 夜雨聆风
夜雨聆风技术动态
01
DeepSeek:发布多模态技术报告《用视觉原语思考(Thinking with Visaul Primitives)》
4月30日,DeepSeek发布多模态技术报告《用视觉原语思考(Thinking with Visaul Primitives)》,详细阐释了DeepSeek识图模式背后的技术细节。
DeepSeek识图模式所使用的是一个284B参数、13B激活多模态推理模型,基座模型是DeepSeek-V4-Flash。DeepSeek的新一代多模态推理模型的核心升级就在于,它把纯粹的语言推理链条,升级成了一种“语言逻辑+空间坐标”交织的双轨思维。当模型对着一张图进行推理时,它是会像人一样,直接输出一个具体的框或者点,在图中精准地“指”出它当下正在想的那个东西。
项目地址:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives
技术报告:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf

原文链接>> DeepSeek“开眼”背后的技术,公开了!
02
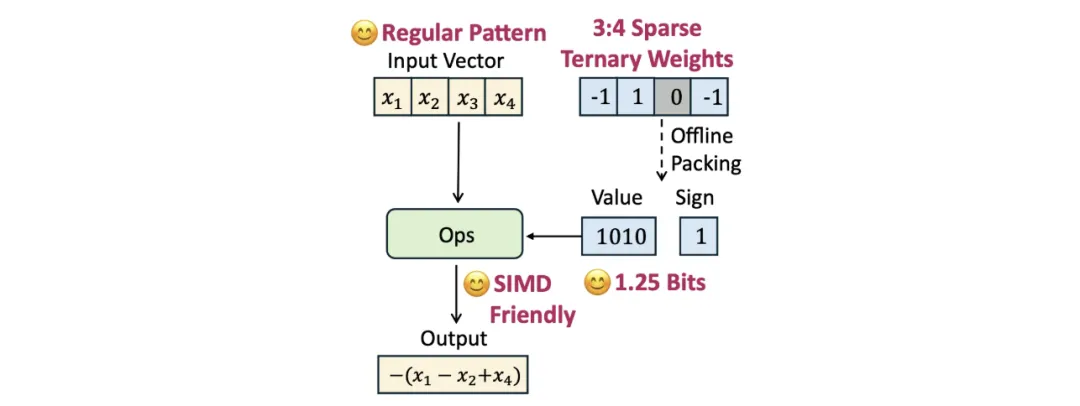
腾讯混元:推出极致量化压缩版本翻译模型 Hy-MT1.5-1.8B-1.25bit
4月29日,腾讯混元推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,无需联网,下载即可直接在手机本地运行。
Hy-MT1.5是腾讯混元团队打造的专业翻译大模型,原生支持33种语言、5种方言/民汉及 1056个翻译方向。针对不同的手机用户,腾讯特别推出了2-bit与1.25-bit两种极致的量化压缩方案,通过自研Sherry稀疏量化技术将1.8B参数模型压缩至440MB。
Sherry论文地址:
https://arxiv.org/abs/2601.07892
AngelSlim 技术报告:
https://arxiv.org/abs/2602.21233
Hy-MT1.5技术报告:
https://arxiv.org/abs/2512.24092
03
银河通用:发布跨本体「隐式世界-动作基础模型」LDA
4月29日,银河通用发布的跨本体「隐式世界-动作基础模型」LDA,在数据层面实现虚实共融、人机混合、质量参差、有无动作标签的数据统一有效利用。
LDA 的核心选择,是放弃VAE,转向DINO结构化潜空间。DINO通过自监督预训练,天然过滤光照、纹理等外观冗余,保留物体级语义与空间结构。在这个空间中,不同机器人、不同环境的数据具有一致的表达形式——外观差异被压制,物理相关信息被突出,使跨本体的动力学学习真正成为可能。
论文地址:
https://arxiv.org/abs/2602.12215
项目链接:
https://pku-epic.github.io/LDA/
代码地址:
https://github.com/jiangranlv/LDA-1B

04
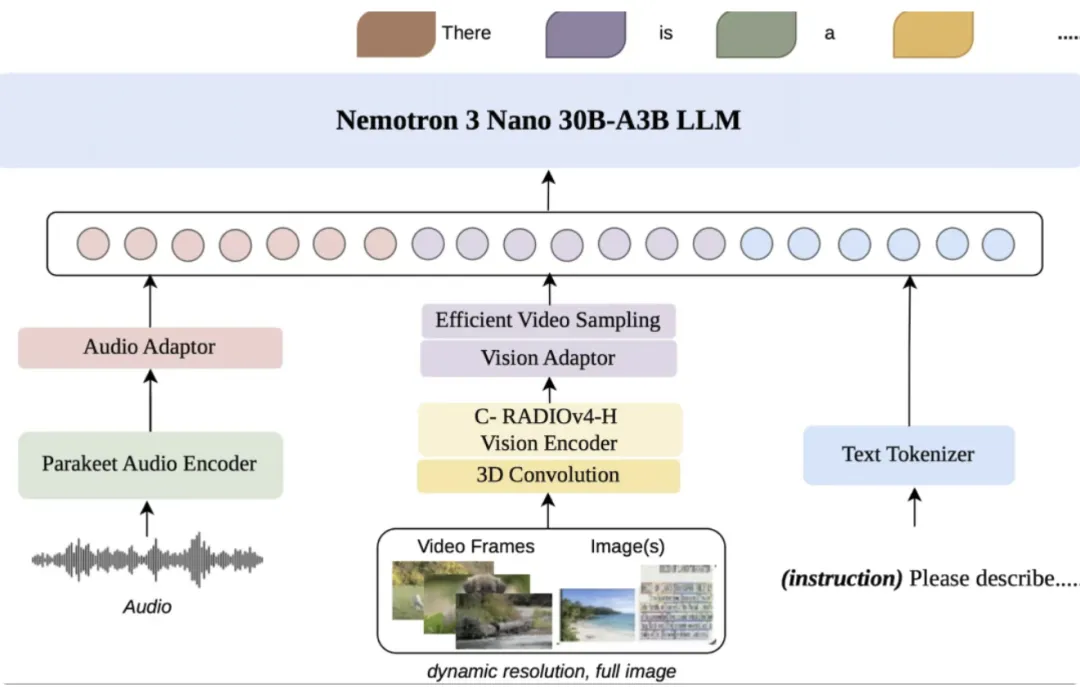
英伟达:推出多模态推理模型Nemotron 3 Nano Omni
4月28日,英伟达正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系。
Nemotron 3 Nano Omni可处理文本、图像、音频、视频、文档、图表和图形界面等多种输入,并以文本形式输出。此外,模型可根据不同任务与模态动态激活专家网络,在保证高吞吐的同时实现强多模态感知能力,使整体吞吐量达到同类开放多模态模型的9倍。
开源网址:
https://nvda.ws/420h6mRhttps://openrouter.ai/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning:free
官方网址:
https://build.nvidia.com/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning
05
商汤科技:发布并开源SenseNova U1系列原生理解生成统一模型
4月28日,商汤科技发布并开源SenseNova U1系列原生理解生成统一模型。
SenseNova U1系列模型基于商汤自主研发的 NEO-unify架构,在单一模型架构上统一了多模态理解、推理与生成。能够将语言与视觉信息作为统一的复合体直接建模,实现语言和视觉信息的高效协同,让理解与生成能力同步增强,在保留语义丰富度的同时,维持像素级的视觉保真度。在逻辑推理与空间智能等方向上,它能够深度理解物理世界的复杂布局与精细关系。
GitHub:
https://github.com/OpenSenseNova/SenseNova-U1
Hugging Face:
https://huggingface.co/collections/sensenova/sensenova-u1

06
小米:发布新款人形机器人,并开源VLA大模型Xiaomi-Robotics-0
4月27日,小米在投资者日活动上,发布新款人形机器人,并开源VLA大模型Xiaomi-Robotics-0。
新款机器人外观上延续了CyberOne的暗灰色调和小米标志,现场演示“比心”、分发纸袋等动作,拥有了更精细的物理交互能力。这双“灵巧手”背后是一套基于触觉抓取的微调模型和VLA大模型Xiaomi-Robotics-0,专门解决机器人在真实作业中容易出现的推理延迟、动作卡顿、能力遗忘等问题,并引入自适应加权机制、Λ型掩码、前缀动作随机遮蔽三大核心技术,让机器人的动作看起来无缝衔接。
技术官网:
https://robotics.xiaomi.com
技术报告:
https://arxiv.org/abs/2602.12684
项目网站:
https://robotics.xiaomi.com/xiaomi-robotics-0.html
模型权重:
https://huggingface.co/XiaomiRobotics
开源代码:
https://github.com/XiaomiRobotics/Xiaomi-Robotics-0

原文链接>> 小米新款人形机器人亮相
行业动态
01
阶跃星辰:发布图像生成编辑模型 Step Image Edit 2
4月29日,阶跃星辰正式发布新一代图像生成编辑模型 Step Image Edit 2,这是一款主打极速响应、高质量输出的轻量级模型。
Step Image Edit 2参数量仅为 3.5B,单次生图仅需 0.5-2s。核心提供图像生成与图像编辑两项能力,支持中英文渲染、局部编辑、视觉推理、主体一致性、风格迁移等。可覆盖 IP 创作、海报设计、漫画生成、人像美颜、旅游修图、写真生成等实际场景需求。

02
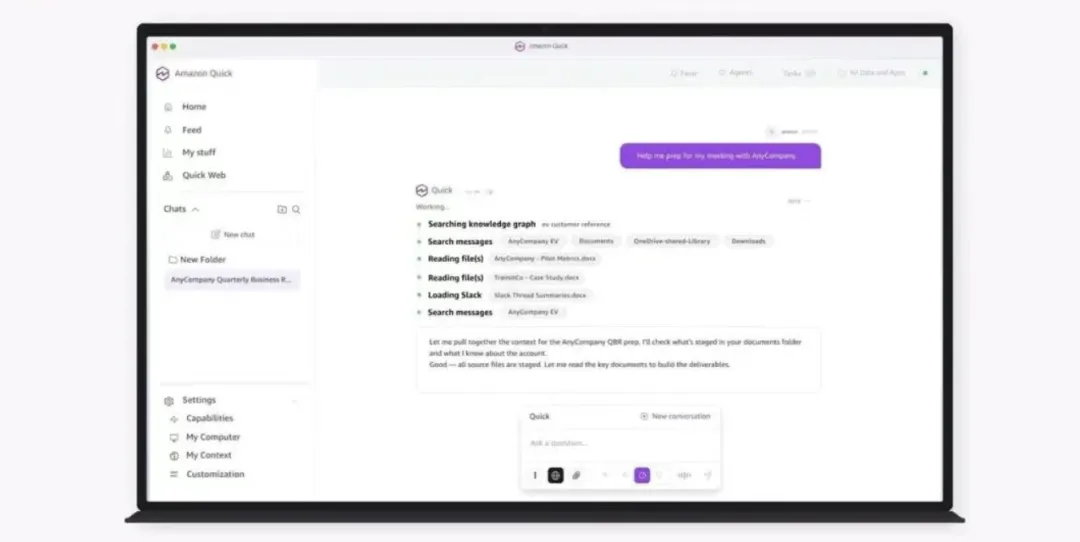
亚马逊云科技:推出桌面端AI助手Amazon Quick
4月29日,亚马逊云科技推出桌面端AI助手Amazon Quick,全域打通办公应用、工具与企业数据。
Amazon Quick打造桌面专属个人AI助手,可快速制作演示文稿、智能数据看板,深度联动主流办公应用,实现全场景需求一站式处理。产品后台常驻运行,深度关联本地文件、日程、邮箱及全量办公工具,持续沉淀工作语境,越用越智能、越贴合业务需求、服务更主动。
03
生数科技:发布通用世界行动模型 Motubrain
4月29日,生数科技正式发布通用世界行动模型 Motubrain,定位于具身智能机器人的通用大脑,具备多本体适配、多任务泛化和长程任务执行能力。
Motubrain 的核心突破,在于将“看到的世界”和“要执行的动作”放入同一个模型中统一建模,让机器人不仅能理解环境,也能想象/预测环境变化,并生成可执行的行动策略。
Motubrain基于原创的UniDiffuser框架统一建模视频与动作两类连续模态,使模型能够同时学习环境变化、动作执行与任务结果之间的关系。在此基础上,Motubrain进一步构建了视频、动作与语言协同的三流MoT架构,融合已有多模态预训练模型和专家模型能力,使模型能够同时完成场景理解、语言指令遵循、结果预测和动作生成。

原文链接>> 生数科技发布通用世界行动模型 Motubrain
04
ima:正式上线copilot知识Agent
4月29日,ima正式上线copilot知识Agent。内置记忆系统包含设定、用户档案、长期记忆和经验技巧四大模块,可跨场景连续调用减少重复输入。
copilot支持全场景感知,以浮窗形式伴随用户浏览网页、文件和知识库,无需额外上传即可理解当前内容并完成处理。同步上线Skills生态,内置知识库操作、笔记管理、报告生成等官方技能,并支持用户自行添加技能和接入第三方模型API。

原文链接>> 你的第一个知识Agent:ima上线copilot功能
05
阿里巴巴ATH团队:发布视频生成模型HappyHorse 1.0
4月27日,阿里巴巴ATH团队发布视频生成模型HappyHorse 1.0。
HappyHorse 1.0 采用原生多模态架构与音视频联合生成方案,面向广告、电商、短剧、社媒创意等场景,提供从生成到编辑的一体化创作能力。在画面质感、镜头运动、人物真实感与内容可控性等方面,均已展现出较强的行业竞争力。

原文链接>> 快乐小马,即刻出发!HappyHorse 1.0 来了
06
百度文库网盘:联合推出通用智能体GenFlow4.0
4月27日,在百度AI DAY上,百度文库网盘联合推出通用智能体GenFlow4.0。
Office Agent全面升级,PPT、Excel、Word三大Agent支持自然语言生成与一键排版,新增记忆中心实现自主思考与项目记忆。深度兼容OpenClaw支持手机电脑协作与定时任务。

原文链接>> 上班一年卷出4个版本,这个通用智能体升级了
政策趋势
01
工业和信息化部、国家数据局:联合实施2026年“模数共振”行动
4月28日,工业和信息化部、国家数据局印发《关于联合实施2026年“模数共振”行动的通知》。
通知明确,行动重点面向制造业领域中的钢铁、工业母机、汽车、航空航天、信息通信等20个行业,并依托重点城市和省份,推动产出一批推广价值高、技术可行性强的人工智能应用场景,攻关一批蕴含工业和信息化领域技术机理的行业模型、专用模型和特色智能体,构建一批行业通识和行业专识高质量数据集,培育一批攻关联合体,优化人才、标准等产业配套生态。到2026年底,基本形成“数据—模型—场景应用”良性互促的循环,推动人工智能高水平赋能新型工业化。
通知部署了七项重点任务,包括构建行业通识数据集和专识数据集、完善模型评测机制、创建“模数共振”空间、打造“模数共振”创新联合体、确定一批重点城市等。通知提出,鼓励“模数共振”空间与国家数据基础设施互联互通,实现多主体数据高效可信流通,赋能模型训练、智能体研发和应用,逐步打造为“智能体工厂”。

02
南京:出台《关于加快推动人工智能终端产业发展的行动计划(2026—2027年)》
4月27日,南京出台《关于加快推动人工智能终端产业发展的行动计划(2026—2027年)》,提出到2027年,全市人工智能终端产业总体规模达2000亿元。
该计划聚焦智能终端产品创新、关键技术突破和产业生态优化,目标是打造具有全球影响力的人工智能产业地标。具体措施包括推动人工智能计算机、手机、机器人等核心产品研发,加强端侧芯片和模型技术攻关,以及培育智能终端产业链。政策将通过专项资金支持、企业培育和应用场景推广等举措,助力南京建设人工智能终端产业高地。

03
深圳:印发《深圳市工业和信息化局打造人工智能先锋城市项目扶持计划操作规程(2026年修订版)》
4月29日,深圳市工信局印发《深圳市工业和信息化局打造人工智能先锋城市项目扶持计划操作规程(2026年修订版)》。
该规程通过"模型券"补贴、行业应用示范项目资助、开源软件奖励等十类项目,对符合条件的企业给予资金支持,重点支持算力支撑、基础数据、人工智能软件及产品等领域,最高扶持3000万元。
04
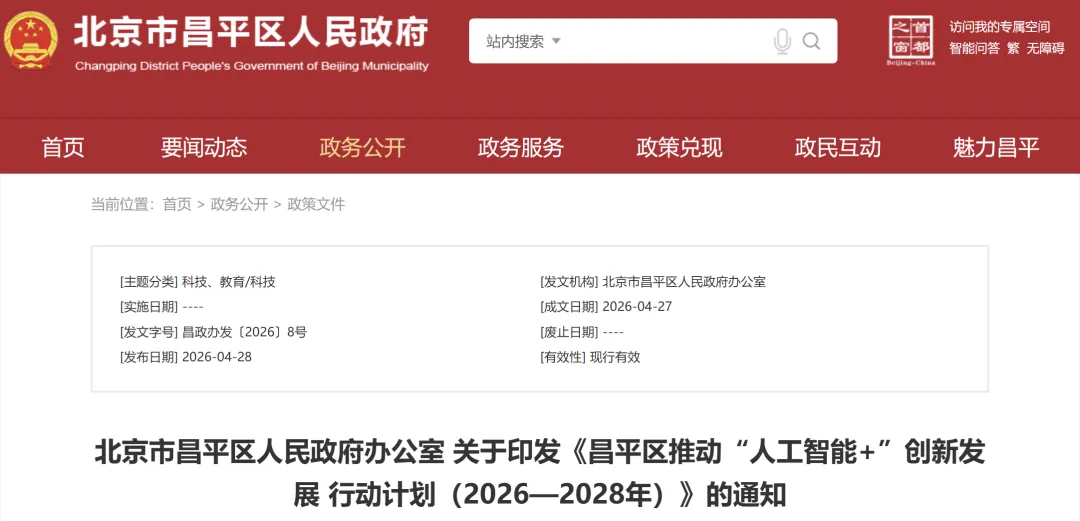
昌平:印发《昌平区推动“人工智能+”创新发展 行动计划(2026—2028年)》
4月28日,北京市昌平区人民政府办公室印发《昌平区推动“人工智能+”创新发展 行动计划(2026—2028年)》。
旨在推动人工智能与产业融合,重点发展“人工智能+生命健康”和“人工智能+能源”两大领域。该计划目标包括突破30项医疗器械注册、12款创新药临床试验,新增5家独角兽企业,打造20个应用场景,并建设算力网络、数据集等基础要素。政策通过高校研发、央企引领、民企协同模式,构建人才、空间、技术服务平台生态。
05
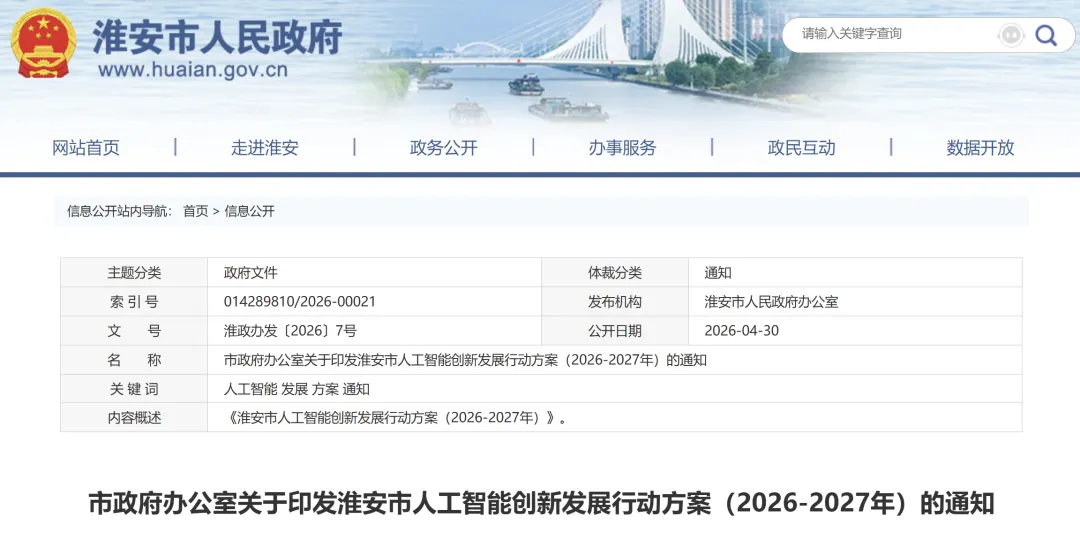
淮安:印发《淮安市人工智能创新发展行动方案(2026-2027年)》
4月28日,淮安市人民政府办公室印发《淮安市人工智能创新发展行动方案(2026-2027年)》,旨在推动人工智能产业融合应用发展。
《方案》重点围绕产业集聚、场景赋能、生态构建三大主线,包含夯实产业基础、推进"人工智能+"赋能、强化创新支撑等四大行动,覆盖工业、农业、商贸等13个领域,提出到2027年实现打造15个工业垂类模型、招引50个亿元级AI项目、培育15家年销超千万AI企业等目标。
来源:NGAI
