 夜雨聆风
夜雨聆风最近读到一篇挺扎心的观点博客,作者 Mark Downie 是个做了 20 多年的技术 Lead,主战场是金融、医疗、制造。文章核心一句话:上一次代码变便宜是 2000 年初的印度外包潮,那一波我们丢了「读得懂代码」的能力,现在 AI 把代码变得更便宜,丢的东西更多,因为这次连一个能解释清楚的「人」都没有。下面把他怎么类比的、为什么这次更糟、工具下一步该往哪做拆给你。

上一次代码便宜:Heartland 和印度外包
Mark 当年在俄亥俄州 Toledo 一家叫 Heartland Information Services 的创业公司干。这家做医疗转录服务,给全美最大几家医院供货。业务听起来简单,背后压力很大,下面这个人手术等着病历,转录晚一分钟可能耽误事。
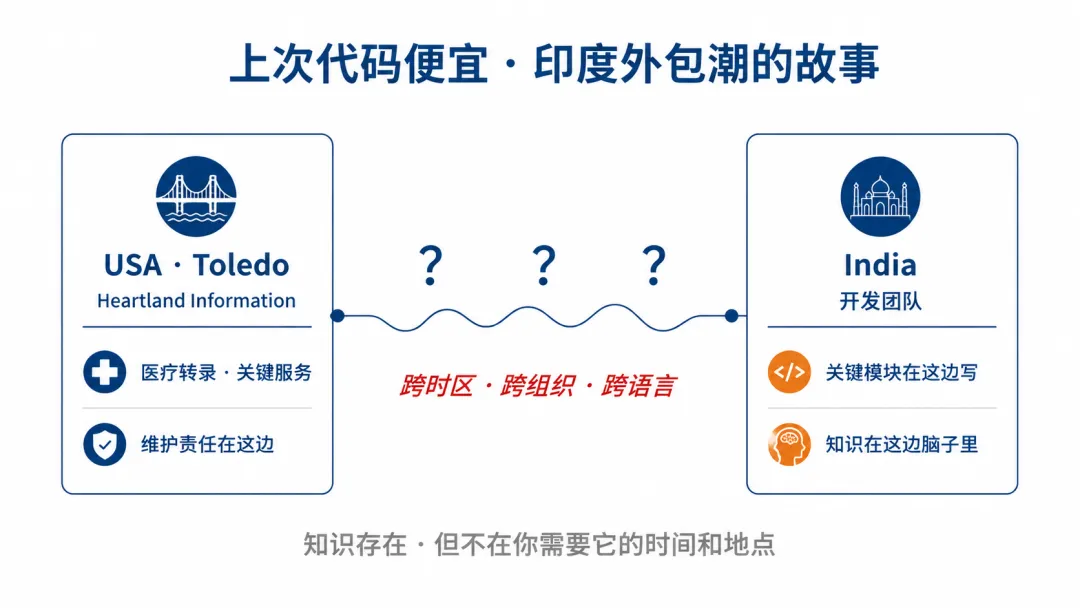
公司当时混合开发,关键模块写在印度部署在美国。原因很直接:印度工程师又便宜又有水平,对一家盯着每一块钱的创业公司来说省下来的成本不可忽视。那也是 Thomas Friedman《世界是平的》刚火的时候,美国本土工程师人人自危,都在问下一个被外包的会不会是自己。
印度团队写出来的代码 Mark 自己说是「他合作过最好的工程师写的」,不是质量不行。问题出在另一个地方:「为什么这段代码这么写」的理解留在一边的脑子里,「出问题去修」的责任压在另一边的肩膀上。知识是存在的,只是不在你需要它的时间和地点。
经济学的公理:东西便宜了,价值转移到互补物
这种「成本转移」不是 Mark 的拍脑袋观察,背后是有经济学定理的。
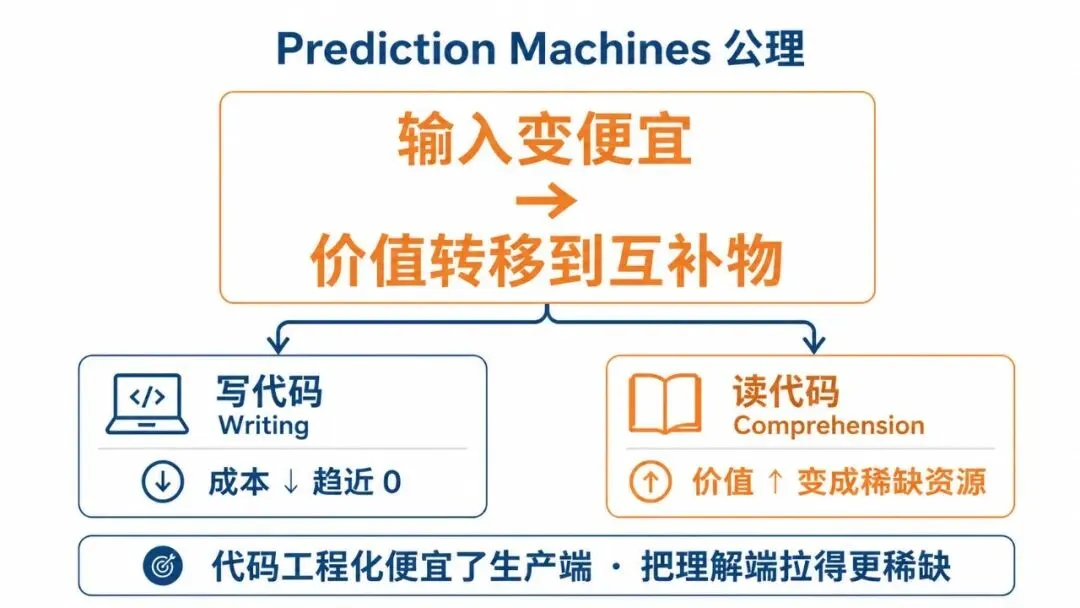
加拿大经济学家 Ajay Agrawal 等人写的《Prediction Machines》里讲过一个核心规律:当一个基础投入变便宜,价值就会转移到它的互补物上。在软件工程里,写代码的互补物一直是「读懂代码」。
外包潮证明了一件事:软件最贵的部分从来不在「把代码写出来」这一步,真正贵的是「写出来之后能不能在压力下安全改动、能不能让下一个接手的人理解为什么周二凌晨 2 点做了那个决定」。代码工程化在便宜化生产端的同时,反而把理解这一侧拉得更稀缺更值钱。
下次你看到 vibe coding 平台号称「30 秒生成全栈应用」,应该立刻想:那 30 秒之后,这堆代码谁来读?谁来改?谁来在生产环境出事的时候说清楚「为什么当时这么写」?
AI 这次更糟:知识根本不在任何人脑子里
外包和 AI 看起来都是让代码生产变便宜,本质上有一个结构性差异。
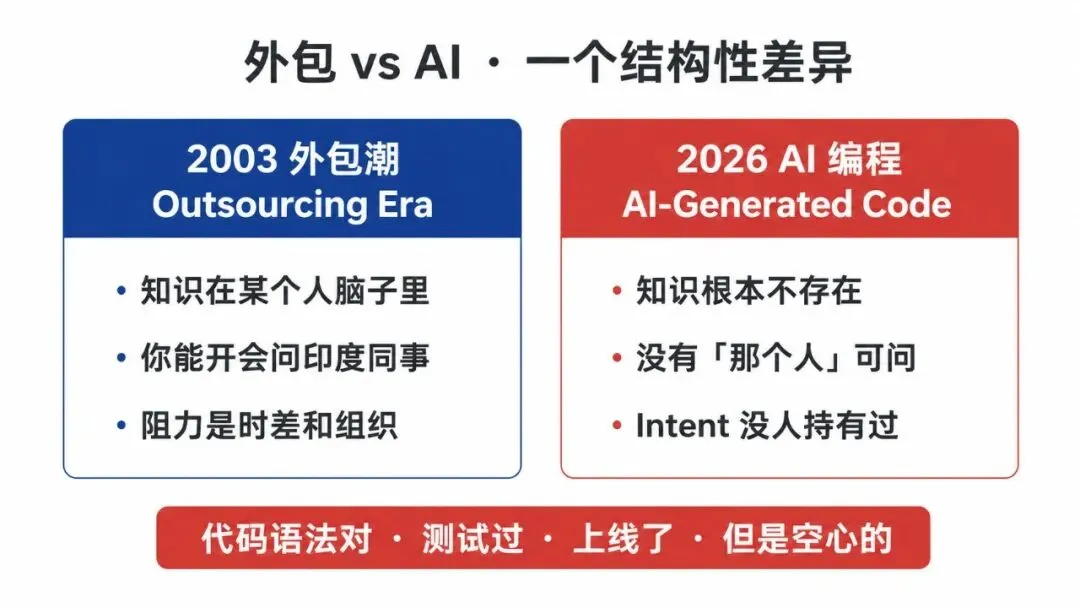
外包时代你拿到一段代码看不懂,至少可以发邮件、开会、问印度同事,那个人脑子里真的装着「我当时为什么这么写」的完整 context。语言、时区、组织架构是阻力,但知识本身存在。
AI 生成的代码不一样,根本没有「那个人」。模型把训练数据里见过的模式拼出一段语法上对的代码,commit 上去看起来工整,但「为什么是这种写法」「这个边界条件是哪个真实场景出过事才加的」,这些 intent 没有任何人持有过。代码语法对、测试过、上线了,但它是空心的。
Mark 在评论区底下,一个叫 Gavin 的咨询师补了一句:「我自己读 Claude 生成的 diff,逐行读,理解程度还是远不如自己写过的代码」。这条评论比文章本身还扎心,是被 AI 编程冲击的工程师群体已经开始普遍体验到的现实。
Joel Spolsky 25 年前就说过的话
软件工程圈对这个问题不是没有共识,是早就有共识,但被便宜的代码生产掩盖了。

Joel Spolsky 早在 25 年前的博客里写过一句话:「读代码比写代码难」(It's harder to read code than to write it)。这句话放在 2001 年的语境是为了反对「重写遗留系统」的冲动,因为重写背后藏着一个错误假设:写新的比读懂旧的更容易。
放到 2026 年的 AI 编程语境里,这句话变得更刺眼。AI 把写代码的成本压到接近零,读代码的成本一点没降。也就是说,软件工程的难度结构发生了根本变化:以前 80% 的工作是写、20% 是理解,现在写的部分 AI 接管了 90%,但理解部分一个百分点都没让出来。理解变成了 100% 的剩余工作量。
那些靠 vibe coding 平台快速产出 demo 的团队,等到要把 demo 升级成生产、要在凌晨 3 点修一个用户报上来的 bug,会突然发现自己面对的是「连写代码的人都不存在」的代码库。这是个新问题。
工具下一步该解决什么
外包潮最终没让所有公司都倒,反而活下来的公司发展得不错。Mark 的观察是这些公司有一个共同动作:把「共同理解」当成一等工程问题来投资。

具体投资的方向包括:把文档当真当严肃事来写、把 code review 当成知识转移而非把关、刻意安排时间培养跨团队对系统的共同理解、在工具上给 onboarding 和遗留代码导航做特殊优化。简单说就是:不再幻想理解会自己产生,而是把它当成需要刻意建造的基础设施。
AI 编程时代的工具该往同一个方向走。Mark 原话:「我们需要为理解而设计的工具,而不只是为产出更快而设计」。具体什么样他没展开,但能想到的方向有:能反推 intent 的代码探索工具、为 LLM 生成代码自动添加架构 context 的工具、强制 AI 输出附带「为什么这么写」的 reasoning trace 的工具、给遗留 AI 代码做语义 diff 而非语法 diff 的工具。
下一波拿融资的开发者工具创业公司,可能不会是「比 Cursor 写得更快」的,会是「比 Cursor 读得更懂」的。
一句话抓重点
便宜的代码生产从来不是免费的午餐。外包潮把成本转移到了沟通和文档,AI 这一波把成本转移到了「理解一段没人写过、没人读过、但已经在生产环境跑的代码」。下次你跟老板要工具预算,别只列写代码快多少,要算理解代码慢多少。
适合谁看:管 10 人以上工程团队的 lead、CTO、做开发者工具的创业者、把 vibe coding 平台搬进生产的产品经理。
不适合谁:纯个人项目玩家不用太焦虑,自己的代码自己读得懂。
原文 poppastring.com/blog/what-we-lost-the-last-time-code-got-cheap,作者 Mark Downie。文章末尾还引用了《Prediction Machines》和 Joel Spolsky 的旧博客 joelonsoftware.com,两本都值得翻一下。
