 夜雨聆风
夜雨聆风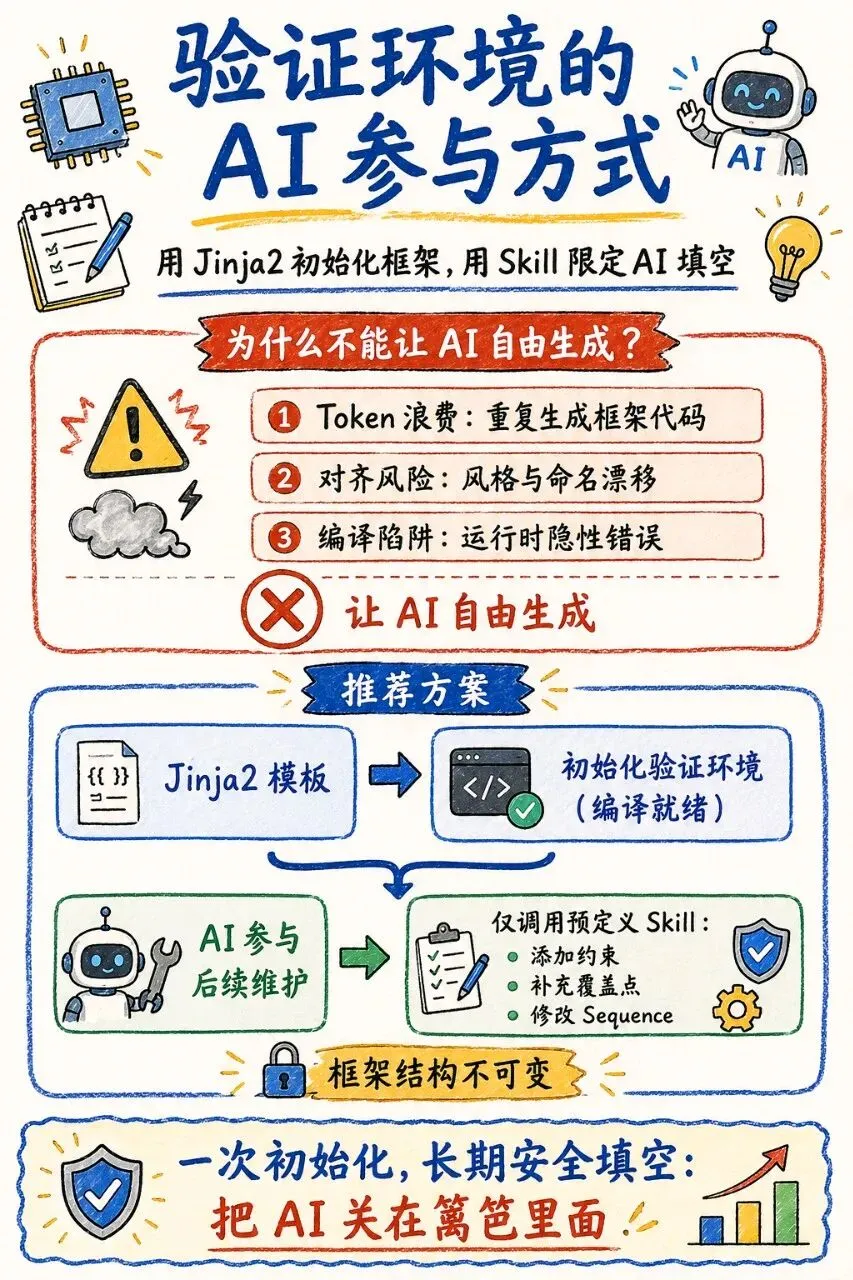
让 AI 直接生成验证环境,对大多数工程师来说还是件没来得及尝试的新鲜事。但已经有一些先行者踩过坑:任凭 AI 从零开始写 UVM 代码,看似省事,实际藏着不小的代价——Token 被大量浪费在重复的框架输出上,每次生成风格都可能漂移,编译和运行时的隐性错误防不胜防。
经历了几次这样的尝试之后,一个共识慢慢浮现:验证环境的框架必须由人严格定义,AI 只能在预留好的位置里做填空。
一、任由 AI 生成整个环境的真实代价
如果让 AI 从无到有生成一个完整的验证环境,问题会被放大到三个难以承受的层面。
首先是 Token 浪费。 一个中等规模的 UVM 环境,agent、env、testbench 顶层加上基础 sequence,模板性质的代码轻易就有数百行。import 语句、组件注册宏、build_phase 里的例化套路、connect_phase 里的连接关系,这些都是每个项目几乎重复的内容。让大模型每次都重新输出这些“胶水代码”,就像请一个架构师去反复砌砖一样,成本极高。而真正需要 AI 智能决策的部分,其实只有少数几处约束、一些覆盖点定义和部分 sequence 行为。
其次是对齐风险。 AI 在不同对话、不同版本中生成的代码风格和命名习惯会自然漂移。这次的 monitor 用了 analysis_port,下次可能换成了 uvm_tlm_analysis_fifo。同一个信号可能在此处叫 req_vld,在另一处又被写成了 req_valid。人类工程师在做集成时,要花大量精力去统一这些差异,而这种对齐开销常常高于从头手写。
最后是编译和运行时的隐性陷阱。 UVM 的语法和宏并不宽容,很多问题会在运行时而非编译期暴露出来。AI 生成的代码表面上可能零编译错误,但 config db 路径不匹配、phase 跳转遗漏、sequence 约束空挂等问题往往要跑回归才能被发现。更糟糕的是,修复一个错误时,让 AI 再次修改常常会牵动更多地方,带来新的不稳定性。
二、人类工程师的方法论,恰恰就是答案
回头看资深验证工程师的做法,会发现一个成熟的工作方式:初始化环境时,用模板生成高确定性的骨架;后续开发中,只在骨架预留的位置上不断填入新的业务逻辑。
具体来说,项目启动时会有一套成熟的目录和文件框架。顶层 testbench 的模块例化、interface 的连接、config db 的路径关系,这些都写成高度参数化的模板,通过少量变量(比如模块名、总线类型)渲染出一套编译就绪的初始化环境。
之后,随着验证的推进,工程师真正要反复修改的,并不是环境的结构,而是约束条件、功能覆盖点、定向测试的 sequence 等等。这些修改都发生在模板事先留好的“空地”上,结构的稳定性从未被动摇。
这套方法的核心在于:将确定性的结构一次性固化,将不确定的变量交给参数化机制处理,将需要持续演化的部分隔离在限定的空间内。 AI 时代的工具,要做的不是推倒重来,而是用 AI 去放大这套方法论。
三、正确路径:Jinja2 生成初始化框架,AI 在框架内维护
将上述方法论映射到 AI 参与的流程中,合理的分工应该分两个阶段。
阶段一:用 Jinja2 生成初始化环境。 Jinja2 是一个 Python 模板引擎,在硬件代码生成领域应用广泛。在验证环境构建的第一步,人类工程师准备好一套验证环境的模板文件,里面定义了完整的目录结构、组件树、phase 机制和连接关系。模板里不做任何真正的业务决策,只通过变量和简单逻辑预留出待填充的空白。例如:
```
class {{ agent_name }}_agent extends uvm_agent;
`uvm_component_utils({{ agent_name }}_agent)
function void build_phase(uvm_phase phase);
super.build_phase(phase);
{% if has_monitor %}
monitor = {{ agent_name }}_monitor::type_id::create("monitor", this);
{% endif %}
{% if has_driver %}
driver = {{ agent_name }}_driver::type_id::create("driver", this);
{% endif %}
endfunction
```
在这个阶段,AI 的作用很轻:它只需要根据项目需求,确定 agent_name、has_monitor、has_driver 等少数几个参数的取值。脚本将这些参数传入 Jinja2,几秒之内就能渲染出一套结构完全稳定、编译一定通过的初始化验证环境。
阶段二:AI 在框架内进行填充和后续维护。 环境初始化完成后,工作才真正开始。工程师需要不断加约束、加覆盖点、加新的 sequence、调整 scoreboard 的比较逻辑。所有这些操作,都在框架早已留出的“可修改区域”内进行。
为了让 AI 安全地参与这个长期维护过程,我们不是让它去直接修改文件,而是为每一种允许的操作定义成原子化的技能(Skill),每个 skill 背后是一个精确的脚本动作,作用范围被严格限定。比如:
· “为某个 sequence 添加一个新的 body 行为”
· “给某个寄存器模型增加一个 field”
· “在 scoreboard 中插入一个新的比较项”
AI 在后续使用中,只是将这些 skill 作为工具来调用,传递必要的参数。它无权去改动 agent 的 build_phase 结构,也碰不到顶层 testbench 的连接关系。这就像工程师在一个接一个地完成小需求,但绝不会去推翻已经验证通过的架构。
这种方式的好处非常清晰:Token 消耗被压到极低,因为 AI 每次只传递意图和参数,不传输重复的框架代码;编译风险被提前消除,因为框架和 skill 脚本已经过完整验证;对齐问题彻底消失,因为所有修改都发生在同一套模板体系内,风格和命名自然统一。
四、Jinja2 在这里的真正定位
Jinja2 在整个流程中的角色是明确的:它只负责“诞生”环境的那一刻,而不是维护环境的一生。 模板继承、宏、条件判断这些特性,让它可以干净地描述“一套具有多个变体的标准框架”。用它来初始化验证环境,本质上就是把团队多年积累的稳定结构用可编程的方式固定下来。
一旦环境初始化完成,Jinja2 就退场了。后续的演进交给 AI 在限定的 skill 集合内完成。AI 成为一个持续在框架边界内做填空题的协作者,而不是一个随时可能重写整个建筑的破坏者。
五、让 AI 回到它真正擅长的事
验证工程师最担心的从来不是工作量,而是集成时引入的隐性风险。让 AI 从零自由生成整个验证环境,本质上是把不确定性引入了系统最不该不稳定的地方。正确的思路,恰恰是把人类工程师一直用的那套方法工具化:用 Jinja2 在起点处生成固定的、经过充分验证的初始化环境;然后用边界清晰的 skill 和脚本,让 AI 在后续的漫长时间里,安全地填充业务内容。
围墙之内,AI 是高效率的助手;围墙之外,AI 是风险。围墙本身,就由 Jinja2 和 skill 规范共同筑成。
下次考虑让 AI 介入验证环境构建时,不妨先想清楚这三件事:初始化框架是否用模板固化好了?后续留给 AI 的操作空间是否已经被 skill 限定清楚?最终呈现给使用者的,到底是“生成一个环境”,还是“在一个坚固的环境里不断填东西”?想清楚这些区别,才是 AI 时代验证工程真正的成熟。
