 夜雨聆风
夜雨聆风前言
要挑最厉害的大模型,目前百花齐放的情况下,可能尚有争议。但要说最厉害的 agent 应用,claude code 当仁不让。这款 AI 应用本来是闭源的,它的魔法、它的技巧本尚不可知,幸运的是如今"被开源了",于是我带着致敬、膜拜的心态学习了 claude code 内部实现,希望能有助于未来自己开发 Agent 应用。
claude code “被开源”对 anthropic 并非坏事,因为 AI 应用和大模型是相辅相成,如果 claude code 被开源,那么中美各家大模型便会针对 claude code 的设计做定制化训练从而让 claude code 有更好的表现,这样也能和其他 AI 应用拉开差距
整体流程
claude code 工作主流程主要分为下面 7 个步骤
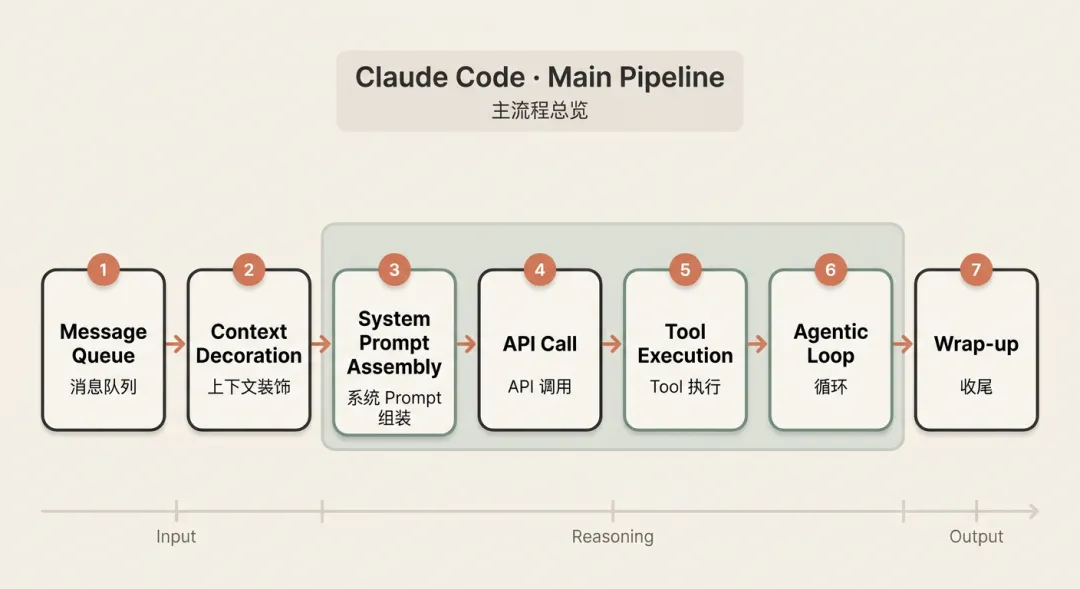
| 节点 | 核心文件 | 职责 |
|---|---|---|
utils/messageQueueManager.ts | ||
context.tsutils/attachments.ts | ||
constants/prompts.tsutils/api.ts | ||
query.tsservices/claude.ts | ||
services/tools/StreamingToolExecutor.tsservices/tools/toolOrchestration.ts | ||
query.ts (agentic loop) | ||
query/stopHooks.tsservices/compact/ |
消息队列
如果把 claude code 想象成一个生产者消费者模型,这个消息队列就是生产者,claude code 根据消息队列里的指令进行动作的执行,消息队列本身是 FIFO 的模式,但是会优先处理高优先级的任务。
优先级分为三种
now:slash command,这是优先级最高的指令,例如常见的 slash command : /test(生成单测) 、/refactor(重构代码)
next:用户的输入:例如帮我给登录代码加下校验
later:后台通知: 例如记忆压缩归档
为什么这么设计?可以看到 slash command 都是方向性的决策,要单测、要重构,是定方向
而用户输入则是迈脚步,要单测,给哪个类写单测,怎么写。显然定方向比迈脚步更重要,如果改变了方向,claude code 需要用最快的响应纠正自身行为。而 later 级别的消息基本是可以晚点执行,不紧急的事情。
这种设计可以确保 claude code 优先保障重要的指令执行,也巧妙做到了机器资源的削峰填谷,later 事件可以在空闲时间段被执行
上下文装饰
为何需要上下文装饰,假想你的 claude code 是一名睡着的演员,他每天醒来要弄清几件事:1. 我今天扮演谁,2. 我在哪个剧组,3. 昨天剧情发展到什么阶段了
那么对应到具体行为上就是以下内容:
我今天扮演谁?
读取 CLAUDE.md 以及时间,这样用户在 CLAUDE.md 里写下的系统概要、架构详情、开发规范都会被 claude code 读取到,并且会放到 user message 里,这样 claude code 就知道了今天面对的是怎么样的一个系统,有哪些规矩都清楚了
我在哪个剧组?
主要是获取 git 状态,会同时执行以下五个指令,大概的知道当前的周围环境
git branch:当前分支名
git remote:默认主分支(main/master)
git status --short:工作区变更摘要
git log --oneline -n 5:最近 5 条提交记录
git config user.name:用户名
昨天剧情发展到什么阶段了
这里涉及到的内容是 Memory 异步加载,这里会开启一个小模型检索相关记忆,但是不会马上使用,而是在第一次执行完 tool 后才会用到这份 Memory。
其实可以看到很明显的问题,claude code 在最开始工作的时候就没有这份记忆,会有问题吗?
这其实是一个权衡,因为加载记忆是需要耗时的,claude code 在执行完第一个 tool 后,memory 大概率就加载好了,这样用户就不需要等待 memory 加载的过程,同时 claude 认为刚执行的时候还用不着记忆,放到我们这里的比喻可能是,演员还在化妆,还在穿衣,还不需要知道昨天剧情发展到什么阶段
memory 的完整召回机制(含双重召回)会在下文"记忆"章节详述。这里的异步加载有以下特点:1. 目标宽松:找所有潜在相关的记忆;2. 无预算压力:反正不立即注入,可以慢慢算;3. 利用空闲:LLM streaming 和 tool 执行的时间窗口足够它跑完。
系统 prompt 组装
┌─────────────────────────────────────┐│ Static (Static Sections) ││ identity, security, tool rules ││ → cache scope: 'global' │├── __DYNAMIC_BOUNDARY__ ─────────────┤│ Dynamic (Dynamic Sections) ││ env info, memory, lang, MCP instr ││ → cache scope: 'org' or none │└─────────────────────────────────────┘在用户消息经过队列、上下文装饰之后,系统需要构造一个完整的 system prompt 发送给 LLM。这个 prompt 不是写死的,而是一个 54KB 左右的动态组装产物,由多个部分组成,并根据使用频率和变化性进行缓存策略划分。
核心函数:getSystemPrompt()
它把 prompt 分成两部分:
静态部分:身份、权限、安全限制、推理风格、tool 列表信息
动态部分:环境、记忆、MCP 信息(因为涉及网络连接不稳定,放在了动态部分)
如果每次请求都重新拼接所有字符串 → 浪费 CPU + 增加延迟
如果全部硬编码 → 无法适配不同用户/项目
如果全量缓存 → 内存爆炸 + 数据过期风险
所以,"分治 + 缓存分级"成为最优解。通过区分变化与不变,以最大化缓存命中率 + 最小化重复计算 + 适应实时变化。
API 调用
请求结构里包含了 System Prompt、User Messages、Tool List。无论 agent 多么厉害可以干多少活,到了这里就又回到了普通的聊天机器人的模式,message in message out。只不过多了更多的上下文信息
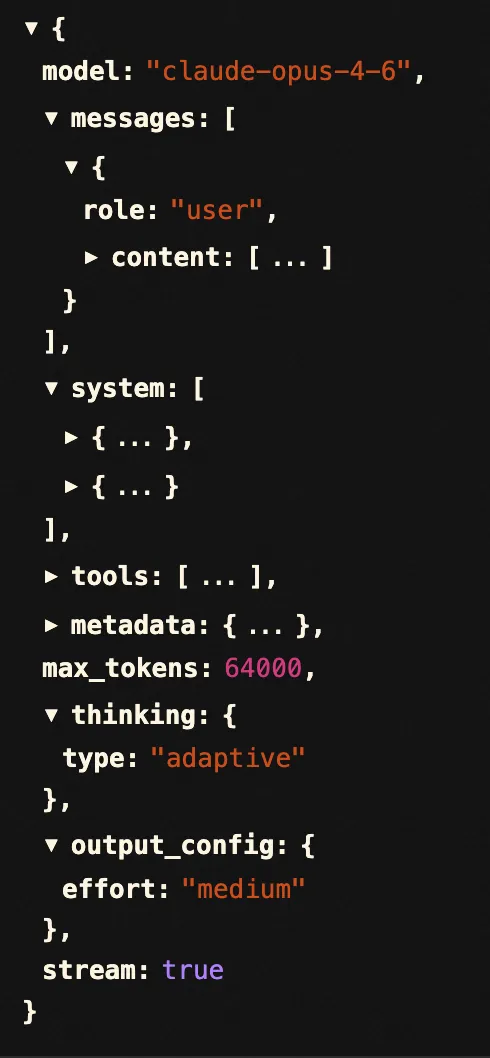
API 的响应是流式的,返回的是 server-sent-events,claude code 将流式处理的返回转换成了以下内部事件
message_start(初始化)
作用:标记一个新消息的开始,初始化
AssistantMessage对象。
{ "type": "message_start", "message": { "id": "msg_abc123", "role": "assistant", "content": [ ], "model": "claude-sonnet-4-20250514", "stop_reason": null, "usage": { "input_tokens": 0, "output_tokens": 0 } }}创建新的 AssistantMessage 实例 2. 初始化空的内容数组 content: [ ]
content_block_start(增量更新)
作用:开始一个新的内容块 —— 可能是纯文本,也可能是工具调用指令。
{ "type": "content_block_start", "index": 0, "content_block": { "type": "text", // 或 "tool_use" "text": "" // 初始为空 }}根据 type 判断是文本块还是工具块,如果是 tool_use,则准备解析后续 JSON 参数。
content_block_delta(增量更新)
作用:增量更新当前内容块 —— 每次只追加一小段文本或 JSON 片段。
{ "type": "content_block_delta", "index": 0, "delta": { "type": "text_delta", "text": "Let me check the file..." }}content_block_stop(完整性校验)
作用:标记当前内容块结束,确认其完整性。
{ "type": "content_block_stop", "index": 0}对于文本块:标记为"已完成",不再接受 delta
对于工具块:尝试解析累积的 JSON,若合法则立马触发工具执行无需等待后续 content 内容,降低用户感知的延迟
更新
AssistantMessage.content[index]的状态为complete
message_delta(元信息同步)
作用:更新消息级别的元信息,通常是
stop_reason(停止原因)。
{ "type": "message_delta", "delta": { "stop_reason": "end_turn", // 正常结束 // 或 "max_tokens", "tool_use", "error", etc. }, "usage": { "output_tokens": 1234 }}更新
AssistantMessage.stop_reason记录 token 使用量(用于计费与配额管理)
若
stop_reason === "tool_use"则触发工具执行流程若
stop_reason === "error"则记录错误日志并通知用户
message_stop(资源释放)
作用:标记整个消息结束,释放资源,通知上游完成。
{ "type": "message_stop", "message": { "id": "msg_abc123", "role": "assistant", "content": [ ... ], "stop_reason": "end_turn", "usage": { "input_tokens": 500, "output_tokens": 1234 } }}标记
AssistantMessage为"已完成"触发下游处理(如保存历史记录、更新 UI、启动下一轮循环)
发送"完成"信号给前端(关闭加载动画、启用输入框)
Tool 执行
当 Claude 模型决定调用某个工具(比如 Read、Edit、Bash),它会生成一个 tool_use 块。这个块不会直接执行,而是进入 StreamingToolExecutor(一个带有多重防护机制的执行引擎)。其中 StreamingToolExecutor 负责单个工具的执行流水线,toolOrchestration 负责多工具的并发/串行编排。
在执行工具的时候有六步规则
循环
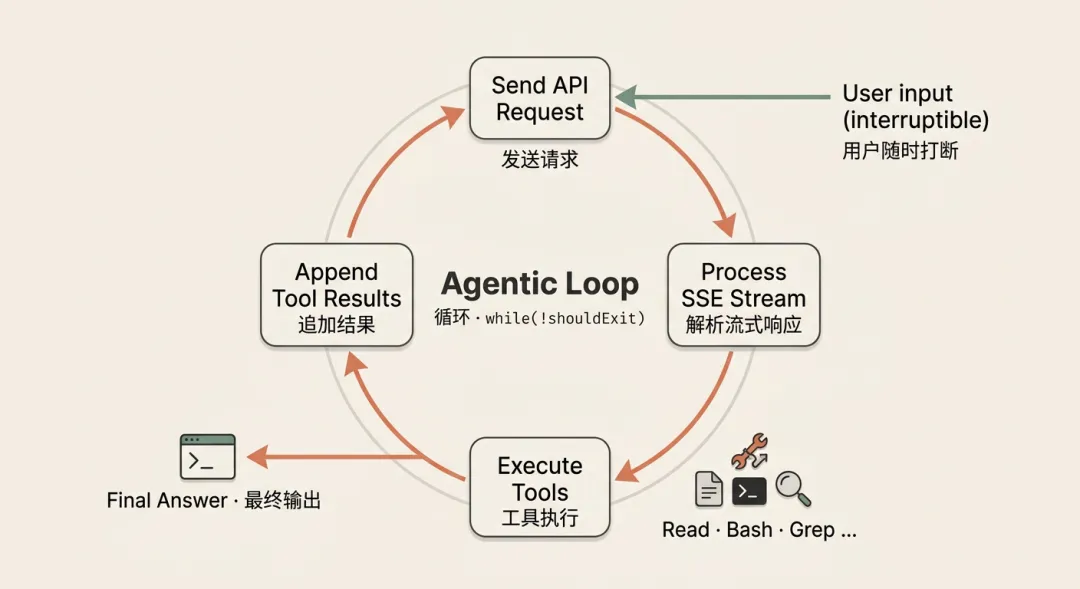
如果说上面的步骤是准备食材架锅做饭,那么这个步骤就是厨师正式做菜的环节,像一个程序员在调试 bug :他先看报错 → 读代码 → 改代码 → 跑测试 → 看结果 → 直到解决。Agent 就是这个过程的自动化版本。具备以下能力
| 特性 | 说明 |
|---|---|
循环的伪代码实现
public void run(String initialUserInput) { List<Message> messages = new ArrayList<>(); messages.add(new Message("user", initialUserInput)); while (true) { // Step 1: 组装上下文以及发送 API 请求 SSEStream stream = sendApiRequest(messages); // Step 2: 处理流事件以及工具执行 AssistantMessage assistantMsg = processStream(stream); // Step 3: 检查是否需要退出 if (shouldExit(assistantMsg)) { break; } // Step 4: 添加工具执行结果 appendToolResultsToMessages(messages, assistantMsg.getToolResults()); // Step 5: 检查用户是否有新输入 if (hasNewUserInput()) { appendNewUserInputsToMessages(messages); } // Step 6: 再次循环 } //跳出循环,准备渲染最终结果 uiRenderer.renderFinalResponse(assistantMsg.getText()); }收尾
到了这一步,claude 已经干好了一次用户的请求,此时依然会做三件事情:记忆保存、上下文压缩、会话存储。
记忆保存:分析本次对话值得记忆的内容存到 MEMORY.md。
上下文压缩:如果上下文窗口用掉了 80% 则会触发,用模型生成一个结构化的摘要,保留关键信息(文件路径、决策原因、未完成的任务)。
会话存储:保存本次的会话所有内容,后续可以通过 claude --resume 命令继续本次会话。
上下文管理
缓存
在大语言模型(LLM)中,每一次 API 调用都会发送完整的 system prompt + user message。模型在处理时,会先生成 KV Cache(Key-Value Cache),这是 Transformer 架构中用于加速自回归生成的关键数据结构。如果 prompt 没变,KV Cache 就可以复用,从而省下大量计算。
所以,如何智能地拆分 prompt,让不变的部分尽可能被缓存?
三级缓存
Claude Code 将 prompt 的缓存划分为三个级别,每个级别有不同的:
Content(内容)
Scope(范围)
Condition / Invalidate(触发条件 / 失效机制)
Reason(设计原因)
全局缓存
内容 (Content): 静态信息,包括身份定义 (Identity)、规则 (Rules)、风格 (Style) 等。这些是模型最基础且几乎不变的设定。
范围 (Scope): 所有用户共享 (Shared by All Users)。
触发条件 (Condition): 仅直接连接 Anthropic API 时有效(通过第三方代理则无法命中)。
失效时机 (Invalidate): 仅在版本更新时失效(例如当 Anthropic 更新了安全规则)。
设计原因: 这是最稳定、复用率最高的部分,能够最大化地节省计算资源。
组织级缓存
内容 (Content): 动态但相对稳定的信息,包括环境配置 (Env)、记忆 (Memory)、语言偏好 (Lang) 等。
范围 (Scope): 同一组织内的用户共享 (Same Org Users)。
失效机制 (Invalidate): 当配置发生变化时失效 (On Config Change)。
特点: 这部分内容比全局缓存更易变,但在组织内部具有共性,因此可以在组织级别进行缓存复用。
无缓存
内容 (Content): MCP Instructions (MCP 指令)。
范围 (Scope): 每次请求重新计算 (Recalculate Each Request)。
原因 (Reason): MCP 服务可能随时连接或断开 (May Connect/Disconnect Anytime),具有高度的不确定性和实时性。
特点: 由于这部分内容变化频繁且不可预测,无法有效缓存,因此每次都需要重新处理。
上下文清理
agent 相比传统的 chat bot 最大的特点之一是 agent 能够记住你之前问过的内容,实现这一特点也仅仅是通过将过往问过的内容添加到 prompt 给到 AI 而已。那么随着 agent 的运行,AI 运行的轮次变多,提问变多,回答变多,工具执行的次数也变多,就会导致 prompt 越来越大,如果放任不管就会发现 agent 运行到后期越来越臃肿,前期的很多关键信息无法感知同时带来很多不必要的 token 开销。
claude code 有一套独特的上下文清理机制来清理臃肿的 prompt。
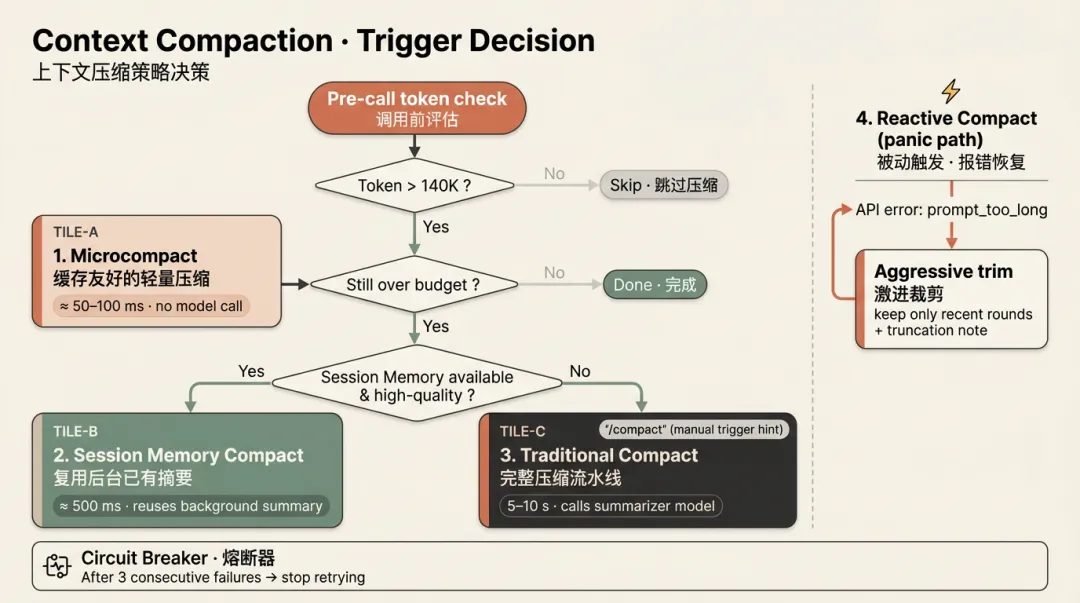
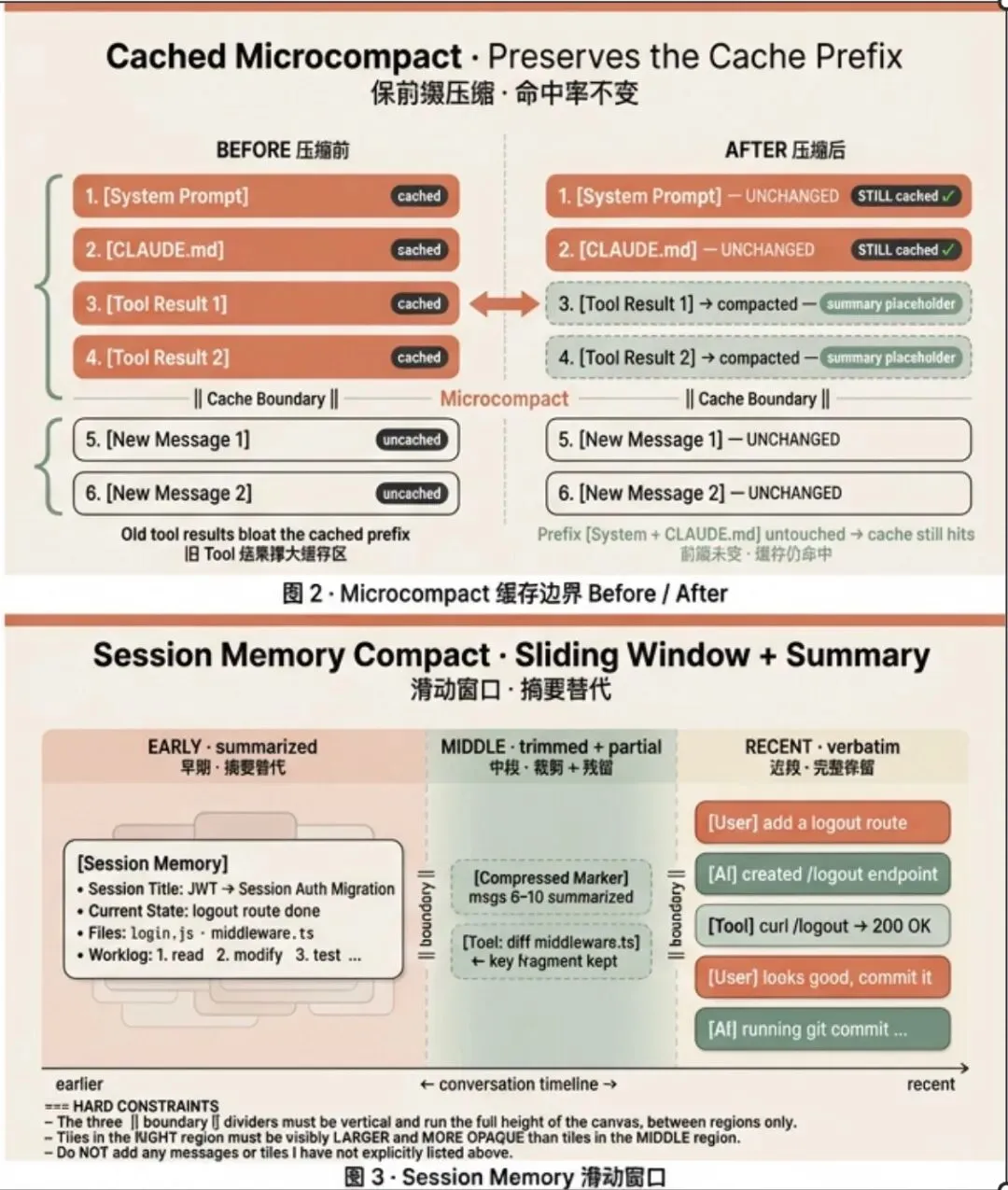
Microcompact
这是最轻量的压缩手段,不调用模型,只压缩 tool 的执行结果。被压缩的 tool 结果替换为一条简短的占位消息,类似于:"Tool result cleared to save context. The tool was called with: Read { file_path: "src/auth.ts" }"。这保留了"调用了什么"的信息(模型知道它曾经读过这个文件),但丢弃了具体内容。
Microcompact 有两种触发的方式分别是 Cached Microcompact 和 Time-Based Microcompact。
| 特性 | Cached Microcompact | Time-Based Microcompact |
|---|---|---|
怎么计算缓存边界?
Claude Code 是客户端,它需要知道服务端到底缓存到了哪里。计算过程如下:
记录结构:客户端在每次发送请求时,会记录 Prompt 的完整结构(例如:
[System Prompt] -> [CLAUDE.md] -> [Message 1] -> [Tool Result A] -> [Tool Result B] ...)。读取反馈:API 响应中会返回两个关键数据:
cache_read_input_tokens:这次命中了多少缓存 Token。cache_creation_input_tokens:这次新创建了多少缓存 Token。反向推算:客户端将
cache_read_input_tokens的数量与之前记录的 Prompt 结构进行比对。例如:System 占 500 tokens,CLAUDE.md 占 2000 tokens,Message 1 占 300 tokens。如果 API 返回命中了 2800 tokens,客户端就能算出:缓存边界停在 CLAUDE.md的末尾附近(500+2000+300=2800)。定位 Index:系统由此确定
boundaryIndex具体落在哪一条消息的结尾。
Cached Microcompact 的核心逻辑
理解了"缓存边界"后,这个变体的精妙之处就显而易见了。
策略:只动"边界内"的旧消息,不动"边界外"的新消息
假设你的 Prompt 结构如下,且上次的缓存边界在 Tool Result 2 的末尾: [System] [CLAUDE.md] [Tool Result 1] [Tool Result 2] ||边界|| [New Message 1] [New Message 2]
如果触发 Cached Microcompact:
系统会压缩
[Tool Result 1]和[Tool Result 2](例如将它们替换为简短摘要)。关键效果:虽然
[Tool Result 1 & 2]因为内容改变导致它们自身的缓存失效,但是[System]和[CLAUDE.md]这部分内容完全没有动!因此,下一次请求时,
[System]和[CLAUDE.md]依然能命中缓存——这就是"保持缓存前缀不变、命中缓存"的关键。系统选择不动
||边界||之后的[New Message 1 & 2],是因为这些新消息本来就没有缓存,无法带来缓存收益。
如果 Microcompact 压缩的空间不够则会走到下面的逻辑。
Session Memory Compact
Claude Code 有一个后台任务,在每轮对话结束后自动运行,由一个独立的 agent 持续提取对话中的关键信息。session memory 包含以下信息
| # | 部分名称 | 内容说明 | 示例解读 |
|---|---|---|---|
"帮我新增开发授信接口" | |||
"机构层接口 已完成,正在改 数据库层" | |||
"先改 spi 层,再改 sop 层" | |||
"creditApplySpi - 核心逻辑" | |||
"npm test 验证每次修改" | |||
"加密密钥报错,密钥配置需要正确" | |||
" HSF Facade → Service → SPI" | |||
"要先分析接口文档,参考类似接口的执行链路" | |||
"涉及文档在 xxx/xxx/x.md" | |||
"1. 读 creditApplySpi 2. 改 middleware..." |
session memory compact 采用"滑动窗口 + 摘要替代"的混合模式:
最早期的对话: 被 Session Memory 摘要替代
中间部分: 可能被裁剪或标记为已压缩
最近部分:完整保留,保证 AI 对当前任务状态不丢失感知
可以用下列情况举例
[System] 初始化环境:Node v18, Express 4.18, Redis 7.0[CLAUDE.md] 项目规范:使用 TypeScript,ESLint strict,测试覆盖率 >80%[Tool Result 1] 读取 src/auth/jwtMiddleware.ts → 内容:验证 JWT token...[Tool Result 2] 读取 src/routes/login.js → 内容:接收用户名密码,生成 JWT...[User Message 1] 帮我把 JWT 改成 Session Auth,用 Redis 存 session。[AI Response 1] 好的,我们先创建 sessionStore.js,然后修改 middleware...[Tool Result 3] 创建 src/sessionStore.js → 使用 redis.createClient()...[User Message 2] 改完 middleware 后测试报错:bcrypt.compare is not a function[AI Response 2] 可能是版本问题,降级 bcrypt 到 5.x...[Tool Result 4] npm install bcrypt@5.1.1 → 成功[User Message 3] 现在改 routes/login.js,别再生成 JWT 了,要设 session.req.user[AI Response 3] 已修改 login.js,调用 req.session.save()...[Tool Result 5] 运行 npm test → 全部通过 ✅[User Message 4] 最后一步:加个 logout 路由,清除 session[AI Response 4] 创建 /logout 路由,调用 req.session.destroy()...[Tool Result 6] curl http://localhost:3000/logout → 返回 200 OK通过压缩变成了
||边界||[Session Memory]{ "Session Title": "JWT to Session Auth Migration", "Current State": "logout 路由已完成", "Files and Functions": "src/login.js (已改为 set session), src/middleware.ts (已改为 check session)", "Worklog": "... 3. 改 login.js 4. 改 middleware ..."}[Compressed Marker: Middle Messages 6-10 Summarized & Partially Kept]// 这里体现了“中间部分”的特殊处理:// 大部分被摘要吸收,但如果有未吸收的关键代码片段,可能会以精简形式保留[Tool Result: Diff of src/middleware.ts] // ^^^ 这是一个“中间部分”的残留:因为 middleware 的改动对当前任务很重要,// 但 Session Memory 只说了“已改”,没展示代码,所以保留了关键的 Diff 结果。[New Message 11] User: 最后一步:加个 logout 路由...[New Message 12] AI: 创建 /logout 路由...[New Message 13] Tool: curl ... 200 OK[New Message 14] User: 看起来不错,提交代码吧。[New Message 15] AI: 好的,正在 git commit...中间部分的原始文本被裁剪,其精华被合并进唯一的 Session Memory。Compressed Marker 仅仅是用来分隔"摘要"和"最新原文"的逻辑界限,保留更多细节,减少幻觉。
Traditional Compact
当 Microcompact 省不出足够空间,Session Memory 又不可用(或质量不够)时,系统启动完整的压缩流水线。这时候需要调用模型生成摘要,耗时 5-10 秒。
五步压缩流水线
步骤一:预处理 (Pre-processing)
在把数据扔给昂贵的摘要模型之前,先做"清洗",以节省 Token 并提高摘要质量。
执行 Microcompact:确保之前的简单优化已生效,减少噪音。
剥离二进制内容:
图片 → 替换为占位符
[image]文档 → 替换为占位符
[document]目的:摘要模型不需要看图片像素,只需要知道“这里有一张图”即可,大幅降低输入长度。
剥离可重新注入的附件:
如
skill附件、file附件等。原因:这些内容在压缩后会被重新注入(Re-inject)到新的上下文中(见步骤五)。如果在摘要过程中让它们占用 Token,既浪费钱又可能干扰模型对对话逻辑的理解。
步骤二:按 API Round 分组 (Grouping by API Round)
定义:将消息流切割成一个个完整的交互单元(Round)。
一个 Round 包含:
用户提问→Agent 回复→工具调用结果→Agent 最终回答。目的:保持对话的原子性。在后续如果因为太长需要丢弃旧数据时,以“Round”为单位丢弃,避免拆散一个完整的问答逻辑(比如只保留了问题却丢了答案)。
步骤三:Fork 摘要 Agent (Fork Summary Agent)
操作:创建一个独立的、专用的 Agent 来专门负责写摘要。
严格限制:
只读权限:只能读取文件,不能修改代码或执行任何工具。
纯文本模式:不允许调用外部 Tool。
独立上下文:拥有独立的 Token 预算,不占用主 Agent 的资源。
为什么这么做?
隔离性 (Isolation):摘要生成的中间思考过程(Chain of Thought)不应污染主 Agent 的对话历史。
安全性 (Safety):防止摘要模型在“总结”过程中意外执行了危险操作(如误删文件)。主 Agent 负责干活,摘要 Agent 负责读书,职责分离。
步骤四:PTL 重试循环 (Prompt Too Long Retry Loop)
PTL = Prompt Too Long,即输入超过模型最大上下文窗口时返回的错误。
问题:如果对话历史实在太长,连"发送给摘要模型的请求"本身都超过了模型的最大上下文窗口(即
prompt_too_long错误)。解决方案:启动渐进式丢弃机制。
第 1 次尝试:发送完整历史。若失败 → 丢弃最旧的 1 个 API Round。
第 2 次尝试:发送剩余历史(N-1 个 Rounds)。若失败 → 再丢弃最旧的 1 个 Round。
最多重试 3 次:如果还是太长,放弃压缩或报错。
逻辑:最旧的对话通常信息价值最低,优先牺牲它们以换取摘要任务的成功执行。
步骤五:构建压缩后的消息 (Constructing Compacted Messages)
摘要生成成功后,系统重组上下文,形成新的消息序列:
| 组成部分 | 说明 | 作用 |
|---|---|---|
[system prompt] | ||
[compact_boundary] | ||
[summary_message] | ||
[recent_assistant] | ||
[reinject_context] |
上下文重注入
因为在步骤一的预处理阶段摘除了一些内容进行压缩,这里会重新恢复,主要是文件附件、skill/hooks、tool schema。
Reactive Compact
上面提到的 Microcompact、Session Memory Compact、Traditional Compact 都是主动压缩,是在 agent 相对宽裕从容的情况下进行的压缩,但是会出现这种情况:仅执行了一个 Bash 命令,输出了 50K tokens 的日志。一瞬间,token 使用量从 150K 跳到 200K,直接越过了所有阈值,API 返回 prompt_too_long 错误。收到报错后:
首先尝试 Traditional Compact
如果第一步后依然报错 prompt_too_long,则进行 PTL 的重试,最多重试 3 次
如果重试也失败,执行最激进的裁剪——直接丢弃旧消息,只保留最近的几轮对话和一条简短的说明:"之前的对话因为上下文限制被截断了"
熔断器
因为压缩是有成本的,像 Traditional Compact 需要调一次 API,即使是 Microcompact 也需要遍历和重组消息。如果压缩反复失败——比如因为网络问题、API 限流、或者某种边界情况——则在连续 3 次压缩失败后,停止尝试。失败后用户会看到明确的报错并被建议手动 /compact 或开启新会话,从而避免更多的资源浪费。
下面是几种压缩方式的触发时机和用户感知情况
/compact → 直接触发 | ||
记忆
Memory 系统就是 claude code 的跨 session 持久化记忆机制,claude code 越用越聪明的秘密就在这里。下面主要讨论记忆写入、加载的具体流程。
写入流程
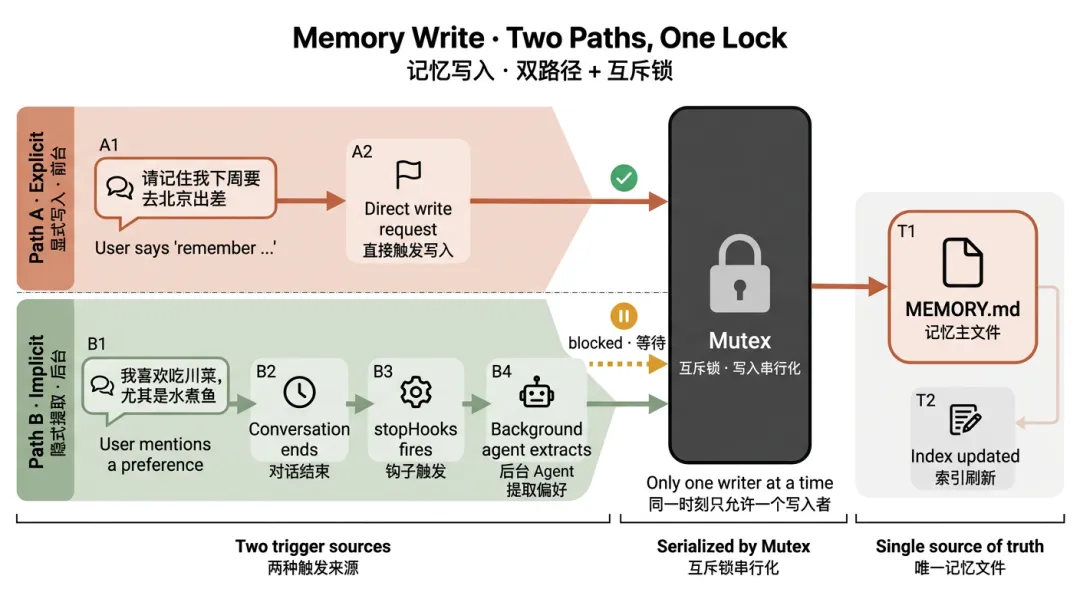
假设你正在和一个 AI 助手聊天:
场景一(显式请求):
你说:"请记住我下周要去北京出差。" → 直接写入 MEMORY.md → 更新索引 → 完成
场景二(隐式提取):
你说:"我喜欢吃川菜,尤其是水煮鱼。" → 没有说"请记住",但对话结束后触发 stopHooks → 后台提取"喜欢川菜"这一偏好 → Agent 分析后决定写入记忆 → 更新索引 → 完成
场景三(并发保护):
如果两个线程同时尝试写入记忆(比如前台写入 + 后台提取),Mutex 会阻止其中一个,避免数据混乱。
读取流程
Claude Code 的召回机制设计得非常精巧,分为两层:始终加载的索引层和按需注入的内容层。这种分层设计旨在平衡"上下文感知能力"与"Token 成本/上下文窗口限制"。
双层召回机制
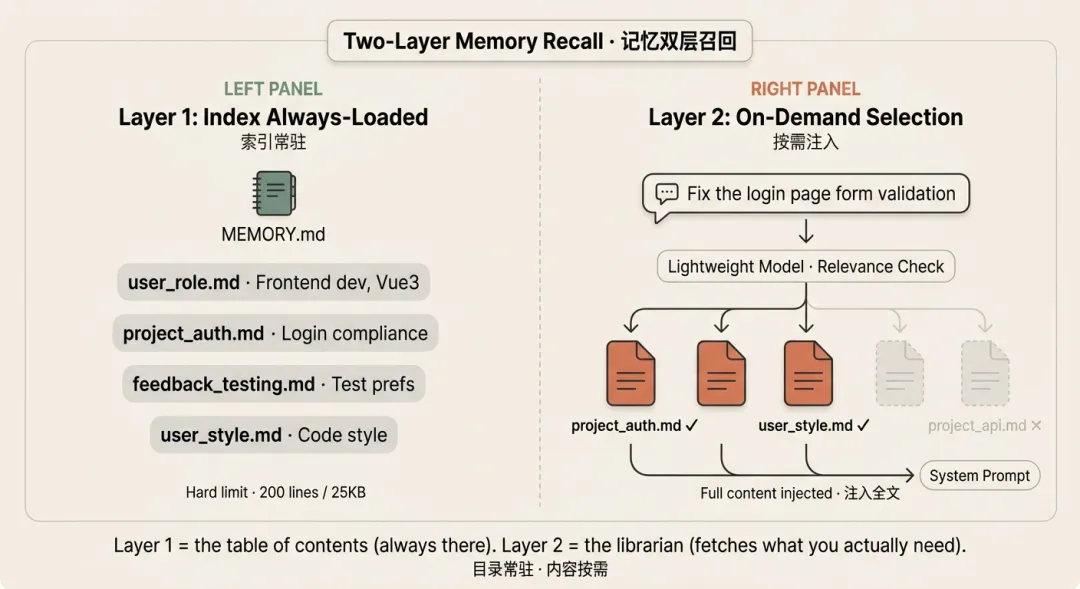
第一层:MEMORY.md 索引常驻
特点:无条件加载、轻量级、全局视野
加载时机:每次会话启动时,系统 prompt 组装过程会 无条件加载
MEMORY.md文件。文件内容:它不包含具体的知识细节,只包含每条记忆的 一行摘要 和 文件路径。
例如: - user_role.md: Frontend dev, Vue3硬限制:该文件有 200 行 / 25KB 的大小限制。
优势:
成本可控:因为文件很小且固定,加载成本极低。
即时感知:Claude 在对话的第一轮就知道"我记得哪些事情",即使它还没有读取任何具体记忆文件的内容。这就像书的目录,让你一眼知道书里有什么。
第二层:相关性选择
特点:按需加载、智能筛选、动态注入
触发时机:当用户发送消息时。
执行者:使用一个轻量模型(如 Haiku/Sonnet)来判断。
核心任务:在所有已知的记忆文件中,判断哪些和当前对话相关。
工作流程详解
1. 输入
用户消息:Fix the login page form validation(修复登录页表单验证)
已加载的索引(MEMORY.md Index):
user_role.md: Frontend dev, Vue3project_auth.md: Login compliancefeedback_testing.md: Test prefsuser_style.md: Code style preferencesproject_api.md: API spec ...
2. 处理:相关性检查
轻量模型分析用户意图(关键词:"login page"、"form validation"),遍历索引中的每一项评估相关性:
project_auth.md→ 高度相关(涉及 Login compliance)user_role.md→ 需要(修代码需知道是 Vue3)user_style.md→ 相关(修代码需遵循规范)feedback_testing.md→ 不相关(测试偏好与此无关)project_api.md→ 不相关(API 规格与此无关)
3. 输出:注入完整内容
系统将被选中文件的完整内容(不是摘要)注入到 system prompt 中,本例为 project_auth.md、user_role.md、user_style.md 的全文。
和异步预取的差别
前文提到记忆是异步加载的,会在第一个 tool 执行完毕后才进行回填。这里区分一下这两种记忆加载方式:
query 循环入口处(与主流程并行启动) | ||
总结
通过对 claude code 的深入理解,可以看到 agent 的开发,本质上都是生成一份 prompt 调用大模型 API,获得结果。只不过如何生成这份 prompt 成了关注的重心。
prompt 膨胀变大怎么办?有了上下文管理;
prompt 没有我之前问过的内容怎么办?有了记忆的管理;
prompt 需要其他更多的信息怎么办?有了 skill 与 mcp;
prompt 比较复杂要做的东西比较多怎么办?有了本文还未介绍的 subAgent 以及 forkAgent。
