 夜雨聆风
夜雨聆风AI干货持续更新中!🌟 收藏防丢失🌟 点击关注↑解锁更多AI思考&前沿应用
观点:AI 工具爆发期,最大的陷阱是"看起来都能用"——但能用 ≠ 该用。选工具前先算清楚账,看清产品本质,再动手也不迟。
最近在团队内部分享 AI 工具的时候发现一件事:大家不是不知道 AI 厉害,而是被铺天盖地的产品搞得有点麻木了。
每周都有新模型、新 agent冒出来,光是看名字就要消耗半小时。所以我花了点时间,把目前主流的 AI 产品做了个分类,再聊聊该怎么选、什么场景配什么工具。
一、先把市面上的 AI 产品做个分类
我把见过用过的产品大致归到了这几类:
- Chatbot
:Claude、ChatGPT、Gemini、Grok、DeepSeek、Kimi、千问、豆包、灵光 - 通用 Agent
:Manus、OpenClaw、Hermers、扣子空间、WorkBuddy、JWSClaw - 编程 Agent
:Claude Code、Codex、CodeBuddy、Trae - 设计 Agent
:Calicat、GenDesign、Claude Design、Lovart - 工作流产品
:Dify、Coze - 视频类
:即梦、可灵、剪映 - 知识库
:NotebookLM、IMA、飞书知识库、企微文档、Obsidian

二、这些产品本质上是四种东西
分类太细其实没意义,往上抽一层会清楚很多。我自己是这么理解的:
1. AI 对话产品(Chatbot)
底层加载不同的大模型,你问它答。会话之间是隔离的,不能操作真实系统,结果你得手动搬运。
打个比方:它是你智囊团里那个特别聪明的人,但没有手——能给你出主意,没法替你干活。
2. AI Agent
你给一句自然语言指令,它自己拆任务、规划步骤、调技能包,最后交付结果。能自主规划、记上下文、调外部系统、定时跑任务。
还是上面那个比喻:这次给那个聪明人装上了手脚,他能自己干活了。
3. 工作流
适合那些 SOP 比较标准、对结果稳定性有要求的业务。换句话说——你不希望它"发挥",你希望它每次都按规矩来。工作流产品(Dify、Coze)就是干这个的。
4. 知识库
通常不单用,是搭配前面三类用的。比如把公司章程、内部产品方案塞进去,让 AI 调用的时候有"自己人"的资料垫底。

三、从业务角度怎么选?
我自己常用的判断方法叫"三问扫描法",问三个问题:
- 重复发生
:这事我做了多少次?超过 3 次以上,就值得想想能不能自动化。 - 有规律可循
:有没有固定套路?输入格式固定吗?处理步骤固定吗? - 业务价值驱动
:自动化能省多少?时间 × 频率 = 真实价值。先算账,再动手。
很多人栽就栽在第三步——花两周做一个每月只用一次的工具,省下来的时间还不够开发的零头。
几个我自己遇到过的场景:
再具体到我们的几个真实场景:
场景 1:给新银行客户生成定制化方案报告
痛点:每次 DA 拜访前要手工写 30+ 页方案,结构类似但数据策略每次都得定制,耗时 1-2 天。
做法:建立银行画像模板(规模/区域/贷款产品)→ AI 自动匹配历史案例 → 生成初稿 → 售前DA 30 分钟微调。
工具:OpenClaw / WorkBuddy + 企业知识库(历史方案、产品手册)。
预计效果:方案生成时间从 2 天 → 2 小时,商务人员可以专注客户关系而不是文档。
场景 2:监控合作银行的舆情动态
痛点:合作银行如果出现负面舆情或政策变化,业务节奏就要相应调整。但靠人工刷新闻很容易漏。
做法:每天自动抓取目标银行 + 监管政策的新闻 → AI 分析风险级别 → 定期推送到企微,重要的即时通知。
工具:OpenClaw + 搜索技能包 + 企微通知。
预计效果:信息覆盖率从 20% → 90%+,重要变化的响应时间从天级到小时级。
场景 3:新员工/销售快速查客户/产品知识
痛点:银行产品线复杂,新销售经常问"这个功能支持吗""这个银行用的是哪个模块",占用产品同学大量时间。
做法:把产品手册、FAQ、历史服务记录灌进知识库 → 搭一个企微内的问答机器人 → 支持自然语言查询。
工具:扣子 Coze / Dify + 企业知识库 + 企微机器人。
预计效果:80%+ 重复性问题可自动回复,产品团队释放约 1 人/天的沟通成本。
场景 4:自动生成银行客户的运营周报
痛点:每周从后台导数据、汇总成各银行的周报发给客户,光数据搬运就 3-4 小时。
做法:Agent 定时拉系统数据 → 按模板生成 Word/PPT 报告 → 自动发到对应客户邮箱/企微。
工具:OpenClaw + 数据读取 + 文档生成 + 邮件/企微发送(其实工作流也行)。
预计效果:每周报告从手动 4 小时 → 全自动,而且不会出现搬运错误。
四、从工程化角度再看一遍
业务角度看完,还得再换一个视角:从工程化角度。
Agent 本质上有两个变量:控制任务走向的"工作流"workflow,和影响输出的"上下文"context。这两个东西的确定性高低,决定了你该选什么工具。
这里说的"确定"是指:流程步骤是不是固定的、输入是不是结构化的。
判断自己在哪个象限,问两个问题就够了:
- 同一类任务,每次的输入格式都一样吗?
(决定上下文确定性) - 同一类任务,每次的处理步骤都一样吗?
(决定工作流确定性)
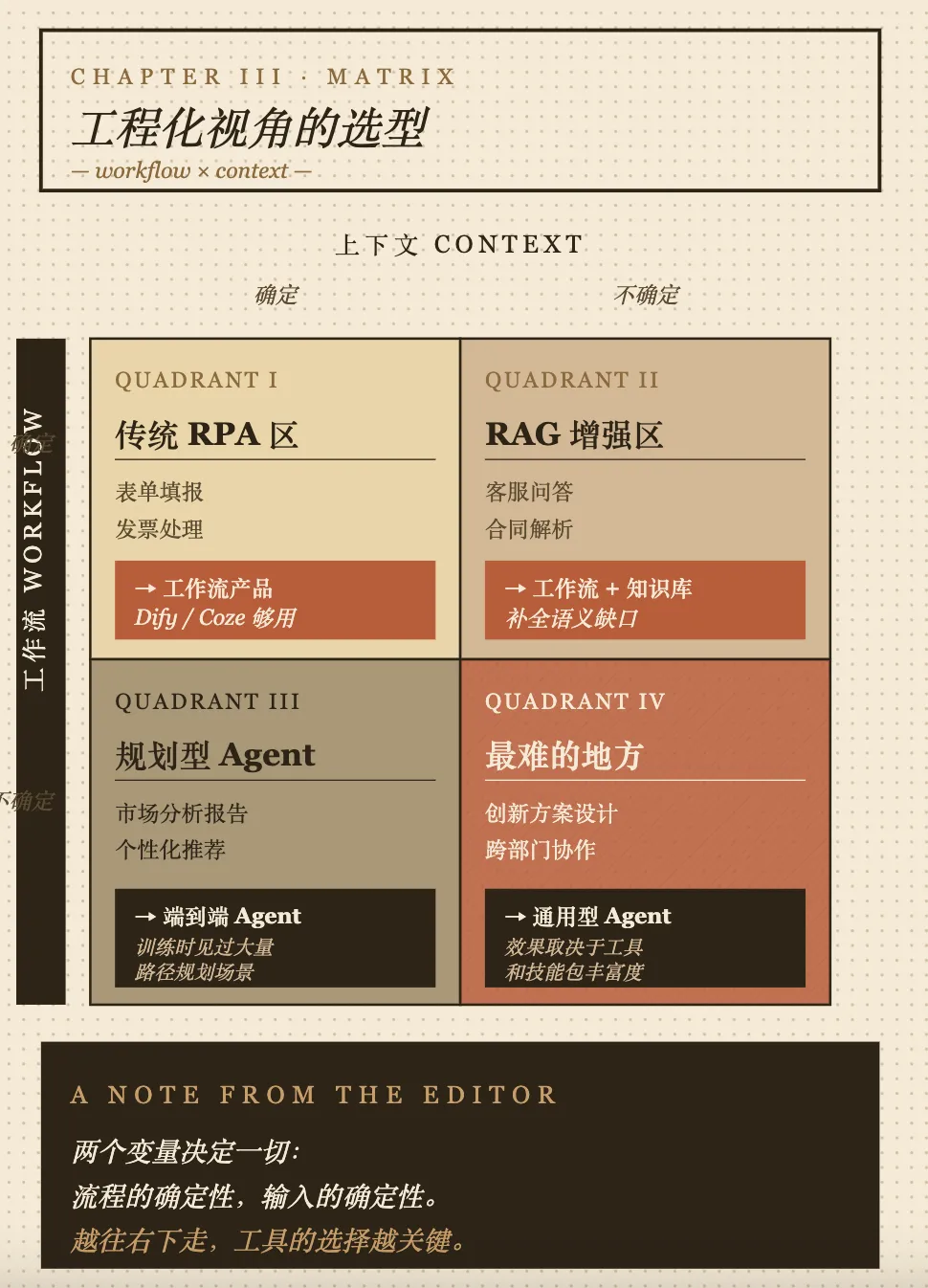
象限 1:工作流确定 + 上下文确定
典型场景:从 ERP 导出销售数据 → 按规则汇总 → 写入报表系统。
输入是结构化的,步骤是固定的。这种活其实不需要 LLM,传统脚本或 RPA(影刀、UiPath)就够了。LLM 加进来反而是杀鸡用牛刀。
→ 选型:传统 RPA / Python 脚本
⚠️反例提醒:别因为"现在是 AI 时代"就硬塞 LLM 进来,纯粹增加成本和不稳定性。
象限 2:工作流确定 + 上下文不确定
典型场景:发票处理、客服问答、固定模板的报告生成。
流程是固定的,但输入是非结构化的(PDF、扫描件、自然语言)。这时候 LLM 是"理解器"——把乱七八糟的输入变成结构化的东西,再走固定流程。
→ 选型:工作流产品(Dify、Coze、扣子)+ RAG/知识库
这是 Dify/Coze 最擅长的领域,也是企业落地 AI性价比最高的地方。
象限 3:工作流不确定 + 上下文确定
典型场景:市场分析报告、代码审查、深度研究、个性化推荐。
输入是清楚的(一个明确的研究问题、一段代码、一个用户画像),但解题路径每次都不一样。这种活需要 Agent 自主规划。
→ 选型:垂类 Agent
研究/分析类:Claude / ChatGPT 的 Deep Research、Manus 编程类:Claude Code、Codex、Cursor 设计类:Lovart、GenDesign
⚠️反例提醒:别用工作流硬套——你写不出能覆盖所有路径的流程图,最后会变成 if-else 嵌套地狱。
象限 4:工作流不确定 + 上下文不确定
典型场景:跨部门信息收集、创新方案设计、复杂调研。
既不知道路径,也不知道输入边界。要边推理边探索,还要调一堆外部工具。
→ 选型:通用型 Agent + 自建技能包
通用 Agent:Manus、OpenClaw、扣子空间、WorkBuddy 关键不在选哪个 Agent,而在给它配什么 MCP / 技能包 / 知识库
这个象限的事,Agent 选型只占 20%,剩下 80% 是上下文工程和工具配置。这事没有捷径,也没有"开箱即用"。
⚠️反例提醒:别指望买个通用 Agent 就解决问题,没有配套的技能包和知识库,它就是个加强版 Chatbot。
五、有了多个方案,怎么选?
很多时候同一件事不止一个解法。我自己的做法是过四个维度:
维度 1:实现难度
你团队(或你自己)能在合理时间内做出来吗?依赖的外部资源容易拿吗?——别低估这个,"我下周就能搞定"的话术听过太多次了。
维度 2:投入产出比
省下来的时间/成本 vs 开发+维护成本。算具体数字,别凭感觉说"值"。凭感觉做的项目,最后大多变成 KPI 装饰品。
维度 3:可维护性
上线后谁来管?出问题能不能快速定位?做完没人维护的工具,最后都会变成"僵尸工具"——挂着 logo,没人敢用。
维度 4:风险与依赖
依赖第三方服务吗?关键节点挂了有没有手动 fallback?这一点平时想不到,出事的时候要命。

最后说一句:AI 工具的爆发期,最大的陷阱是"看起来都能用"。但能用 ≠ 该用。先想清楚自己的业务结构、流程确定性、维护成本,再去挑工具,效率比追新高得多。
仅代表个人观点,欢迎拍砖。
