'ct': 'http://schemas.openxmlformats.org/package/2006/content-types'}
# 查找主文档部件
# Word: /word/document.xml
# Excel: /xl/workbook.xml
# PowerPoint: /ppt/presentation.xml
main_parts = [
'/word/document.xml',
'/xl/workbook.xml',
'/ppt/presentation.xml'
]
for part_name in main_parts:
for override in root.findall('ct:Override', ns):
if override.get('PartName') == part_name:
return override.get('ContentType', '')
return"未找到主文档部件"
except Exception as e:
returnf"解析失败: {str(e)}"
defprint_file_info(file_list: List[str]) -> None:
"""
按指定格式输出文件信息
"""
print("文件列表信息:")
print("-" * 120)
for file_path in file_list:
if os.path.exists(file_path):
file_name, ext, mime_type = get_file_mime_info(file_path)
content_type = get_ooxml_content_type(file_path)
print(f"\n【{file_name}】")
print(f"文件名 - 后缀名 - MIME: {file_name} - {ext} - {mime_type}")
print(f"文件名 - 后缀名 - Content_Types: {file_name} - {ext} - {content_type}")
else:
print(f"\n【{file_path}】")
print(f"{file_path} - 不存在")
print("-" * 120)
defscan_directory_files(directory: str = ".") -> List[str]:
"""
扫描指定目录中的所有文件
"""
files = []
for entry in os.listdir(directory):
entry_path = os.path.join(directory, entry)
if os.path.isfile(entry_path):
files.append(entry_path)
returnsorted(files)
if __name__ == "__main__":
print("=== 扫描当前目录 ===")
directory_files = scan_directory_files(".")
print_file_info(directory_files)
五、特殊
在讨论 OOXML 魔术字节时,必须注意一个容易被忽略的问题:
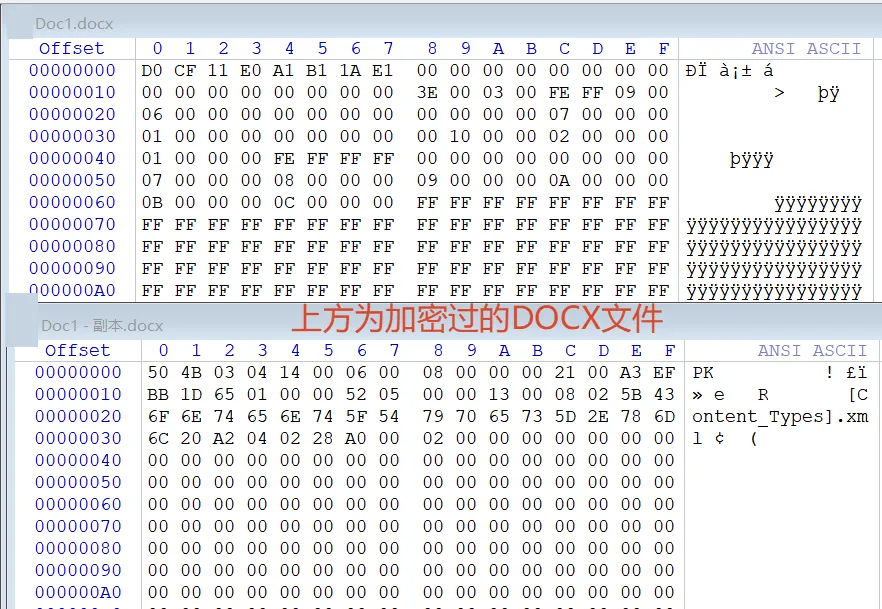
• 普通未加密 OOXML:外层通常是 ZIP,开头为 50 4B 03 04• 某些加密的现代 Office 文档:外层可能被封装为 OLE/CFBF,开头会变成:
D0 CF 11 E0 A1 B1 1A E1这意味着:
• 如果仅靠 PK 03 04去判断“所有 OOXML”,结论并不完整• 更准确的说法应是: • 普通未加密 OOXML 的外层容器头通常为 ZIP。 • 部分加密 OOXML 会表现为复合OLE文档内的加密OPC包存储。

六、参考依据
• pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT • MSHTML & OOXML (.docx) Analysis | Oste's Blog
