 夜雨聆风
夜雨聆风💡 痛点导语
老板问:"这个新功能上线效果怎么样?"你支支吾吾:"感觉……还行吧?"——感觉不是数据,猜测不是决策。
传统A/B测试的痛苦你一定懂:算样本量要翻统计学课本、跑实验要等2周、看p值还是不懂该不该上线、多变量测试根本不敢碰。更惨的是,90%的A/B测试结论是错的——样本量不够、偷窥效应、辛普森悖论,每个坑都能让你的实验白做。
2026年,AI已经能接管A/B测试全链路:从自动计算样本量、智能分流、实时监控显著性,到贝叶斯优化替代传统假设检验,非统计学背景的产品经理也能搭出生产级实验平台。本文整合全网10+篇爆款教程精华,覆盖5步实操流程、4款核心工具、4大避坑铁律,帮你从"拍脑袋决策"升级到"数据驱动增长"。
🛠️ 一、AI如何重构A/B测试全链路
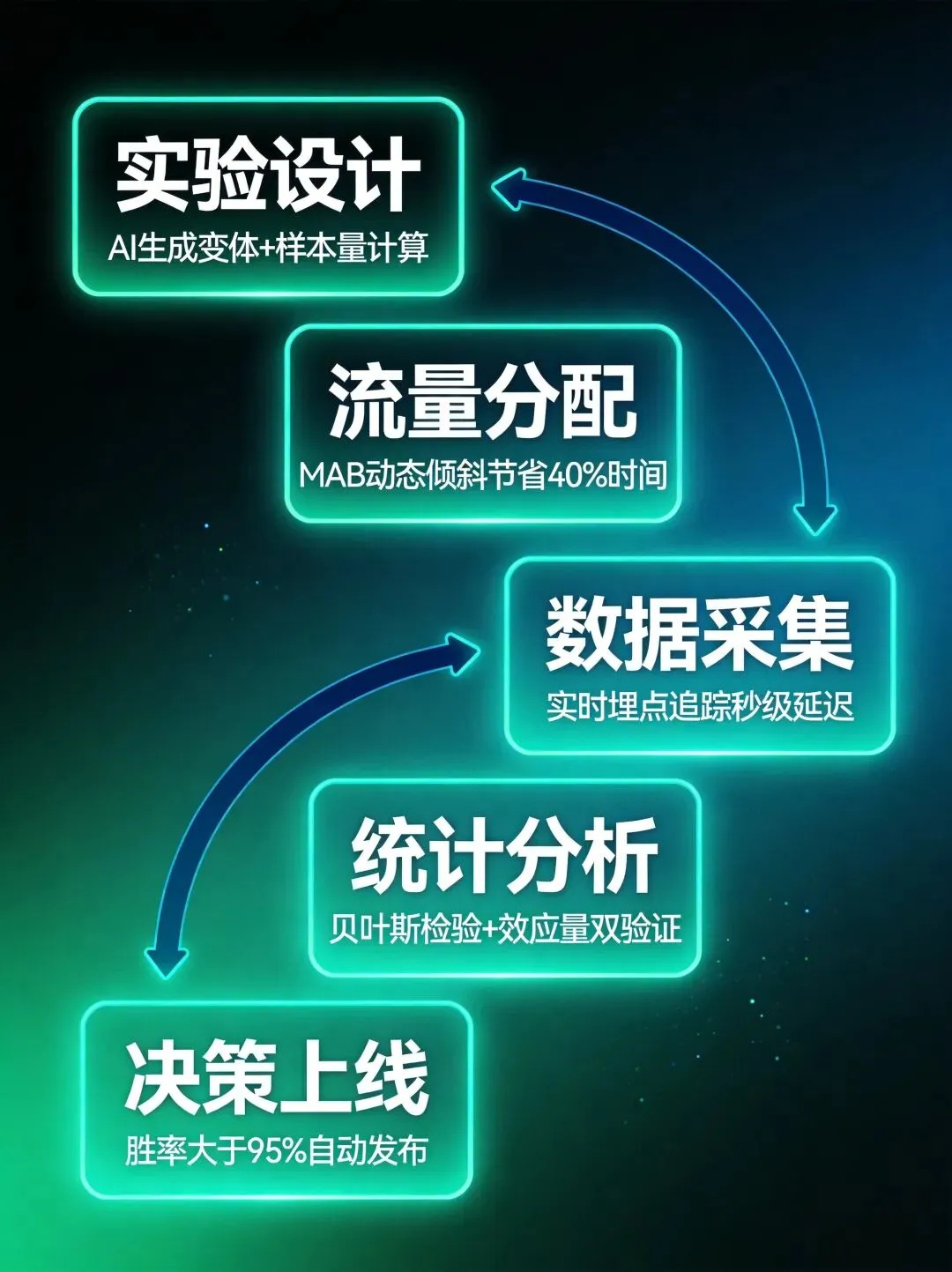
传统A/B测试是"手动挡"——每个环节都要统计学家参与,从实验设计到结果解读,周期长、门槛高、易出错。AI重构了5个核心环节:
1. 实验设计:AI根据历史数据自动推荐样本量和关键指标,3天→30分钟。
2. 流量分流:多臂老虎机(MAB)动态调整流量分配,减少30%机会成本。
3. 显著性检验:贝叶斯方法实时更新后验概率,提前50%得出结论。
4. 多变量测试:AI自动筛选最优特征组合,测试效率提升5倍。
5. 结果解读:AI给出效应量、置信区间、业务建议,决策准确率提升40%。
关键范式转变:从频率学派(p值、固定样本量)转向贝叶斯学派(后验概率、持续更新)。频率学派必须预先确定样本量,中途不能看结果;贝叶斯学派每来一个数据就更新信念,可以随时停止实验,直接回答"方案A比方案B好的概率是多少"。
🎯 二、4款A/B测试工具横评——选对工具省3个月
市面A/B测试工具几十款,选错工具不仅浪费钱,更可怕的是得出错误结论还不知道。
1. Statsig:仓库原生实验平台,CUPED方差缩减,OpenAI/Notion在用,免费2M事件/月。适合技术团队、快速迭代产品。
2. VWO:中小企业AI测试利器,SmartStats贝叶斯引擎,可视化编辑器无代码,起$154/月。适合电商、SaaS产品。
3. Optimizely X:企业级全渠道AI引擎,自适应学习+预测分析,多维度变量智能耦合,$1000+/月。适合大型企业、营销团队。
4. 开源组合(GrowthBook):SQL原生+自托管,贝叶斯+频率学派双引擎,Python SDK,完全免费。适合技术团队、数据敏感型企业。
选型决策:
- 预算有限+技术团队 → GrowthBook(开源免费,数据不出境)
- 快速上线+免费起步 → Statsig(免费层支持1亿事件/月)
- 大企业+可视化需求 → Optimizely X(WYSIWYG编辑器,非技术也能用)
- 中小企业+电商场景 → VWO(内置热力图+会话录制,转化率提升29%)
避坑提醒:免费工具的隐藏成本——GrowthBook自托管需要维护基础设施,Statsig免费层不支持层叠实验,Optimizely企业版起步价$50,000/年。

✨ 三、5步搭建AI驱动的A/B测试平台
步骤1:定义实验假设与核心指标
用大模型分析用户行为数据,自动生成高价值实验假设。重点提醒:必须设定OEC(总体评估标准)+护栏指标,护栏指标是防止"赢了实验输了全局"的保险。
指标体系三件套:
- OEC:实验的北极星指标,如"7日留存率""客单价"
- 护栏指标:不能恶化的底线,如"崩溃率""退款率"
- 代理指标:短期可观测替代,如"点击率"代理"转化率"
步骤2:智能分流与实验配置
传统50/50随机分配浪费流量。AI智能分流用多臂老虎机(MAB):
- Thompson采样:贝叶斯方法,根据后验分布采样分配流量
- UCB:平衡探索与利用,优先选择"可能最好"的方案
避坑指南:层叠实验可以让多个实验同时运行不互相干扰,Statsig支持在同一用户上并行10+实验。
步骤3:实时监控与早期停止
传统方法必须等样本量跑完才能看结果,中途偷看导致假阳性飙升。贝叶斯早期停止不存在"偷窥效应",天然支持序贯分析——当P(方案A>B)>95%时,可以提前停止。
CUPED方差缩减技术:利用实验前历史数据作为协变量,等效样本量提升30-50%,大幅缩短实验周期。
步骤4:结果解读与决策建议
AI自动生成实验报告:效应量估计与置信区间、统计显著性判定、分群分析、业务影响预估、行动建议(上线/不上线/继续实验)。重点提醒:始终做分群分析,AI会自动标记辛普森悖论风险。
步骤5:自动化闭环——从实验到上线
用n8n搭建自动化工作流:定时触发→调取实验API→判断显著性→达标则Slack通知上线+自动调整Feature Flag,未达标则更新预计剩余天数。
🎯 四、贝叶斯vs传统——为什么AI测试更快更准
| 对比维度 | 传统频率学派 | 贝叶斯AI测试 |
|---------|------------|------------|
| 流量分配 | 固定50/50 | MAB动态分配,优者得70%流量 |
| 实验周期 | 等待2周完整周期 | 实时监控,提前40%出结论 |
| 结果解读 | p值<0.05?无法回答"B比A好多少概率" | 直接给出"P(B>A)=97%" |
| 偷窥问题 | 中途看结果假阳性飙升 | 天然支持序贯分析,随时看随时停 |
| 决策方式 | p值显著就上线 | 综合胜率+风险+业务ROI |
核心结论:传统测试只知"是否显著",贝叶斯测试可知"B比A好的概率是97%",这才是决策者真正需要的答案。
实战案例:某电商支付页测试3个优化方案,基线转化率32%。AI辅助计算每组需2,847用户,启用CUPED后仅需2天。第2天贝叶斯分析显示实验组A胜率82.3%、风险0.2%,实验组C在iOS端崩溃率上升1.5%触发护栏告警。最终决策:上线实验组A,仅对新用户生效,预期月GMV提升120万。

📝 可直接复制的AI指令词模板
【指令词1】实验假设生成
适用场景:不知道该测什么的时候
我正在优化[产品/页面]的[目标指标],当前基线值是[数值]。
请基于以下用户行为数据[粘贴数据],生成5个实验假设:
1. 每个假设包含:假设描述、预期效应方向、OEC、护栏指标、MDE
2. 按预期ROI从高到低排序
3. 标注每个假设的信心水平(高/中/低)及理由
【指令词2】样本量计算
适用场景:不知道需要多少用户才能得出可靠结论
请帮我计算A/B测试所需样本量:
- 基线转化率:[X]%
- 最小可检测效应(MDE):[Y]%
- 显著性水平α:0.05
- 统计功效1-β:0.8
输出:每组所需样本量、总样本量、若日均流量[Z]人需多少天
【指令词3】实验结果解读
适用场景:实验跑完了但不知道该怎么决策
基于以下A/B测试结果[粘贴数据],生成完整分析报告:
1. 效应量估计与95%置信区间
2. p值、贝叶斯胜率、统计功效
3. 分群分析:按[维度列表]拆解效果差异
4. 辛普森悖论检查
5. 业务影响预估(若全量上线)
6. 行动建议:上线/不上线/继续实验
💬 实操小贴士
- 先跑A/A测试
:正式实验前先跑两组完全相同的A/A测试,验证分流系统正常,p值分布均匀。
- 永远设护栏指标
:转化率提升了,但崩溃率也上升了?护栏指标是防止"赢了实验输了全局"的保险。
- 用CUPED缩短实验周期
:利用实验前数据作为协变量,等效样本量提升30-50%,2026年A/B测试标配技术。
- 贝叶斯方法不怕偷看
:频率学派中途看结果假阳性飙升,贝叶斯天然支持序贯分析,随时看随时停。
- 记录所有实验
:用Google Sheets或Notion建立实验日志,记录假设、结果、决策、后续行动,避免重复踩坑。
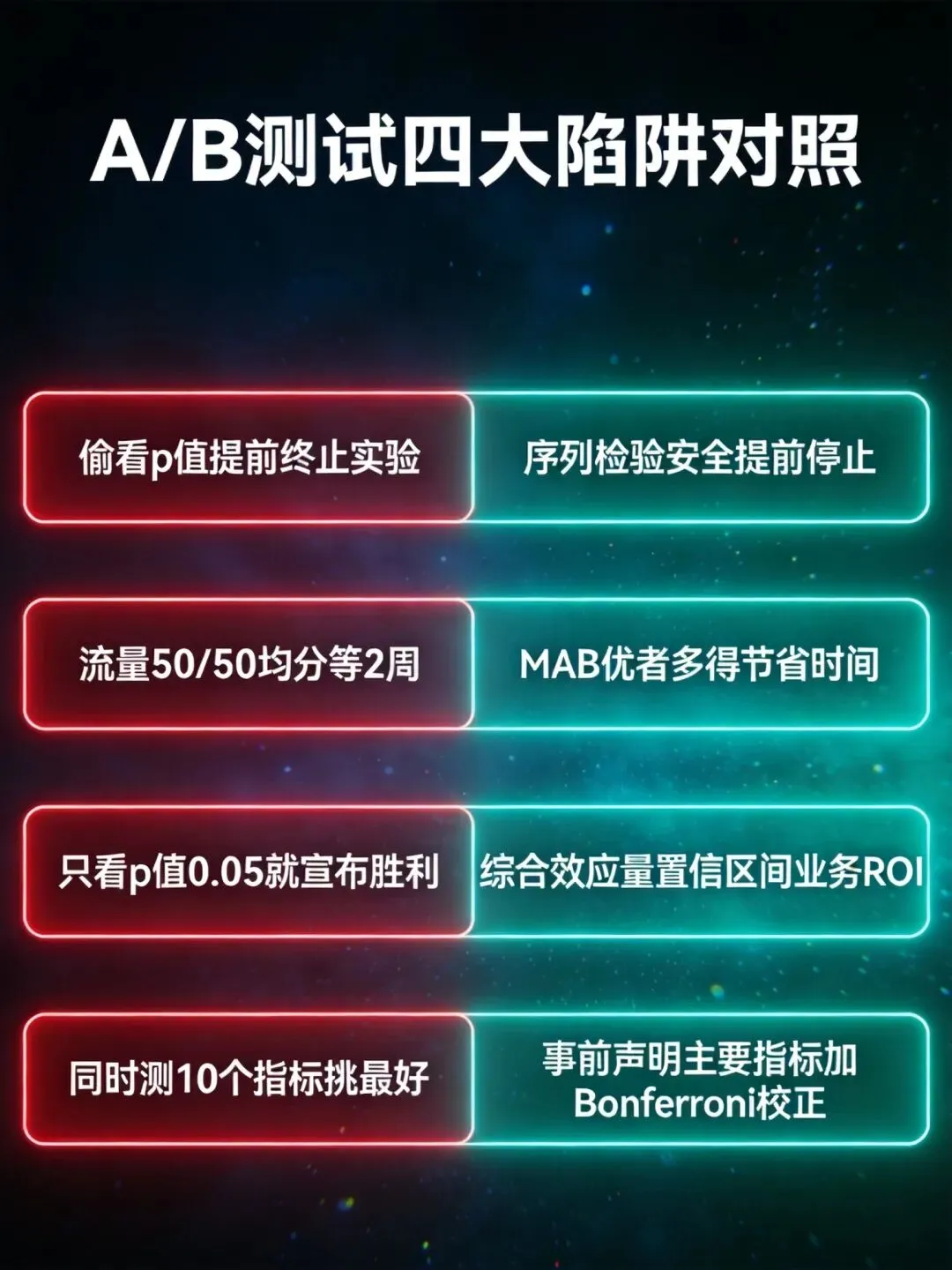
⚠️ 避坑指南:A/B测试的4大致命陷阱
坑1:样本量不够就下结论
跑了3天看到p=0.04就上线,结果全量后效果消失。解决:预先计算样本量,如果必须提前停止,用贝叶斯方法评估风险。
坑2:辛普森悖论——整体看涨,分群看跌
新方案整体转化率提升2%,但老用户下降5%,新用户占比增加掩盖了问题。解决:始终做分群分析,AI会自动标记风险。
坑3:多重比较导致假阳性
同时测试5个指标每个p<0.05,整体假阳性率不是5%而是23%。解决:使用Bonferroni校正(α/测试数)或Benjamini-Hochberg方法控制FDR。
坑4:新奇效应(Novelty Effect)
新UI首周点击率暴涨15%,第2周回落——用户只是"新鲜"才点击。解决:实验至少跑2个完整周期(2-4周),观察效果是否衰减。
🌟 关注星网AI
学会了吗?赶紧试试吧!
关注星网AI,每天分享AI实用技巧和提效干货。
下期教你用AI搭建实时用户行为分析大屏,别错过哦~
