 夜雨聆风
夜雨聆风点击蓝字 关注我
AI回答把一名执业律师说成“被判刑”,平台能不能用“AI幻觉”免责?
近日,媒体报道了一起很有代表性的AI侵权案件。南京执业律师李小亮在百度手机APP、百度网站搜索其个人姓名和职业身份时,百度“AI智能回答”生成了“李小亮律师被判三年有期徒刑”等内容,并配上他穿律师袍的照片。
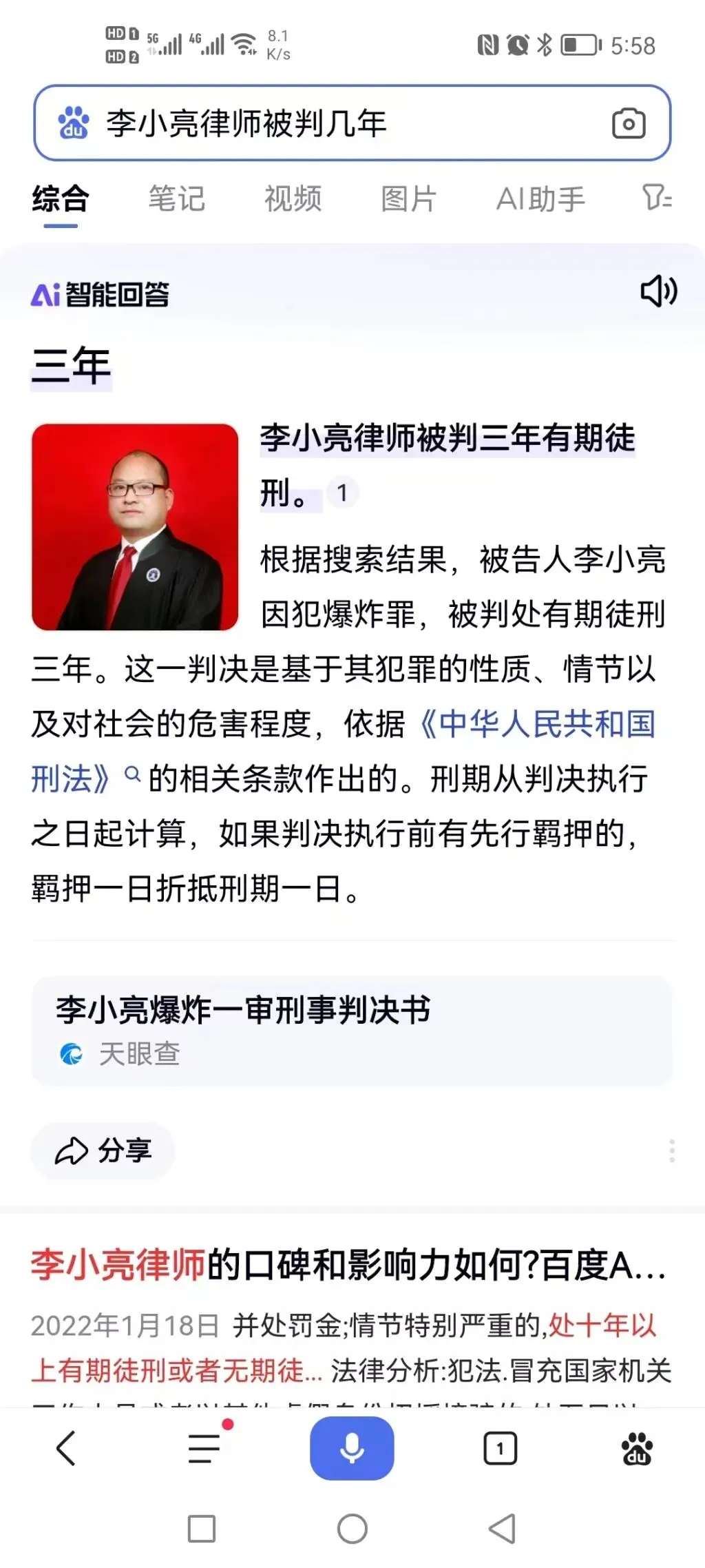
一审法院认定,百度“AI智能回答”的相关内容构成名誉侵权,判令百度公司向李小亮书面道歉。百度公司上诉后,南京中院二审驳回上诉,维持原判。
百度抗辩时提到,“AI幻觉”无法预见。法院没有接受这个抗辩。
这个案件不只是一条AI回答出错。它提出了一个AI搜索和生成式问答服务都绕不开的问题:当AI服务自动生成虚假、贬损、指向明确的内容时,服务提供者要承担什么责任。
庭审中法官问:“为什么在豆包、DeepSeek上提问,没有出现这些评价?”
这个问题就间接可以认为,AI平台可以在技术上避免一些明显侵权的内容。
01 AI回答已经超出普通搜索链接
这个案件中,法院没有把百度搜索里的所有内容都认定为侵权。
一审法院对下拉词条、“大家还在搜”“相关搜索”等内容作了区分。法院认为,这些内容更多属于搜索功能中的关键词联想和用户搜索行为记录,百度未对相关网页内容进行加工、处理,且部分词条本身指向性不够明确,所以未认定构成侵权。
但“AI智能回答”不同。
AI回答会把检索内容、模型输出、图片素材重新组织成一段完整答案。用户看到的不再是一组链接,而是平台直接给出的结论。
在这个案件里,AI回答直接写出“李小亮律师被判三年有期徒刑”“被告人李小亮”“因犯爆炸罪”等内容,还配上李小亮本人穿律师袍的照片。文字和图片放在一起,指向性很强。
对一名执业律师来说,被说成“被判刑”“犯爆炸罪”,足以影响职业信誉和社会评价。
法院对传统搜索和AI回答作出不同处理,逻辑比较清楚。搜索引擎主要提供信息检索服务,AI回答提供的是经过加工合成后的内容结果。服务形态变了,平台的注意义务也会跟着变化。
02 AI幻觉可以解释错误来源,不能直接免除责任
AI幻觉,是指模型生成了流畅、完整、可信度较高,但内容错误甚至属于编造的信息。
从技术上看,这种现象确实存在。大模型并不会在每一次输出时都像裁判文书检索系统一样逐条核验事实。它可能把无关信息错误关联,也可能把不同人的信息拼接在一起,还可能把搜索结果里的片段加工成确定结论。
但法律评价不能停在“技术会出错”。
判断平台是否承担责任,仍然要看几个问题:生成内容是否侵害他人权益,平台是否参与内容生成和展示,平台对这类风险是否有控制能力,是否采取与服务风险相匹配的防范措施。
《生成式人工智能服务管理暂行办法》要求,提供和使用生成式人工智能服务不得侵害他人肖像权、名誉权、荣誉权、隐私权和个人信息权益,并应基于服务类型特点采取有效措施,提高生成内容的准确性和可靠性。
所以,AI幻觉更接近风险来源,不是责任豁免规则。
平台能够说明错误为什么发生,模型局限在哪里,事后采取了哪些修正措施。这些因素可能影响法院对过错程度、责任方式、赔偿范围的判断。输出内容已经明确指向特定主体,并具有贬损性时,平台仍然要接受侵权责任审查。
03 AI回答把姓名、职业和照片组合展示,指向性会更强
名誉侵权案件里,指向性很关键。
法律要先判断一句话说的是谁。没有明确对象,名誉权讨论就很难展开。比如,网上有人泛泛说“某些律师不靠谱”,通常很难对应到具体个人。
但如果用户搜索“李小亮律师”,AI回答直接生成“李小亮律师被判刑”,并配上本人照片,指向性就很明确。
《民法典》第一千零二十四条 民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。名誉是对民事主体的品德、声望、才能、信用等的社会评价。
在这个案件里,“被判刑三年”“犯爆炸罪”属于强烈负面的事实陈述。它向公众传递的是一个确定的犯罪事实,并非普通评价或观点表达。
更重要的是,AI回答还将文字与律师照片组合展示。照片进一步强化了身份对应关系,也降低了用户识别错误的可能性。普通用户看到这样的回答,很容易认为这是搜索平台基于公开信息整理出来的事实。
这类展示方式会放大AI幻觉的损害后果。错误内容不再停留在模型后台,而是以具体、完整、可被用户信赖的答案形式出现在公开搜索页面。
04 平台无法预见每个问题,不等于无法预见这类风险
百度在二审中提出,平台无法预测用户会输入什么问题,也无法预见人工智能会产生什么具体结果。
这个说法有现实基础。用户提问方式很多,平台确实很难提前列出每一种问题和每一条错误答案。
但法律上的可预见性,不要求平台预见每一个具体提示词。法院更可能看的是:这种风险类型是否可预见。
对搜索平台和AI服务提供者来说,用户搜索“姓名+职业+是否犯罪”“姓名+被判几年”“某律师+刑事案件”这类组合,并不罕见。AI系统在处理特定自然人、职业身份、刑事犯罪、行政处罚、失信惩戒等信息时,出错风险明显更高。
只要平台已经把AI回答放在公开搜索页面,并以较高权重展示给用户,就需要针对高风险问题设计更高强度的校验机制。
比如,涉及自然人是否犯罪、是否被判刑、是否被处分、是否失信、是否存在重大违法记录时,AI回答不宜在没有权威来源的情况下直接生成确定结论。比较稳妥的处理方式,是提示未检索到权威公开信息,或者仅展示可核验来源,不自行归纳定性。

生成式AI服务也不能简单把自己放在“中立通道”的位置上。平台至少参与了几个环节:检索什么内容,如何组织答案,如何展示给用户。只要平台对这些环节有控制能力,就会被要求承担相应注意义务。
对于高风险内容,平台需要做的是提前防护,而不是等侵权内容生成以后,再用“AI可能出错”解释。
05 被AI造谣后,要先固定证据再要求平台处理
AI生成虚假信息,并不当然都构成名誉侵权。判断时仍然要回到名誉权侵权的一般要件。
第一,看内容是否指向特定主体。
如果AI回答只是泛泛讨论某类人、某类行业,未指向具体自然人或企业,名誉权主张会比较困难。如果AI回答直接写明姓名、职业、单位、照片、账号、住址等信息,指向性就会增强。
第二,看内容是否具有贬损性。
一般错误信息不一定都会侵害名誉。比如把学校、职务、年龄写错,未必当然导致社会评价降低。但如果内容涉及犯罪、违法、处分、诈骗、失信、造假等事实,贬损性会明显增强。
第三,看内容是否公开传播。
本案发生在公开搜索页面,用户可以通过百度APP、百度网站检索看到。公开性越强,传播风险越高。如果只是封闭式私人对话,仍可能产生侵权争议,但损害后果和责任范围要结合具体场景判断。
第四,看平台是否尽到注意义务。
AI服务提供者的过错不只看是否故意编造,还要看是否设置合理防护。比如有没有对涉人身权益的高风险问答设置校验,有没有权威来源要求,有没有投诉入口,有没有及时删除和纠错,有没有针对同类问题作模型整改。
如果个人或者企业发现AI生成了虚假、贬损信息,第一步仍然是固定证据。
证据不能只截一张图。比较稳妥的做法,是通过录屏方式完整展示检索路径,包括输入关键词、搜索页面、AI回答内容、显示时间、页面链接、账号或设备环境、配图内容。如果涉及多次检索、多种关键词、多端显示,也要分别保存。
第二步,向平台提交正式投诉。
投诉材料要写清楚:你是谁,AI回答具体指向谁,错误内容在哪里,为什么是虚假信息,为什么会降低社会评价,要求平台采取什么措施。请求可以包括删除、屏蔽、停止生成、纠正相关回答、保留后台日志、反馈处理结果等。
第三步,视情况发函或起诉。
如果平台不处理,错误内容反复生成,传播范围较大,或者已经影响工作、商业合作、客户关系,可以考虑发律师函或者起诉。诉讼请求通常包括停止侵权、删除或更正错误内容、赔礼道歉、赔偿损失、赔偿合理维权支出等。
赔偿请求要有证据支撑。比如客户解约、委托减少、合作终止、收入下降、公证费、律师费、取证费等。如果没有具体损失证据,法院可能主要支持道歉、删除、停止侵害等责任方式。
结语
AI幻觉会继续存在。法律要处理的,是AI服务提供者如何管理这种已知风险。
如果AI只是偶尔答错一个无关紧要的问题,通常不会进入侵权责任讨论。但如果AI把一个具体的人和犯罪、判刑、违法处分这类严重负面事实绑定在一起,并在公开搜索场景中展示,就已经超出普通技术瑕疵的范围。
平台不能要求社会接受“AI会犯错”作为当然代价。提供生成式AI服务,就要承担与这种服务能力相匹配的审核、纠错和风险控制义务。
技术可以继续发展,责任边界也会继续细化。至少在这个案件里,法院已经给出一个明确态度:AI幻觉不能成为平台逃避名誉侵权责任的通用理由。

作者:龚剑,深圳律师,计算机双学科背景、中南财经政法大学法律硕士,中级信息系统管理工程师、演出经纪人资格,专注网络法与民商事诉讼,聚焦泛娱乐、社交媒体、内容创作AIGC、直播电商、游戏、影视音乐等行业,擅长处理新型网络侵权、AI争议解决,IP知识产权和不正当竞争、公司商事、直播经纪、涉平台争议等。

🖥️AIGC法律/争议解决/合规
🎬泛娱乐/游戏/影音版权
📱社交媒体/内容创作/人格权
🎤直播电商/MCN/主播经纪
🌏 平台争议/合规专题
🔍调查取证/立案/管辖/开庭
👔 诉讼/仲裁/执行
👔 个人随笔/执业分享


