 夜雨聆风
夜雨聆风在当今企业数字化转型的大潮中,数据已经成为了最重要的资产之一。然而,数据 ≠ 价值。如何从海量数据中快速获取业务洞察,如何让非技术用户也能轻松进行数据分析,始终是企业数据团队面临的巨大挑战。
RuoYi-AI+metricbot,正是一站式解决这些痛点的企业级 AI 助手平台。它不仅在传统若依框架上集成了 AI 能力,更构建了一套完整的指标语义层 + ChatBI + 流程编排体系,让数据真正"说话"。
本文将从四个方面深度剖析 RuoYi-AI-MetricBot 的数据智能能力:
指标体系(Metrics) 数据集语义(Dataset Semantics) ChatBI(对话式商业智能) 指标归因分析
最后附上源码启动教程,带你从零跑起整个项目。
一、指标体系:让业务语言统一
1.1 什么是指标?
指标(Metric)是对业务现象的量化描述,它是连接业务世界和数据世界的桥梁。比如:
- 日活跃用户(DAU)
— 产品健康度的核心指标 - 客单价
— 衡量每单交易价值的指标 - 净利润率
— 企业经营效率的关键指标
在传统的数据分析中,指标散落在各个 SQL 查询和报表中,同名不同义、同义不同名的现象比比皆是。RuoYi-AI 通过指标语义层来解决这个问题。
1.2 RuoYi-AI-MetricBot 的指标模型
RuoYi-AI-MetricBot 的指标以 metric_info 表为核心,包含以下关键字段:
metric_cn_name | ||
metric_name | ||
level | ||
type | ||
business_caliber | ||
caliber | sum(total_amount) | |
table_name | ||
relate_metric |
1.3 原子指标 vs 派生指标
指标体系的核心在于分层设计:
- 原子指标(atom)
:从数据源直接计算的不可再分指标,如 sum(total_amount)、count(distinct user_id) - 派生指标(custom)
:基于原子指标通过四则运算组合而成,如 均次费 = [总金额] / [就诊人次]
这种分层设计让指标体系具备极强的可维护性和可扩展性。当底层的原子指标口径调整时,上层所有派生指标自动生效。
1.4 指标管理的可视化
RuoYi-AI 的管理后台提供了完整的指标 CRUD 界面,支持按主题分组管理、指标状态控制(启用/停用),以及指标的导入导出功能。用户可以在界面中清晰地查看和维护整个指标体系。
二、数据集语义:连接指标与物理数据
2.1 语义层的作用
数据集语义层是介于业务指标和物理数据表之间的中间层。它的核心作用是:
- 屏蔽物理表的复杂性
:业务用户不需要知道数据存在哪张表、用什么 join、字段名是什么 - 提供统一的语义视图
:将物理表映射为业务概念(数据集),每个数据集包含若干维度 - 实现指标的可复用性
:一个指标定义好后,可以在任何查询、任何仪表盘中复用
2.2 RuoYi-AI-MetricBot 的数据集模型
数据集以 dataset_info 表为核心:
name | ||
datasource | ||
dimensions | ||
metric_sql | select stat_date, experiment_group, ... from da_redbook_behavior_day | |
dimension_sql | ||
date_column |
2.3 语义层的执行流程
当用户发起一个查询(如"近 30 天各渠道的订单金额趋势")时,语义层的工作流程如下:
用户问题 ↓LLM 语义匹配 → 选出相关指标和维度 ↓数据集过滤 → 匹配指标关联的数据集和可用维度 ↓DQL 解析 → 生成分析查询 DSL ↓SQL 生成 → AnalyticSqlGenerator 生成可执行 SQL ↓数据执行 → 连接数据源,执行查询,返回结果 ↓结果格式化 → 格式化为表格或图表2.4 关键组件:AnalyticSqlGenerator
这个核心解析器基于阿里巴巴 Druid SQL AST 解析器构建,能够:
接收 DQL(类 SQL 的分析查询语言)描述 根据指标定义验证度量合法性和维度匹配性 自动处理多表关联( table_ref字段配置)在多个层级(dw/dm/da)的候选表中选择最优的查询路径 生成最终的、可执行的 SQL 语句
例如,一个 ROE(净资产收益率)指标的计算口径为 [ROA]*[权益乘数],解析器会自动展开为多层子查询,最终生成完整的 SQL。
三、ChatBI:对话式商业智能
3.1 什么是 ChatBI?
ChatBI = Chat + Business Intelligence,即通过自然语言对话的方式来进行数据分析。用户不需要掌握 SQL,不需要了解数据库表结构,只需要用中文描述问题,系统就能自动完成:
理解意图 → 2. 匹配指标 → 3. 生成 SQL → 4. 查询执行 → 5. 结果呈现
3.2 RuoYi-AI-MetricBot 的 ChatBI 架构
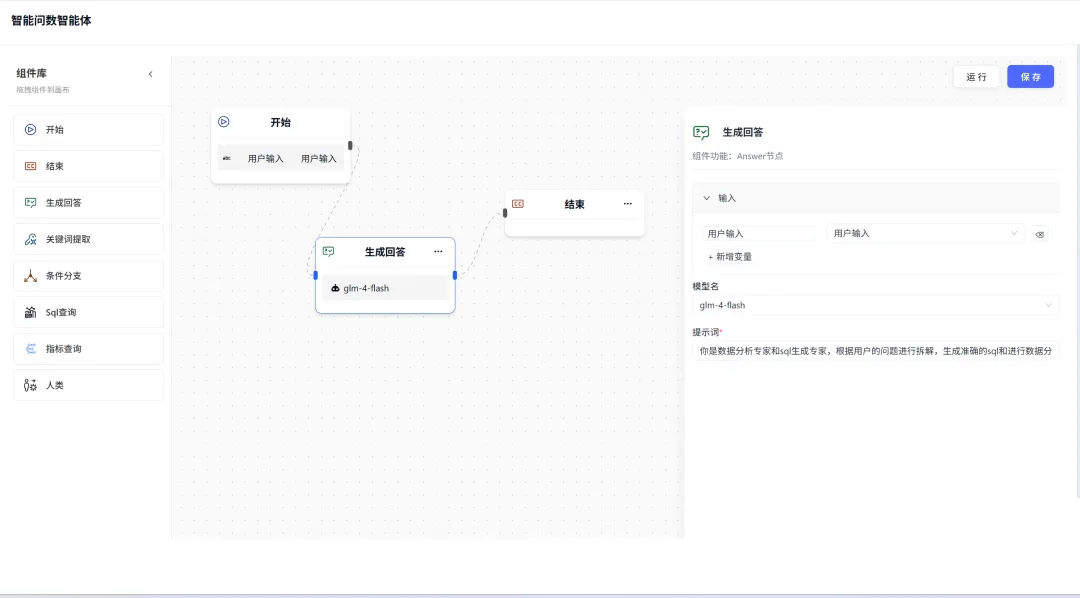
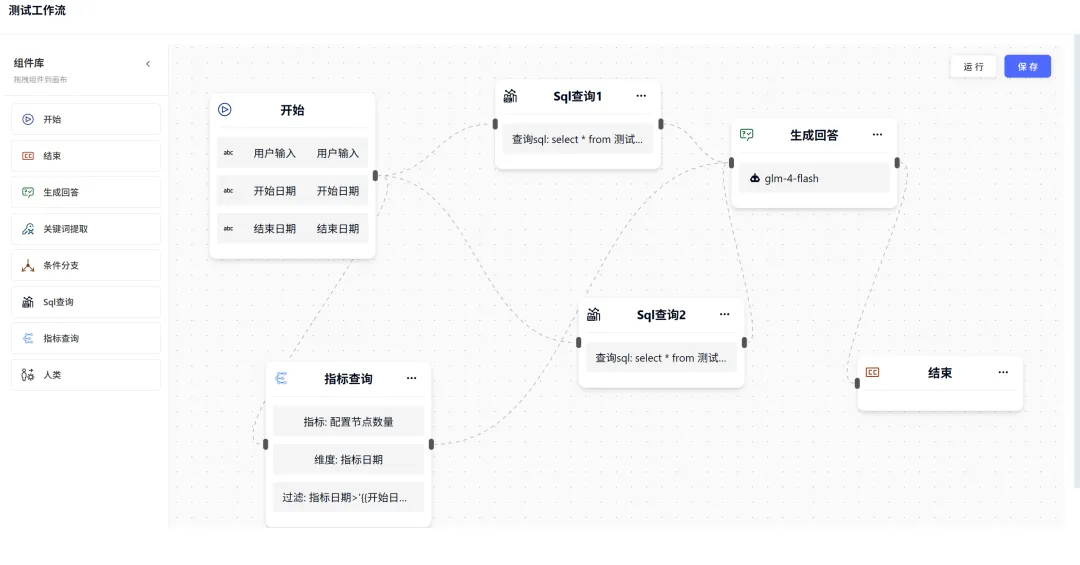
RuoYi-AI 的 ChatBI 能力融入在AI Flow 工作流引擎中,包含多个核心组件:
SqlAgent(智能数据库代理) 基于 Langchain4j 构建,具备以下能力:
自动查询数据库的所有表和表结构 理解用户自然语言问题 调用 executeSql工具生成并执行 SQL返回格式化的分析结果
MetricQueryService(指标查询服务) 这是 ChatBI 的中枢模块,执行完整的指标查询流程:
从数据库中加载所有指标定义 使用 LLM 对用户问题进行语义匹配,选出相关指标 根据数据集维度信息进行维度过滤 再次使用 LLM 推荐分析维度 返回结构化的指标元数据和推荐维度
MultiAgentEngine(多智能体引擎) 支持 Supervisor 模式的智能体编排,将复杂的分析任务分解为子任务:
TaskDecomposer 负责任务分解 多个 Agent 并行执行子分析任务 汇总结果生成综合分析报告
3.3 ChatBI 的交互方式
RuoYi-AI 提供了两种 ChatBI 交互方式:
- 对话式 Chat 界面
:用户直接在聊天界面提问,AI 实时生成答案,支持 SSE 流式输出 - AI Flow 工作流
:通过可视化拖拽编排分析流程,支持 MetricQuery 节点、SQL 查询节点、LLM Answer 节点等组合
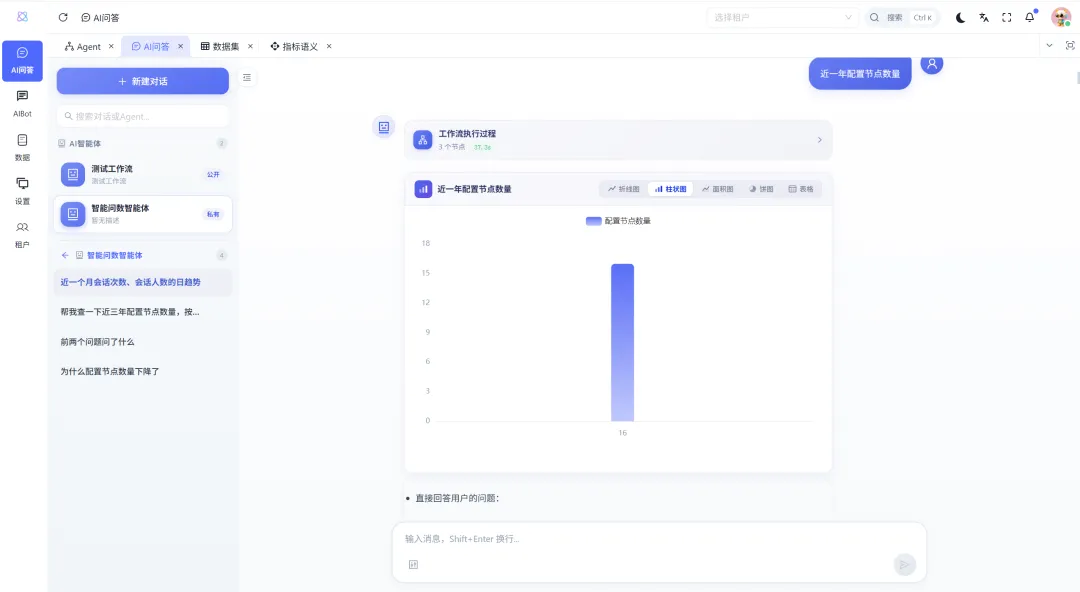
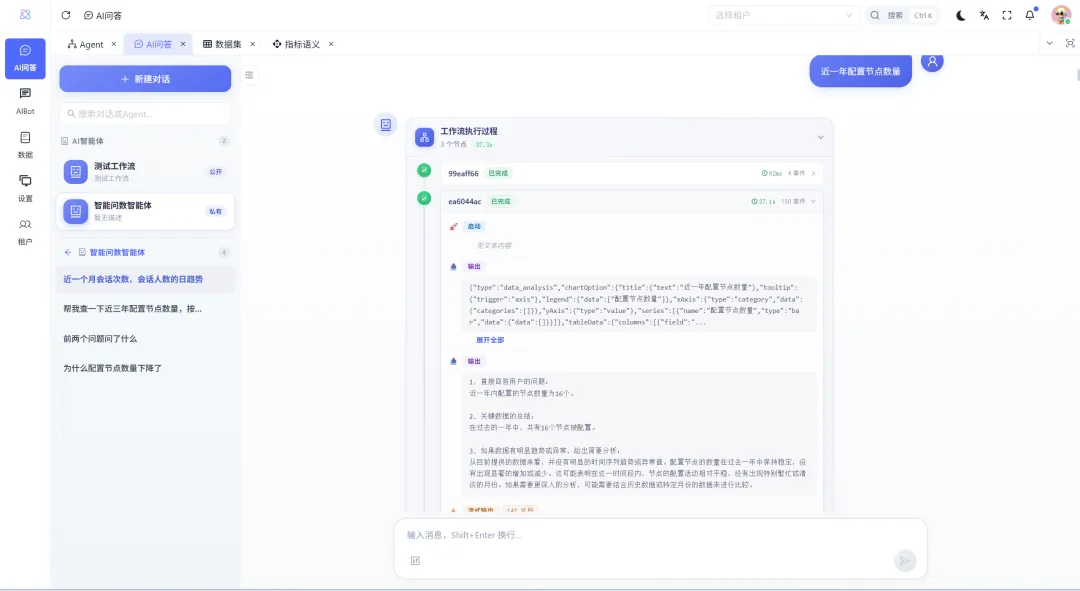
3.4 实际场景示例
用户提问:"最近 30 天首页曝光人数的趋势怎么样,按实验组别分组"
系统执行流程:
LLM 匹配指标 → 选出"首页曝光人数" 匹配数据集 → 找到"小红书行为天数据集" 维度推荐 → 推荐"指标日期"和"实验组别名称" 生成 DQL → {metrics: ["首页曝光人数"], dimensions: ["指标日期", "实验组别名称"], ...}解析生成 SQL → SELECT stat_date, experiment_group, SUM(home_exposure_users) ...执行查询 → 连接数据源获取数据 可视化呈现 → 展示为折线图或表格
四、指标归因分析:从"是什么"到"为什么"
4.1 归因分析的价值
常规的数据分析回答的是**"是什么"——指标涨了还是跌了。而归因分析要回答的是"为什么"**——什么因素导致了指标的变化。
4.2 RuoYi-AI-MetricBot 的归因分析设计
RuoYi-AI-MetricBot 通过 relate_metric(指标拆解)字段来实现归因分析的能力。核心体现在两个方面:
1. 指标拆解关系定义
派生指标通过 relate_metric 记录其依赖的原子指标:
ROE → ROA, 权益乘数ROA → 销售净利率, 资产周转率销售净利率 → 净利润, 销售收入净利润 → 销售收入, 全部成本, 其他利润, 所得税全部成本 → 销售成本, 销售费用, 管理费用, 财务费用这就构成了一棵指标拆解树,从顶层指标可以一路下钻到最底层的原子指标。
2. 杜邦分析模型
RuoYi-AI 内置了完整的杜邦分析指标链(某医药公司的财务域案例):
ROE / \ ROA 权益乘数 / \ 销售净利率 资产周转率 / \ / \ 净利润 销售收入 销售收入 总资产 / | \ / / \ 收入 全部成本 其他利润 所得税 流动资产 非流动资产 / | \ \ / | | \ 成本 费用 管理 财务 现金 应收 存货 其他这种链式结构让用户可以逐层下钻,定位指标变动的根因。
4.3 归因分析在 ChatBI 中的应用
当用户分析一个派生指标时,系统能够:
- 自动展开
:将派生指标展开为底层原子指标 - 同步查询
:一次性查询所有相关指标的数据 - 对比分析
:计算各因子对顶层指标变化的贡献度 - 智能解读
:用自然语言描述变化原因
例如,查询"净利润率下降的原因",系统会查询净利润、销售收入等底层指标,对比不同期间的变化,给出类似以下的结论:
"净利润下降的主要原因是销售成本增长 15% 和财务费用增长 8%,虽然销售收入增长了 5%,但成本增速超过收入增速导致净利润率下降 2.3 个百分点。"
五、源码启动教程
5.1 项目结构
ruoyi-ai/ # Java 后端(Spring Boot 3 + Langchain4j)├── ruoyi-admin # 启动入口,端口 6039├── ruoyi-modules/│ ├── ruoyi-chat # AI 聊天 + Agent 智能体│ ├── ruoyi-aiflow # AI Flow 工作流引擎│ └── ruoyi-data-asset # 数据资产管理(指标+数据集+数据源)├── ruoyi-common/│ └── ruoyi-common-parser # SQL/指标解析器ruoyi-ui/ # 管理后台前端(Vue 3 + Vben Admin 5)apps/web-antd/src/views/├── chat/ # 聊天界面├── aiflow/ # 工作流设计器├── data-asset/ # 数据资产管理└── ...5.2 方式一:Docker 一键启动(推荐)
最简单的方式,无需安装 JDK、Node.js 等开发环境:
git clone https://github.com/ageerle/ruoyi-ai.gitcd ruoyi-ai# 一键启动所有服务docker-compose -f docs/docker/ruoyi-ai/docker-compose-all.yaml up -d启动成功后访问:
管理后台:http://localhost:25666(账号:admin / admin123) 后端 API:http://localhost:26039
5.3 方式二:源码编译启动
后端启动
前置条件:JDK 21、Maven 3.6+、MySQL 8.0、Redis
# 1. 修改配置文件 ruoyi-admin/src/main/resources/application-dev.yml# 配置 MySQL 连接(默认 127.0.0.1:3306/ruoyi_ai)# 配置 Redis 连接(默认 127.0.0.1:6379)# 页面配置 AI 模型 API Key(如 DeepSeek)# 使用DBeaver导入数据库文件 # 2. 编译打包mvn clean install -DskipTests# 3. 启动服务# 运行 RuoYiAIApplication.java(位于 ruoyi-admin 模块)# 或使用 Maven 插件:cd ruoyi-adminmvn spring-boot:run -Dspring-boot.run.profiles=dev后端端口:启动后服务运行在 http://localhost:6039
管理后台前端启动
前置条件:Node.js 18+、pnpm
# 1. 安装依赖pnpm install# 3. 配置后端地址# 修改 apps/web-antd/.env.development 中的 VITE_GLOB_API_URLVITE_GLOB_API_URL=http://localhost:6039# 4. 启动开发服务器pnpm dev:antd前端端口:启动后访问 http://localhost:5666
5.4 核心配置说明
在启动前,需要修改 application-dev.yml 中的配置:
# 数据源配置spring:datasource:url:jdbc:mysql://127.0.0.1:3306/ry-ai?useUnicode=true&characterEncoding=utf8username:rootpassword:your_password# Redis 配置redis:host:127.0.0.1port:6379# AI 模型配置(以 DeepSeek 为例)langchain4j:chat-model:api-key:sk-your-api-keymodel-name:deepseek-chaturl:https://api.deepseek.com/v1数据库初始化脚本位于 ruoyi-ai/sql/ 目录下,首次运行需要先执行建表脚本。
5.5 启动步骤总结
总结
RuoYi-AI 通过指标语义层实现了业务语言的统一,通过数据集语义屏蔽了底层数据的复杂性,通过ChatBI让非技术用户也能自助分析,通过指标归因分析让用户不仅知道"是什么",更理解"为什么"。
这套完整的数据智能体系,让企业可以在开源的基础上,快速构建属于自己的 AI 驱动的数据分析平台。
如果你觉得本文有帮助,欢迎点赞、在看、转发三连,让更多人看到开源的力量!
