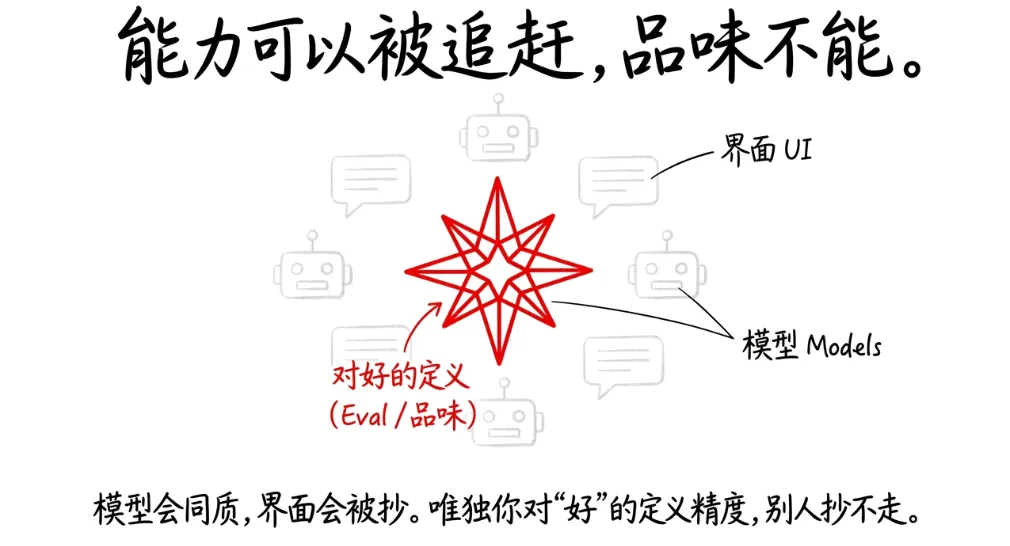
最近看了一个访谈,Anthropic 的产品负责人 Kat Wu 说了一句话,让我停了很久。她说:我们内部判断一个 AI 功能做得好不好,不是看用户反馈,不是看DAU,而是看 eval 通过率。Eval,就是评测集。一组预先定义好的测试用例,用来衡量模型在特定任务上的表现。听起来很技术对不对?但我越想越觉得,这可能是当下 AI 行业最被低估的一个认知:大多数团队都在卷模型能力,但真正决定产品好不好的,不是模型强不强,是你有没有能力定义"什么叫好"。能定义好,就能迭代。不能定义好,就只能靠感觉。靠感觉做产品,在传统软件时代还能混,在 AI 时代会死得很快。
为什么 AI 产品特别需要 Eval
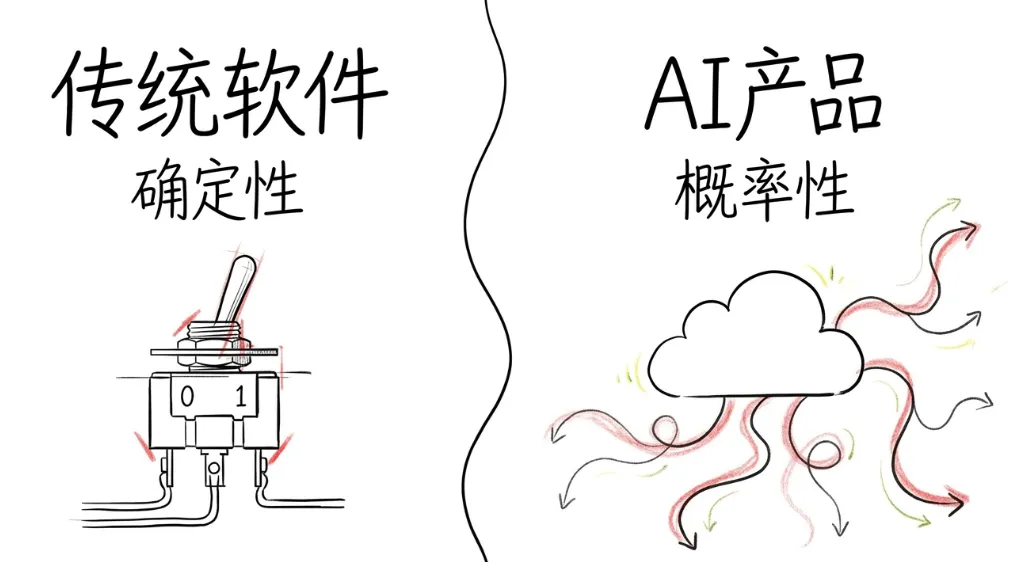
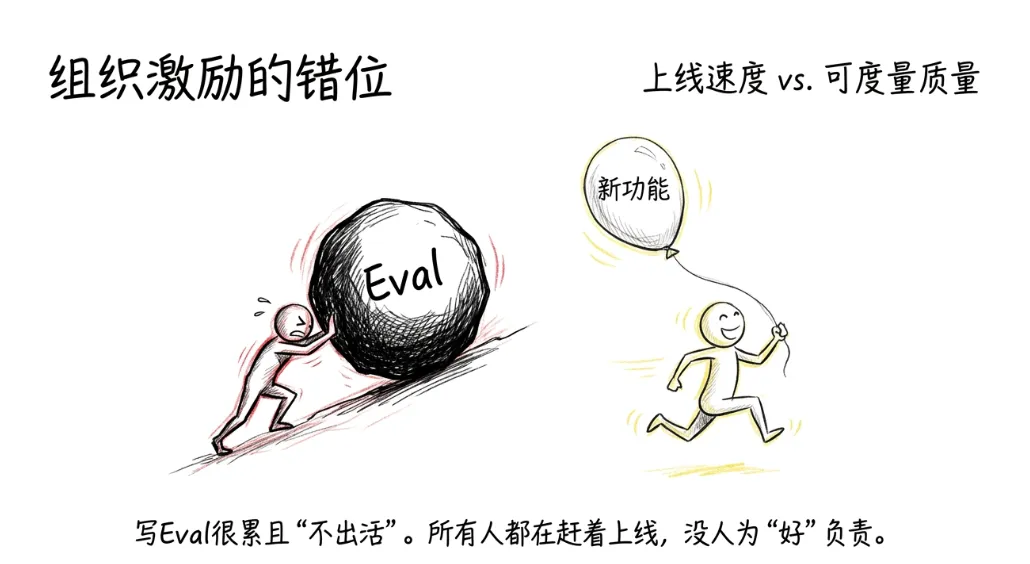
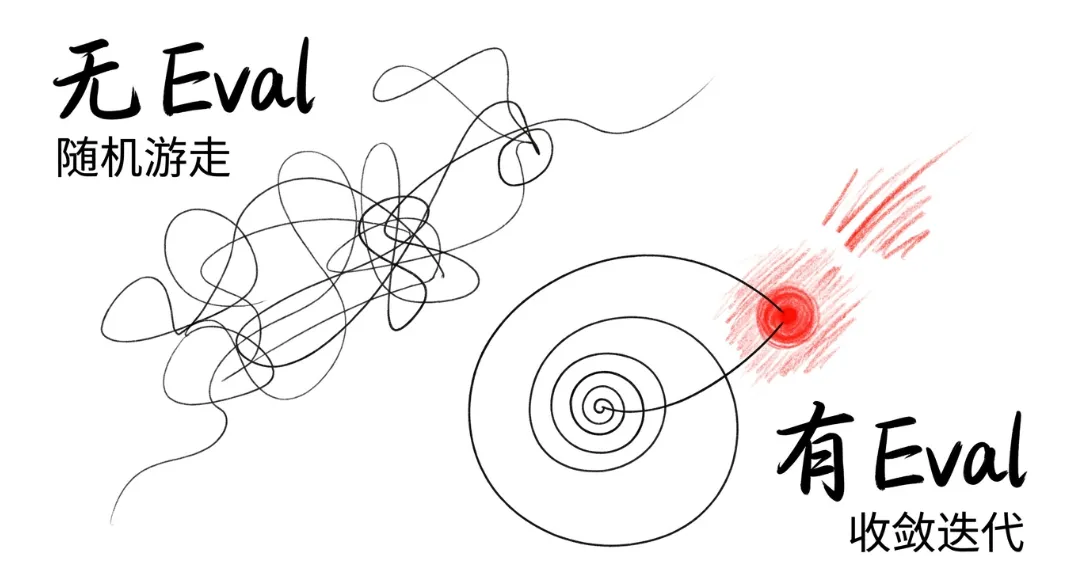
先说一个很多做 AI 产品的人都遇到过、但很少被正式讨论的问题。传统软件的质量判断是确定性的。一个按钮点下去,要么跳转了,要么没跳转。一个接口调用,要么返回正确结果,要么报错。对错分明,测试用例写起来很直觉。但 AI 产品不一样。你让模型写一段摘要,它给你三个版本,哪个算"好"?你让模型做一个推荐,它推了五个结果,哪个算"对"?你让模型回答一个客服问题,它说的话语气太硬还是太软,标准在哪?AI 产品的输出是概率性的、模糊的、非确定性的。这意味着传统的 QA 方法论在这里几乎失效。你没有办法用"通过/不通过"这种二元判断来覆盖所有场景。那怎么办?Anthropic 的做法是:在动手写任何功能之前,先写 eval。先定义"在这个场景下,什么样的输出算好",把它变成一组可以自动跑的测试用例。然后所有的迭代、调优、上线决策,都围绕这组 eval 的通过率来做。这听起来像常识,但现实是绝大多数 AI 团队都没在做这件事。他们做的是什么呢?上线一个功能,自己试几下觉得"还行",就推出去了。用户反馈不好,就改改 prompt。改完再试几下,觉得"好像好了",再推一版。整个过程没有基准线,没有回归测试,没有量化标准。每一次迭代都是盲人摸象。
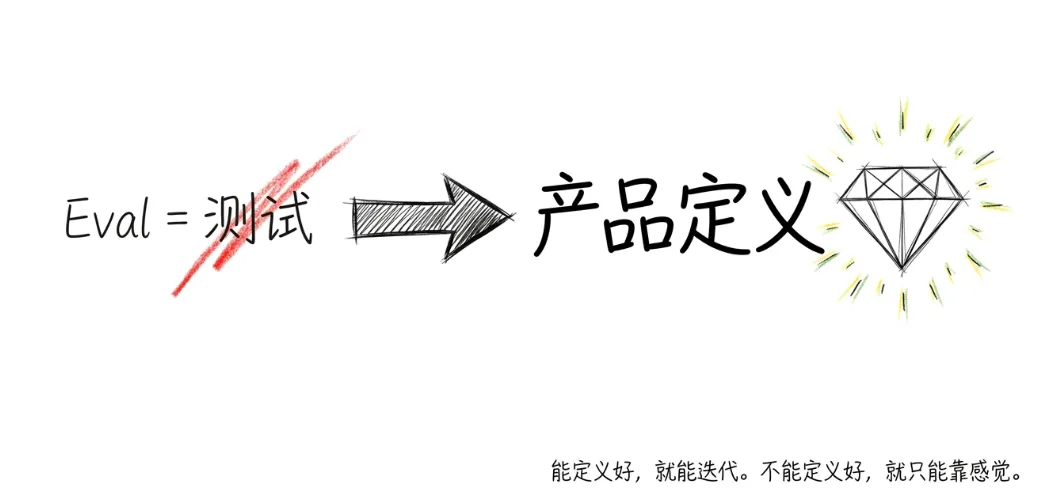
Eval 的本质不是测试,是产品定义
很多人一听"评测集",第一反应是这是工程师的事,是测试团队的事。错了。在 AI 产品里,写 eval 本质上是在做产品定义。因为当你坐下来写一条测试用例的时候,你必须回答这些问题:这个功能到底要解决什么问题?用户在什么场景下会用它?什么样的输出对用户有价值?什么样的输出是不可接受的?在多个"还行"的输出之间,我们按什么标准排优先级?这些问题,每一个都是产品问题,不是技术问题。Kat Wu 在访谈里说了一个很有意思的细节:Anthropic 内部,PM 写 eval 的时间比写 PRD 的时间还多。因为在 AI 产品里,PRD 那种"用户可以做 X,系统应该返回 Y"的描述方式太粗糙了。你必须用具体的 case 来定义什么是好。举个例子。假设你在做一个 AI 客服产品,用户问"我的订单什么时候到"。传统 PRD 会写:系统应返回预计送达时间。但 eval 需要你定义得更细:如果物流信息正常,回复预计时间加当前状态,语气要确定。 如果物流信息延迟,回复预计时间的同时主动致歉,并给出补偿选项。如果物流信息缺失,不能编造时间,应该告知用户正在查询并提供人工转接。每一种情况都是一条测试用例。每一条测试用例背后都是一个产品判断。所以 eval 不是在"测产品",而是在"定义产品"。你的 eval 写得越精确,你的产品定义就越清晰。这也是为什么 Kat Wu 说"eval 是 AI 产品的真正产品力"。不是因为它是质量保障手段,而是因为它反映了一个团队对"好"的定义精度。
 夜雨聆风
夜雨聆风