 夜雨聆风
夜雨聆风最近读到 Anthropic Claude Code 团队的 Thariq Shihipar 一篇文章,主旨是他不再让 AI 写 Markdown 文档,全部改用 HTML——尽管 HTML 比 Markdown 慢 2 到 4 倍。
按软件工程几十年的所有直觉,这是个奇怪的选择。工具应该越来越快才对。
他文章里给的解释——信息密度、视觉清晰、易于分享、支持交互——都成立,但都不是真正的原因。真正的原因他自己在文末才说出来:
❝"I had begun to fear that because I had stopped reading plans in depth I would simply have to leave Claude to make its choices."
❞
Thariq 不是在选文件格式。他在解决的是另一个问题:自己的注意力不够用了。
而这个看似私人的焦虑,背后是一次更大的、结构性的成本翻转。
一、一个开发者的私人焦虑,是一次结构性翻转的征兆
Thariq 描述的处境很具体。AI agent 给他生成的内容多到他读不完——超过 100 行的 markdown 文件他不读,公司里其他人更不读。
这看起来是个老问题:信息过载。但有一个关键区别。过去几十年说的"信息过载",源头都在外部——推特、邮件、新闻、永远刷不完的信息流。这次的过载来自他自己使唤的工具。第一次出现这种情形:人让机器干活,结果机器干得太多,人消化不了。
这件事看起来很"个人",但背后是软件工程几十年来一个隐含前提的崩塌。
所有现代软件工程实践——库要复用、组件要抽象、代码要 DRY、测试要覆盖——都建立在一个默认假设上:「生产成本远远大于消费成本」。人写程序昂贵,所以工具的全部使命是降低生产成本。代码评审、CI/CD、设计模式、敏捷开发——一整套方法论都是为了让"生产"这一端的效率最大化。
消费这一端从未被认真讨论。因为没必要——人读代码、读文档的速度,长期被默认为"够用",毕竟生产本来比消费慢得多。
AI 改变的不是这个等式的某一项,而是整个等式。生产端的成本垂直坠落。机器生成 1000 行 markdown 几乎不要钱,1 万行也不要钱。但消费端没动——人的眼睛还是那双眼睛,人的注意力还是 24 小时一天。
等式翻转了。
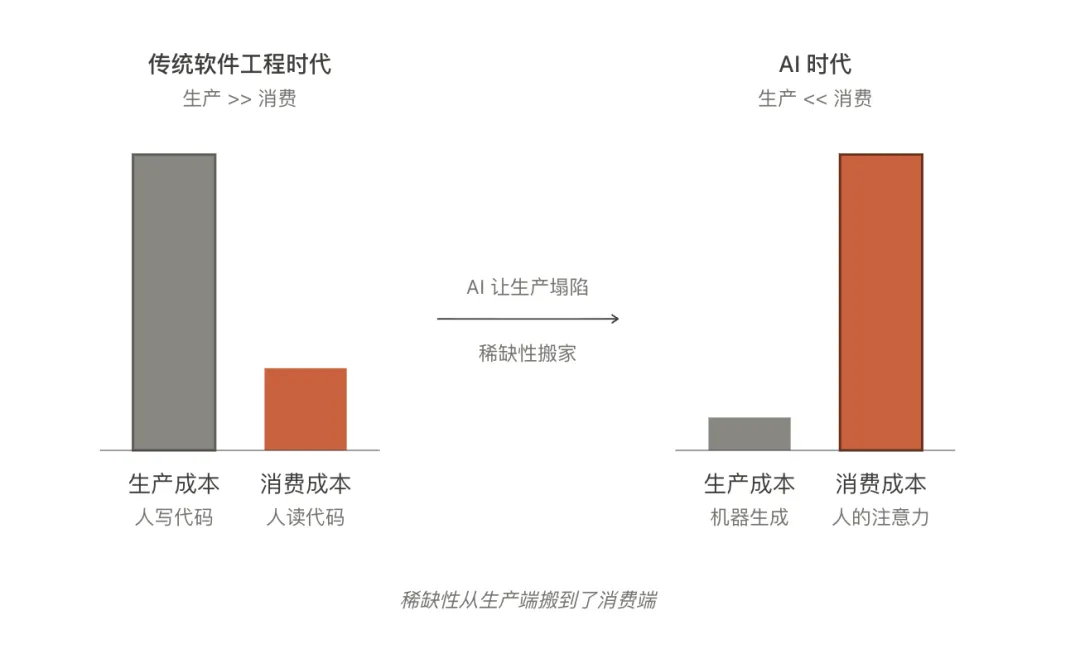
一旦翻转发生,所有围绕"降低生产成本"建立的工程直觉开始失效。DRY 原则在 AI 代码生成面前变得可疑——重复生成不要钱,何必复用?代码评审在 PR 数量爆炸时变成瓶颈——人审不过来。详尽的文档反而成了负担——写得越多,越没人读。
Thariq 愿意付 2 到 4 倍的生成时间来换"我会读这份文档",是这个翻转最早期、最朴素的反应。他自己可能没有把这件事概念化,但他的选择是诚实的。「他在用过剩的资源(机器时间)兑换稀缺的资源(自己的注意力)。」
过去三十年的软件工程,本质上一直在解决"缺人手"的问题。现在第一次,要解决的是"缺眼睛"的问题。
二、AI 改变了"注意力稀缺"的物理规则
读到这里有个反驳很自然:注意力稀缺这事不新鲜,半个世纪前已经有经济学家明确指出过——信息越多,注意力越稀缺。互联网时代的注意力经济、社交媒体的算法推荐、各种 dark pattern——都是这个判断的产物。这条线起码三十年了。
承认。但旧的"注意力稀缺"故事里,藏着一个稳定参数:「生产端是人」。
人写推文、人拍视频、人发新闻——生产有自然的速度上限。一个人一天最多发 50 条推文,写一篇深度报道。整个注意力争夺战是"有限生产 vs 有限消费"。即便最高效的内容工厂——大型媒体、MCN、内容工作室——都依赖人力。
AI 取消了这个稳定参数。生产端的物理上限被打掉了。
第一次出现这种局面:单个消费者背后挂着 N 个不知疲倦的生产者。Thariq 一个人对应一队 Claude,每个 Claude 都在持续输出 markdown plan、spec、报告、PR 描述。任何一个用 AI 工具的人,都在体验这件事的早期形态——你的 Notion 里堆着 AI 写的会议纪要,你的代码库里堆着 AI 写的 README,你的邮箱里堆着 AI 起草的回复模板。
这不是"注意力经济升级",是物理规则换了。过去是 N 个人抢 1 双眼睛,未来是 N × ∞ 个 AI agent 抢 1 双眼睛。
更关键的差异在内容质量这一维度。过去的注意力稀缺还能靠"内容更精彩"竞争出胜负——人有创意上限,所以"好内容"是稀缺品,作者凭着把内容做得更好争夺读者。AI 时代连"好内容"都可以批量生产。今天的前沿模型写一篇有结构、有论据、有数据的分析报告,成本几乎为零。
「唯一不能批量生产的,是"读完它"这件事本身。」
三、HTML 是消费端的一次"扩容"尝试
回到 Thariq 文章里那些看似散乱的论据:信息密度更高、视觉更清晰、易于分享、支持交互、令人愉悦(joyful)。
这些论据全部归到同一个目标上:「让我愿意读、读得动」。
信息密度更高,意味着单位时间能吸收更多。视觉更清晰,降低消费门槛。易于分享,让协作者也愿意读。双向交互,把"读"变成"用",提高 engagement。Joyful,触发内在动机。
注意一件事:Thariq 整篇文章里,没有任何一条论据是关于"AI 用 HTML 能写得更好"。所有论据都是关于"我更看得进去"。
这就是他愿意付 2 到 4 倍生成时间的全部理由。他不在乎机器的时间——机器的时间已经过剩到不需要在乎。「他在用机器的时间,买自己的注意力。」
这是非常清晰的资源置换:把已经过剩的资源(AI 计算)兑换成已经稀缺的资源(人类注意力)。所有意识到等式翻转的人都会做这件事,只是大多数人还没把它概念化。
类似的兑换在其他领域也已经开始。研究者让 AI 生成五个版本的论文摘要,自己挑一个——他在用 AI 算力买自己的判断力。产品经理让 AI 准备同一个 spec 的三种视觉风格,自己选一种——他在用 AI 算力买自己的审美决断。这些行为表面看是"利用 AI 提效",本质都是同一个逻辑:用便宜的去买贵的。
四、消费端的天花板,比看起来还低
HTML 路线很聪明,但天花板很低。
眼睛还是那双眼睛,大脑还是那个大脑。视觉化、信息密度、交互设计——乐观估计能把消费效率提高 2 到 3 倍。一个原本读不进 100 行 markdown 的工程师,换成 HTML 也许能愿意看 300 行。这是边际改进,不是数量级跃迁。
但生产端可以提高 100 倍、1000 倍。下一代模型一发布,下一代 agent 框架一成熟,生产端的"乘数效应"就会继续放大。两年后写 1 万行文档的成本,可能只有今天的十分之一。
消费端没有这种乘数。人类感知带宽是个生理常量。
缺口只会越来越大。
那真正的应对策略有几条。第一条:「外包消费」。让 AI 替你读、替你决策、替你写总结、替你和别人沟通。但这是 Thariq 拒绝的——他要 stay in the loop。第二条:「精读优化」。HTML 这种路线,把消费体验做得更好,多撑一阵。但只能延缓问题,不能解决问题。第三条:「重构协作方式」。从"AI 生成、人审阅"变成完全不同的工作流——但这个"完全不同"目前没有人有清晰答案。
大多数人会在前两条之间摇摆。第三条才是真正的开放问题。
这个开放问题之所以难,是因为它本质上是个权力问题:在一个 AI 可以无限生产、人类无法跟上消费的世界里,到底谁说了算?完全外包给 AI,相当于把决策权交出去;完全自己审阅,意味着永远跟不上 AI 的生产速度。
中间那个平衡点在哪儿,目前没人知道。
五、Stay in the Loop 是一个存在论问题
回到 Thariq 文章的这句:Stay in the Loop。这才是全文的真锚点。
他害怕的不是 Claude 做错决策——Claude 做错决策在他的工作流里是可以纠正的。
他害怕的是更深的东西:「如果我不再读、不再验证、不再判断,那"我"在这件事里还剩下什么?」
在工业时代,人类外包了体力。机器替我们犁地、纺纱、运输、组装。但人类保留了"做什么"的决定权。机器是执行者,人是规划者。
在 AI 时代,"做什么"和"怎么做"也开始被外包。剩下的只有"按下回车键"。
Thariq 的反应是非常本能的。他没有发表关于人机协作的宏大宣言,他只是改了文件格式。但这个改变背后藏着一个朴素的固执:「这件事是我的,所以我必须看着它发生」。
HTML 是他给自己保留 agency 的方式。他不是在选文件格式,他是在选择继续作为"那个做事的人"存在。
这种固执很容易被嘲笑——AI 都能写得比你好了,你为什么还坚持自己看?但这种固执,可能是人类在 AI 时代最后的护城河。
不是因为人类的判断比 AI 准。而是因为,一件事只有被一个具体的人"看进去过",它才属于那个人。
Thariq 不是孤立的。
产品经理不读自己 AI 写的需求文档。经理不看自己 AI 起草的邮件。学者不读自己 AI 准备的文献综述。律师不审自己 AI 生成的合同。同样的事情在不同行业里以不同形式发生着——一个人让机器为他生产某样东西,然后发现自己根本看不过来。
这件事的吊诡之处在于:在一个无限生产的世界里,「没被消费过的产出,等于没被生产过」。一份没人读的 spec、一段没人审的代码、一份没人看的报告——它们消耗了 token,占用了存储,但在因果链条上从未发生。
于是稀缺性的位置已经清楚了:愿意消费,比能生产更稀缺。
Thariq 选择 HTML,不是因为他想要更漂亮的文件。是因为在一个无限生产的世界里,他想保住自己作为消费者的位置。
那个位置可能是人类最后一块属于自己的地。
